Rychlý start: Vytvoření clusteru Apache Kafka ve službě Azure HDInsight pomocí webu Azure Portal
Apache Kafka je opensourcová distribuovaná streamovací platforma. Často se používá jako zprostředkovatel zpráv, protože nabízí funkce podobné frontě pro publikování a odběr zpráv.
V tomto rychlém startu se dozvíte, jak vytvořit cluster Apache Kafka pomocí webu Azure Portal. Dozvíte se také, jak používat obsažené nástroje k odesílání a příjmu zpráv pomocí platformy Apache Kafka. Podrobné vysvětlení dostupných konfigurací najdete v tématu Nastavení clusterů ve službě HDInsight. Další informace týkající se použití portálu k vytváření clusterů najdete v tématu Vytváření clusterů na portálu.
Upozorňující
Fakturace clusterů HDInsight se účtuje za minutu bez ohledu na to, jestli je používáte, nebo ne. Až cluster dokončíte, nezapomeňte ho odstranit. Podívejte se, jak odstranit cluster HDInsight.
Rozhraní Apache Kafka API je přístupné jenom pro prostředky ve stejné virtuální síti. V tomto rychlém startu přistupujete ke clusteru přímo pomocí SSH. Pokud chcete k platformě Apache Kafka připojit jiné služby, sítě nebo virtuální počítače, musíte nejprve vytvořit virtuální síť a pak v síti vytvořit prostředky. Další informace najdete v dokumentu Připojení k platformě Apache Kafka pomocí virtuální sítě. Další obecné informace o plánování virtuálních sítí pro HDInsight najdete v tématu Plánování virtuální sítě pro Azure HDInsight.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Klient SSH. Další informace najdete v tématu Připojení ke službě HDInsight (Apache Hadoop) pomocí SSH.
Vytvoření clusteru Apache Kafka
Pokud chcete vytvořit cluster Apache Kafka ve službě HDInsight, postupujte následovně:
Přihlaste se k portálu Azure.
V horní nabídce vyberte + Vytvořit prostředek.
Výběrem možnosti Analytics>Azure HDInsight přejděte na stránku Vytvořit cluster HDInsight.
Na kartě Základy zadejte následující informace:
