Použití jazyka C# se streamováním MapReduce v Apache Hadoopu ve službě HDInsight
Naučte se používat C# k vytvoření řešení MapReduce ve službě HDInsight.
Streamování Apache Hadoop umožňuje spouštět úlohy MapReduce pomocí skriptu nebo spustitelného souboru. V této části se .NET používá k implementaci mapovače a redukčního nástroje pro řešení počtu slov.
.NET ve službě HDInsight
Clustery HDInsight používají Mono (https://mono-project.com) ke spouštění aplikací .NET. Mono verze 4.2.1 je součástí HDInsight verze 3.6. Další informace o verzi Mono, která je součástí HDInsight, najdete v tématu o komponentách Apache Hadoop dostupných ve verzích HDInsight.
Další informace o kompatibilitě Mono s verzemi rozhraní .NET Framework naleznete v tématu Mono kompatibilita.
Jak funguje streamování Hadoop
Základní proces používaný pro streamování v tomto dokumentu je následující:
- Hadoop předává data mapperu (mapper.exe v tomto příkladu) ve službě STDIN.
- Mapovač zpracuje data a vygeneruje dvojice klíč/hodnota oddělených tabulátory do stDOUT.
- Výstup přečte Hadoop a pak se předá redukčnímu modulu (reducer.exe v tomto příkladu) v režimu STDIN.
- Redukční funkce čte páry klíč/hodnota oddělených tabulátory, zpracuje data a potom vygeneruje výsledek jako páry klíč/hodnota oddělených tabulátory v stDOUT.
- Výstup přečte Hadoop a zapíše do výstupního adresáře.
Další informace o streamování najdete v tématu Hadoop Streaming.
Požadavky
Visual Studio.
Znalost psaní a vytváření kódu jazyka C#, který cílí na rozhraní .NET Framework 4.5.
Způsob nahrání .exe souborů do clusteru Kroky v tomto dokumentu používají nástroje Data Lake pro Visual Studio k nahrání souborů do primárního úložiště clusteru.
Cluster Apache Hadoop ve službě HDInsight. Viz Začínáme se službou HDInsight v Linuxu.
Schéma identifikátoru URI pro primární úložiště clusterů. Toto schéma by bylo
wasb://pro Azure Storage,abfs://pro Azure Data Lake Storage Gen2 neboadl://Azure Data Lake Storage Gen1. Pokud je pro Azure Storage nebo Data Lake Storage Gen2 povolený zabezpečený přenos, identifikátor URI by bylwasbs://neboabfss://v uvedeném pořadí.
Vytvoření mapovače
V sadě Visual Studio vytvořte novou konzolovou aplikaci rozhraní .NET Framework s názvem mapper. Pro aplikaci použijte následující kód:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Po vytvoření aplikace ji sestavte, aby /bin/Debug/mapper.exe se soubor vytvořil v adresáři projektu.
Vytvoření reduktoru
V sadě Visual Studio vytvořte novou konzolovou aplikaci rozhraní .NET Framework s názvem reducer. Pro aplikaci použijte následující kód:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Po vytvoření aplikace ji sestavte, aby /bin/Debug/reducer.exe se soubor vytvořil v adresáři projektu.
Nahrání do úložiště
Dále je potřeba nahrát aplikace mapperu a redukčního modulu do úložiště HDInsight.
V sadě Visual Studio vyberte Zobrazit>Průzkumníka serveru.
Klikněte pravým tlačítkem na Azure, vyberte Připojit k předplatnému Microsoft Azure... a dokončete proces přihlášení.
Rozbalte cluster HDInsight, do kterého chcete tuto aplikaci nasadit. Zobrazí se položka s textem (výchozí účet úložiště).
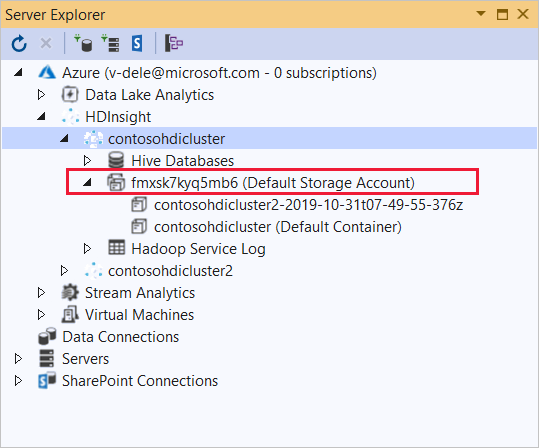
Pokud je možné položku (výchozí účet úložiště) rozšířit, používáte účet úložiště Azure jako výchozí úložiště pro cluster. Pokud chcete zobrazit soubory ve výchozím úložišti clusteru, rozbalte položku a poklikejte na (výchozí kontejner).
Pokud položku (výchozí účet úložiště) nejde rozbalit, používáte Azure Data Lake Storage jako výchozí úložiště pro cluster. Pokud chcete zobrazit soubory ve výchozím úložišti clusteru, poklikejte na položku (Výchozí účet úložiště).
K nahrání .exe souborů použijte jednu z následujících metod:
Pokud používáte účet služby Azure Storage, vyberte ikonu Nahrát objekt blob .

V dialogovém okně Nahrát nový soubor v části Název souboru vyberte Procházet. V dialogovém okně Nahrát objekt blob přejděte do složky bin\debug projektu mapperu a zvolte soubor mapper.exe . Nakonec vyberte Otevřít a pak OK dokončete nahrávání.
V případě Azure Data Lake Storage klikněte pravým tlačítkem na prázdnou oblast v seznamu souborů a pak vyberte Nahrát. Nakonec vyberte soubor mapper.exe a pak vyberte Otevřít.
Po dokončení nahrávání mapper.exe opakujte proces nahrávání souboru reducer.exe.
Spuštění úlohy: Použití relace SSH
Následující postup popisuje, jak spustit úlohu MapReduce pomocí relace SSH:
Pomocí příkazu ssh se připojte ke clusteru. Upravte následující příkaz nahrazením clusteru názvem clusteru a zadáním příkazu:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPomocí jednoho z následujících příkazů spusťte úlohu MapReduce:
Pokud je výchozím úložištěm Azure Storage:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutPokud je výchozím úložištěm Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutPokud je výchozím úložištěm Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
Následující seznam popisuje, co jednotlivé parametry a možnosti představují:
Parametr Popis hadoop-streaming.jar Určuje soubor JAR, který obsahuje funkci MapReduce streamování. -soubory Určuje soubory mapper.exe a reducer.exe pro tuto úlohu. Deklarace wasbs:///,adl:///neboabfs:///protokolu před každým souborem je cesta ke kořenovému adresáři výchozího úložiště clusteru.-kartograf Určuje soubor, který implementuje mapovač. -reduktor Určuje soubor, který implementuje redukční nástroj. -vstup Určuje vstupní data. -výstup Určuje výstupní adresář. Po dokončení úlohy MapReduce zobrazte výsledky pomocí následujícího příkazu:
hdfs dfs -text /example/wordcountout/part-00000Následující text je příkladem dat vrácených tímto příkazem:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Spuštění úlohy: Pomocí PowerShellu
Pomocí následujícího skriptu PowerShellu spusťte úlohu MapReduce a stáhněte si výsledky.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Tento skript vás vyzve k zadání názvu a hesla přihlašovacího účtu clusteru spolu s názvem clusteru HDInsight. Po dokončení úlohy se výstup stáhne do souboru s názvem output.txt. Následující text je příkladem dat v output.txt souboru:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17