Použití Apache Kafka® ve službě HDInsight s Apache Flinkem® ve službě HDInsight v AKS
Důležitý
Azure HDInsight na Azure Kubernetes Service byl vyřazen 31. ledna 2025. Další informace s tímto oznámením.
Abyste se vyhnuli náhlému ukončení úloh, musíte migrovat úlohy do Microsoft Fabric nebo ekvivalentního produktu Azure.
Důležitý
Tato funkce je aktuálně ve verzi Preview. doplňkové podmínky použití pro Preview Microsoft Azure obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, v režimu Preview nebo ještě nebyly vydány v obecné dostupnosti. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight ve službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás pro další aktualizace na komunitě Azure HDInsight.
Známý případ použití pro Apache Flink je stream analytics. Oblíbená volba mnoha uživatelů k používání datových proudů, které se ingestují pomocí Apache Kafka. Typické instalace Flinku a Kafky začínají tím, že streamy událostí jsou odesílány do Kafky, které mohou být využívány úlohami ve Flinku.
Tento příklad používá HDInsight v clusterech AKS se systémem Flink 1.17.0 ke zpracování streamovaných dat s využitím a vytváření tématu Kafka.
Poznámka
FlinkKafkaConsumer je zastaralý a odebere se pomocí Flinku 1.17, použijte místo toho KafkaSource. FlinkKafkaProducer je zastaralý a bude odebrán s Flink 1.15, použijte místo toho KafkaSink.
Požadavky
Kafka i Flink musí být ve stejné virtuální síti nebo by mezi těmito dvěma clustery měly existovat vnet-peering.
Vytvořte cluster Kafka ve stejné virtuální síti. Na základě aktuálního využití můžete ve službě HDInsight zvolit Kafka 3.2 nebo 2.4.
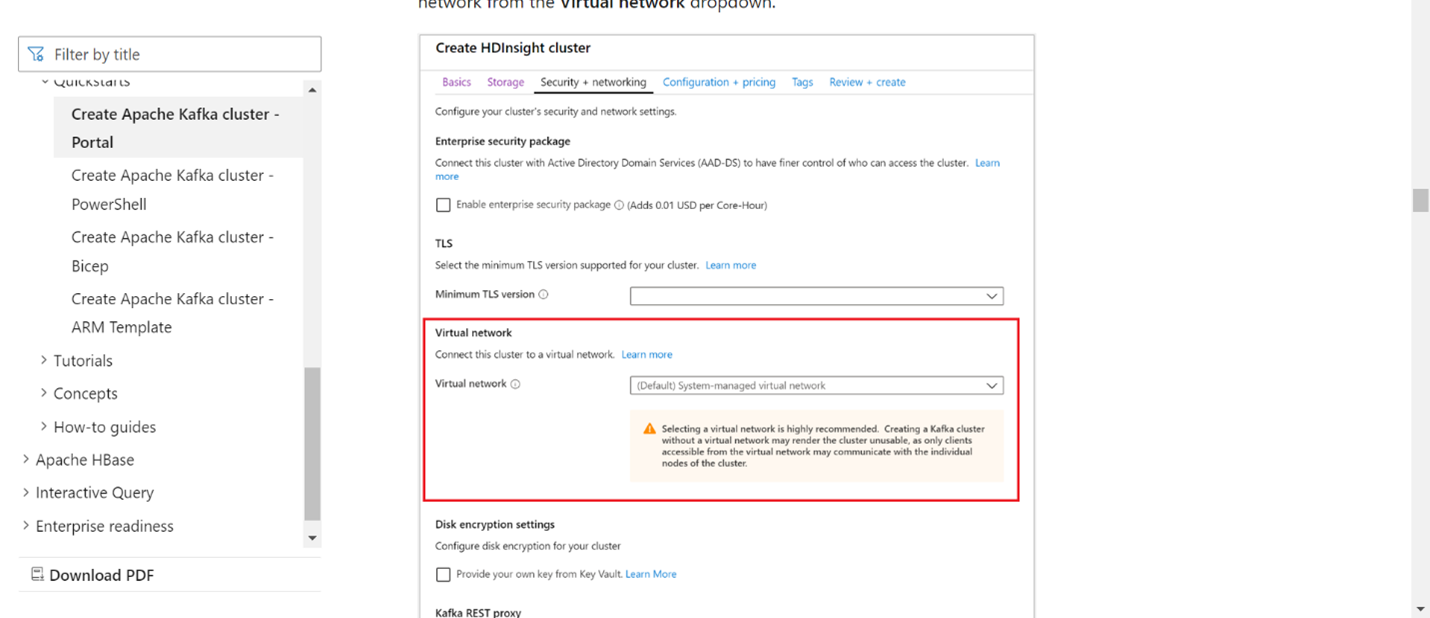
Do části Virtuální síť přidejte podrobnosti o virtuální síti.
Vytvořte HDInsight ve fondu clusterů AKS se stejným VNet.
Vytvořte cluster Flink v již vytvořeném fondu clusterů.

Konektor Apache Kafka
Flink poskytuje konektor Apache Kafka pro čtení dat z témat Kafka a zápis dat do témat Kafka s přesně jednou zárukou.
Maven závislost
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Sestavení jímky Kafka
Kafka sink poskytuje třídu builder pro vytvoření instance KafkaSink. Používáme totéž k vytvoření jímky a jejímu použití společně s clusterem Flink běžícím v HDInsight v AKS.
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Vytváření programu v Javě Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Zabalte soubor JAR a odešlete úlohu do Flinku.
Na webu Webssh nahrajte soubor JAR a odešlete soubor JAR.

V uživatelském rozhraní řídicího panelu Flink

Vytvoření tématu – kliknutí na Kafka

Spotřebovávat téma – události v systému Kafka

Odkaz
- Konektor Apache Kafka
- Názvy projektů Apache, Apache Kafka, Kafka, Apache Flink, Flink a přidružených open-source projektů jsou ochranné známkyApache Software Foundation (ASF).