Typy vizualizací
Tento článek popisuje typy vizualizací, které jsou k dispozici v poznámkových blocích Azure Databricks a v Sql Databricks, a ukazuje, jak vytvořit příklad jednotlivých typů vizualizací.
Poznámka:
Další informace o typech vizualizací dostupných pro řídicí panely AI/BI najdete v tématu typy vizualizací řídicích panelů.
Sloupcový diagram
Pruhové grafy znázorňují změnu metrik v průběhu času nebo zobrazují proporcionalitu, podobně jako výsečový graf.
Poznámka:
Pruhové grafy podporují back-endové agregace, které poskytují podporu pro dotazy vracející více než 64 tisíc dat bez zkrácení výsledku set.
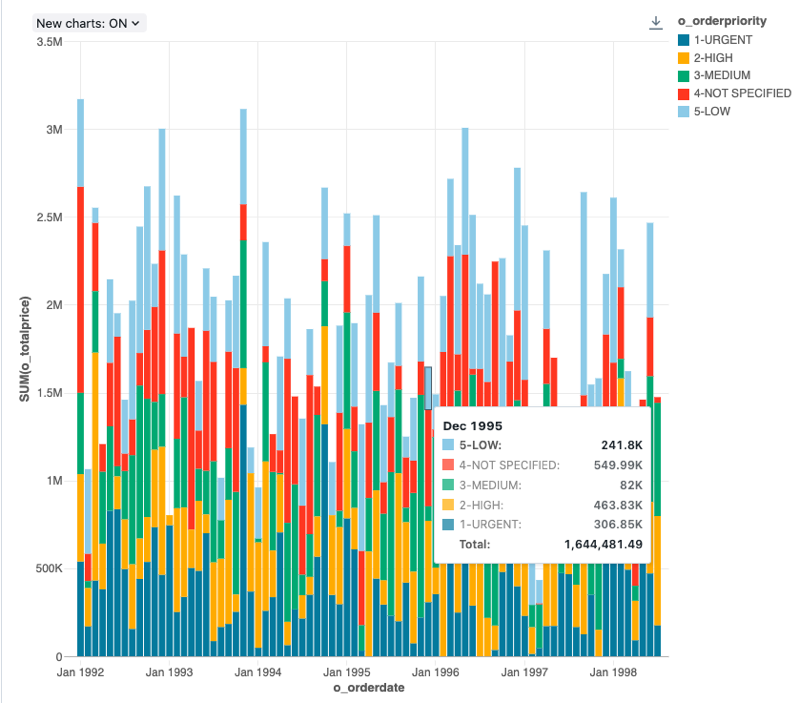
Konfigurace values: Pro vizualizaci tohoto pruhového grafu byly následující valuesset:
- X column:
- Datová sada column:
o_orderdate - Úroveň data:
Months
- Datová sada column:
- Y columns:
- Dataset column:
o_totalprice - Typ agregace:
Sum
- Dataset column:
- Seskupit podle datové sady (column):
o_orderpriority - Stohování:
Stack - Název osy X (přepsání výchozí hodnoty):
Order month - Název osy Y (přepsat výchozí hodnotu):
Total price
Možnosti konfigurace: Možnosti konfigurace pruhového grafu najdete v tématu Možnosti konfigurace grafu.
dotaz SQL: Pro tuto vizualizaci pruhového grafu se k generate dat setpoužil následující dotaz SQL.
select * from samples.tpch.orders
Spojnicový graf
Spojnicové grafy představují změnu v jedné nebo více metrikách v průběhu času.
Poznámka:
Spojnicové grafy podporují backendové agregace, které poskytují podporu pro dotazy vracejících více než 64 tisíc řádků dat bez zkrácení výsledku set.
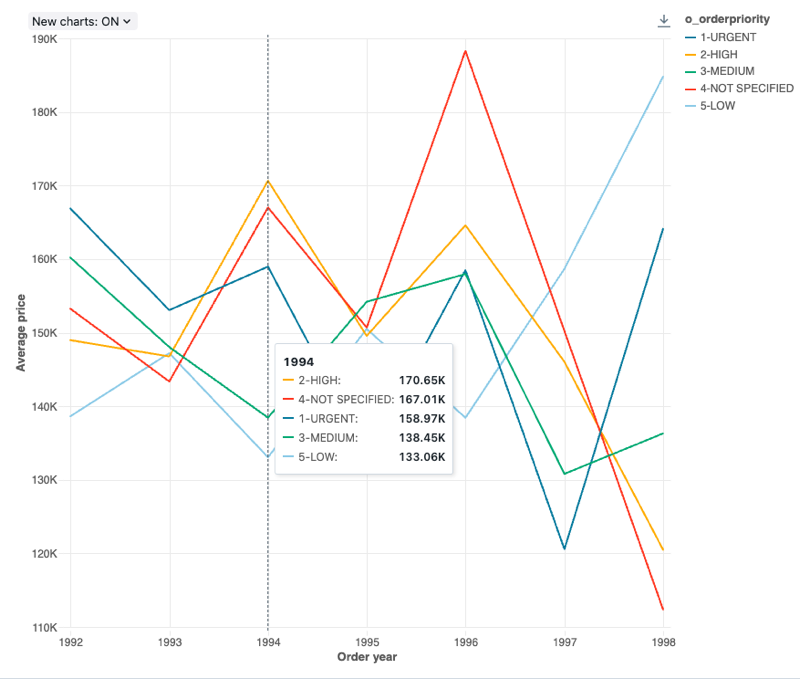
konfigurace values: Pro tuto vizualizaci spojnicového grafu byly setnásledující values:
- X column:
- Dataset column:
o_orderdate - Úroveň data:
Years
- Dataset column:
- Y columns:
- Datová sada column:
o_totalprice - Typ agregace:
Average
- Datová sada column:
- Seskupit podle (datová sada column):
o_orderpriority - Název osy X (přepsání výchozí hodnoty):
Order year - Název osy Y (přepsat výchozí hodnotu):
Average price
Možnosti konfigurace: Možnosti konfigurace spojnicového grafu najdete v tématu Možnosti konfigurace grafu.
SQL dotaz: Pro tuto vizualizaci spojnicového grafu se k generate datům setpoužil následující SQL dotaz.
select * from samples.tpch.orders
Plošný graf
Plošné grafy kombinují spojnicový a pruhový graf, aby ukázaly, jak se číselné values jedné nebo více skupin mění v průběhu druhé proměnné, obvykle podle času. Často se používají k zobrazení změn trychtýře prodeje v čase.
Poznámka:
Plošné grafy podporují backendové agregace, které poskytují podporu pro dotazy vracející více než 64 tisíc řádků dat bez zkrácení výsledků set.
