Trénování modelu PyTorch
Tento článek popisuje, jak používat komponentu Train PyTorch Model v návrháři Azure Machine Learning k trénování modelů PyTorch, jako je DenseNet. Trénování probíhá po definování modelu a nastavení jeho parametrů a vyžaduje označená data.
Komponenta TyTorch Model v současné době podporuje jeden uzel i distribuované trénování.
Jak používat trénování modelu PyTorch
Přidejte komponentu DenseNet nebo ResNet do konceptu kanálu v návrháři.
Přidejte do kanálu komponentu Train PyTorch Model . Tuto komponentu najdete v kategorii Trénování modelu. Rozbalte položku Train (Trénovat) a přetáhněte komponentu Train PyTorch Model (Trénování modelu) do kanálu.
Poznámka:
Trénování komponenty modelu PyTorch je lepší spustit na výpočetních prostředcích typu GPU pro velkou datovou sadu, jinak váš kanál selže. Výpočetní prostředky pro konkrétní komponentu můžete vybrat v pravém podokně komponenty nastavením Použít jiný cílový výpočetní objekt.
Na levém vstupu připojte nevytrénovaný model. Připojte trénovací datovou sadu a ověřovací datovou sadu k prostřednímu a pravému vstupu trénování modelu PyTorch.
Pro nenatrénovaný model musí být model PyTorch, jako je DenseNet; Jinak se vyvolá chyba InvalidModelDirectoryError.
Pro datovou sadu musí být trénovací datová sada označený jako adresář obrázků. Informace o tom, jak získat adresář obrázků s popiskem, najdete v části Převést do adresáře obrázků. Pokud není označeno, vyvolá se chyba NotLabeledDatasetError.
Trénovací datová sada a ověřovací datová sada mají stejné kategorie popisků, jinak se vyvolá chyba InvalidDatasetError.
V případě Epochs zadejte, kolik epoch chcete trénovat. Celá datová sada bude ve výchozím nastavení iteována v každé epochě 5.
V případě velikosti dávky zadejte, kolik instancí se má v dávce trénovat, ve výchozím nastavení 16.
Pro číslo kroku Warmup určete, kolik epoch chcete trénování zahřát, pokud je počáteční rychlost učení mírně příliš velká, aby se ve výchozím nastavení 0 začalo konvergovat.
Pro rychlost učení zadejte hodnotu pro rychlost učení a výchozí hodnota je 0,001. Rychlost učení řídí velikost kroku, který se používá v optimalizátoru, jako je sgd při každém otestování a opravě modelu.
Když nastavíte menší rychlost, model otestujete častěji s rizikem, že byste se mohli zaseknout v místní plošině. Když nastavíte rychlost větší, můžete konvergovat rychleji s rizikem přehození skutečného minima.
Poznámka:
Pokud během trénování dojde ke ztrátě trénování, což může být způsobeno příliš velkou rychlostí učení, může pomoct snížení rychlosti učení. V distribuovaném trénování se kvůli zachování stabilního gradientního sestupu vypočítá
lr * torch.distributed.get_world_size()skutečná rychlost učení, protože velikost dávky skupiny procesů je světová velikost jednoho procesu. Polynomická rychlost učení se využívá a může pomoct dosáhnout lepšího výkonu modelu.Pro náhodné počáteční hodnoty volitelně zadejte celočíselnou hodnotu, která se má použít jako počáteční hodnota. Pokud chcete zajistit reprodukovatelnost experimentu napříč úlohami, doporučuje se použít počáteční hodnoty.
V případě trpělivosti určete, kolik epoch se má v případě, že ztráta ověření po sobě nezmenší. ve výchozím nastavení 3.
Pro frekvenci tisku zadejte frekvenci tisku trénovacího protokolu v každé epochě ve výchozím nastavení 10.
Odešlete kanál. Pokud má vaše datová sada větší velikost, bude chvíli trvat a doporučí se výpočetní výkon GPU.
Distribuované trénování
Při distribuovaném trénování úlohy pro trénování modelu se rozdělí a sdílí mezi několik miniprocesorů označovaných jako pracovní uzly. Tyto pracovní uzly fungují paralelně a urychlují trénování modelu. Návrhář v současné době podporuje distribuované trénování pro komponentu Trénování modelu PyTorch.
