Extrahování funkcí N-Gram z odkazu na komponentu Text
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning. K featurizaci nestrukturovaných textových dat použijte funkci Extrahovat funkce N-Gram z textové komponenty.
Konfigurace extrahování funkcí N-Gram z textové komponenty
Komponenta podporuje následující scénáře použití slovníku n-gram:
Vytvořte nový n-gramový slovník ze sloupce volného textu.
K featurizaci volného textového sloupce použijte existující sadu textových funkcí .
Určení skóre nebo nasazení modelu , který používá n-gramy
Vytvoření nového slovníku n-gram
Přidejte do kanálu extrahování N-Gram funkcí z textové komponenty a připojte datovou sadu s textem, který chcete zpracovat.
Pomocí sloupce Text vyberte sloupec typu řetězce, který obsahuje text, který chcete extrahovat. Vzhledem k tomu, že výsledky jsou podrobné, můžete zpracovat pouze jeden sloupec najednou.
Nastavte režim slovníku na Vytvořit , abyste označili, že vytváříte nový seznam n-gramových funkcí.
Nastavte velikost N-Gramy, která určuje maximální velikost n-gramů pro extrakci a uložení.
Pokud například zadáte 3, jednogramy, bigramy a trigramy, vytvoří se.
Funkce vážení určuje, jak vytvořit vektor funkce dokumentu a jak extrahovat slovník z dokumentů.
Binární váha: Přiřadí binární hodnotu přítomnosti extrahovaným n-gramům. Hodnota pro každý n-gram je 1, pokud existuje v dokumentu, a 0 jinak.
Hmotnost TF: Přiřadí skóre frekvence termínů (TF) extrahovanému n-gramu. Hodnota pro každý n-gram je jeho četnost výskytu v dokumentu.
Váha IDF: Přiřadí skóre inverzní frekvence dokumentu (IDF) k extrahovanému n-gramu. Hodnota každého n-gramu je protokol velikosti korpusu dělený jeho četností výskytu v celém korpusu.
IDF = log of corpus_size / document_frequencyVáha TF-IDF: Přiřadí skóre frekvence/inverzní frekvence dokumentů (TF/IDF) k extrahovanému n-gramu. Hodnota každého n-gramu je skóre TF vynásobené skóre IDF.
Nastavte minimální délku slova na minimální počet písmen, která lze použít v libovolném slově v n-gramu.
Maximální délka slova slouží k nastavení maximálního počtu písmen, která lze použít v libovolném slově v n-gramu.
Ve výchozím nastavení je povoleno až 25 znaků na slovo nebo token.
Pokud chcete nastavit minimální počet výskytů potřebných pro zahrnutí n-gramu do slovníku n-gram, použijte minimální absolutní frekvenci dokumentu n-gram.
Pokud například použijete výchozí hodnotu 5, musí se v korpusu zahrnout alespoň pětkrát n-gram do slovníku n-gram.
Nastavte maximální poměr n-gram dokumentu k maximálnímu poměru počtu řádků, které obsahují určitý n-gram, nad počtem řádků v celkovém korpusu.
Například poměr 1 by značil, že i když je v každém řádku přítomen určitý n-gram, může být n-gram přidán do slovníku n-gram. Obvykle by se slovo, které se vyskytuje v každém řádku, považováno za slovo šumu a bylo by odebráno. Pokud chcete vyfiltrovat slova šumu závislého na doméně, zkuste tento poměr snížit.
Důležité
Míra výskytu určitých slov není jednotná. Liší se od dokumentu po dokument. Pokud například analyzujete komentáře zákazníků k určitému produktu, může být název produktu velmi vysoký a blízko slova šumu, ale v jiných kontextech to může být významný termín.
Vyberte možnost Normalizovat vektory funkce n-gram pro normalizaci vektorů funkce. Pokud je tato možnost povolená, je každý vektor funkce n-gram rozdělený normou L2.
Odešlete kanál.
Použití existujícího slovníku n-gram
Přidejte do kanálu extrahování n-gramových funkcí a připojte datovou sadu s textem , který chcete zpracovat, k portu datové sady .
Pomocí sloupce Text vyberte textový sloupec, který obsahuje text, který chcete featurizovat. Ve výchozím nastavení komponenta vybere všechny sloupce typu řetězec. Nejlepších výsledků dosáhnete tak, že najednou zpracujete jeden sloupec.
Přidejte uloženou datovou sadu, která obsahuje dříve vygenerovaný slovník n-gram, a připojte ji k portu slovníku Input. Můžete také propojit výstup slovníku Výsledek upstream instance extrahovat funkce N-Gram z textové komponenty.
V případě režimu slovníku vyberte v rozevíracím seznamu možnost Aktualizovat jen pro čtení.
Možnost ReadOnly představuje vstupní korpus pro vstupní slovník. Místo výpočtu četností termínů z nové textové datové sady (na levém vstupu) se použije n-gramové váhy ze vstupního slovníku tak, jak je.
Tip
Tuto možnost použijte při vyhodnocování klasifikátoru textu.
Všechny ostatní možnosti najdete v popisu vlastností v předchozí části.
Odešlete kanál.
Kanál odvozování sestavení, který k nasazení koncového bodu v reálném čase používá n gramy
Trénovací kanál, který obsahuje funkci Extrahovat N gramy z modelu textu a skóre pro predikci testovací datové sady, je sestavená v následující struktuře:
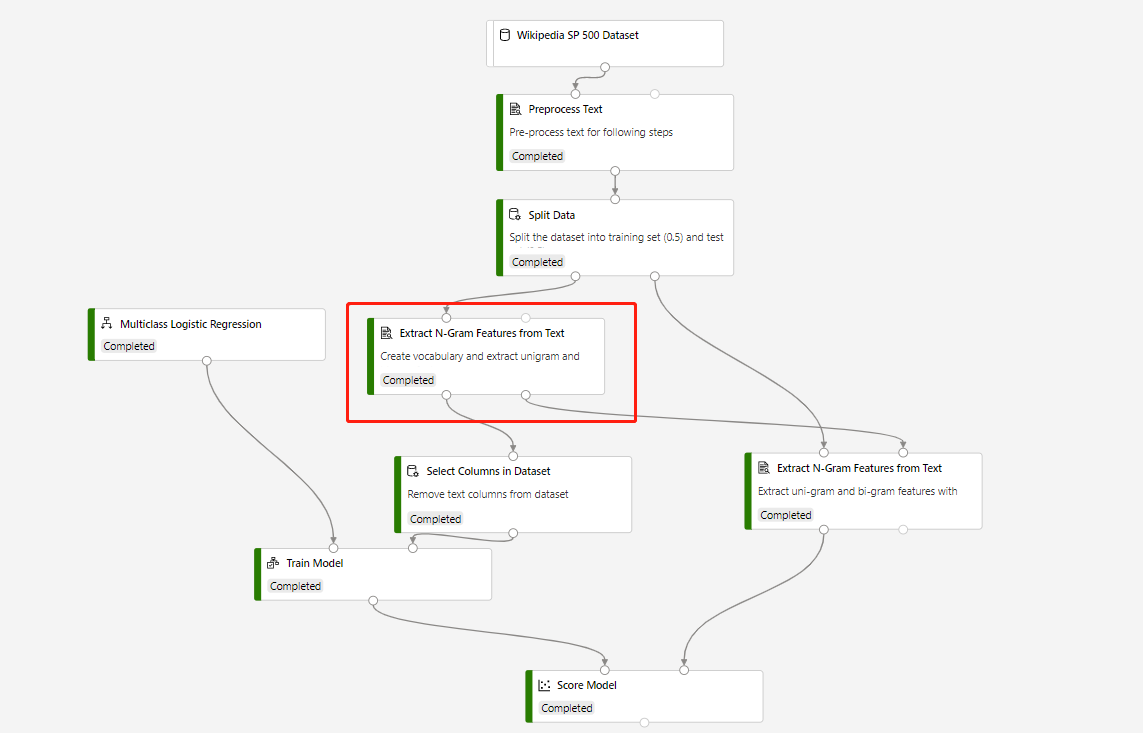
Režim slovníku v kruhové funkci Extrahovat N-Gramy z textové komponenty je Vytvořit a Režim slovníku komponenty, která se připojuje k komponentě Score Model je ReadOnly.
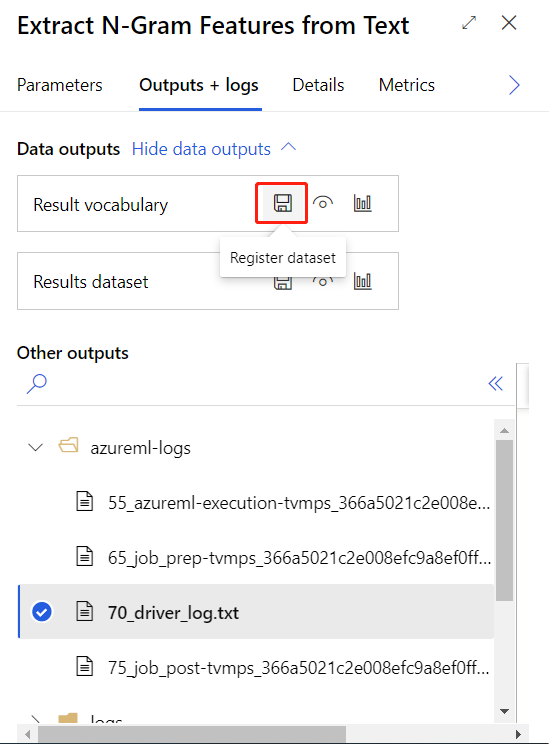
Po úspěšném odeslání trénovacího kanálu můžete jako datovou sadu zaregistrovat výstup zakroužkované komponenty.
Pak můžete vytvořit kanál odvozování v reálném čase. Po vytvoření kanálu odvozování je potřeba kanál odvozování upravit ručně takto:
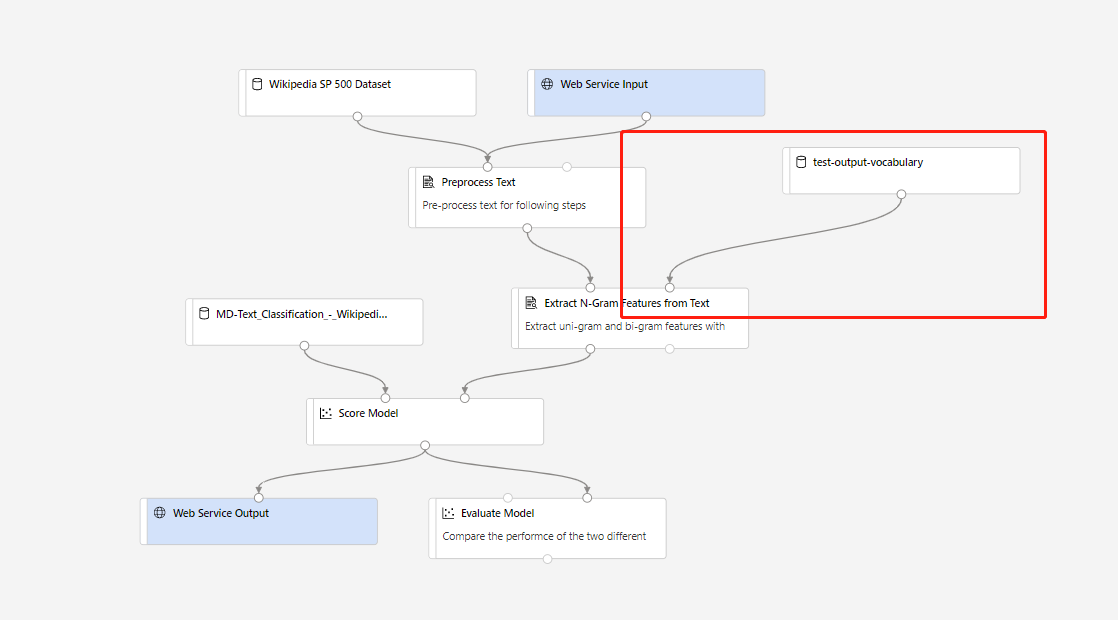
Pak odešlete kanál odvozování a nasaďte koncový bod v reálném čase.
Výsledky
Extrahování funkcí N-Gram z textové komponenty vytvoří dva typy výstupu:
Výsledná datová sada: Tento výstup je souhrn analyzovaného textu v kombinaci s n-gramy, které byly extrahovány. Sloupce, které jste nevybrali v možnosti Textový sloupec , se předávají výstupu. Pro každý sloupec textu, který analyzujete, komponenta generuje tyto sloupce:
- Matice n-gram výskytů: Komponenta generuje sloupec pro každý n-gram nalezený v celkovém korpusu a přidá skóre v každém sloupci, které označuje váhu n-gram pro daný řádek.
Slovní zásoba výsledků: Slovník obsahuje skutečný slovník n-gram společně s skóre četnosti termínů, které se generují jako součást analýzy. Datovou sadu můžete uložit pro opakované použití s jinou sadou vstupů nebo pro pozdější aktualizaci. Můžete také znovu použít slovník pro modelování a bodování.
Výsledek slovníku
Slovník obsahuje slovník n-gram s skóre četnosti termínů, které se generují jako součást analýzy. Skóre DF a IDF se generují bez ohledu na jiné možnosti.
- ID: Identifikátor vygenerovaný pro každý jedinečný n-gram.
- NGram: N-gram. Mezery nebo jiné oddělovače slov se nahradí znakem podtržítka.
- DF: Skóre četnosti pro n-gram v původním korpusu.
- IDF: Inverzní skóre frekvence dokumentu pro n-gram v původním korpusu.
Tuto datovou sadu můžete aktualizovat ručně, ale může docházet k chybám. Příklad:
- Pokud komponenta najde duplicitní řádky se stejným klíčem ve vstupním slovníku, vyvolá se chyba. Ujistěte se, že žádné dva řádky ve slovníku nemají stejné slovo.
- Vstupní schéma datových sad slovníku se musí shodovat přesně, včetně názvů sloupců a typů sloupců.
- Sloupec ID a sloupec DF musí být celočíselného typu.
- Sloupec IDF musí být typu float.
Poznámka:
Nepřipojujte výstup dat k komponentě Train Model přímo. Před odesláním do modelu trénování byste měli odebrat bezplatné textové sloupce. Jinak se bezplatné textové sloupce budou považovat za kategorické funkce.
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.