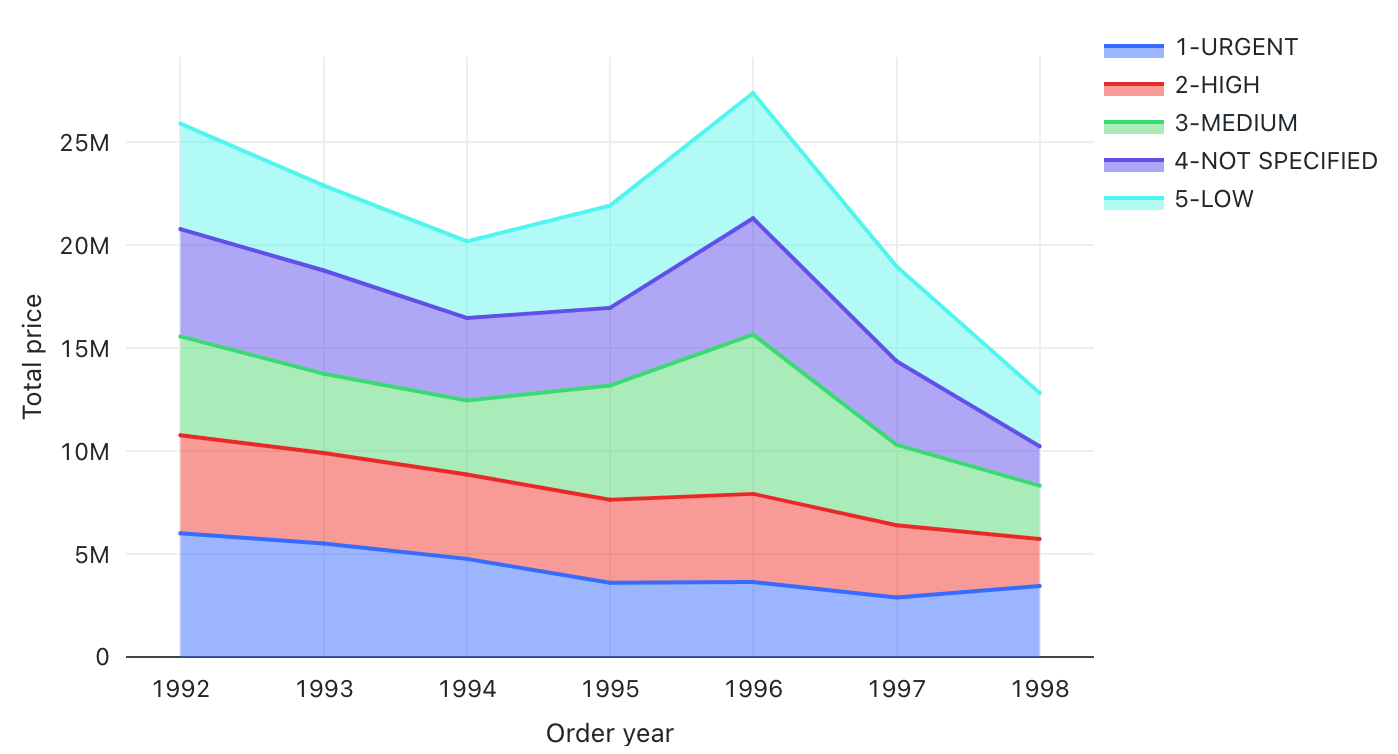
Konfigurace values: Pro tuto vizualizaci plošného diagramu byly následující valuesset:
- X column:
- Datová sada column:
o_orderdate - Úroveň data:
Years
- Datová sada column:
- Y columns:
-
columndatová sada:
o_totalprice - Typ agregace:
Sum
-
columndatová sada:
- Seskupte podle datové sady column:
o_orderpriority - Stohování:
Stack - Název osy X (přepsání výchozí hodnoty):
Order year - Název osy Y (přepsat výchozí hodnotu):
Total price
Možnosti konfigurace: Možnosti konfigurace plošných grafů najdete v tématu Možnosti konfigurace grafu.
dotaz SQL: Pro tuto vizualizaci plošného grafu se k generate dat setpoužil následující dotaz SQL.
select * from samples.tpch.orders
Výsečové grafy
Výsečové grafy zobrazují proporcionalitu mezi metrikami. Nejsou určeny pro předávání dat časových řad.
Poznámka:
Výsečové grafy podporují backendové agregace pro dotazy vracející více než 64 000 řádků dat, aniž by došlo ke zkrácení výsledku set.
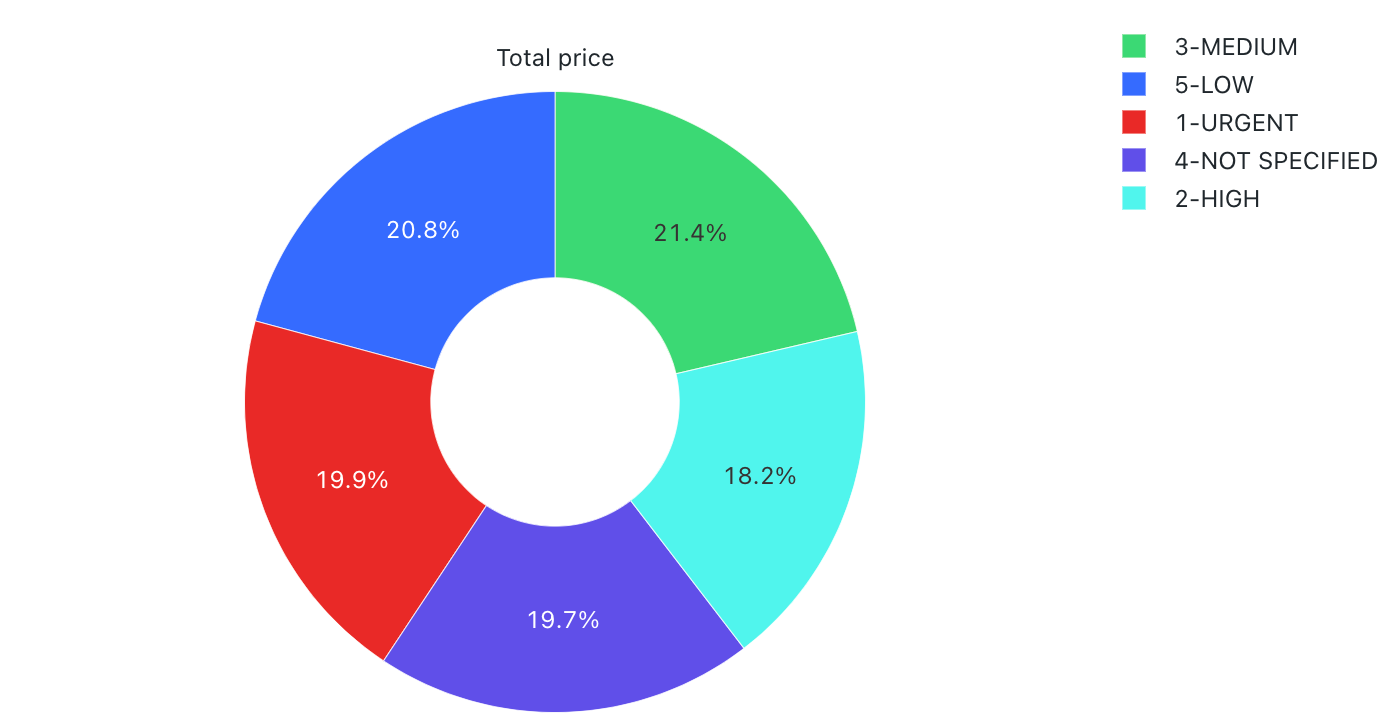
konfigurace values: Pro tuto vizualizaci výsečového grafu byly následující valuesset:
- X column (datová sada column):
o_orderpriority - Y columns:
- Datová sada column:
o_totalprice - Typ agregace:
Sum
- Datová sada column:
- Popisek (přepsání výchozí hodnoty):
Total price
Možnosti konfigurace: Možnosti konfigurace výsečového grafu najdete v tématu Možnosti konfigurace grafu.
dotaz SQL: Pro tuto vizualizaci výsečového grafu se k generate dat setpoužil následující dotaz SQL.
select * from samples.tpch.orders
Histogramové grafy
Histogram vykreslí frekvenci výskytu dané hodnoty v datové sadě. Histogram vám pomůže pochopit, jestli datová sada obsahuje values, které jsou seskupené kolem malého počtu rozsahů nebo jsou rozprostřenější. Histogram se zobrazí jako pruhový graf, ve kterém řídíte počet jednotlivých pruhů (označovaných také jako intervaly).
Poznámka:
Grafy histogramů podporují back-endové agregace a poskytují podporu pro dotazy vracející více než 64 tisíc řádků dat bez zkrácení výsledku set.
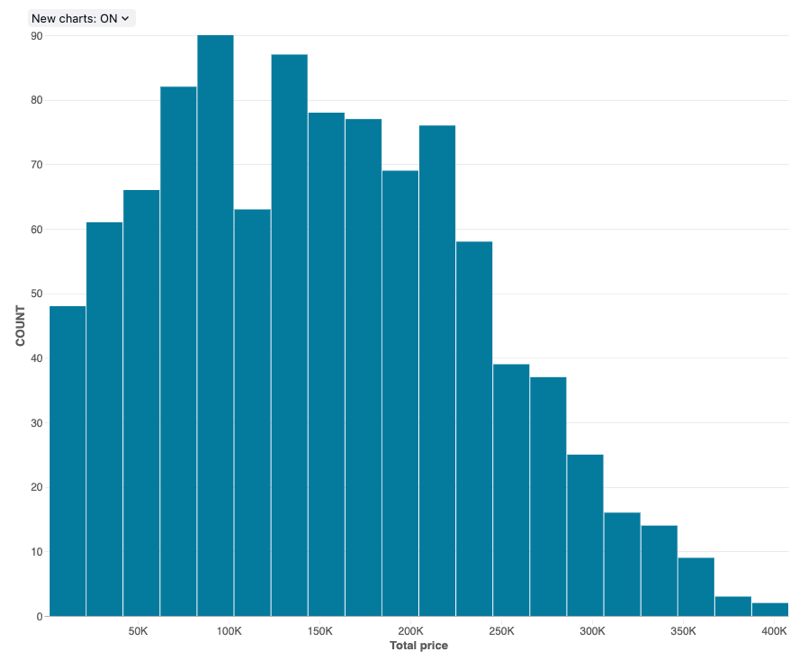
konfigurace values: Pro vizualizaci histogramu byly následující valuesset:
- X column (datová sada column):
o_totalprice - Počet intervalů: 20
- Název osy X (přepsání výchozí hodnoty):
Total price
Možnosti konfigurace: Možnosti konfigurace histogramu grafu najdete v tématu možnosti konfigurace histogramu.
dotaz SQL: Pro tuto vizualizaci histogramu se k generate dat setpoužil následující dotaz SQL.
select * from samples.tpch.orders
Heatmap chart
Heatmapové grafy kombinují funkce pruhových grafů, skládacích a bublinových grafů, které umožňují vizualizovat číselná data pomocí barev. Běžná barevná paleta pro heat mapu zobrazuje nejvyšší values pomocí teplejších barev, jako je oranžová nebo červená, a nejnižší values pomocí chladnějších barev, jako je modrá nebo fialová.
Představte si například následující heat mapu, která vizualizuje nejčastěji se vyskytující vzdálenosti jízdy taxíkem v každém dni a seskupuje výsledky podle dne v týdnu, vzdálenosti a celkové jízdy.
Poznámka:
Heatmapové grafy podporují backendové agregace, které umožňují dotazy vracející více než 64 000 řádků dat bez zkrácení výsledků set.
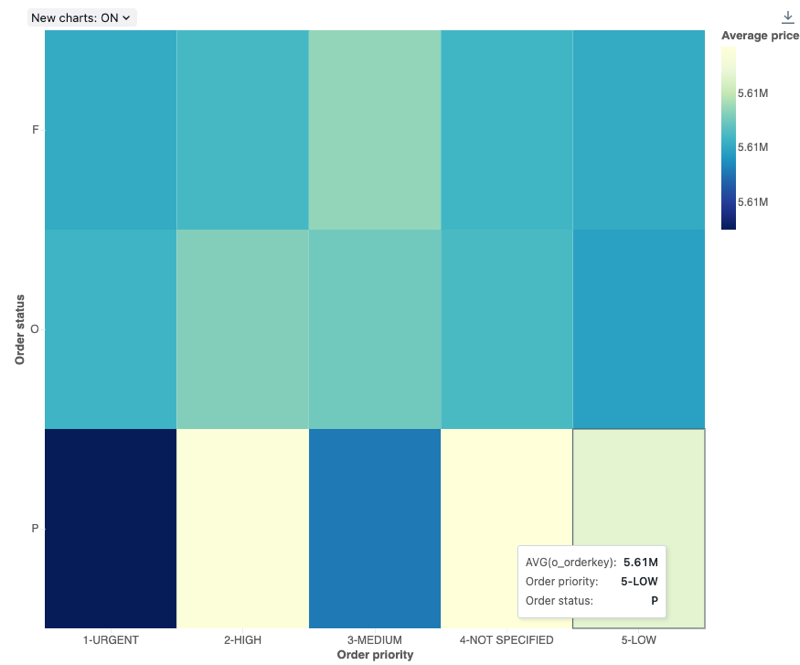
Konfigurace values: Pro tuto vizualizaci heatmapy byly setnásledující values:
- X column (datová sada column):
o_orderpriority - Y columns (columndatové sady):
o_orderstatus - Barva column:
-
columndatová sada:
o_totalprice - Typ agregace:
Average
-
columndatová sada:
- Název osy X (přepsání výchozí hodnoty):
Order priority - Název osy Y (přepsat výchozí hodnotu):
Order status - Název barvy (přepsat výchozí hodnotu):
Average price - Barevné schéma (přepsat výchozí hodnotu):
YIGnBu
Možnosti konfigurace: Možnosti konfigurace heat mapy najdete v tématu Možnosti konfigurace grafu heat mapy.
dotaz SQL: Pro tuto vizualizaci teplotní mapy byl k generate datům setpoužit následující dotaz SQL.
select * from samples.tpch.orders
Bodový graf
Bodové vizualizace se běžně používají k zobrazení vztahu mezi dvěma číselnými proměnnými. Kromě toho lze třetí dimenzi zakódovat barvou, aby bylo vidět, jak se číselné proměnné liší mezi skupinami.
Poznámka:
Bodové grafy podporují back-endové agregace, které poskytují podporu pro dotazy vracející více než 64 tisíc řádků dat bez zkrácení výsledku set.
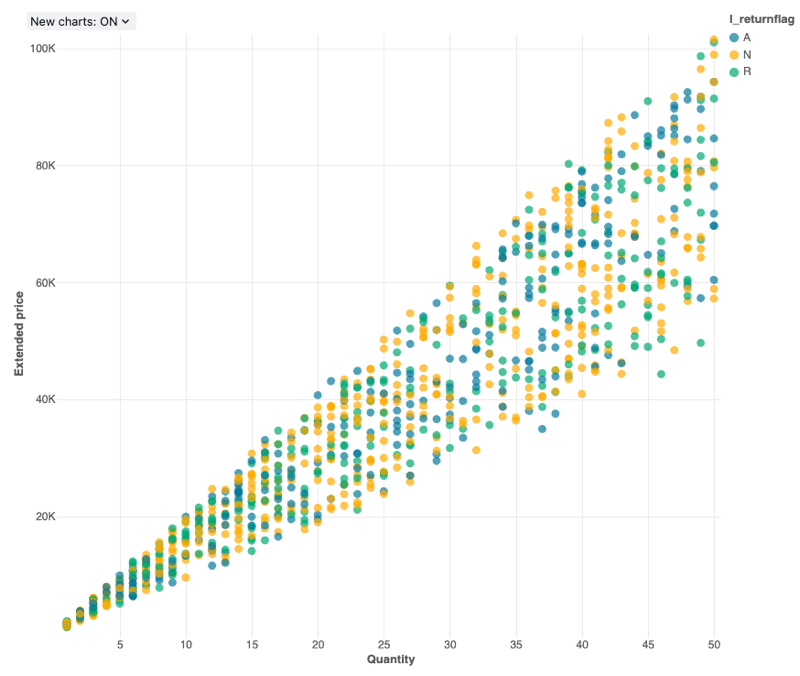
Konfigurace values: Pro tuto vizualizaci bodového grafu byly setnásledující values:
- X column (datová sada column):
l_quantity - Y column (datové sady column):
l_extendedprice - Seskupte podle datové sady column:
l_returnflag - Název osy X (přepsání výchozí hodnoty):
Quantity - Název osy Y (přepsat výchozí hodnotu):
Extended price
Možnosti konfigurace: Možnosti konfigurace bodového grafu najdete v tématu Možnosti konfigurace grafu.
