Použití nástroje MirrorMaker k replikaci témat Apache Kafka s využitím platformy Kafka ve službě HDInsight
Naučte se používat funkci zrcadlení Apache Kafka k replikaci témat do sekundárního clusteru. Zrcadlení můžete spustit jako nepřetržitý proces nebo přerušovaně a migrovat data z jednoho clusteru do druhého.
V tomto článku použijete zrcadlení k replikaci témat mezi dvěma clustery HDInsight. Tyto clustery jsou v různých virtuálních sítích v různých datacentrech.
Upozornění
Nepoužívejte zrcadlení jako prostředek k dosažení odolnosti proti chybám. Posun k položkám v rámci tématu se mezi primárním a sekundárním clusterem liší, takže klienti nemůžou tyto dva clustery zaměnit. Pokud máte obavy o odolnost proti chybám, měli byste nastavit replikaci pro témata v rámci vašeho clusteru. Další informace najdete v tématu Začínáme s Apache Kafka ve službě HDInsight.
Jak funguje zrcadlení Apache Kafka
Zrcadlení funguje pomocí nástroje MirrorMaker , který je součástí Apache Kafka. MirrorMaker využívá záznamy z témat v primárním clusteru a pak vytvoří místní kopii v sekundárním clusteru. MirrorMaker používá jednoho nebo více příjemců , kteří čtou z primárního clusteru, a producenta , který zapisuje do místního (sekundárního) clusteru.
Nejužitečnější nastavení zrcadlení pro zotavení po havárii používá clustery Kafka v různých oblastech Azure. Aby toho bylo dosaženo, jsou virtuální sítě, ve kterých se nacházejí clustery, vzájemně propojené.
Následující diagram znázorňuje proces zrcadlení a tok komunikace mezi clustery:
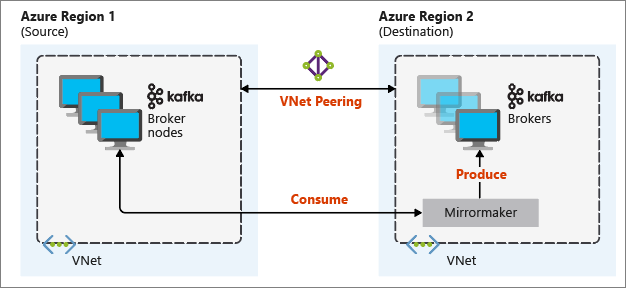
Primární a sekundární clustery se můžou lišit v počtu uzlů a oddílů a liší se také posuny v rámci témat. Zrcadlení udržuje hodnotu klíče, která se používá k dělení, takže pořadí záznamů se zachová na základě jednotlivých klíčů.
Zrcadlení přes hranice sítě
Pokud potřebujete zrcadlit mezi clustery Kafka v různých sítích, je potřeba vzít v úvahu následující další aspekty:
Brány: Sítě musí být schopné komunikovat na úrovni protokolu TCP/IP.
Adresování serverů: Uzly clusteru můžete adresovat pomocí jejich IP adres nebo plně kvalifikovaných názvů domén.
IP adresy: Pokud nakonfigurujete clustery Kafka tak, aby používaly reklamu na IP adresy, můžete pokračovat v nastavení zrcadlení pomocí IP adres zprostředkovatelů a uzlů ZooKeeper.
Názvy domén: Pokud nenakonfigurujete clustery Kafka pro inzerování IP adres, musí být clustery schopné se vzájemně připojit pomocí plně kvalifikovaných názvů domén (FQDN). To vyžaduje server DNS (Domain Name System) v každé síti, který je nakonfigurovaný tak, aby předával požadavky do ostatních sítí. Při vytváření virtuální sítě Azure místo automatického DNS poskytovaného se sítí musíte zadat vlastní server DNS a IP adresu serveru. Po vytvoření virtuální sítě musíte vytvořit virtuální počítač Azure, který tuto IP adresu používá. Pak na něj nainstalujete a nakonfigurujete software DNS.
Důležité
Před instalací SLUŽBY HDInsight do virtuální sítě vytvořte a nakonfigurujte vlastní server DNS. Aby služba HDInsight používala server DNS nakonfigurovaný pro virtuální síť, nevyžaduje žádnou další konfiguraci.
Další informace o propojení dvou virtuálních sítí Azure najdete v tématu Konfigurace připojení.
Architektura zrcadlení
Tato architektura obsahuje dva clustery v různých skupinách prostředků a virtuálních sítích: primární a sekundární.