Vlastnost Popis Předplatné V rozevíracím seznamu vyberte předplatné Azure, které se používá pro cluster. Skupina prostředků Vytvořte skupinu prostředků nebo vyberte existující. Skupina prostředků je kontejner komponent Azure. V tomto případě skupina prostředků obsahuje cluster HDInsight a závislý účet služby Azure Storage. Název clusteru Zadejte globálně jedinečný název. Název může obsahovat až 59 znaků včetně písmen, číslic a pomlček. První a poslední znak názvu nemůže být pomlčka. Oblast V rozevíracím seznamu vyberte oblast, ve které je cluster vytvořen. Zvolte oblast blíže k vám, abyste měli lepší výkon. Typ clusteru Výběrem možnosti Vybrat typ clusteru otevřete seznam. V seznamu jako typ clusteru vyberte Kafka . Verze Bude zadána výchozí verze pro typ clusteru. Pokud chcete zadat jinou verzi, vyberte ji z rozevíracího seznamu. Přihlašovací uživatelské jméno a heslo clusteru Výchozí přihlašovací jméno je admin. Heslo musí mít délku nejméně 10 znaků a musí obsahovat alespoň jednu číslici, jedno velké a jedno malé písmeno, jeden nealnumerický znak (s výjimkou znaků' ` "). Ujistěte se, že nezadáte běžná hesla, napříkladPass@word1.Uživatelské jméno Secure Shell (SSH) Výchozí uživatelské jméno je sshuser. Pro uživatelské jméno SSH můžete zadat jiný název.Použití hesla pro přihlášení ke clusteru pro SSH Toto políčko zaškrtněte, pokud chcete použít stejné heslo pro uživatele SSH jako heslo, které jste zadali pro přihlašovacího uživatele clusteru. 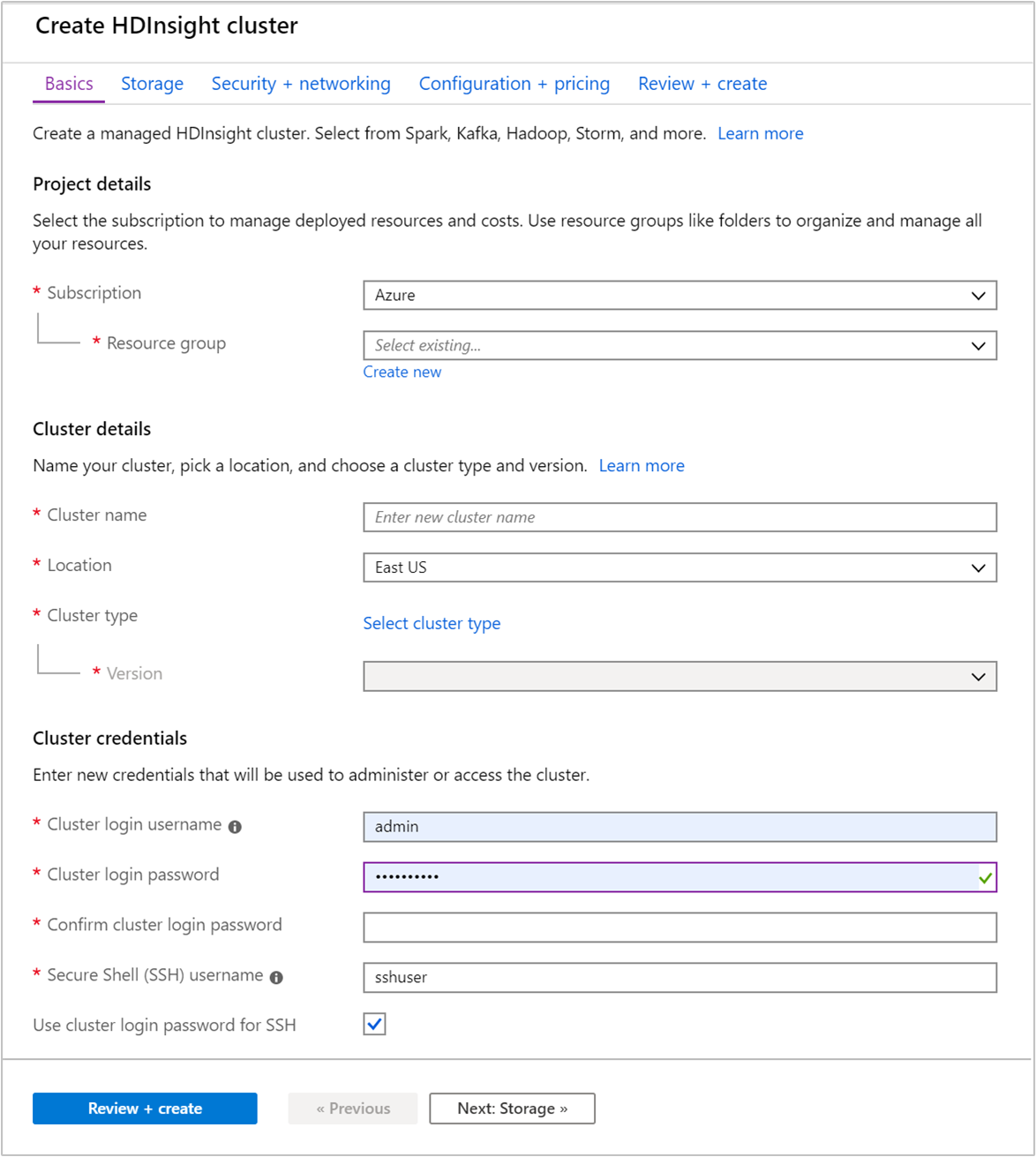
Každá oblast Azure (umístění) poskytuje domény selhání. Doména selhání je logické seskupení základního hardwaru v datovém centru Azure. Všechny domény selhání sdílí společný zdroje napájení a síťový přepínač. Virtuální počítače a spravované disky, které implementují uzly v clusteru služby HDInsight, jsou distribuované napříč těmito doménami selhání. Tato architektura omezuje potenciální dopad selhání fyzického hardwaru.
Pro zajištění vysoké dostupnosti dat vyberte oblast (umístění), které obsahuje tři domény selhání. Informace o počtu domén selhání v oblasti najdete v dokumentu popisujícím dostupnost Linuxových virtuálních počítačů.
Výběrem karty Další: Úložiště >> přejděte k nastavení úložiště.