Doba trénování
Distribuované trénování umožňuje trénovat na velké datové sadě, jako je ImageNet (1000 tříd, 1,2 milionu obrázků) během několika hodin pomocí Trénování modelu PyTorch. Následující tabulka ukazuje dobu trénování a výkon během trénování 50 epoch resnet50 v síti ImageNet od začátku na základě různých zařízení.
| Zařízení | Čas trénování | Trénovací propustnost | Přesnost ověření top-1 | Přesnost ověření top-5 |
|---|---|---|---|---|
| 16 GPU V100 | 6h22min | ~3200 obrázků za sekundu | 68.83% | 88.84% |
| 8 GPU V100 | 12h21min | ~1670 obrázků za sekundu | 68.84% | 88.74% |
Klikněte na tuto kartu Metriky a prohlédněte si grafy trénovacích metrik, například Trénování obrázků za sekundu a Nejvyšší přesnost.

Povolení distribuovaného trénování
Pokud chcete povolit distribuované trénování pro komponentu TyTorch Model, můžete v nastavení úlohy nastavit v pravém podokně komponenty. Distribuované trénování podporuje pouze výpočetní cluster AML.
Poznámka:
K aktivaci distribuovaného trénování se vyžaduje více GPU , protože komponenta TyTorch Model ncCL vyžaduje cuda.
Vyberte komponentu a otevřete pravý panel. Rozbalte část Nastavení úlohy.
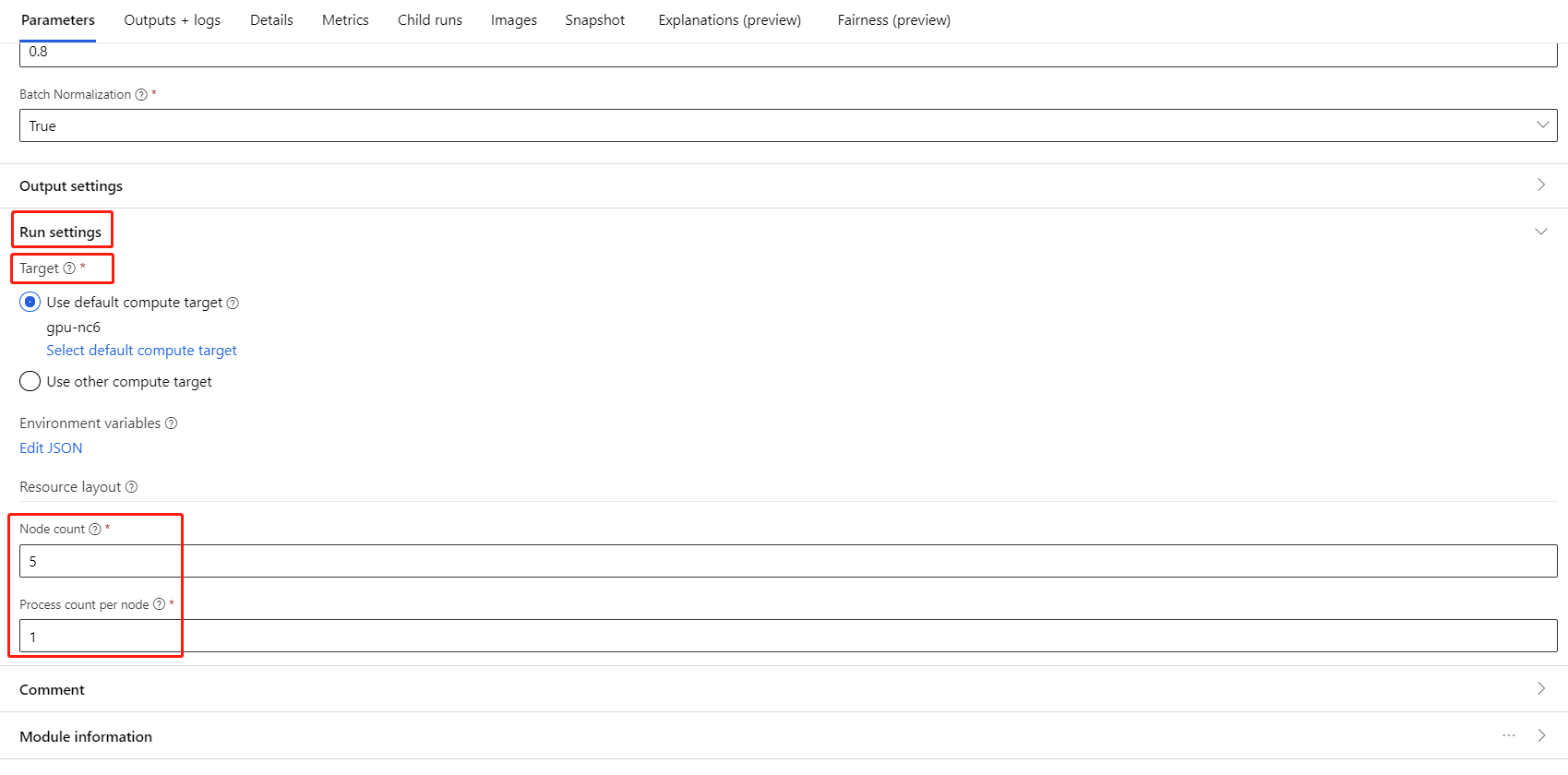
Ujistěte se, že jste pro cílový výpočetní objekt vybrali výpočetní prostředky AML.