Postup vytvoření
Vytvořte dvě nové skupiny prostředků:
Skupina prostředků Umístění kafka-primary-rg USA – střed kafka-secondary-rg USA – středosever Vytvořte novou virtuální síť kafka-primary-vnet v systému kafka-primary-rg. Ponechte výchozí nastavení.
Vytvořte novou virtuální síť kafka-secondary-vnet v systému kafka-secondary-rg, také s výchozím nastavením.
Vytvořte dva nové clustery Kafka:
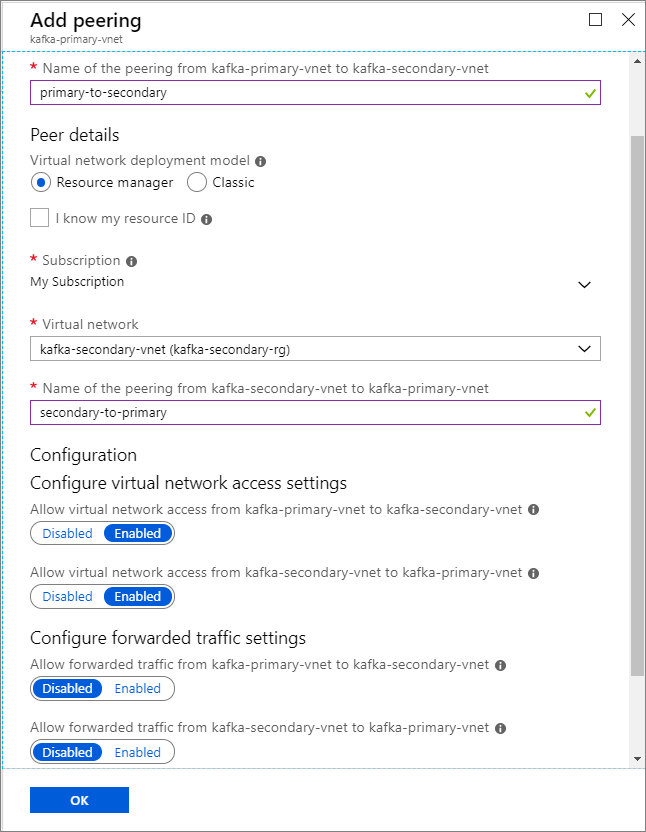
Název clusteru Skupina prostředků Virtuální síť Účet úložiště kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka -secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Vytvořte partnerské vztahy virtuálních sítí. V tomto kroku se vytvoří dva partnerské vztahy: jeden z kafka-primary-vnet na kafka-secondary-vnet a druhý z kafka-secondary-vnet na kafka-primary-vnet.
Vyberte virtuální síť kafka-primary-vnet .
V části Nastavení vyberte Partnerské vztahy.
Vyberte Přidat.
Na obrazovce Přidat partnerský vztah zadejte podrobnosti, jak je znázorněno na následujícím snímku obrazovky.
Konfigurace inzerce PROTOKOLU IP
Nakonfigurujte inzerci PROTOKOLU IP tak, aby se klient mohl připojit pomocí IP adres zprostředkovatele místo názvů domén.
Přejděte na řídicí panel Ambari primárního clusteru:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Vyberte Služby>Kafka. Vyberte kartu Konfigurace .
Do dolní části šablony kafka-env přidejte následující řádky konfigurace. Vyberte Uložit.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesNa obrazovce Uložit konfiguraci zadejte poznámku a vyberte Uložit.
Pokud se zobrazí upozornění konfigurace, vyberte Přesto pokračovat.
V části Uložit změny konfigurace vyberte OK.
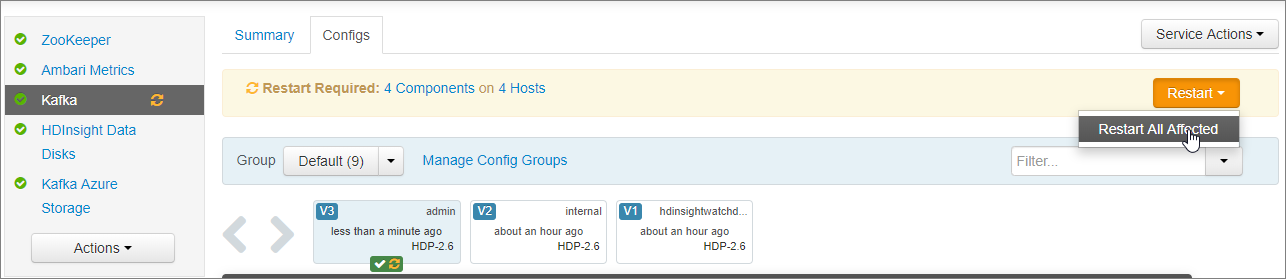
V oznámení Restartovat požadované vyberte Restartovat>všechny ovlivněné. Pak vyberte Potvrdit Restartovat vše.
Konfigurace platformy Kafka pro naslouchání na všech síťových rozhraních
- Zůstaňte na kartě Konfigurace v části Služby>Kafka. V části Kafka Broker nastavte vlastnost naslouchacího procesu na
PLAINTEXT://0.0.0.0:9092hodnotu . - Vyberte Uložit.
- Vyberte Restart ConfirmRestart All (Restartovat> vše).
Záznam IP adres zprostředkovatele a adres ZooKeeper pro primární cluster
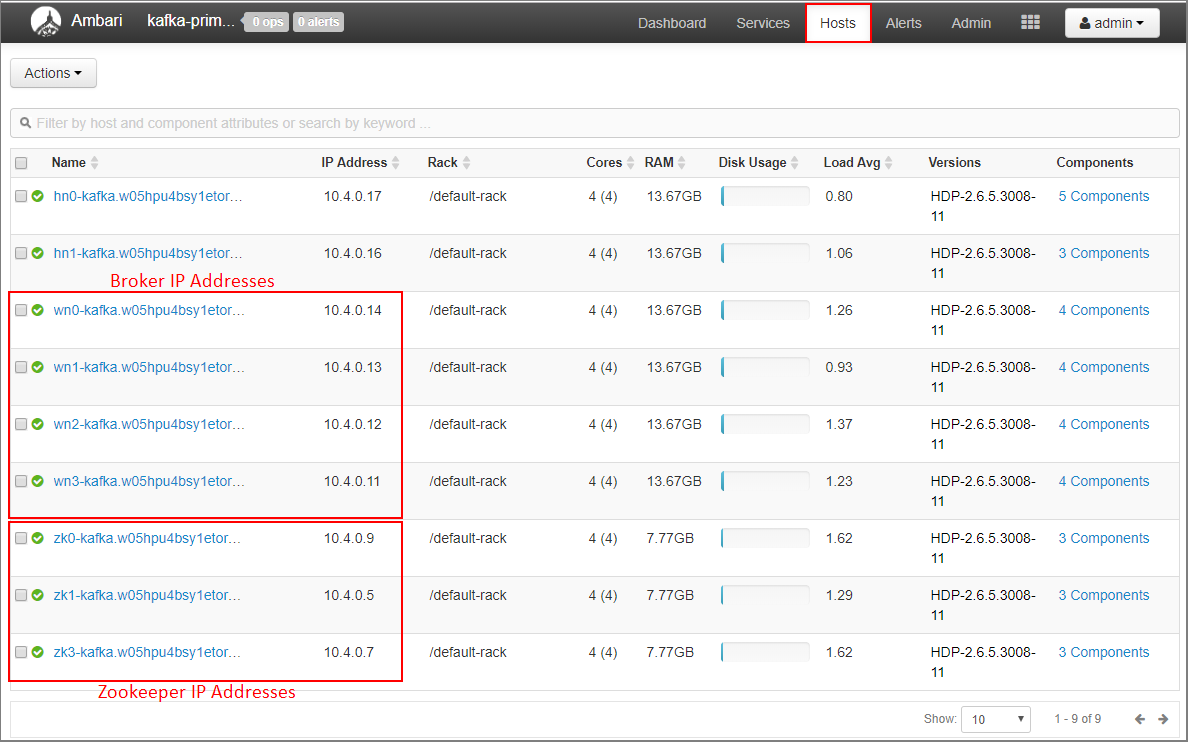
Na řídicím panelu Ambari vyberte Hostitelé .
Poznamenejte si IP adresy zprostředkovatelů a zookeeperů. Zprostředkovatelské uzly mají první dvě písmena názvu hostitele a uzly ZooKeeper mají jako první dvě písmena názvu hostitele zk .
Opakujte předchozí tři kroky pro druhý cluster kafka-secondary-cluster: nakonfigurujte inzerci PROTOKOLU IP, nastavte naslouchací procesy a poznamenejte si IP adresy zprostředkovatele a ZooKeeperu.
Vytváření témat
Připojte se k primárnímu clusteru pomocí SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netNahraďte
sshuseruživatelským jménem SSH, které jste použili při vytváření clusteru. NahraďtePRIMARYCLUSTERzákladním názvem, který jste použili při vytváření clusteru.Další informace najdete v tématu Použití SSH se službou HDInsight.