Na kartě Úložiště zadejte následující hodnoty:
Vlastnost Popis Typ primárního úložiště Použijte výchozí hodnotu Azure Storage. Metoda výběru Použijte výchozí hodnotu Vybrat ze seznamu. Účet primárního úložiště V rozevíracím seznamu vyberte existující účet úložiště nebo vyberte Vytvořit nový. Pokud vytvoříte nový účet, musí mít název délku 3 až 24 znaků a může obsahovat jenom číslice a malá písmena. Kontejner Použijte automaticky vyplněnou hodnotu. 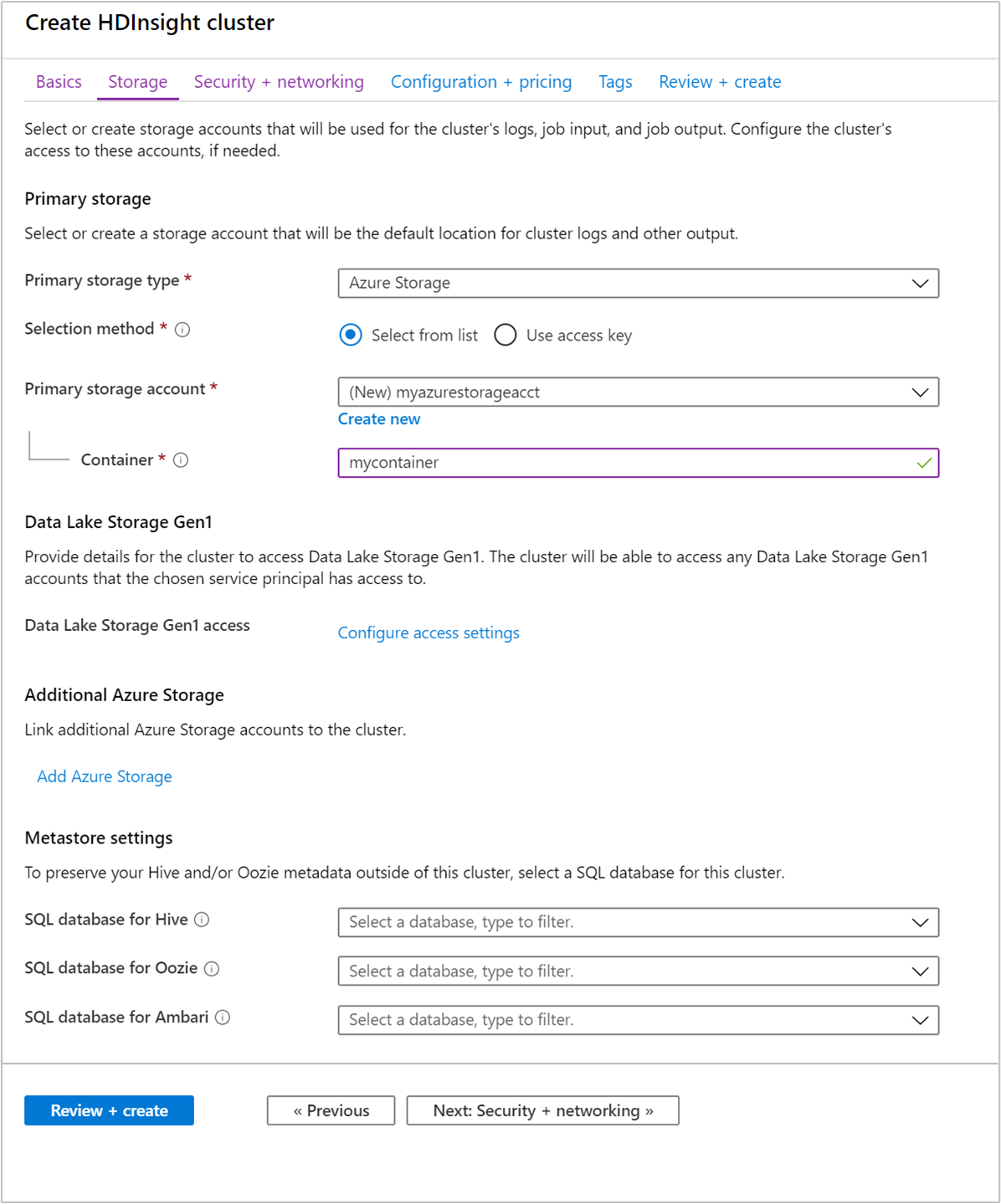