dotaz SQL: Pro tuto vizualizaci bodového grafu se k generate dat setpoužil následující dotaz SQL.
select * from samples.tpch.lineitem
Bublinový graf
Bublinové grafy patří mezi bodové grafy where, přičemž velikost každé značky bodu odráží relevantní metriku.
Poznámka:
Bublinové grafy podporují back-endové agregace, které poskytují podporu pro dotazy vracející více než 64 tisíc dat bez zkrácení výsledku set.
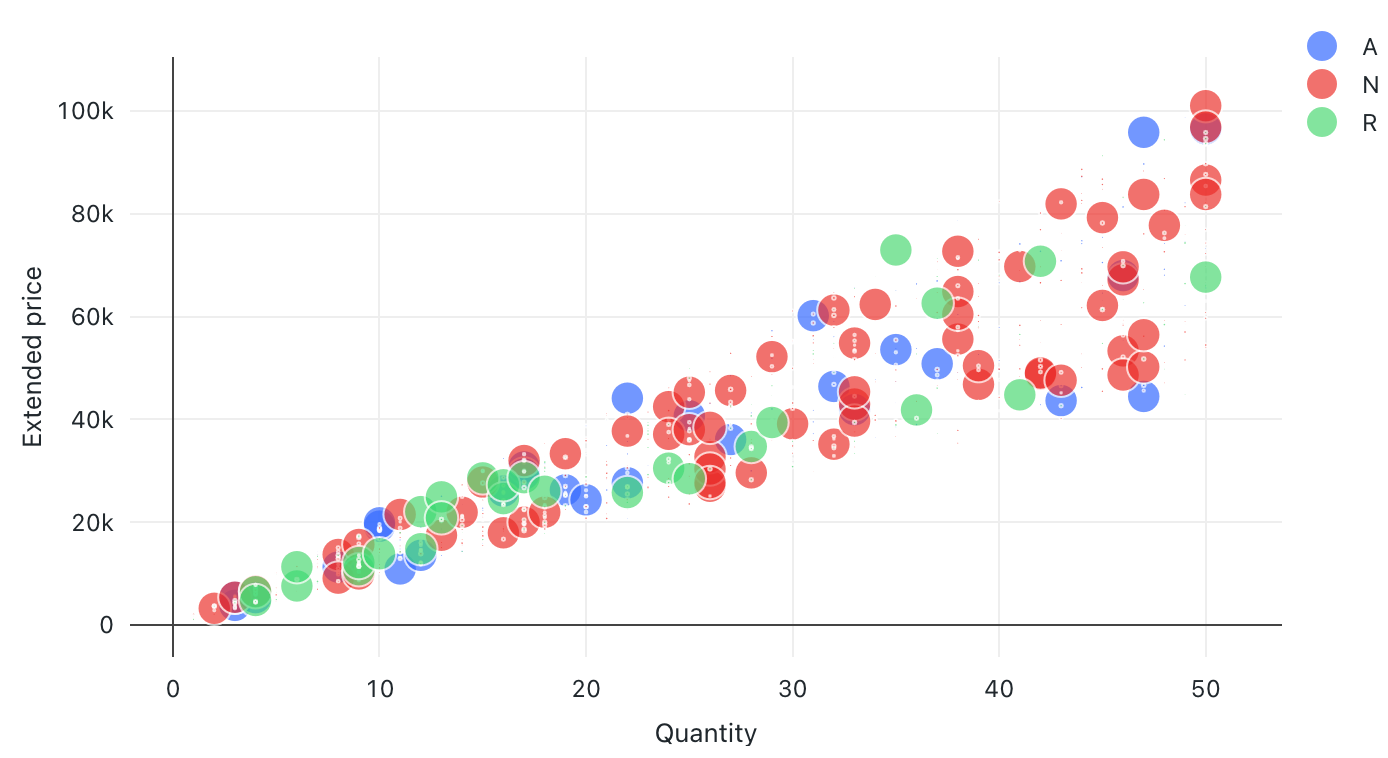
Konfigurace values: Pro tuto vizualizaci bublinového grafu byly následující položky valuesset:
- X (datová sada column):
l_quantity - Y columns (columndatová sada):
l_extendedprice - Seskupte podle (datová sada column):
l_returnflag - Velikost bubliny column (datové sady column):
l_tax - Koeficient velikosti bublin: 20
- Proporcionální velikost bubliny:
Area - Název osy X (přepsání výchozí hodnoty):
Quantity - Název osy Y (přepsat výchozí hodnotu):
Extended price
Možnosti konfigurace: Možnosti konfigurace bublinového grafu najdete v tématu Možnosti konfigurace grafu.
SQL dotaz: Pro vizualizaci tohoto bublinového grafu byl k generate datům setpoužit následující SQL dotaz.
select * from samples.tpch.lineitem where l_quantity < 45
Krabicový graf
Vizualizace krabicového grafu zobrazuje souhrn rozdělení číselných dat, volitelně seskupených podle kategorie. Pomocí vizualizace krabicového grafu můžete rychle porovnat rozsahy hodnot napříč kategoriemi a vizualizovat skupiny umístění, rozložení a nerovnoměrné distribuce values prostřednictvím jejich kvartilů. V každém rámečku zobrazuje tmavší čára oblast interquartilu. Další informace o interpretaci krabicových vizualizací grafů najdete v článku Box chart na Wikipedii.
Poznámka:
Krabicové grafy podporují agregaci až pro 64 000 řádků. Pokud je datová sada větší než 64 000 řádků, data budou zkrácena.
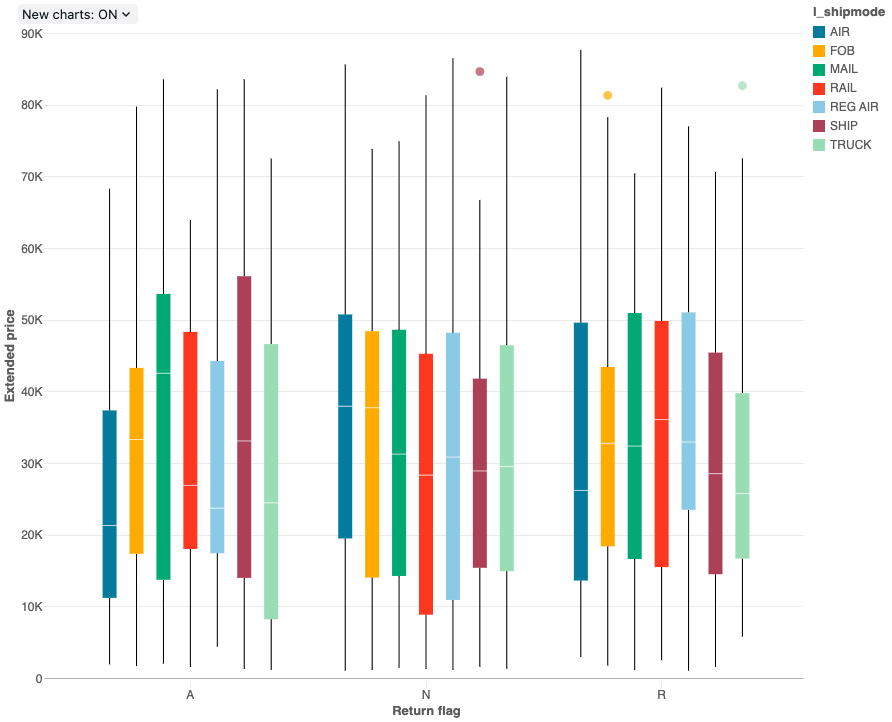
konfigurace values: Pro tuto vizualizaci krabicového diagramu byly setnásledující values:
- X column (datová sada column):
l_returnflag -
columns Y (columndatové sady):
l_extendedprice - Seskupení podle datové sady column:
l_shipmode - Název osy X (přepsání výchozí hodnoty):
Return flag - Název osy Y (přepsat výchozí hodnotu):
Extended price
Možnosti konfigurace: Možnosti konfigurace krabicového grafu najdete v tématu Možnosti konfigurace krabicového grafu.
dotaz SQL: Pro tuto vizualizaci krabicového grafu byl k generate dat setpoužit následující dotaz SQL.
select * from samples.tpch.lineitem
Kombinovaný graf
Kombinované grafy kombinují spojnicové a pruhové grafy a prezentují změny v průběhu času pomocí proporcionality.
Poznámka:
Kombinované grafy podporují back-endové agregace a poskytují podporu pro dotazy vracející více než 64 tisíc řádků dat bez zkrácení výsledku set.
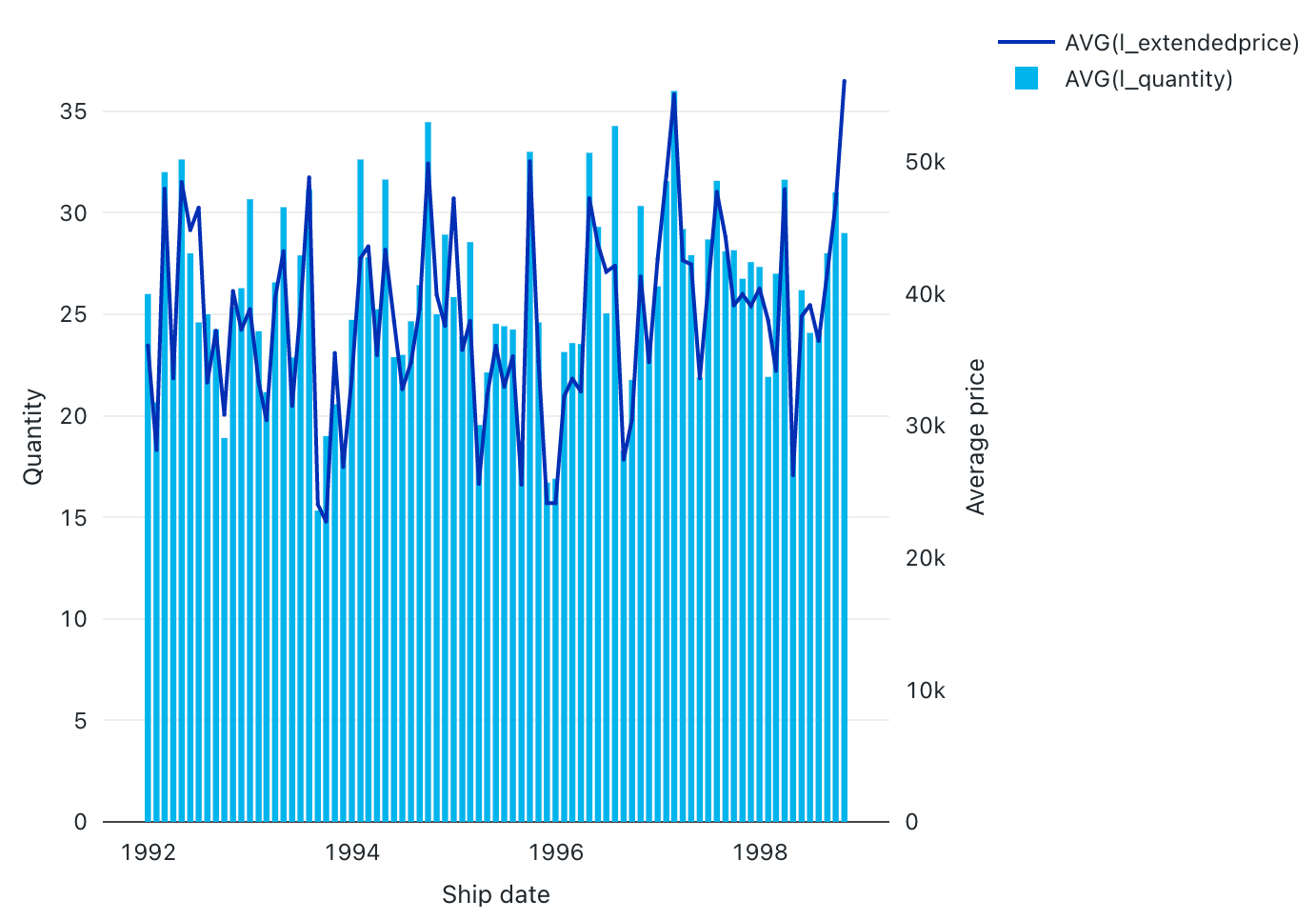
Konfigurace values: Pro tuto vizualizaci kombinovaného grafu byly následující valuesset:
- X column:
- Datová sada column:
l_shipdate - Úroveň data:
Months
- Datová sada column:
- Y columns:
- První datová sada column:
l_extendedprice - Typ agregace: průměr
- Druhá datová sada column:
l_quantity - Typ agregace: průměr
- První datová sada column:
- Název osy X (přepsání výchozí hodnoty):
Ship date - Název osy Y vlevo (přepsat výchozí hodnotu):
Quantity - Název osy Y vpravo (přepsat výchozí hodnotu):
Average price - Řada:
- Order1 (datová sada column):
AVG(l_extendedprice) - Osa Y: vpravo
- Typ: Čára
- Order2 (datová sada column):
AVG(l_quantity) - Osa Y: vlevo
- Typ: Pruh
- Order1 (datová sada column):
Možnosti konfigurace: Možnosti konfigurace kombinovaného grafu najdete v tématu Možnosti konfigurace grafu.
SQL dotaz: Pro tuto vizualizaci kombinovaného grafu byl použit následující SQL dotaz k generate dat set.
select * from samples.tpch.lineitem
Analýza kohorty
Analýza kohorty zkoumá výsledky předem určených skupin označovaných jako kohorty při procházení set fází. Vizualizace kohorty agreguje pouze data (umožňuje měsíční agregace). Neprovádí žádné jiné agregace dat v rámci výsledku set. Všechny ostatní agregace se provádějí v samotném dotazu.
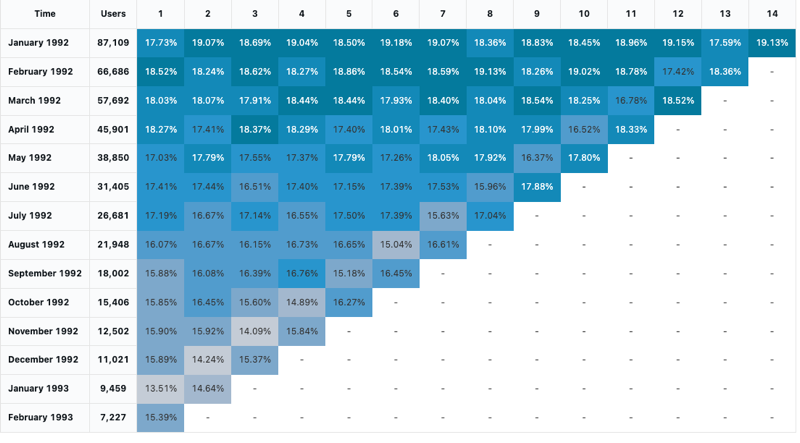
Konfigurace values: Pro tuto vizualizaci skupiny byly následující valuesset:
- Datum (kategorie) (databáze column):
cohort_month - Fáze (databáze column):
months - Velikost bucketu v databázi (column):
size - Hodnota fáze z databáze column:
active - Časový interval:
monthly
Možnosti konfigurace: Možnosti konfigurace kohorty najdete v tématu Možnosti konfigurace kohorty grafu.
dotaz SQL: Pro tuto vizualizaci kohorty byl použit následující dotaz SQL k generate dat set.
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
Zobrazení čítače
Čítače zobrazují jednu hodnotu zřetelně s možností jejich porovnání s cílovou hodnotou. Chcete-li použít čítače, určete, který řádek dat se má zobrazit ve vizualizaci čítače pro hodnotu Column a cílovou hodnotu Column.
Poznámka:
Čítač podporuje pouze agregaci až pro 64 000 řádků. Pokud je datová sada větší než 64 000 řádků, data budou zkrácena.
Konfigurace values: Pro tuto vizualizaci čítače byly následující valuesset:
- Hodnota column
- Datová sada column:
avg(o_totalprice) - Řádek 1:
- Datová sada column:
- Cílová column:
- Sada dat column:
avg(o_totalprice) - Řádek 2:
- Sada dat column:
- Formát cílové hodnoty: Povolit
dotaz SQL: Pro tuto vizualizaci čítačů se k generate dat setpoužil následující dotaz SQL.
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
Trychtýřová vizualizace
Vizualizace trychtýře pomáhá analyzovat změnu metriky v různých fázích. Chcete-li použít trychtýř, zadejte step a valuecolumn.
Poznámka:
Trychtýř podporuje agregaci až pro 64 000 řádků. Pokud je datová sada větší než 64 000 řádků, data budou zkrácena.
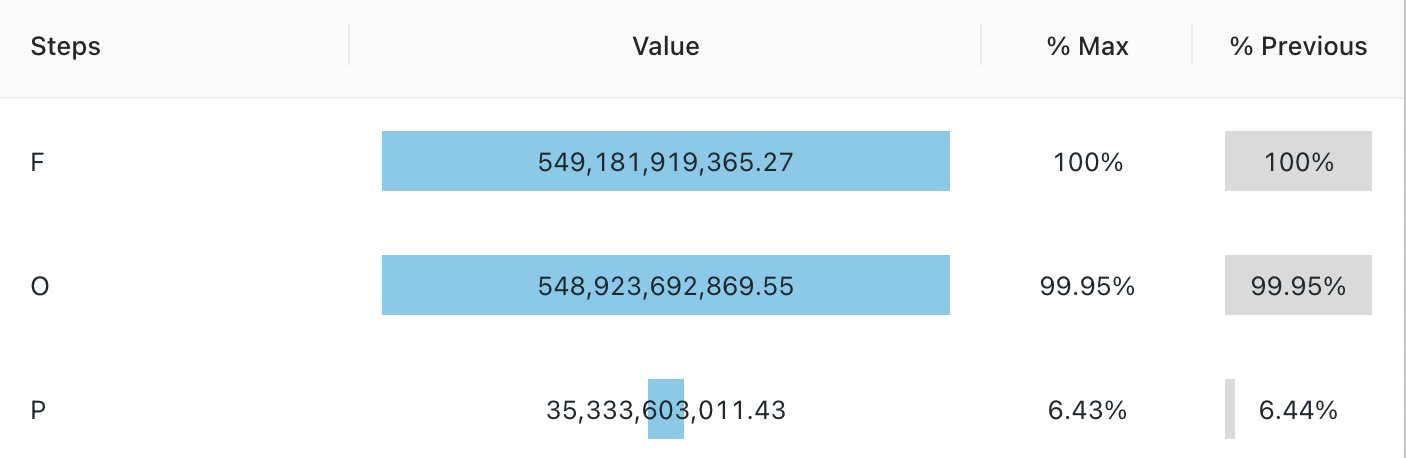
konfigurace values: Pro tuto vizualizaci trychtýře byly následující valuesset:
- Krok column (datové sady column):
o_orderstatus - Hodnota column (datová sada column):
Revenue
dotaz SQL: Pro tuto trychtýřovou vizualizaci byl k generate dat setpoužit následující dotaz SQL.
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
Vizualizace mapy (Choropleth)
V choropleth vizualizacích jsou zeměpisné lokality, jako jsou země nebo státy, obarvené podle agregované values každého klíčového column. Dotaz musí vracet geografická umístění podle názvu.
Poznámka:
Vizualizace Choropleth nedělají žádné agregace dat v rámci výsledku set. Všechny agregace se musí vypočítat v samotném dotazu.
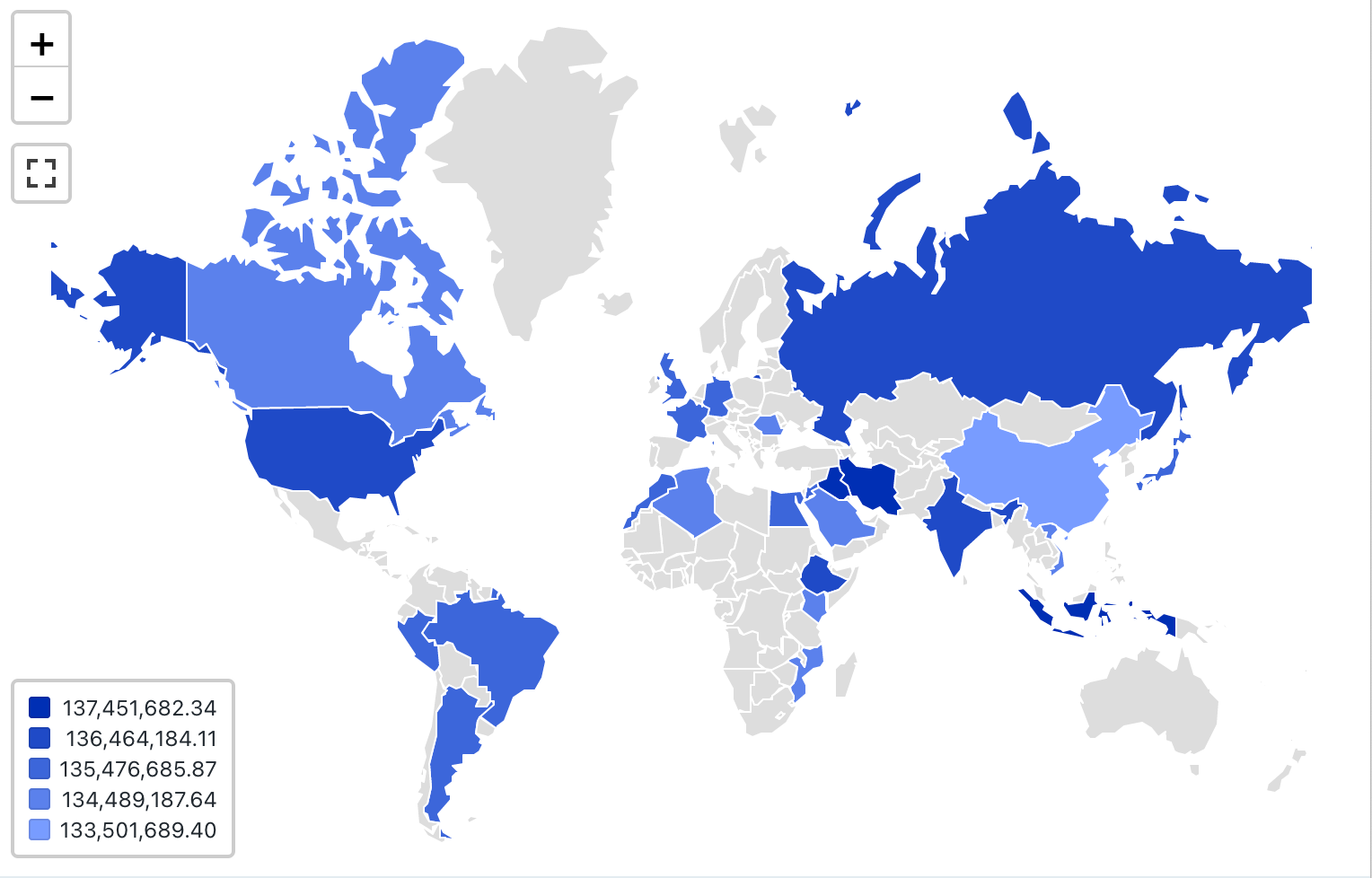
konfigurace values: Pro tuto vizualizaci choropleth byly setnásledující values:
- Mapa (datová sada column):
Countries - Geografická column (datová sada column):
Country - Zeměpisný typ: Krátký název
- Hodnota column (datová sada column):
Revenue - Režim clusteringu: ekvividantní
Možnosti konfigurace: Možnosti konfigurace choropleth najdete v tématu možnosti konfigurace choropleth.
Dotaz SQL: Pro tuto choroplethovou vizualizaci se použil následující SQL dotaz pro generate dat set.
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
Vizualizace mapy značek
Ve vizualizacích značek se značka umístí na set souřadnic na mapě. Výsledek dotazu musí vracet páry zeměpisné šířky a délky.
Poznámka:
Marker neprovádí žádné agregace dat ve výsledku set. Všechny agregace se musí vypočítat v samotném dotazu.
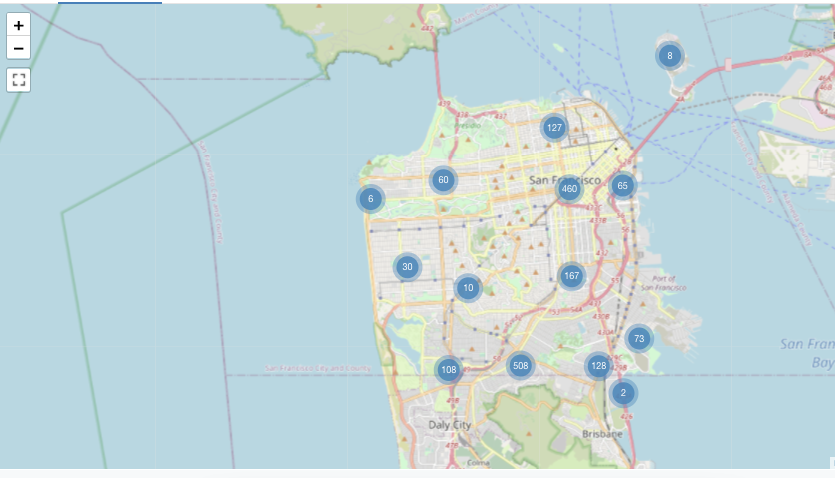
Tento příklad značky se vygeneruje z datové sady, která zahrnuje values zeměpisné šířky i délky – které nejsou dostupné v ukázkových datových sadách Databricks. Možnosti konfigurace choropleth najdete v tématu Možnosti konfigurace značek.
vizualizace Pivottable
Vizualizace pivottable agreguje záznamy z výsledku dotazu do nového tabulkového zobrazení. Podobá se PIVOT příkazům nebo GROUP BY příkazům v SQL. Vizualizaci pivottable nakonfigurujete přetažením polí.
Poznámka:
Pivot tables podporují back-endové agregace a poskytují podporu pro dotazy vracející více než 64 tisíc řádků dat bez zkrácení výsledku set. Pivot table (starší verze) však podporují agregaci až pro 64 000 řádků. Pokud je datová sada větší než 64 000 řádků, data budou zkrácena.
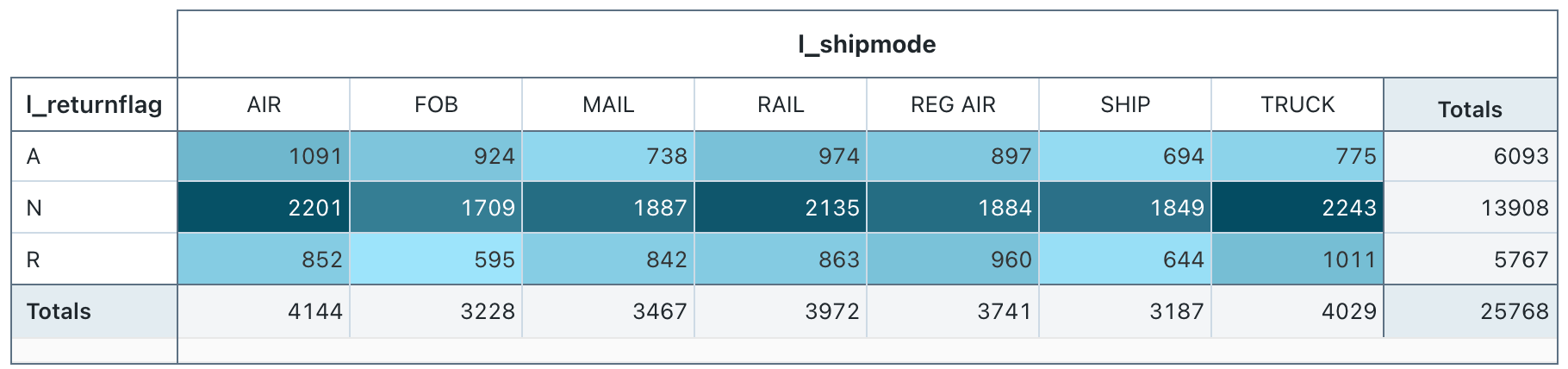
konfigurace values: Pro tuto vizualizaci byly následující pivottablevaluesset:
-
Select řádky datové sady column:
l_returnflag -
Select
columns (datové sady column):
l_shipmode - Buňka
- Datová sada column:
l_quantity - Typ agregace: Součet
- Barevné buňky podle hodnoty: Zapnuto
- Datová sada column:
dotaz SQL: Pro tuto vizualizaci pivottable se k generate dat setpoužil následující dotaz SQL.
select * from samples.tpch.lineitem
Sankey
Sankey diagram vizualizuje tok z jednoho set od values do druhého.
Poznámka:
Vizualizace Sankey neprovedou žádné agregace dat v rámci výsledku set. Všechny agregace se musí vypočítat v samotném dotazu.

dotaz SQL: Pro tuto vizualizaci Sankey se k generate dat setpoužil následující dotaz SQL.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Vícevrstvá sekvence
Vícevrstvý diagram pomáhá vizualizovat hierarchická data pomocí soustředných kruhů.
Poznámka:
Sunburst sekvence neprovádí žádné agregace dat v rámci výsledku set. Všechny agregace se musí vypočítat v samotném dotazu.
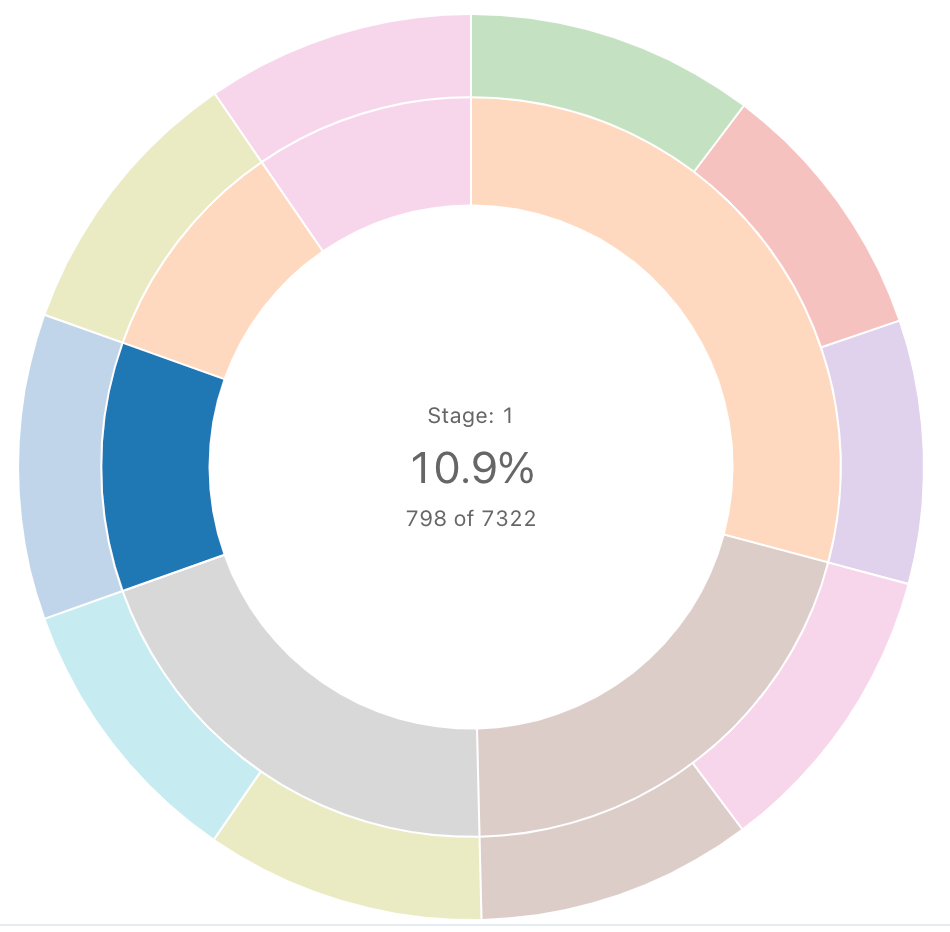
dotaz SQL: Pro tuto sunburst vizualizaci byl následující SQL dotaz použit k generate dat set.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Table
Vizualizace table zobrazuje data ve standardním table, ale s možností ručního uspořádání, skrytí a formátování dat. Podívejte se na Table možnosti.
Poznámka:
Table vizualizace neprovádějí žádné agregace dat ve výsledku set. Všechny agregace se musí vypočítat v samotném dotazu.
Informace o možnostech konfigurace table naleznete v tématu table možnosti konfigurace.
Word cloud
Word cloud vizuálně představuje frekvenci výskytu slova v datech.
Poznámka:
Word Cloud podporuje agregaci pouze pro 64 000 řádků. Pokud je datová sada větší než 64 000 řádků, data budou zkrácena.
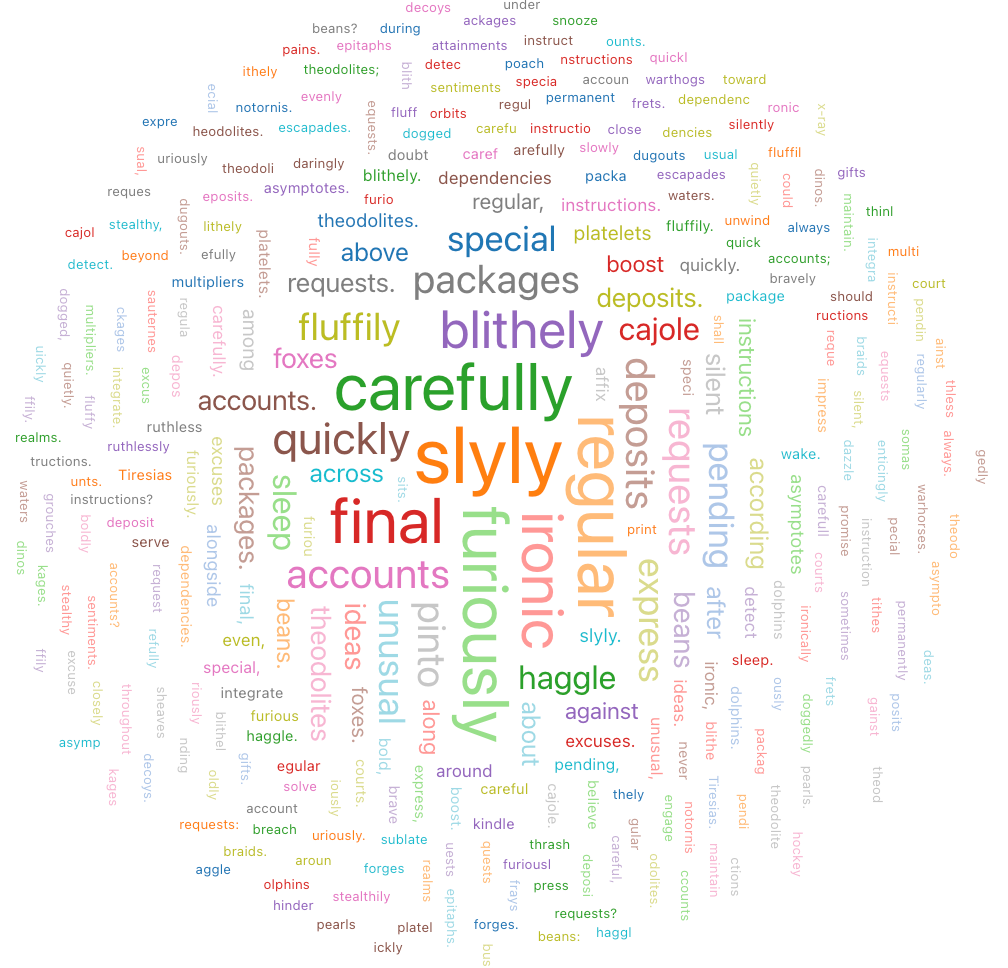
konfigurace values: Pro tuto vizualizaci slovního mraku byly setnásledující values: test
-
column slov (datová sada column):
o_comment - Délka slova Limit: Min = 5
- Frekvence limit: Min = 2
dotaz SQL: Pro tuto vizualizaci word cloudu byl použit k generate dat setnásledující dotaz SQL.
select * from samples.tpch.orders