V části Rozložení prostředku musíte nastavit následující hodnoty:
Počet uzlů: Počet uzlů ve výpočetním cíli použitém pro trénování. Měl by být menší nebo roven maximálnímu počtu uzlů výpočetního clusteru. Ve výchozím nastavení je to 1, což znamená úlohu s jedním uzlem.
Počet procesů na uzel: Počet procesů aktivovaných na uzel Měla by být menší než nebo rovna jednotce zpracování výpočetních prostředků. Ve výchozím nastavení je to 1, což znamená jednu úlohu procesu.
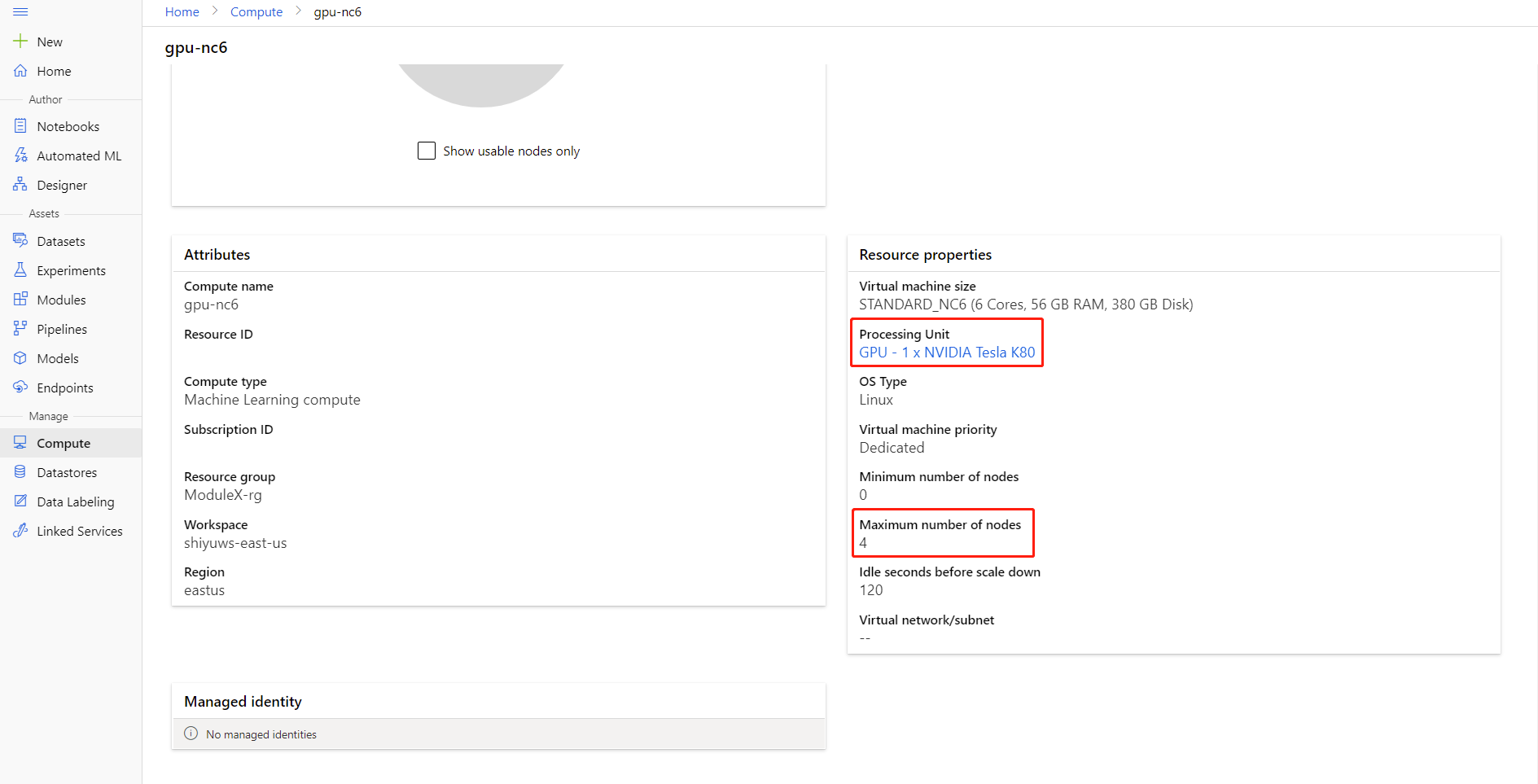
Maximální počet uzlů a jednotek zpracování výpočetních prostředků můžete zkontrolovat kliknutím na název výpočetních prostředků na stránku podrobností o výpočetních prostředcích.


Další informace o distribuovaném trénování ve službě Azure Machine Learning najdete tady.
Řešení potíží s distribuovaným trénováním
Pokud pro tuto komponentu povolíte distribuované trénování, budou pro každý proces existovat protokoly ovladačů. 70_driver_log_0 je určená pro hlavní proces. V protokolech ovladačů můžete v pravém podokně zkontrolovat podrobnosti o chybách jednotlivých procesů na kartě Výstupy a protokoly .

Pokud komponenta s povoleným distribuovaným trénováním selže bez protokolů 70_driver , můžete zkontrolovat 70_mpi_log podrobnosti o chybě.
Následující příklad ukazuje běžnou chybu, což je počet procesů na uzel je větší než výpočetní jednotka zpracování.

Další podrobnosti o řešení potíží s komponentou najdete v tomto článku .