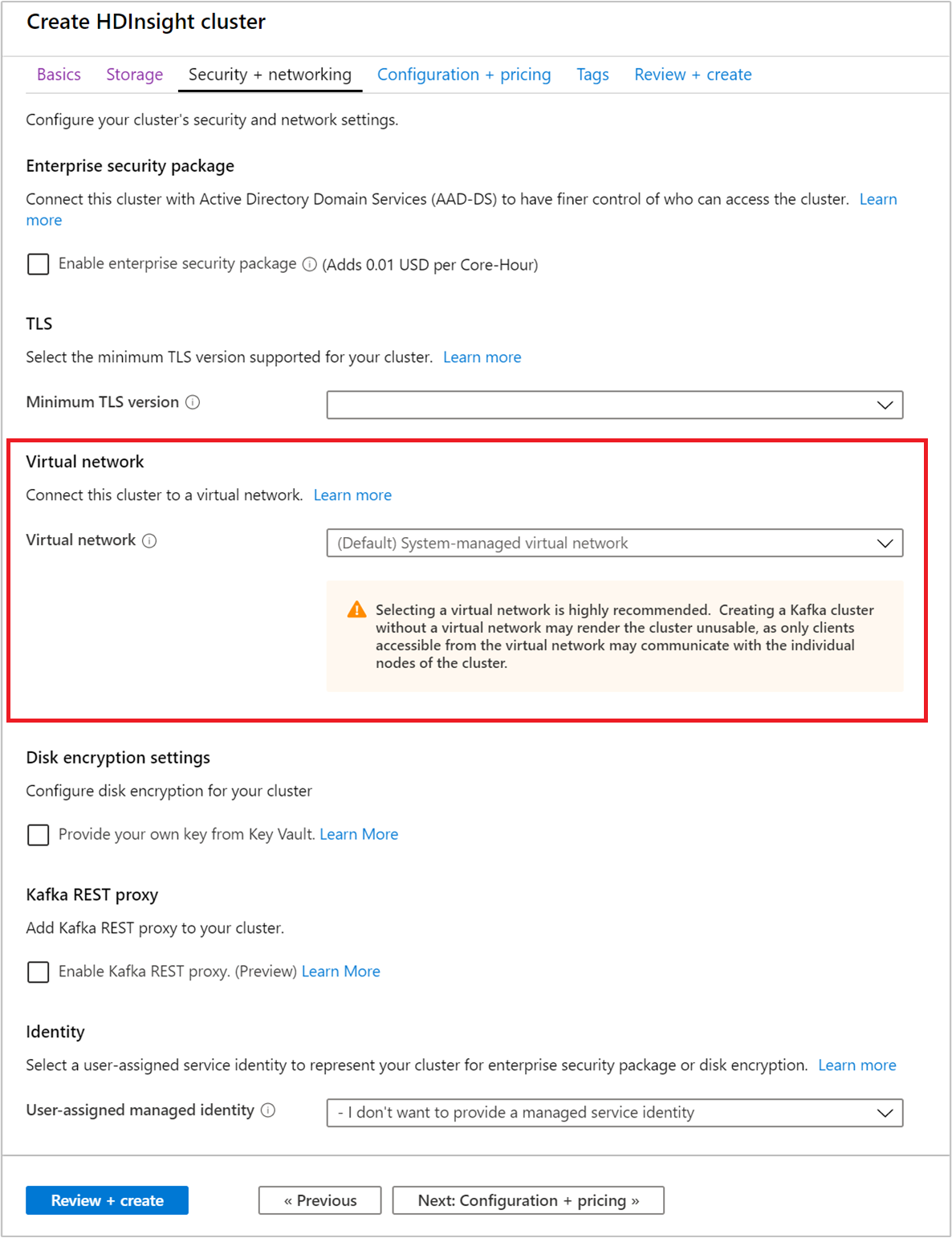
Vyberte kartu Zabezpečení a sítě.
Pro účely tohoto rychlého startu ponechte výchozí nastavení zabezpečení. Další informace o balíčku podnikového zabezpečení najdete v tématu Konfigurace clusteru HDInsight s balíčkem zabezpečení podniku pomocí služby Microsoft Entra Domain Services. Informace o použití vlastního klíče pro službu Apache Kafka Disk Encryption najdete v tématu Šifrování disků spravovaných zákazníkem.
Pokud chcete svůj cluster připojit k virtuální síti, vyberte virtuální síť v rozevíracím seznamu Virtuální síť.
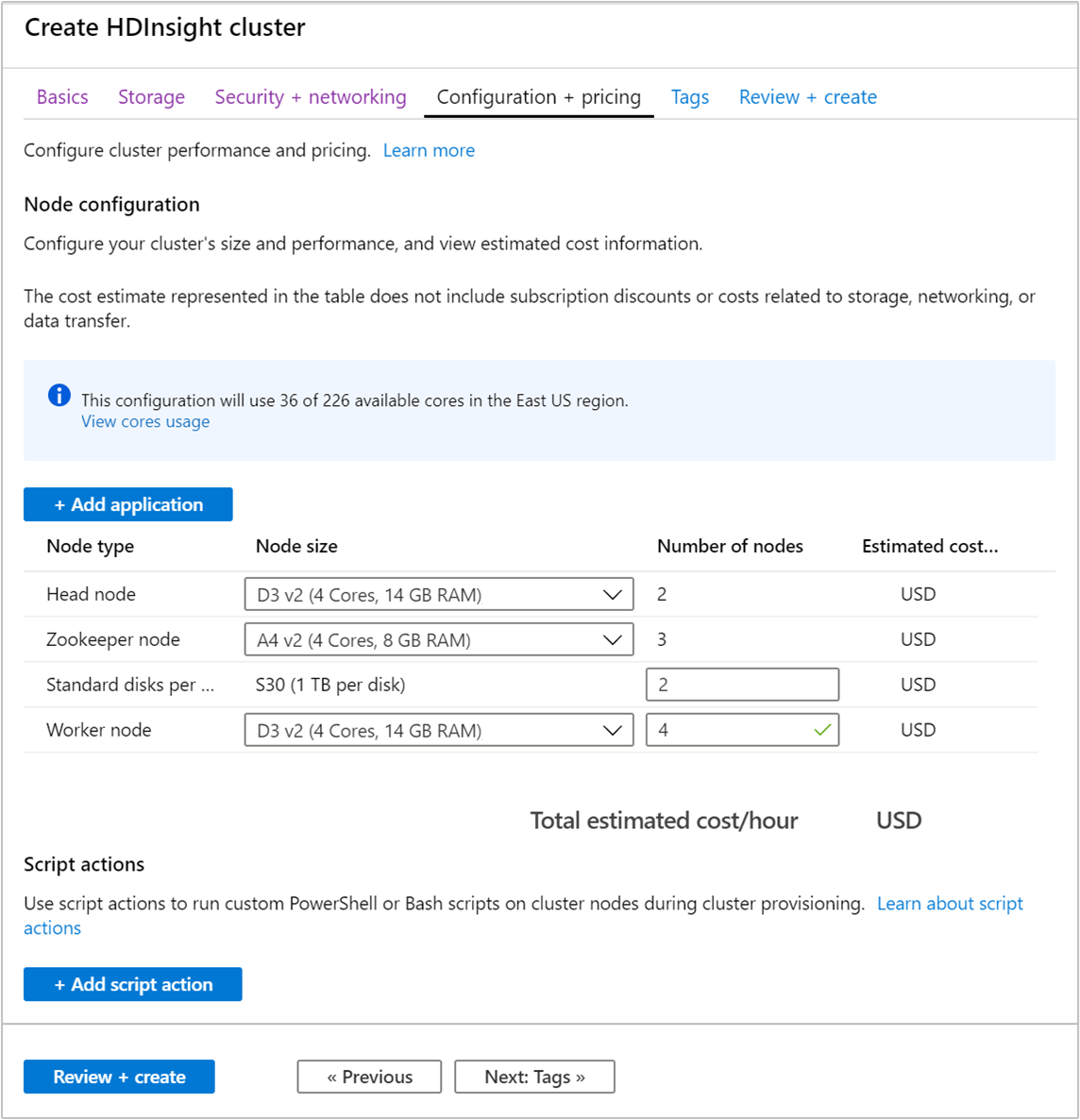
Vyberte kartu Konfigurace a ceny.
