Rychlý start: Zachycení dat služby Event Hubs ve službě Azure Storage a jejich čtení pomocí Pythonu (azure-eventhub)
Centrum událostí můžete nakonfigurovat tak, aby se data odesílaná do centra událostí zaznamenávala v účtu úložiště Azure nebo v Azure Data Lake Storage Gen 1 nebo Gen2. V tomto článku se dozvíte, jak napsat kód Pythonu pro odesílání událostí do centra událostí a čtení zachycených dat ze služby Azure Blob Storage. Další informace o této funkci najdete v tématu Přehled funkce Event Hubs Capture.
V tomto rychlém startu se k předvedení funkce Capture používá sada Azure Python SDK . Aplikace sender.py odesílá simulovaná telemetrická data prostředí do center událostí ve formátu JSON. Centrum událostí je nakonfigurováno tak, aby používalo funkci Capture k zápisu těchto dat do úložiště objektů blob v dávkách. Aplikace capturereader.py tyto objekty blob načte a vytvoří pro každé zařízení soubor připojení. Aplikace pak zapíše data do souborů CSV.
V tomto rychlém startu:
- Na webu Azure Portal vytvořte účet služby Azure Blob Storage a kontejner.
- Vytvořte obor názvů služby Event Hubs pomocí webu Azure Portal.
- Vytvořte centrum událostí s povolenou funkcí Capture a připojte ho k účtu úložiště.
- Odešlete data do centra událostí pomocí skriptu Pythonu.
- Čtení a zpracování souborů ze služby Event Hubs Capture pomocí jiného skriptu Pythonu
Požadavky
Python 3.8 nebo novější s nainstalovaným a aktualizovaným pipem
Předplatné Azure. Pokud ho nemáte, vytvořte si bezplatný účet před tím, než začnete.
Aktivní obor názvů služby Event Hubs a centrum událostí. Vytvořte obor názvů služby Event Hubs a centrum událostí v oboru názvů. Poznamenejte si název oboru názvů služby Event Hubs, název centra událostí a primární přístupový klíč pro obor názvů. Přístupový klíč získáte v tématu Získání služby Event Hubs připojovací řetězec. Výchozí název klíče je RootManageSharedAccessKey. Pro účely tohoto rychlého startu potřebujete jenom primární klíč. Nepotřebujete připojovací řetězec.
Účet úložiště Azure, kontejner objektů blob v účtu úložiště a připojovací řetězec k účtu úložiště. Pokud tyto položky nemáte, proveďte následující kroky:
- Vytvoření účtu úložiště Azure
- Vytvoření kontejneru objektů blob v účtu úložiště
- Získání připojovací řetězec k účtu úložiště
Nezapomeňte zaznamenat název připojovací řetězec a kontejneru pro pozdější použití v tomto rychlém startu.
Povolení funkce Capture pro centrum událostí
Povolte funkci Capture pro centrum událostí. Postupujte podle pokynů v tématu Povolení funkce Event Hubs Capture pomocí webu Azure Portal. Vyberte účet úložiště a kontejner objektů blob, který jste vytvořili v předchozím kroku. Vyberte Avro pro formát serializace výstupní události.
Vytvoření skriptu Pythonu pro odesílání událostí do centra událostí
V této části vytvoříte skript Pythonu, který odesílá 200 událostí (10 zařízení * 20 událostí) do centra událostí. Tyto události představují ukázkové čtení prostředí odeslané ve formátu JSON.
Otevřete oblíbený editor Pythonu, například Visual Studio Code.
Vytvořte skript s názvem sender.py.
Do sender.py vložte následující kód.
import time import os import uuid import datetime import random import json from azure.eventhub import EventHubProducerClient, EventData # This script simulates the production of events for 10 devices. devices = [] for x in range(0, 10): devices.append(str(uuid.uuid4())) # Create a producer client to produce and publish events to the event hub. producer = EventHubProducerClient.from_connection_string(conn_str="EVENT HUBS NAMESAPCE CONNECTION STRING", eventhub_name="EVENT HUB NAME") for y in range(0,20): # For each device, produce 20 events. event_data_batch = producer.create_batch() # Create a batch. You will add events to the batch later. for dev in devices: # Create a dummy reading. reading = { 'id': dev, 'timestamp': str(datetime.datetime.utcnow()), 'uv': random.random(), 'temperature': random.randint(70, 100), 'humidity': random.randint(70, 100) } s = json.dumps(reading) # Convert the reading into a JSON string. event_data_batch.add(EventData(s)) # Add event data to the batch. producer.send_batch(event_data_batch) # Send the batch of events to the event hub. # Close the producer. producer.close()Ve skriptech nahraďte následující hodnoty:
- Nahraďte
EVENT HUBS NAMESPACE CONNECTION STRINGpřipojovací řetězec pro obor názvů služby Event Hubs. - Nahraďte
EVENT HUB NAMEnázvem centra událostí.
- Nahraďte
Spuštěním skriptu odešlete události do centra událostí.
Na webu Azure Portal můžete ověřit, že centrum událostí přijalo zprávy. V části Metriky přepněte do zobrazení Zprávy. Aktualizujte stránku, aby se graf aktualizoval. Zobrazení, že zprávy byly přijaty, může trvat několik sekund.
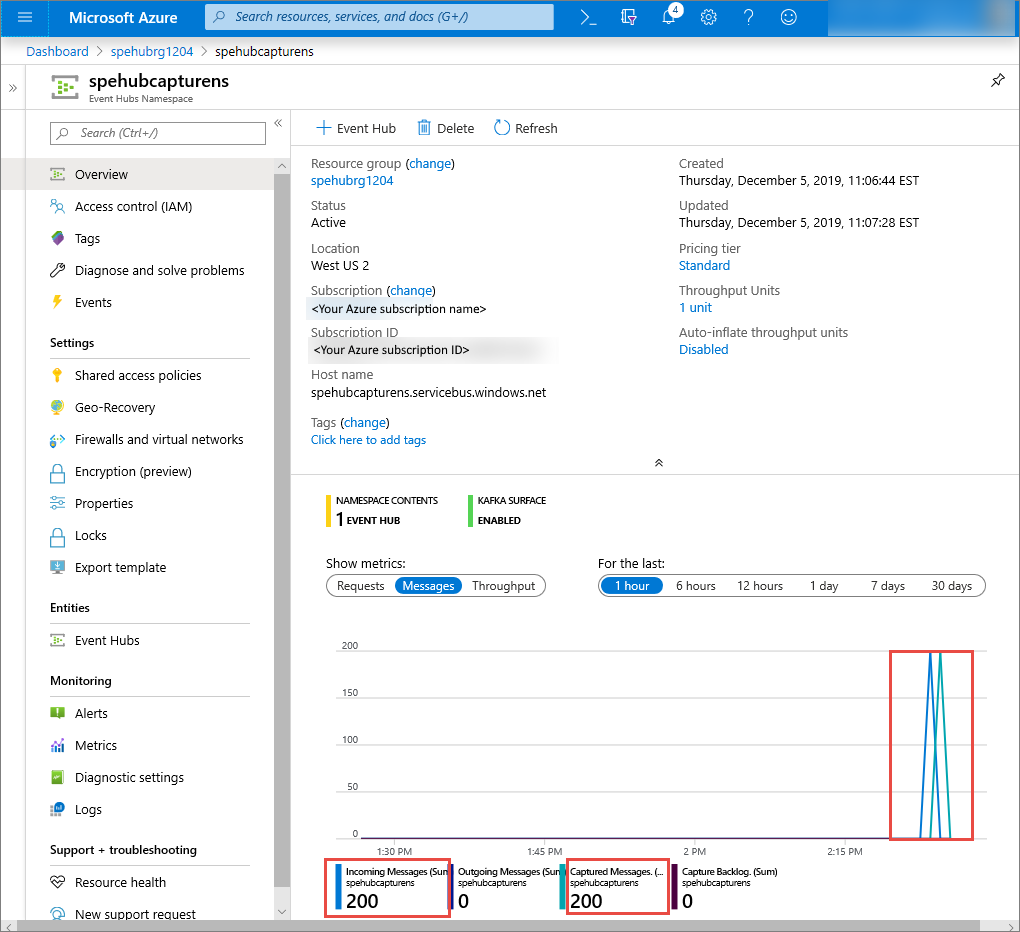

Vytvoření skriptu Pythonu pro čtení souborů Capture
V tomto příkladu se zachycená data ukládají ve službě Azure Blob Storage. Skript v této části načte zachycené datové soubory z účtu úložiště Azure a vygeneruje soubory CSV, abyste je mohli snadno otevřít a zobrazit. V aktuálním pracovním adresáři aplikace se zobrazí 10 souborů. Tyto soubory obsahují čtení prostředí pro 10 zařízení.
V editoru Pythonu vytvořte skript s názvem capturereader.py. Tento skript přečte zachycené soubory a vytvoří soubor pro každé zařízení, aby zapisoval data jenom pro dané zařízení.
Do capturereader.py vložte následující kód.
import os import string import json import uuid import avro.schema from azure.storage.blob import ContainerClient, BlobClient from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def processBlob2(filename): reader = DataFileReader(open(filename, 'rb'), DatumReader()) dict = {} for reading in reader: parsed_json = json.loads(reading["Body"]) if not 'id' in parsed_json: return if not parsed_json['id'] in dict: list = [] dict[parsed_json['id']] = list else: list = dict[parsed_json['id']] list.append(parsed_json) reader.close() for device in dict.keys(): filename = os.getcwd() + '\\' + str(device) + '.csv' deviceFile = open(filename, "a") for r in dict[device]: deviceFile.write(", ".join([str(r[x]) for x in r.keys()])+'\n') def startProcessing(): print('Processor started using path: ' + os.getcwd()) # Create a blob container client. container = ContainerClient.from_connection_string("AZURE STORAGE CONNECTION STRING", container_name="BLOB CONTAINER NAME") blob_list = container.list_blobs() # List all the blobs in the container. for blob in blob_list: # Content_length == 508 is an empty file, so process only content_length > 508 (skip empty files). if blob.size > 508: print('Downloaded a non empty blob: ' + blob.name) # Create a blob client for the blob. blob_client = ContainerClient.get_blob_client(container, blob=blob.name) # Construct a file name based on the blob name. cleanName = str.replace(blob.name, '/', '_') cleanName = os.getcwd() + '\\' + cleanName with open(cleanName, "wb+") as my_file: # Open the file to write. Create it if it doesn't exist. my_file.write(blob_client.download_blob().readall()) # Write blob contents into the file. processBlob2(cleanName) # Convert the file into a CSV file. os.remove(cleanName) # Remove the original downloaded file. # Delete the blob from the container after it's read. container.delete_blob(blob.name) startProcessing()Nahraďte
AZURE STORAGE CONNECTION STRINGpřipojovací řetězec pro váš účet úložiště Azure. Název kontejneru, který jste vytvořili v tomto rychlém startu, je zaznamenán. Pokud jste pro kontejner použili jiný název, nahraďte zachytávání názvem kontejneru v účtu úložiště.
Spuštění skriptů
Otevřete příkazový řádek, který má Python v cestě, a spuštěním těchto příkazů nainstalujte požadované balíčky Pythonu:
pip install azure-storage-blob pip install azure-eventhub pip install avro-python3Změňte adresář na adresář, do kterého jste uložili sender.py a capturereader.py, a spusťte tento příkaz:
python sender.pyTento příkaz spustí nový proces Pythonu, který spustí odesílatele.
Počkejte několik minut, než se zachycení spustí, a pak do původního příkazového okna zadejte následující příkaz:
python capturereader.pyTento procesor zachytávání používá místní adresář ke stažení všech objektů blob z účtu úložiště a kontejneru. Zpracovává soubory, které nejsou prázdné, a výsledky zapisuje jako soubory CSV do místního adresáře.
Další kroky
Projděte si ukázky Pythonu na GitHubu.