Pomocí následujícího příkazu vytvořte dvě proměnné prostředí s hostiteli Apache ZooKeeper a zprostředkovatelskými hostiteli pro primární cluster. Nahraďte řetězce jako
ZOOKEEPER_IP_ADDRESS1skutečnými DŘÍVE zaznamenanými IP adresami, například10.23.0.11a10.23.0.7. Totéž platí proBROKER_IP_ADDRESS1. Pokud používáte překlad plně kvalifikovaných názvů domén s vlastním serverem DNS, pomocí následujícího postupu získejte názvy zprostředkovatele a ZooKeeperu.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'K vytvoření tématu s názvem
testtopicpoužijte následující příkaz:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSPomocí následujícího příkazu ověřte, že se téma vytvořilo:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSOdpověď obsahuje
testtopic.Pomocí následujícího postupu můžete zobrazit informace o hostiteli zprostředkovatele pro tento (primární) cluster:
echo $PRIMARY_BROKERHOSTSVrátí se informace podobné následujícímu textu:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Tyto informace si uložte. Použije se v další části.
Konfigurace zrcadlení
Připojte se k sekundárnímu clusteru pomocí jiné relace SSH:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netNahraďte
sshuseruživatelským jménem SSH, které jste použili při vytváření clusteru. NahraďteSECONDARYCLUSTERnázvem, který jste použili při vytváření clusteru.Další informace najdete v tématu Použití SSH se službou HDInsight.
Ke konfiguraci komunikace s primárním clusterem
consumer.propertiespoužijte soubor . K vytvoření souboru použijte následující příkaz:nano consumer.propertiesJako obsah
consumer.propertiessouboru použijte následující text:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupNahraďte
PRIMARY_BROKERHOSTSIP adresami hostitele zprostředkovatele z primárního clusteru.Tento soubor popisuje informace o spotřebiteli, které se mají použít při čtení z primárního clusteru Kafka. Další informace najdete v tématu Konfigurace příjemců na adrese
kafka.apache.org.Pokud chcete soubor uložit, stiskněte Ctrl+X, Y a pak enter.
Před konfigurací producenta, který komunikuje se sekundárním clusterem, nastavte proměnnou pro IP adresy zprostředkovatele sekundárního clusteru. K vytvoření této proměnné použijte následující příkazy:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Příkaz
echo $SECONDARY_BROKERHOSTSby měl vrátit informace podobné následujícímu textu:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Ke komunikaci sekundárního clusteru
producer.propertiespoužijte soubor. K vytvoření souboru použijte následující příkaz:nano producer.propertiesJako obsah
producer.propertiessouboru použijte následující text:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneNahraďte
SECONDARY_BROKERHOSTSIP adresami zprostředkovatele, které jste použili v předchozím kroku.Další informace najdete v tématu Konfigurace producenta na adrese
kafka.apache.org.Pomocí následujících příkazů vytvořte proměnnou prostředí s IP adresami hostitelů ZooKeeper pro sekundární cluster:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'Výchozí konfigurace kafka ve službě HDInsight neumožňuje automatické vytváření témat. Před zahájením procesu zrcadlení musíte použít jednu z následujících možností:
Vytvoření témat v sekundárním clusteru: Tato možnost umožňuje také nastavit počet oddílů a faktor replikace.
Témata můžete vytvořit předem pomocí následujícího příkazu:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSNahraďte
testtopicnázvem tématu, které chcete vytvořit.Konfigurace clusteru pro automatické vytváření témat: Tato možnost umožňuje nástroji MirrorMaker automaticky vytvářet témata. Upozorňujeme, že je může vytvořit s jiným počtem oddílů nebo jiným faktorem replikace než primární téma.
Pokud chcete nakonfigurovat sekundární cluster tak, aby automaticky vytvářel témata, postupujte takto:
- Přejděte na řídicí panel Ambari pro sekundární cluster:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Vyberte Services>Kafka. Pak vyberte kartu Konfigurace .
- Do pole Filtr zadejte hodnotu
auto.create. Tím se vyfiltruje seznam vlastností a zobrazí seauto.create.topics.enablenastavení. - Změňte hodnotu
auto.create.topics.enablenatruea pak vyberte Uložit. Přidejte poznámku a pak znovu vyberte Uložit . - Vyberte službu Kafka , vyberte Restartovat a pak vyberte Restartovat všechny ovlivněné. Po zobrazení výzvy vyberte Potvrdit restartování všech.
