Vytvoření bloků velkých dokumentů pro řešení vektorového vyhledávání ve službě Azure AI Search
Dělení velkých dokumentů na menší bloky dat vám může pomoct zůstat pod maximálními limity vstupu tokenů vložených modelů. Například maximální délka vstupního textu pro model Azure OpenAI embedding-ada-002 je 8 191 tokenů. Vzhledem k tomu, že každý token je přibližně čtyři znaky textu pro běžné modely OpenAI, je toto maximální omezení ekvivalentní přibližně 6 000 slovům textu. Pokud tyto modely používáte ke generování vložených objektů, je důležité, aby vstupní text zůstal pod limitem. Rozdělením obsahu do bloků dat zajistíte, že data mohou být zpracována vloženými modely a že neztratíte informace kvůli zkrácení.
Doporučujeme integrované vektorizace pro předdefinované bloky dat a vkládání. Integrovaná vektorizace využívá závislost na indexerech, sadách dovedností, dovednostech rozdělení textu a dovednostech vkládání, jako je dovednost Azure OpenAI Embedding. Pokud nemůžete použít integrovanou vektorizaci, tento článek popisuje některé přístupy k vytváření bloků obsahu.
Běžné techniky vytváření bloků dat
Bloky dat se vyžadují jenom v případě, že jsou zdrojové dokumenty příliš velké pro maximální velikost vstupu uloženou modely.
Tady jsou některé běžné techniky vytváření bloků dat, počínaje nejčastěji používanou metodou:
Bloky s pevnou velikostí: Definujte pevnou velikost, která je dostatečná pro sémanticky smysluplné odstavce (například 200 slov) a umožňuje určité překrytí (například 10–15 % obsahu) vytvořit dobré bloky dat jako vstup pro vkládání generátorů vektorů.
Bloky dat s proměnlivou velikostí založené na obsahu: Rozdělte data na základě charakteristik obsahu, jako jsou interpunkční znaménka konce věty, značky na konci řádku nebo použití funkcí v knihovnách zpracování přirozeného jazyka (NLP). K rozdělení dat je možné použít také strukturu jazyka Markdown.
Přizpůsobte nebo iterujte některou z výše uvedených technik. Například při práci s velkými dokumenty můžete použít bloky dat s proměnlivou velikostí, ale také připojit název dokumentu k blokům dat uprostřed dokumentu, abyste zabránili ztrátě kontextu.
Důležité informace o překrývání obsahu
Při vytváření bloků dat může zachování kontextu pomoct překrývající se malý objem textu mezi bloky dat. Doporučujeme začít s překrytím přibližně 10 %. Například s pevnou velikostí bloku 256 tokenů byste začali testovat s překrytím 25 tokenů. Skutečné množství překrývání se liší v závislosti na typu dat a konkrétním případu použití, ale zjistili jsme, že 10–15 % funguje v mnoha scénářích.
Faktory pro vytváření bloků dat
Pokud jde o vytváření bloků dat, zamyslete se nad těmito faktory:
Tvarování a hustota dokumentů Pokud potřebujete nedotčený text nebo pasáže, větší bloky dat a bloky proměnných, které zachová strukturu vět, můžou dosáhnout lepších výsledků.
Dotazy uživatelů: Větší bloky dat a překrývající se strategie pomáhají zachovat kontext a sémantickou bohatost pro dotazy, které cílí na konkrétní informace.
Velké jazykové modely (LLM) mají pokyny k výkonu pro velikost bloků dat. Potřebujete nastavit velikost bloku, která nejlépe vyhovuje všem modelům, které používáte. Pokud například používáte modely pro sumarizaci a vkládání, zvolte optimální velikost bloku, která funguje pro obojí.
Jak se bloky dat zapadnou do pracovního postupu
Pokud máte velké dokumenty, musíte do indexování vložit krok bloku dat a pracovní postupy dotazů, které rozdělí velký text. Při použití integrované vektorizace se použije výchozí strategie vytváření bloků dat pomocí dovednosti Rozdělení textu. Vlastní strategii vytváření bloků dat můžete použít také pomocí vlastní dovednosti. Mezi knihovny, které poskytují bloky dat, patří:
Většina knihoven poskytuje běžné techniky vytváření bloků dat pro pevnou velikost, velikost proměnné nebo kombinaci. Můžete také zadat překrytí, které duplikuje malé množství obsahu v každém bloku dat pro zachování kontextu.
Příklady bloků dat
Následující příklady ukazují, jak se strategie bloků dat použijí na soubor PDF se zemí NASA at Night:
Příklad dovednosti rozdělení textu
Integrace bloků dat prostřednictvím dovednosti Rozdělení textu je obecně dostupná.
Tato část popisuje předdefinované bloky dat pomocí přístupu řízeného dovednostmi a parametrů dovednosti rozdělení textu.
Ukázkový poznámkový blok pro tento příklad najdete v úložišti azure-search-vector-samples .
Nastavení textSplitMode rozdělení obsahu na menší bloky dat:
pages(výchozí). Bloky dat se skládají z několika vět.sentences. Bloky se skládají z jednoduchých vět. To, co představuje větu, je závislý na jazyce. V angličtině se používá standardní interpunkční interpunkce, jako je nebo.!je použita. Jazyk je řízen parametremdefaultLanguageCode.
Parametr pages přidá další parametry:
maximumPageLengthdefinuje maximální počet znaků 1 nebo tokenů 2 v každém bloku dat. Rozdělovač textu zabraňuje rozdělení vět, takže skutečný počet znaků závisí na obsahu.pageOverlapLengthdefinuje, kolik znaků od konce předchozí stránky je zahrnuto na začátku další stránky. Pokud je tato hodnota nastavená, musí být menší než polovina maximální délky stránky.maximumPagesToTakedefinuje, kolik stránek nebo bloků dat má být odebráno z dokumentu. Výchozí hodnota je 0, což znamená, že se z dokumentu přebírají všechny stránky nebo bloky dat.
1 Znaky nejsou v souladu s definicí tokenu. Počet tokenů měřených llm se může lišit od velikosti znaků měřené dovedností Rozdělení textu.
2 Bloky tokenů jsou k dispozici ve verzi 2024-09-01-Preview a obsahují další parametry pro zadání tokenizátoru a všech tokenů, které by se neměly během vytváření bloků rozdělit.
Následující tabulka ukazuje, jak volba parametrů ovlivňuje celkový počet bloků dat ze Země v noční elektronické knize:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Celkový počet bloků dat |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
– | N/A | 13361 |
textSplitMode pages Použití výsledků ve většině bloků dat, které mají celkový počet znaků blízko maximumPageLength. Počet znaků bloku se liší podle rozdílů v tom, kde hranice vět spadají do bloku dat. Délka tokenu bloku dat se liší kvůli rozdílům v obsahu bloku dat.
Následující histogramy ukazují, jak rozdělení délky znaků bloku dat porovnává s délkou tokenu bloku bloků dat pro gpt-35-turbo při použití pagestextSplitMode , z roku maximumPageLength 2000 a pageOverlapLength 500 na Zemi v noci e-book:
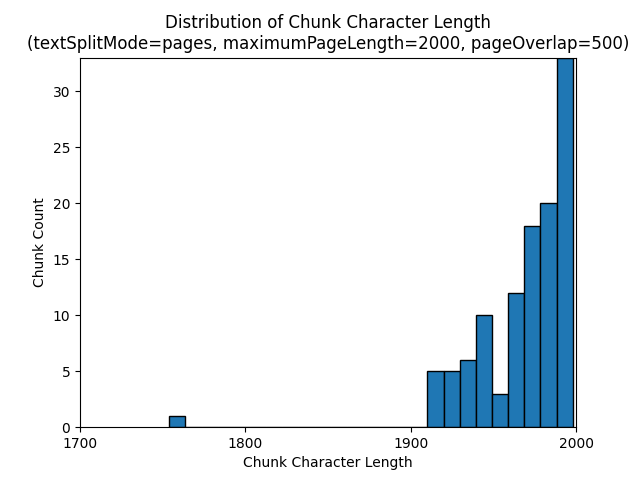
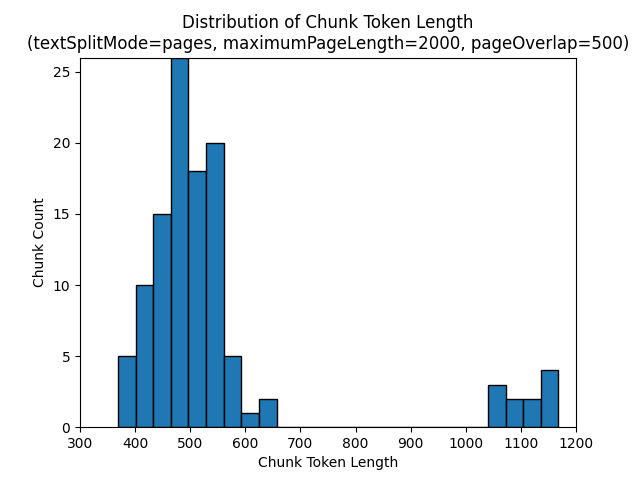
textSplitMode sentences Použití výsledků ve velkém počtu bloků dat, které se skládají z jednotlivých vět. Tyto bloky dat jsou výrazně menší než ty, které pagesvytváří , a počet tokenů bloků se více shoduje s počty znaků.
Následující histogramy ukazují, jak rozdělení délky znaků bloku dat porovnává s délkou tokenu bloku bloků dat pro gpt-35-turbo při použití na textSplitMode sentences Zemi v noci e-book:
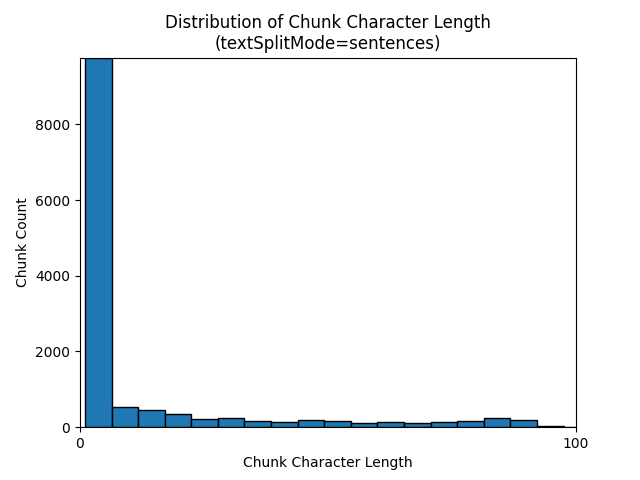
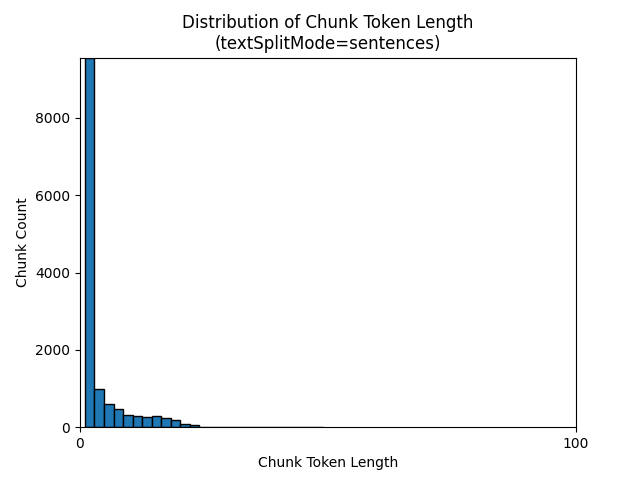
Optimální volba parametrů závisí na tom, jak se budou bloky dat používat. U většiny aplikací se doporučuje začít s následujícími výchozími parametry:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Příklad vytváření bloků dat jazyka LangChain
LangChain poskytuje zavaděče dokumentů a rozdělovače textu. Tento příklad ukazuje, jak načíst PDF, získat počty tokenů a nastavit rozdělovač textu. Získání počtu tokenů vám pomůže učinit informované rozhodnutí o velikosti bloků dat.
Ukázkový poznámkový blok pro tento příklad najdete v úložišti azure-search-vector-samples .
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Výstup označuje 200 dokumentů nebo stránek v PDF.
Pokud chcete získat odhadovaný počet tokenů pro tyto stránky, použijte TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Výstup označuje, že žádné stránky nemají žádné tokeny, průměrná délka tokenu na stránku je 189 tokenů a maximální počet tokenů každé stránky je 1 583.
Znalost průměrné a maximální velikosti tokenu vám poskytne přehled o nastavení velikosti bloku dat. I když byste mohli použít standardní doporučení 2000 znaků s překrytím 500 znaků, je v tomto případě vhodné snížit počet tokenů ukázkového dokumentu. Nastavení příliš velké hodnoty překrytí může ve skutečnosti způsobit, že se vůbec nezobrazí žádné překrytí.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Výstup dvou po sobě jdoucích bloků dat zobrazuje text z prvního bloku překrývajícího se na druhý blok dat. Výstup je mírně upravován pro čitelnost.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Vlastní dovednost
Ukázka generování bloků dat s pevnou velikostí a vkládání ukazuje generování bloků dat i vektorového vkládání pomocí modelů vkládání Azure OpenAI. Tato ukázka používá vlastní dovednost Azure AI Search v úložišti Power Skills k zabalení kroku bloku dat.