Aby bylo možné zaručit dostupnost Apache Kafka ve službě HDInsight, musí být počet uzlů pro pracovní uzel nastavený na hodnotu 3 nebo vyšší. Výchozí hodnota je 4.
Položka disků Standard na pracovní uzel konfiguruje škálovatelnost Apache Kafka ve službě HDInsight. Apache Kafka ve službě HDInsight používá k ukládání dat místní disky virtuálních počítačů v clusteru. Platforma Apache Kafka je náročná na vstupně-výstupní operace, proto se k zajištění vysoké propustnosti a vyšší kapacity úložiště na každý uzel využívají Spravované disky Azure. Typ spravovaného disku může být buď Standardní (HDD), nebo Prémiový (SSD). Typ disku závisí na velikosti virtuálního počítače používaného pracovními uzly (zprostředkovateli Apache Kafka). U virtuálních počítačů řady DS a GS se automaticky používají prémiové disky. Všechny ostatní typy virtuálních počítačů používají standardní disky.
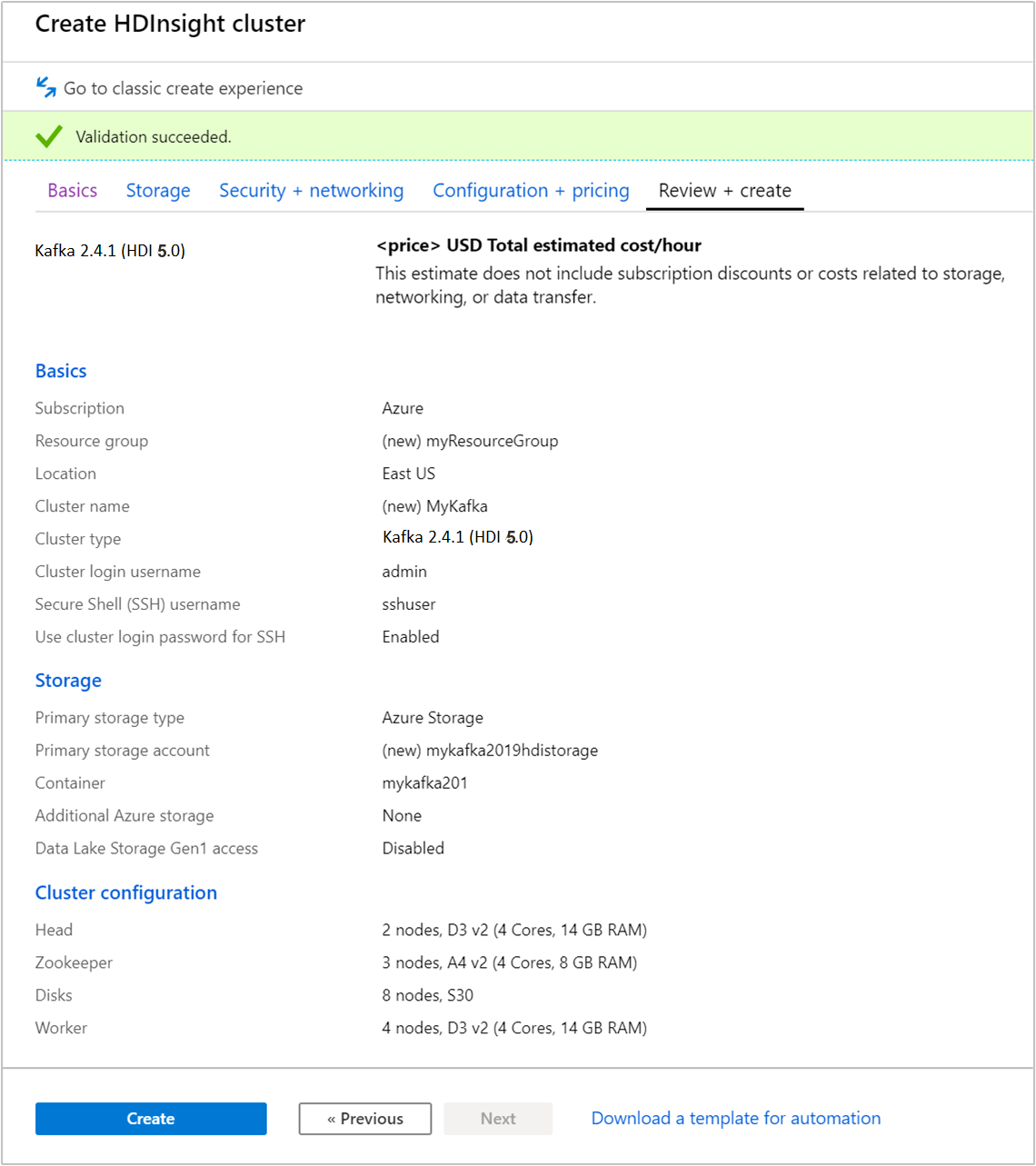
Vyberte kartu Zkontrolovat a vytvořit.
Zkontrolujte konfiguraci clusteru. Změňte všechna nesprávná nastavení. Nakonec vyberte Vytvořit a vytvořte cluster.
Vytvoření clusteru trvá přibližně 20 minut.
Připojení ke clusteru
Pomocí příkazu ssh se připojte ke clusteru. Upravte následující příkaz nahrazením clusteru názvem clusteru a zadáním příkazu:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPo zobrazení výzvy zadejte heslo uživatele SSH.
Po připojení se zobrazí informace podobné tomuto textu:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Získání informací o hostiteli Apache Zookeeper a Broker
Při práci se systémem Kafka musíte znát hostitele Apache Zookeeper a Broker . Tito hostitelé se používají s rozhraním Apache Kafka API a mnohými z nástrojů, které se se systémem Kafka dodávají.
V této části získáte informace o hostiteli z rozhraní Apache Ambari REST API v clusteru.
Nainstalujte jq, procesor JSON příkazového řádku. Tento nástroj slouží k analýze dokumentů JSON a je užitečný při analýze informací o hostiteli. Z otevřeného připojení SSH zadejte následující příkaz, který chcete nainstalovat
jq:sudo apt -y install jqNastavte proměnnou hesla. Nahraďte
PASSWORDpřihlašovacím heslem clusteru a pak zadejte příkaz:export PASSWORD='PASSWORD'Extrahujte název clusteru se správnými písmeny. Skutečná velikost výskytu názvu clusteru se může lišit od očekávání podle toho, jak byl cluster vytvořen. Tento příkaz získá skutečné velikostí a uloží ho do proměnné. Zadejte tento příkaz:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Poznámka:
Pokud tento proces provádíte mimo cluster, existuje jiný postup pro uložení názvu clusteru. Název clusteru získáte v malých písmenech z webu Azure Portal. Potom nahraďte název
<clustername>clusteru následujícím příkazem a spusťte ho:export clusterName='<clustername>'.Pokud chcete nastavit proměnnou prostředí s informacemi o hostiteli Zookeeper, použijte následující příkaz. Příkaz načte všechny hostitele Zookeeper a pak vrátí pouze první dvě položky. Je to proto, že chcete určitou redundanci pro případ, že jeden hostitel bude nedosažitelný.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Poznámka:
Tento příkaz vyžaduje přístup k Ambari. Pokud je váš cluster za skupinou zabezpečení sítě, spusťte tento příkaz z počítače, který má přístup k Ambari.
Pokud chcete ověřit správné nastavení proměnné prostředí, použijte následující příkaz:
echo $KAFKAZKHOSTSTento příkaz by měl vrátit informace podobné následujícímu textu:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181K nastavení proměnné prostředí s použitím informací o hostiteli zprostředkovatele Apache Kafka použijte následující příkaz:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Poznámka:
Tento příkaz vyžaduje přístup k Ambari. Pokud je váš cluster za skupinou zabezpečení sítě, spusťte tento příkaz z počítače, který má přístup k Ambari.
Pokud chcete ověřit správné nastavení proměnné prostředí, použijte následující příkaz:
echo $KAFKABROKERSTento příkaz by měl vrátit informace podobné následujícímu textu:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Správa témat Apache Kafka
Kafka ukládá datové proudy do témat. Témata můžete spravovat pomocí nástroje kafka-topics.sh.
K vytvoření tématu použijte tento příkaz v připojení SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSTento příkaz se připojí ke zprostředkovateli pomocí informací o hostiteli uložených v
$KAFKABROKERS. Pak vytvoří téma Apache Kafka s názvem test.Data uložená v tomto tématu jsou rozdělená mezi osm oddílů.
Každý oddíl se replikuje mezi tři pracovní uzly v clusteru.
Pokud jste vytvořili cluster v oblasti Azure, která poskytuje tři domény selhání, použijte faktor replikace 3. Jinak použijte faktor replikace 4.
V oblastech se třemi doménami selhání faktor replikace 3 umožní rozložení replik mezi domény selhání. V oblastech se dvěma doménami selhání faktor replikace 4 rozloží repliky rovnoměrně mezi domény selhání.
Informace o počtu domén selhání v oblasti najdete v dokumentu popisujícím dostupnost Linuxových virtuálních počítačů.
Apache Kafka nemá o doménách selhání Azure žádné informace. Při vytváření replik oddílu pro témata se nemusí repliky distribuovat správně z hlediska vysoké dostupnosti.
K zajištění vysoké dostupnosti použijte nástroj pro vyrovnávání oddílů Apache Kafka. Tento nástroj se musí spustit z připojení SSH k hlavnímu uzlu clusteru Apache Kafka.
K zajištění nejvyšší dostupnosti dat Apache Kafka byste měli obnovit rovnováhu replik oddílů pro vaše téma v těchto situacích:
Při vytvoření nového tématu nebo oddílu
Při vertikálním navýšení kapacity clusteru
K zobrazení seznamu témat použijte tento příkaz:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSTento příkaz vypíše seznam témat dostupných v clusteru Apache Kafka.
K odstranění tématu použijte tento příkaz:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSTento příkaz odstraní téma s názvem
topicname.Upozorňující
Pokud odstraníte dříve vytvořené téma
test, pak ho musíte vytvořit znovu. Používá se v dalších krocích tohoto dokumentu.
Další informace o příkazech, které jsou k dispozici v nástroji kafka-topics.sh, získáte pomocí tohoto příkazu:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Produkce a konzumace záznamů
Kafka ukládá záznamy v tématech. Záznamy jsou vytvářeny producenty a spotřebovávány konzumenty. Producenti a konzumenti komunikují se službou zprostředkovatele Kafka. Každý pracovní uzel v clusteru HDInsight je hostitelem zprostředkovatele Apache Kafka.
Pokud chcete uložit záznamy do dříve vytvořeného tématu test a pak je načíst pomocí konzumenta, použijte následující postup:
Pokud chcete zapsat záznamy do tématu, použijte nástroj
kafka-console-producer.shz připojení SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testPo tomto příkazu přejdete na prázdný řádek.
Na prázdný řádek zadejte textovou zprávu a stiskněte Enter. Tímto způsobem zadejte několik zpráv a pak se pomocí klávesové zkratky Ctrl + C vraťte na normální příkazový řádek. Každý řádek se odešle do tématu Apache Kafka jako samostatný záznam.
Pokud chcete číst záznamy z tématu, použijte nástroj
kafka-console-consumer.shz připojení SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningTento příkaz načte záznamy z tématu a zobrazí je. Parametr
--from-beginningzpůsobí, že konzument začne načítat od začátku datového proudu a zpracuje tak všechny záznamy.Pokud používáte starší verzi Kafka, nahraďte
--bootstrap-server $KAFKABROKERSza--zookeeper $KAFKAZKHOSTS.Konzumenta zastavíte stisknutím Ctrl+C.
Můžete také programově vytvořit producenty a spotřebitele. Příklad použití tohoto rozhraní API najdete v dokumentu Apache Kafka Producer and Consumer API s dokumentem HDInsight .
Vyčištění prostředků
Pokud chcete vyčistit prostředky vytvořené v tomto rychlém startu, můžete odstranit skupinu prostředků. Odstraněním skupiny prostředků odstraníte také přidružený cluster HDInsight a všechny další prostředky, které jsou k příslušné skupině prostředků přidružené.
Odebrání skupiny prostředků pomocí webu Azure Portal:
- Na webu Azure Portal rozbalením nabídky na levé straně otevřete nabídku služeb a pak zvolte Skupiny prostředků. Zobrazí se seznam skupin prostředků.
- Vyhledejte skupinu prostředků, kterou chcete odstranit, a klikněte pravým tlačítkem na tlačítko Další (...) na pravé straně seznamu.
- Vyberte Odstranit skupinu prostředků a potvrďte tuto akci.
Upozorňující
Odstraněním clusteru Apache Kafka ve službě HDInsight se odstraní všechna data uložená v systému Kafka.