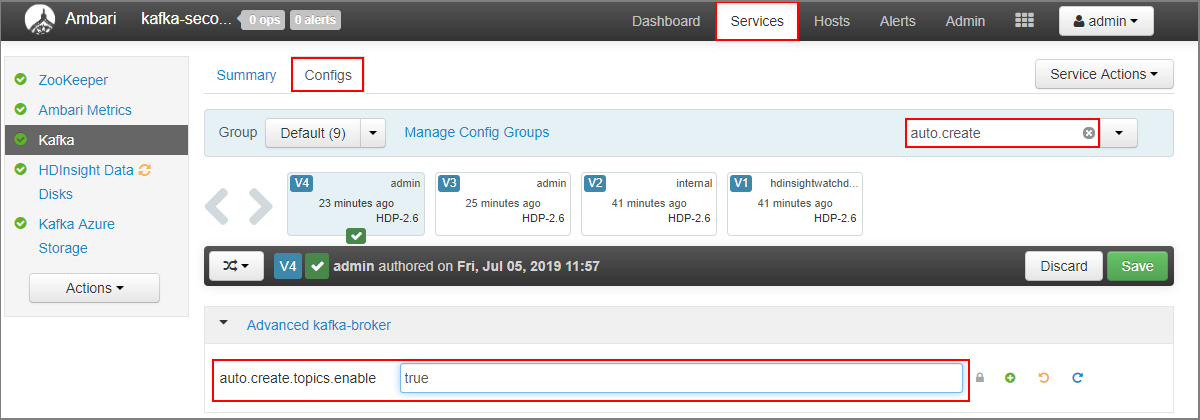
- Přejděte na řídicí panel Ambari pro sekundární cluster:
Spustit MirrorMaker
Poznámka
Tento článek obsahuje odkazy na termín, který už microsoft nepoužívá. Po odebrání termínu ze softwaru ho z tohoto článku odebereme.
Z připojení SSH k sekundárnímu clusteru spusťte proces MirrorMaker pomocí následujícího příkazu:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4V tomto příkladu se používají parametry:
Parametr Popis --consumer.configUrčuje soubor, který obsahuje vlastnosti příjemce. Tyto vlastnosti použijete k vytvoření příjemce, který čte z primárního clusteru Kafka. --producer.configUrčuje soubor, který obsahuje vlastnosti producenta. Pomocí těchto vlastností vytvoříte producenta, který zapisuje do sekundárního clusteru Kafka. --whitelistSeznam témat, která Nástroj MirrorMaker replikuje z primárního clusteru do sekundárního. --num.streamsPočet vláken příjemce, která se mají vytvořit. Příjemce na sekundárním uzlu teď čeká na příjem zpráv.
Z připojení SSH k primárnímu clusteru pomocí následujícího příkazu spusťte producenta a odešlete zprávy do tématu:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicKdyž kurzorem přejdete na prázdný řádek, zadejte několik textových zpráv. Zprávy se odesílají do tématu v primárním clusteru. Až budete hotovi, ukončete proces producenta stisknutím kláves Ctrl+C.
Z připojení SSH k sekundárnímu clusteru ukončete proces MirrorMakeru stisknutím kláves Ctrl+C. Dokončení procesu může trvat několik sekund. Pokud chcete ověřit, že se zprávy replikovaly do sekundární databáze, použijte následující příkaz:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningSeznam témat teď obsahuje
testtopic, který se vytvoří, když MirrorMaster zrcadlí téma z primárního clusteru do sekundárního. Zprávy načtené z tématu jsou stejné jako zprávy, které jste zadali v primárním clusteru.
Odstranění clusteru
Upozornění
Fakturace za clustery HDInsight se účtuje po minutách bez ohledu na to, jestli je používáte, nebo ne. Po dokončení používání clusteru nezapomeňte odstranit. Přečtěte si , jak odstranit cluster HDInsight.
Kroky v tomto článku vytvořily clustery v různých skupinách prostředků Azure. Pokud chcete odstranit všechny vytvořené prostředky, můžete odstranit dvě vytvořené skupiny prostředků: kafka-primary-rg a kafka-secondary-rg. Odstraněním skupin prostředků odeberete všechny prostředky vytvořené podle tohoto článku, včetně clusterů, virtuálních sítí a účtů úložiště.
Další kroky
V tomto článku jste zjistili, jak pomocí nástroje MirrorMaker vytvořit repliku clusteru Apache Kafka . Další způsoby práce se systémem Kafka najdete na následujících odkazech: