Použití uživatelem definovaných funkcí jazyka C# s Apache Hivem a Apache Pigem v Apache Hadoopu ve službě HDInsight
Naučte se používat uživatelem definované funkce jazyka C# s Apache Hivem a Apache Pig ve službě HDInsight.
Důležité
Kroky v tomto dokumentu fungují s clustery HDInsight se systémem Linux. HDInsight od verze 3.4 výše používá výhradně operační systém Linux. Další informace najdete v tématu Správa verzí součástí HDInsight.
Hive i Pig můžou předávat data externím aplikacím ke zpracování. Tento proces se označuje jako streamování. Když použijete aplikaci .NET, data se předají aplikaci ve službě STDIN a aplikace vrátí výsledky stDOUT. Ke čtení a zápisu z rozhraní STDIN a STDOUT můžete použít Console.ReadLine() a Console.WriteLine() z konzolové aplikace.
Požadavky
Znalost psaní a vytváření kódu jazyka C#, který cílí na rozhraní .NET Framework 4.5.
Použijte libovolné integrované vývojové prostředí (IDE), které chcete. Doporučujeme Visual Studio nebo Visual Studio Code. Kroky v tomto dokumentu používají Visual Studio 2019.
Způsob, jak nahrát .exe soubory do clusteru a spustit úlohy Pig a Hive Doporučujeme nástroje Data Lake pro Visual Studio, Azure PowerShell a Azure CLI. Kroky v tomto dokumentu používají nástroje Data Lake pro Visual Studio k nahrání souborů a spuštění ukázkového dotazu Hive.
Informace o dalších způsobech spouštění dotazů Hive najdete v tématu Co je Apache Hive a HiveQL ve službě Azure HDInsight?.
Hadoop v clusteru HDInsight. Další informace o vytvoření clusteru najdete v tématu Vytváření clusterů HDInsight.
.NET ve službě HDInsight
Clustery HDInsight založené na Linuxu používají mono (https://mono-project.com) ke spouštění aplikací .NET. Mono verze 4.2.1 je součástí HDInsight verze 3.6.
Další informace o kompatibilitě Mono s verzemi rozhraní .NET Framework naleznete v tématu Mono kompatibilita.
Další informace o verzi rozhraní .NET Framework a Mono, které jsou součástí hdInsight verze, naleznete v tématu Verze komponent HDInsight.
Vytvoření projektů jazyka C#
Následující části popisují, jak vytvořit projekt jazyka C# v sadě Visual Studio pro uživatelem definované uživatelem Apache Hive a UDF Apache Pig.
Apache Hive UDF
Vytvoření projektu jazyka C# pro UDF Apache Hive:
Spusťte Visual Studio.
Vyberte Vytvořit nový projekt.
V okně Vytvořit nový projekt zvolte šablonu konzolové aplikace (.NET Framework) (verze jazyka C#). Pak vyberte Další.
V okně Konfigurovat nový projekt zadejte název projektu HiveCSharp a přejděte do umístění pro uložení nového projektu. Pak vyberte Vytvořit.
V integrovaném vývojovém prostředí sady Visual Studio nahraďte obsah Program.cs následujícím kódem:
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }Na řádku nabídek vyberte Sestavit>řešení a sestavte projekt.
Zavřete řešení.
Apache Pig UDF
Vytvoření projektu jazyka C# pro UDF Apache Hive:
Otevřete sadu Visual Studio.
V okně Start vyberte Vytvořit nový projekt.
V okně Vytvořit nový projekt zvolte šablonu konzolové aplikace (.NET Framework) (verze jazyka C#). Pak vyberte Další.
V okně Konfigurovat nový projekt zadejte název projektu PigUDF a přejděte do umístění, kam chcete nový projekt uložit. Pak vyberte Vytvořit.
V integrovaném vývojovém prostředí sady Visual Studio nahraďte obsah Program.cs následujícím kódem:
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }Tento kód analyzuje řádky odeslané z Pig a přeformátuje řádky, které začínají
java.lang.Exception.V řádku nabídek zvolte sestavit řešení sestavení>a sestavte projekt.
Nechte řešení otevřené.
Nahrání do úložiště
Dále nahrajte aplikace Hive a Pig UDF do úložiště v clusteru HDInsight.
V sadě Visual Studio přejděte do Průzkumníka> serveru.
V Průzkumníku serveru klikněte pravým tlačítkem na Azure, vyberte Připojit k předplatnému Microsoft Azure a dokončete proces přihlášení.
Rozbalte cluster HDInsight, do kterého chcete tuto aplikaci nasadit. Zobrazí se položka s textem (výchozí účet úložiště).
