Parsování nebo blok obsahu pro pracovní postupy v Azure Logic Apps (Preview)
Platí pro: Azure Logic Apps (Consumption + Standard)
Důležité
Tato funkce je ve verzi Preview a podléhá dodatečným podmínkám použití pro microsoft Azure Preview.
Někdy musíte obsah převést na tokeny, což jsou slova nebo bloky znaků, nebo před použitím tohoto obsahu s určitými akcemi rozdělte velký dokument na menší části. Například akce Azure AI Search nebo Azure OpenAI očekávají tokenizovaný vstup a můžou zpracovávat pouze omezený počet tokenů.
V těchto scénářích použijte akce operací s daty s názvem Parsovat dokument a text bloku v pracovním postupu aplikace logiky. Tyto akce transformují obsah, například dokument PDF, soubor CSV, excelový soubor atd., do výstupu tokenizovaného řetězce a potom tento řetězec rozdělí na části na základě počtu tokenů. Tyto výstupy pak můžete odkazovat a používat s dalšími akcemi v pracovním postupu.
Tip
Pokud se chcete dozvědět víc, můžete se zeptat Azure Copilotu na tyto otázky:
- Co je token v AI?
- Co je tokenizovaný vstup?
- Co je výstup tokenizovaného řetězce?
- Co je analýza v AI?
- Co je blok dat v AI?
Pokud chcete najít Azure Copilot, na panelu nástrojů webu Azure Portal vyberte Copilot.
Tento návod ukazuje, jak přidat a nastavit tyto operace ve vašem pracovním postupu.
Známé problémy a omezení
Analýza dokumentu a textových akcí bloků v současné době nepodporuje hostitelské soubory, například sálové a střední uspořádání binárních souborů, jako jsou soubory metody VSAM (Virtual Storage Access Method). Pokud ale pracujete se standardními pracovními postupy, můžete místo toho použít integrovanou akci SOUBOR HOSTITELE IBM s názvem Analyzovat obsah souboru hostitele.
Požadavky
Účet a předplatné Azure. Pokud nemáte předplatné Azure, zaregistrujte si bezplatný účet Azure.
Pracovní postup aplikace logiky Consumption nebo Standard s existujícím triggerem, protože operace Parsování dokumentu a bloku textu jsou k dispozici pouze jako akce. Ujistěte se, že akce, která načte obsah, který chcete analyzovat, nebo blok dat předchází těmto datovým operacím.
Parsování dokumentu
Akce parsování dokumentu převede obsah, například dokument PDF, soubor CSV, excelový soubor atd., na tokenizovaný řetězec. V tomto příkladu předpokládejme, že váš pracovní postup začíná triggerem požadavku s názvem Při přijetí požadavku HTTP. Tento trigger čeká na přijetí požadavku HTTP odeslaného z jiné komponenty, jako je funkce Azure, jiný pracovní postup aplikace logiky atd. Požadavek HTTP obsahuje adresu URL pro nový nahraný dokument, který je k dispozici pro pracovní postup pro načtení a analýzu. Akce HTTP okamžitě následuje za triggerem a odešle požadavek HTTP na adresu URL dokumentu a vrátí obsah dokumentu z jeho umístění úložiště.
Pokud používáte jiné zdroje obsahu, jako je Azure Blob Storage, SharePoint, OneDrive, Systém souborů, FTP atd., můžete zkontrolovat, jestli jsou triggery pro tyto zdroje dostupné. Můžete také zkontrolovat, jestli jsou akce k dispozici pro načtení obsahu pro tyto zdroje. Další informace najdete v tématu Integrované operace a spravované konektory.
Na webu Azure Portal otevřete prostředek aplikace logiky a pracovní postup v návrháři.
Pod existujícím triggerem a akcemi přidejte do pracovního postupu akci Operace s daty s názvem Parsovat dokument.
V návrháři vyberte akci Parsovat dokument .
Jakmile se otevře podokno informací o akci, na kartě Parametry ve vlastnosti Obsah dokumentu zadejte obsah, který chcete parsovat pomocí následujících kroků:
Vyberte uvnitř pole Obsah dokumentu.
Zobrazí se možnosti seznamu dynamického obsahu (ikona blesku) a editoru výrazů (ikona funkce).
Pokud chcete vybrat výstup z předchozí akce, vyberte seznam dynamického obsahu.
Pokud chcete vytvořit výraz, který manipuluje s výstupem z předchozí akce, vyberte editor výrazů.
Tento příklad pokračuje výběrem ikony blesku pro seznam dynamického obsahu.
Po otevření seznamu dynamického obsahu vyberte požadovaný výstup z předchozí operace.
V tomto příkladu akce Parsovat dokument odkazuje na základní výstup z akce HTTP .
Výstup textu se teď zobrazí v poli Obsah dokumentu:
Pod akci Parsovat dokument přidejte akce, které chcete pracovat s výstupem tokenizovaného řetězce, například text bloku dat, který tento průvodce popisuje později.
Parsování dokumentu – referenční dokumentace
Parametry
| Jméno | Hodnota | Datový typ | Popis | Limit |
|---|---|---|---|---|
| Obsah dokumentu | < content-to-parse> | Všechny | Obsah, který se má analyzovat. | Nic |
Výstupy
| Name | Datový typ | Popis |
|---|---|---|
| Analyzovaný text výsledku | Pole řetězců | Pole řetězců. |
| Parsovaný výsledek | Objekt | Objekt, který obsahuje celý analyzovaný text. |
Text bloku dat
Akce bloku textu rozdělí obsah na menší části pro následné akce, které se lépe použijí v aktuálním pracovním postupu. Následující kroky vycházejí z příkladu z části Analýza dokumentu a rozdělí výstup řetězce tokenu pro použití s operacemi Azure AI, které očekávají tokenizované malé bloky obsahu.
Poznámka:
Předchozí akce, které používají bloky dat, nemají vliv na akci bloku textu, ani akce bloku dat nemá vliv na následné akce, které používají bloky dat.
Na webu Azure Portal otevřete prostředek aplikace logiky a pracovní postup v návrháři.
V části Parsovat akci dokumentu přidejte pomocí těchto obecných kroků akci Operace s daty s názvem Text bloku dat.
V návrháři vyberte akci Blok textu .
Jakmile se otevře podokno s informacemi o akci, na kartě Parametry u vlastnosti Strategie vytváření bloků dat vyberte tokenSize jako metodu bloku dat, pokud ještě není vybraná.
Strategie Popis TokenSize Rozdělte zadaný obsah na základě počtu tokenů. Po výběru strategie vyberte uvnitř textového pole a určete obsah pro bloky dat.
Zobrazí se možnosti seznamu dynamického obsahu (ikona blesku) a editoru výrazů (ikona funkce).
Pokud chcete vybrat výstup z předchozí akce, vyberte seznam dynamického obsahu.
Pokud chcete vytvořit výraz, který manipuluje s výstupem z předchozí akce, vyberte editor výrazů.
Tento příklad pokračuje výběrem ikony blesku pro seznam dynamického obsahu.
Po otevření seznamu dynamického obsahu vyberte požadovaný výstup z předchozí operace.
V tomto příkladu akce Blok textu odkazuje na výstup analyzovaného výsledku z akce Parsovat dokument .
V textovémpoli se teď zobrazuje výstup akce parsovaný výsledek:
Dokončete nastavení akce Blok textu na základě vybrané strategie a scénáře. Další informace naleznete v tématu Blok textu – referenční informace.
Když teď přidáte další akce, které očekávají a používají tokenizovaný vstup, jako jsou akce Azure AI, vstupní obsah se naformátuje pro snadnější spotřebu.
Text bloku dat – referenční dokumentace
Parametry
| Jméno | Hodnota | Datový typ | Popis | Omezení |
|---|---|---|---|---|
| Strategie vytváření bloků dat | TokenSize | Výčet řetězců | Rozdělte obsah na základě počtu tokenů. Výchozí: TokenSize |
Nelze použít |
| Text | < content-to-chunk> | Všechny | Obsah, který se má vytvořit. | Průvodce referenčními informacemi o omezeních a konfiguraci |
| Kódovací model | < encoding-method> | Výčet řetězců | Model kódování, který se má použít: - Výchozí: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) Další informace najdete v tématu OpenAI – Přehled modelů. |
Nelze použít |
| TokenSize | < max-tokens-per-chunk> | Celé číslo | Maximální počettokench Výchozí: Žádné |
Minimum: 1 Maximum: 8000 |
| PageOverlapLength | < počet překrývajících se znaků> | Celé číslo | Počet znaků od konce předchozího bloku dat, které se mají zahrnout do dalšího bloku dat. Toto nastavení vám pomůže vyhnout se ztrátě důležitých informací při rozdělení obsahu do bloků dat a zachování kontinuity a kontextu mezi bloky dat. Výchozí hodnota: 0 – Neexistují žádné překrývající se znaky. |
Minimum: 0 |
Tip
Pokud se chcete dozvědět víc, můžete se zeptat Azure Copilotu na tyto otázky:
- Co je PageOverlapLength v blonkingu?
- Co je kódování v Azure AI?
Pokud chcete najít Azure Copilot, na panelu nástrojů webu Azure Portal vyberte Copilot.
Výstupy
| Name | Datový typ | Popis |
|---|---|---|
| Blokované textové položky výsledku | Pole řetězců | Pole řetězců. |
| Položka textových položek s blokem dat | String | Jeden řetězec v poli. |
| Výsledek bloku dat | Objekt | Objekt, který obsahuje celý blokovaný text. |
Ukázkový pracovní postup
Následující příklad obsahuje další akce, které vytvoří úplný vzor pracovního postupu pro příjem dat z libovolného zdroje:
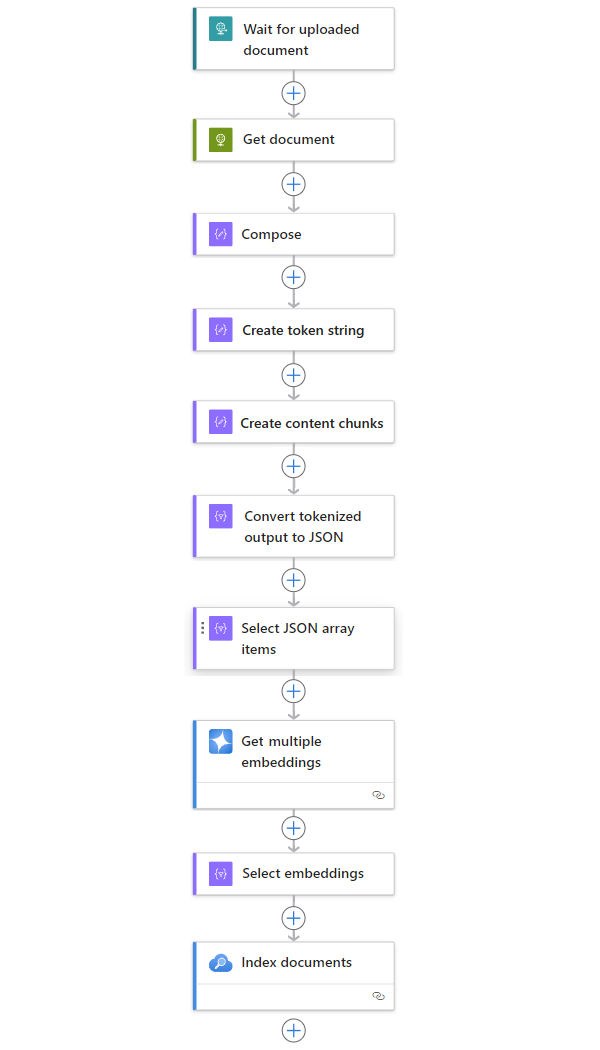
| Krok | Úloha | Základní operace | Popis |
|---|---|---|---|
| 1 | Počkejte nebo zkontrolujte nový obsah. | Při přijetí požadavku HTTP | Trigger, který buď dotazuje nebo čeká na doručení nových dat, buď na základě plánovaného opakování, nebo v reakci na konkrétní události. Taková událost může být nový soubor, který se nahraje do konkrétního systému úložiště, jako je Azure Blob Storage, SharePoint, OneDrive, Systém souborů, FTP atd. V tomto příkladu operace triggeru požadavku čeká na požadavek HTTP nebo HTTPS odeslaný z jiného koncového bodu. Požadavek obsahuje adresu URL nového nahraného dokumentu. |
| 2 | Získejte obsah. | HTTP | Akce HTTP, která načte nahraný dokument pomocí adresy URL souboru z výstupu triggeru. |
| 3 | Vytvoření podrobností dokumentu | Compose (Sestavení) |
Akce operace s daty, která zřetězí různé položky. Tento příklad zřetězí informace o klíč-hodnota dokumentu. |
| 4 | Vytvořte řetězec tokenu. | Parsování dokumentu | Akce Operace s daty, která vytvoří tokenizovaný řetězec pomocí výstupu akce Vytvořit. |
| 5 | Vytváření bloků obsahu | Text bloku dat | Akce Operace s daty, která rozdělí řetězec tokenu na části na základě počtu tokenů na kusy obsahu. |
| 6 | Převeďte tokenizovaný a blokovaný text na JSON. | Parsování formátu JSON | Akce Operace s daty, která převádí blokovaný výstup na pole JSON. |
| 7 | Vyberte položky pole JSON. | Vybrat | Akce operace s daty, která vybere více položek z pole JSON. |
| 8 | Vygenerujte vložené možnosti. | Získání více vložených objektů | Akce Azure OpenAI, která vytvoří vkládání pro každou položku pole JSON. |
| 9 | Vyberte vkládání a další informace. | Vybrat | Akce operace s daty, která vybere vkládání a další informace o dokumentu. |
| 10 | Indexujte data. | Indexování dokumentů | Akce Azure AI Search, která indexuje data na základě každého vybraného vkládání. |