Výsledky
Po dokončení úlohy kanálu pro použití modelu pro bodování propojte model Trénování modelu PyTorch k určení skóre image modelu a predikci hodnot pro nové vstupní příklady.
Technické poznámky
Očekávané vstupy
| Name | Typ | Popis |
|---|---|---|
| Netrénovaný model | UntrainedModelDirectory | Nevytrénovaný model, vyžadovat PyTorch |
| Trénovací datová sada | ImageDirectory | Trénovací datová sada |
| Ověřovací datová sada | ImageDirectory | Ověřovací datová sada pro vyhodnocení každé epochy |
Parametry komponent
| Název | Rozsah | Typ | Výchozí | Popis |
|---|---|---|---|---|
| Epoch | >0 | Celé číslo | 5 | Vyberte sloupec obsahující popisek nebo sloupec výsledku. |
| Velikost dávky | >0 | Celé číslo | 16 | Kolik instancí se má v dávce trénovat |
| Číslo kroku warmup | >=0 | Celé číslo | 0 | Kolik epoch k zahřátí trénování |
| Rychlost učení | >=double. Epsilon | Float | 0,1 | Počáteční míra učení pro optimalizátor Stochastic Gradient Sestup. |
| Náhodné číslo | Všechny | Celé číslo | 0 | Počáteční hodnota generátoru náhodných čísel používaných modelem. |
| Trpělivost | >0 | Celé číslo | 3 | Kolik epoch k předčasnému zastavení trénování |
| Frekvence tisku | >0 | Celé číslo | 10 | Frekvence tisku trénovacích protokolů v jednotlivých epochách |
Výstupy
| Name | Typ | Popis |
|---|---|---|
| Trénovaný model | ModelDirectory | Trénovaný model |
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.