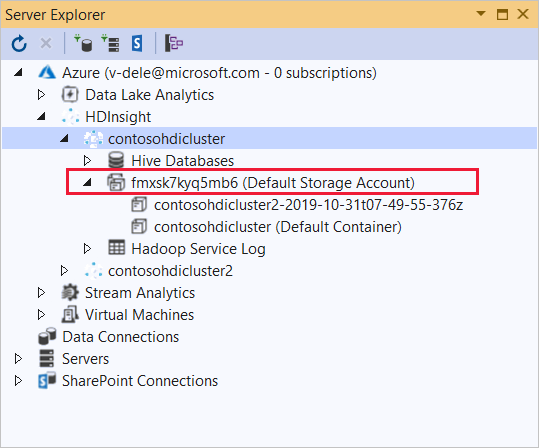
Pokud je možné tuto položku rozšířit, jako výchozí úložiště clusteru používáte účet úložiště Azure. Pokud chcete zobrazit soubory ve výchozím úložišti clusteru, rozbalte položku a poklikejte na položku (Výchozí kontejner).
Pokud tuto položku nejde rozšířit, používáte Azure Data Lake Storage jako výchozí úložiště clusteru. Pokud chcete zobrazit soubory ve výchozím úložišti clusteru, poklikejte na položku (Výchozí účet úložiště).
K nahrání .exe souborů použijte jednu z následujících metod:
Pokud používáte účet služby Azure Storage, vyberte ikonu Nahrát objekt blob .

V dialogovém okně Nahrát nový soubor v části Název souboru vyberte Procházet. V dialogovém okně Nahrát objekt blob přejděte do
bin\debugsložky projektu HiveCSharp a zvolte soubor HiveCSharp.exe . Nakonec vyberte Otevřít a pak OK dokončete nahrávání.Pokud používáte Azure Data Lake Storage, klikněte pravým tlačítkem na prázdnou oblast v seznamu souborů a pak vyberte Nahrát. Nakonec zvolte soubor HiveCSharp.exe a vyberte Otevřít.
Po dokončení nahrávání HiveCSharp.exe opakujte proces nahrávání souboru PigUDF.exe.
Spuštění dotazu Apache Hive
Teď můžete spustit dotaz Hive, který používá vaši aplikaci Hive UDF.
V sadě Visual Studio přejděte do Průzkumníka> serveru.
Rozbalte položku Azure a pak rozbalte HDInsight.
Klikněte pravým tlačítkem myši na cluster, do kterého jste nasadili aplikaci HiveCSharp , a pak vyberte Napsat dotaz Hive.
Pro dotaz Hive použijte následující text:
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;Důležité
Odkomentujte
add filepříkaz, který odpovídá typu výchozího úložiště použitého pro váš cluster.Tento dotaz vybere
clientidpole ,devicemakeadevicemodelpole zhivesampletablea pak předá pole do HiveCSharp.exe aplikace. Dotaz očekává, že aplikace vrátí tři pole, která jsou uložena jakoclientid,phoneLabelaphoneHash. Dotaz také očekává, že najde HiveCSharp.exe v kořenovém adresáři výchozího kontejneru úložiště.Přepněte výchozí interaktivní do služby Batch a pak vyberte Odeslat a odešlete úlohu do clusteru HDInsight. Otevře se okno Souhrn úlohy Hive.
Výběrem možnosti Aktualizovat aktualizujete souhrn, dokud se stav úlohy nezmění na Dokončeno. Pokud chcete zobrazit výstup úlohy, vyberte Výstup úlohy.
Spuštění úlohy Apache Pig
Můžete také spustit úlohu Pig, která používá vaši aplikaci Pig UDF.
Připojte se ke clusteru HDInsight pomocí SSH. (Například spusťte příkaz
ssh sshuser@<clustername>-ssh.azurehdinsight.net.) Další informace najdete v tématu Použití SSH sHDInsight.Ke spuštění příkazového řádku Pig použijte následující příkaz:
piggrunt>Zobrazí se výzva.Zadáním následujícího příkazu spusťte úlohu Pig, která používá aplikaci .NET Framework:
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;Příkaz
DEFINEvytvoří alias pro PigUDF.exe aplikaci aCACHEnačte ho z výchozíhostreamerúložiště pro cluster.streamerPozději se s operátoremSTREAMpoužije ke zpracování jednotlivých řádků obsaženýchLOGa vrácení dat jako řady sloupců.Poznámka:
Název aplikace, který se používá pro streamování, musí být při použití s aliasem ohraničen znakem
`(backtick) a znakem'SHIP(jednoduchá uvozovka).Po zadání posledního řádku by se měla úloha spustit. Vrátí výstup podobný následujícímu textu:
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)Slouží
exitk ukončení prasete.
Další kroky
V tomto dokumentu jste zjistili, jak používat aplikaci .NET Framework z Hive a Pig ve službě HDInsight. Pokud chcete zjistit, jak používat Python s Hivem a Pigem, přečtěte si téma Použití Pythonu s Apache Hive a Apache Pig v HDInsightu.
Další způsoby použití Hivu a informace o používání MapReduce najdete v následujících článcích: