Komponenta Trénování modelu
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning.
Tato komponenta slouží k trénování klasifikačního nebo regresního modelu. Trénování probíhá po definování modelu a nastavení jeho parametrů a vyžaduje označená data. Model trénování můžete použít také k přetrénování existujícího modelu s novými daty.
Jak trénovací proces funguje
Vytvoření a použití modelu strojového učení ve službě Azure Machine Learning je obvykle třístupňový proces.
Model nakonfigurujete tak, že zvolíte konkrétní typ algoritmu a definujete jeho parametry nebo hyperparametry. Zvolte některý z následujících typů modelů:
- Klasifikační modely založené na neurálních sítích, rozhodovacích stromech a rozhodovacích strukturách a dalších algoritmech.
- Regresní modely, které mohou zahrnovat standardní lineární regresi nebo které používají jiné algoritmy, včetně neurálních sítí a bayesovské regrese.
Zadejte datovou sadu, která je označená a má data kompatibilní s algoritmem. Připojte data i model k trénování modelu.
Výsledkem trénování je určitý binární formát, iLearner, který zapouzdřuje statistické vzory získané z dat. Tento formát nelze přímo upravit ani přečíst; Jiné komponenty však mohou tento natrénovaný model použít.
Můžete také zobrazit vlastnosti modelu. Další informace najdete v části Výsledky.
Po dokončení trénování použijte trénovaný model s jednou z hodnoticích komponent k předpovědím na nových datech.
Jak používat trénování modelu
Přidejte do kanálu komponentu Trénování modelu . Tuto komponentu najdete v kategorii Machine Learning . Rozbalte položku Train (Trénovat) a potom přetáhněte komponentu Train Model (Trénovat model ) do kanálu.
Na levém vstupu připojte nevyučovaný režim. Připojte trénovací datovou sadu ke vstupu modelu trénování pravým tlačítkem myši.
Trénovací datová sada musí obsahovat sloupec popisku. Všechny řádky bez popisků se ignorují.
U sloupce Popisek klikněte na možnost Upravit sloupec v pravém panelu komponenty a zvolte jeden sloupec, který obsahuje výsledky, které model může použít k trénování.
V případě problémů s klasifikací musí sloupec popisku obsahovat buď hodnoty kategorií , nebo diskrétní hodnoty. Příkladem může být hodnocení ano/ne, kód klasifikace onemocnění nebo název nebo skupina příjmů. Pokud vyberete sloupec, který není zařazený do kategorií, komponenta během trénování vrátí chybu.
V případě problémů s regresí musí sloupec popisku obsahovat číselná data, která představují proměnnou odpovědi. Číselná data v ideálním případě představují průběžné škálování.
Příkladem může být skóre úvěrového rizika, předpokládaný čas selhání pevného disku nebo předpokládaný počet volání do call centra v daném dni nebo čase. Pokud nevyberete číselný sloupec, může se zobrazit chyba.
- Pokud nezadáte sloupec popisku, který se má použít, Azure Machine Learning se pokusí odvodit, což je příslušný sloupec popisku pomocí metadat datové sady. Pokud vybere nesprávný sloupec, opravte ho pomocí selektoru sloupců.
Tip
Pokud máte potíže s používáním selektoru sloupců, přečtěte si článek Výběr sloupců v datové sadě , kde najdete tipy. Popisuje některé běžné scénáře a tipy pro použití možností WITH RULES a BY NAME .
Odešlete kanál. Pokud máte hodně dat, může to chvíli trvat.
Důležité
Pokud máte sloupec ID, který je ID každého řádku nebo textového sloupce, který obsahuje příliš mnoho jedinečných hodnot, může model trénování dojít k chybě typu Počet jedinečných hodnot ve sloupci: {column_name} je větší, než je povoleno.
Důvodem je to, že sloupec dosáhl prahové hodnoty jedinečných hodnot a může způsobit nedostatek paměti. Pomocí funkce Upravit metadata můžete tento sloupec označit jako funkci Vymazat a tento sloupec nebude použit při trénování nebo extrahovat funkce N-Gram z textové komponenty k předběžnému zpracování textového sloupce. Další podrobnosti o chybě najdete v kódu chyby Návrháře.
Interpretovatelnost modelu
Interpretovatelnost modelu poskytuje možnost pochopit model ML a prezentovat podkladový základ pro rozhodování způsobem, který je srozumitelný pro lidi.
Komponenta Trénování modelu v současné době podporuje použití balíčku interpretability k vysvětlení modelů ML. Podporují se následující předdefinované algoritmy:
- Lineární regrese
- Regrese neurální sítě
- Zesílená regrese stromu
- Regrese rozhodovacího lesa
- Poissonova regrese
- Logistická regrese se dvěma třídami
- Support Vector Machine (SVM) se dvěma třídami
- Dvoutřídní zesílený dekusionový strom
- Rozhodovací les se dvěma třídami
- Rozhodovací doménová struktura s více třídami
- Logistická regrese s více třídami
- Neurální síť s více třídami
Pokud chcete vygenerovat vysvětlení modelu, můžete v rozevíracím seznamu vysvětlení modelu v komponentě Trénování modelu vybrat true. Ve výchozím nastavení je v komponentě Train Model nastavena na Hodnotu False. Upozorňujeme, že generování vysvětlení vyžaduje dodatečné náklady na výpočetní prostředky.
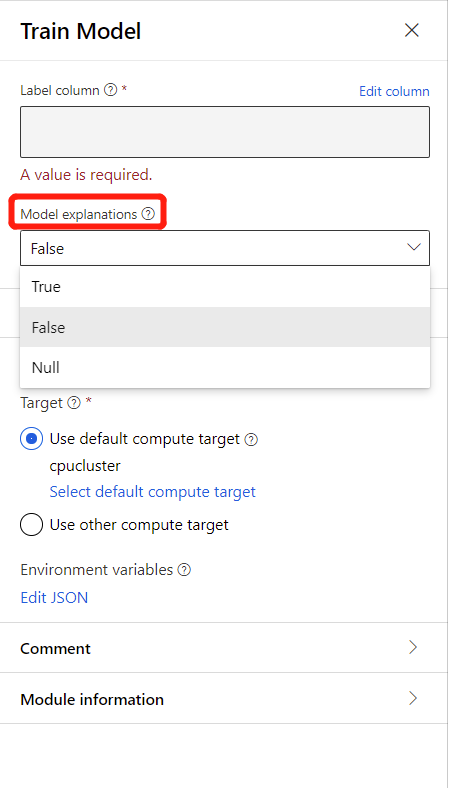
Po dokončení spuštění kanálu můžete navštívit kartu Vysvětlení v pravém podokně komponenty Trénování modelu a prozkoumat výkon modelu, datovou sadu a důležitost funkcí.
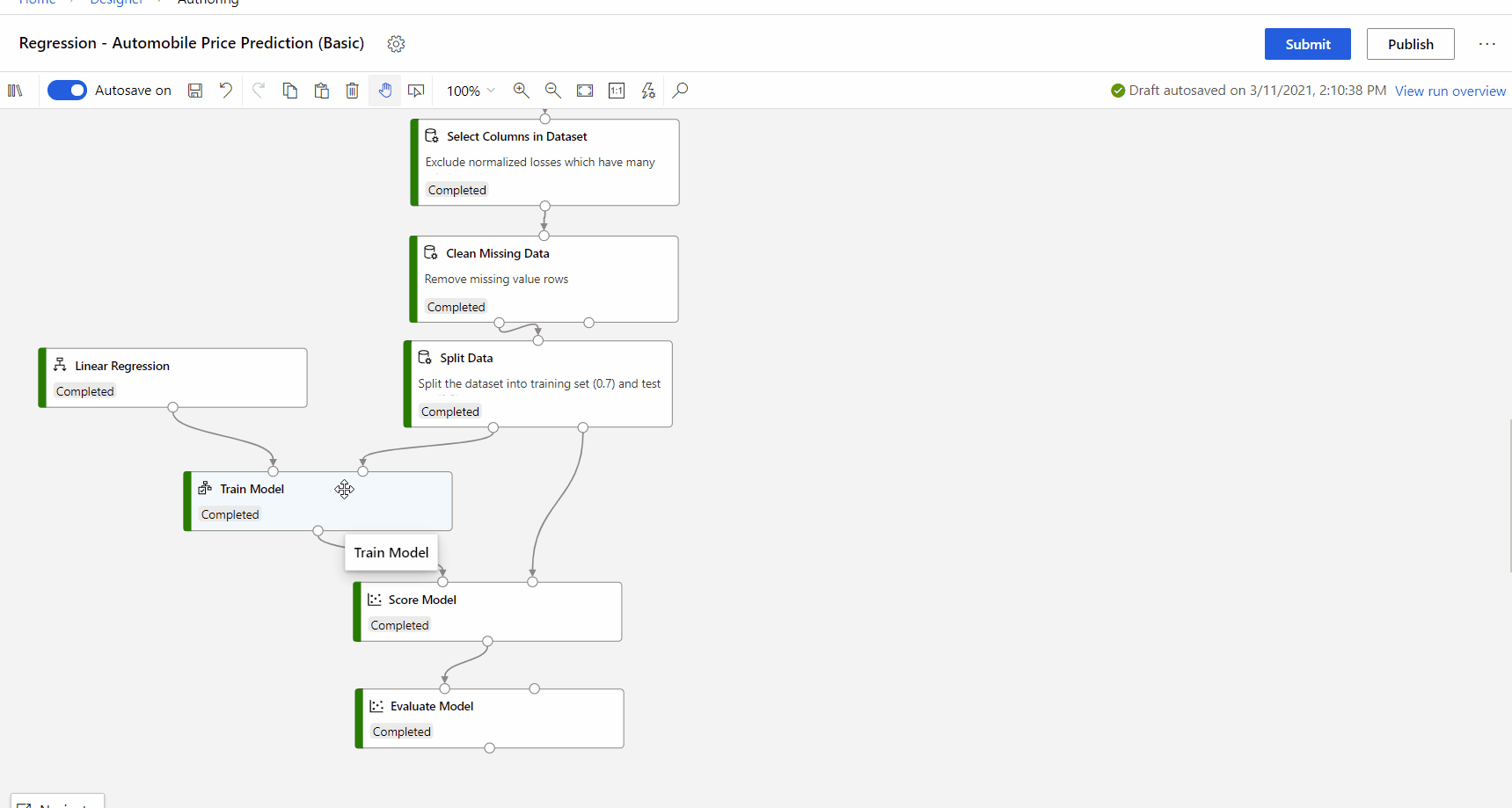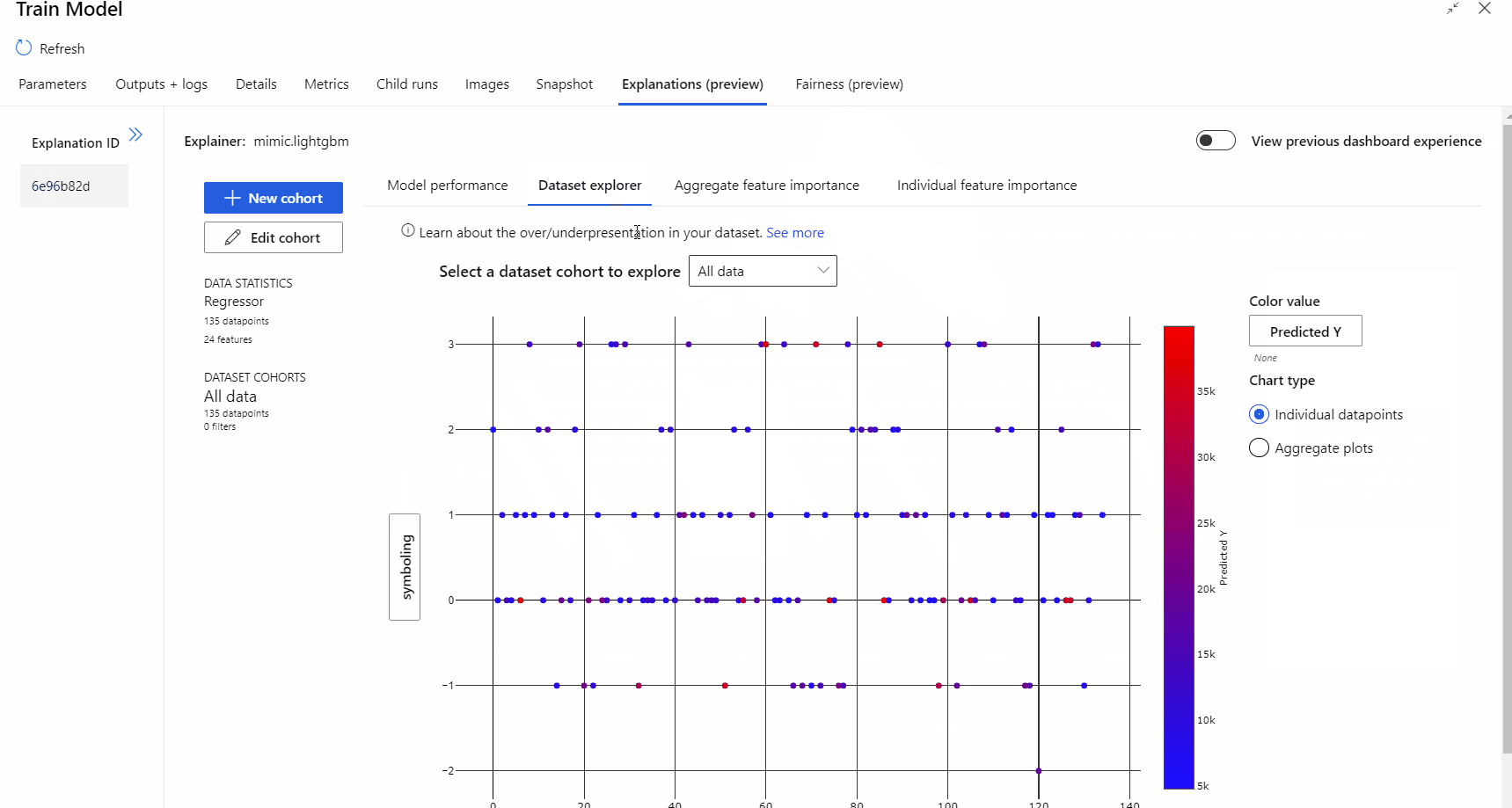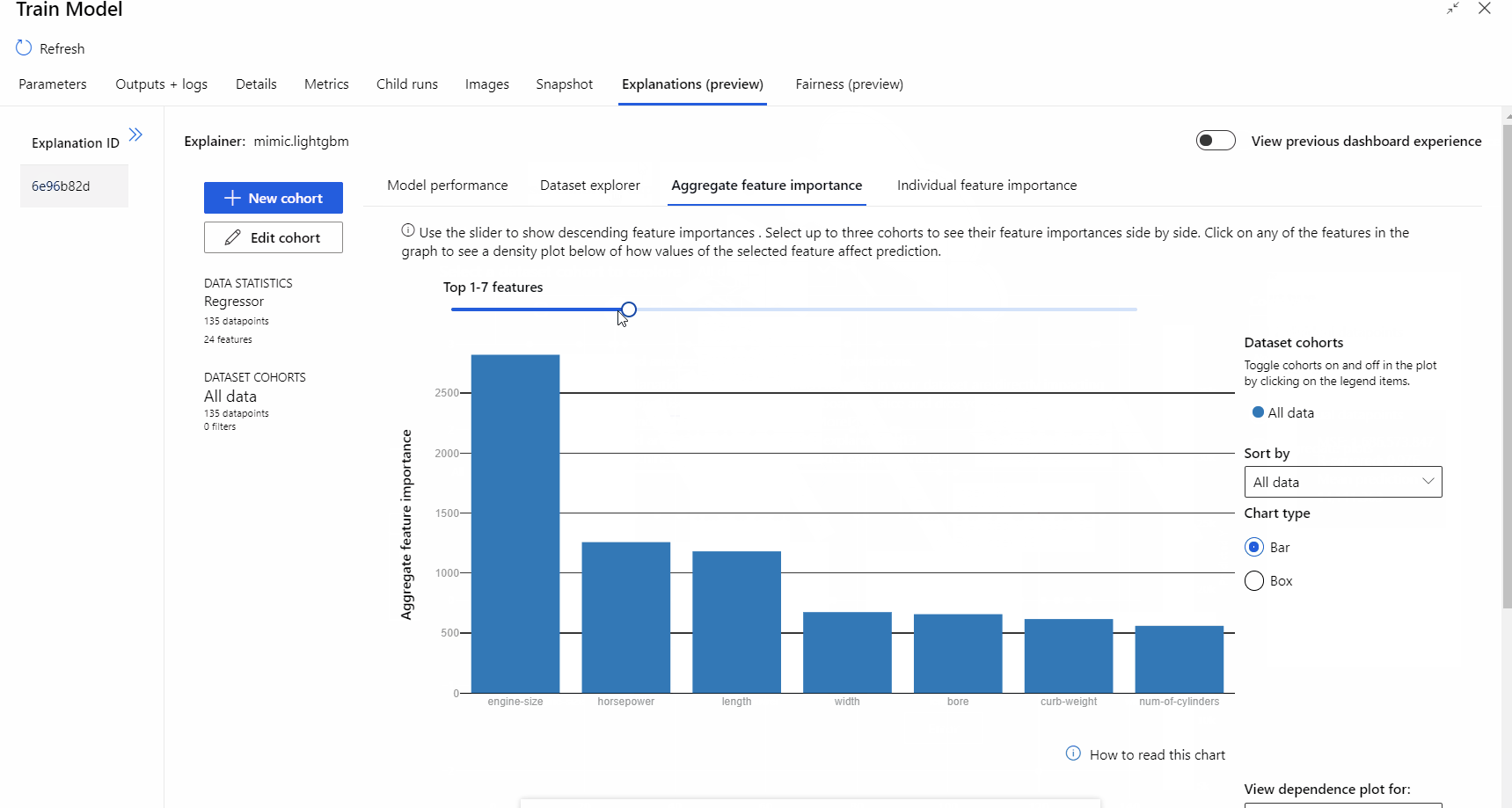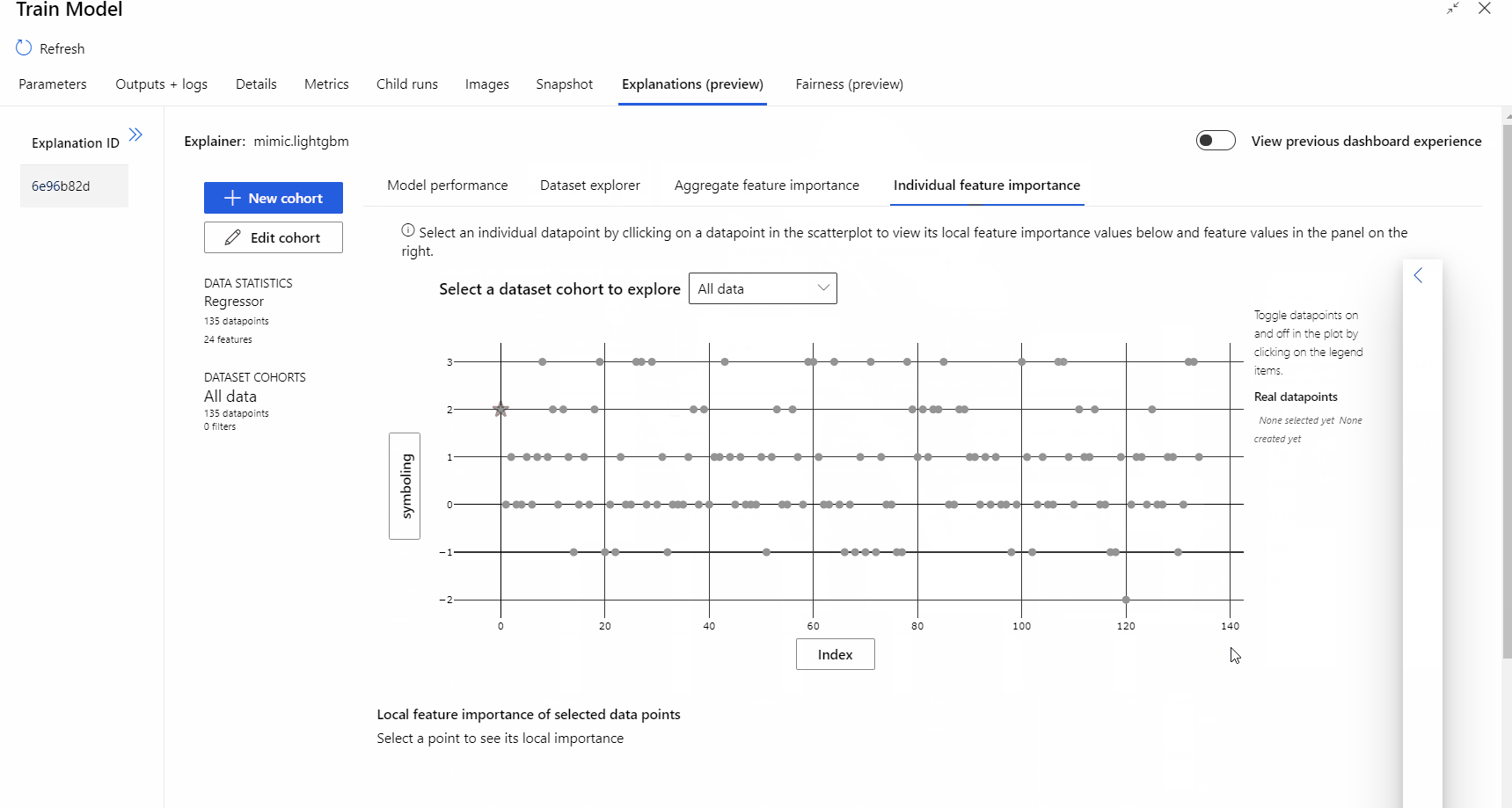
Další informace o používání vysvětlení modelů ve službě Azure Machine Learning najdete v článku s postupy týkajícím se modelů Interpret ML.
Výsledky
Po natrénování modelu:
Pokud chcete použít model v jiných kanálech, vyberte komponentu a vyberte ikonu Zaregistrovat datovou sadu na kartě Výstupy na pravém panelu. K uloženým modelům můžete přistupovat v paletě komponent v části Datové sady.
Pokud chcete model použít při předpovídání nových hodnot, připojte ho ke komponentě Určení skóre modelu spolu s novými vstupními daty.
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.