Regionální zotavení po havárii pro clustery Azure Databricks
Tento článek popisuje architekturu zotavení po havárii, která je užitečná pro clustery Azure Databricks, a kroky k provedení tohoto návrhu.
Architektura Azure Databricks
Když vytvoříte pracovní prostor Azure Databricks z webu Azure Portal, spravovaná aplikace se ve vašem předplatném nasadí jako prostředek Azure ve zvolené oblasti Azure (například USA – západ). Toto zařízení se nasadí ve službě Azure Virtual Network se skupinou zabezpečení sítě a účtem Azure Storage, které je dostupné ve vašem předplatném. Virtuální síť poskytuje zabezpečení na úrovni hraniční sítě pracovnímu prostoru Databricks a je chráněná prostřednictvím skupiny zabezpečení sítě. V rámci pracovního prostoru vytvoříte clustery Databricks tím, že poskytnete typ virtuálního počítače pracovního procesu a ovladače a verzi modulu runtime Databricks. Trvalá data jsou k dispozici ve vašem účtu úložiště. Po vytvoření clusteru můžete úlohy spouštět prostřednictvím poznámkových bloků, rozhraní REST API nebo koncových bodů ODBC/JDBC tak, že je připojíte ke konkrétnímu clusteru.
Řídicí rovina Databricks spravuje a monitoruje prostředí pracovního prostoru Databricks. Z řídicí roviny se zahájí jakákoli operace správy, jako je například vytvoření clusteru. Všechna metadata, jako jsou naplánované úlohy, jsou uložená ve službě Azure Database a zálohy databází se automaticky replikují do spárovaných oblastí , ve kterých je implementovaná.
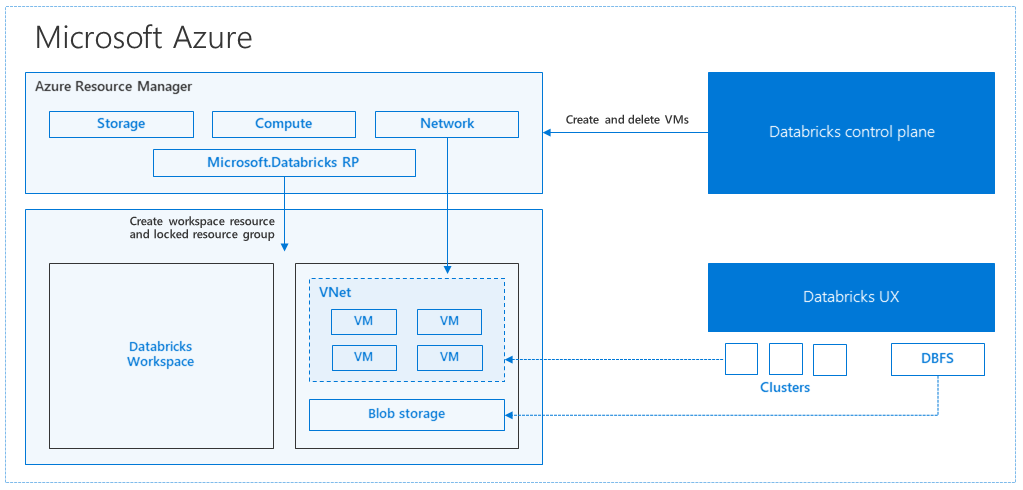
Jednou z výhod této architektury je, že uživatelé můžou azure Databricks připojit k libovolnému prostředku úložiště ve svém účtu. Klíčovou výhodou je, že výpočetní prostředky (Azure Databricks) i úložiště se dají škálovat nezávisle na sobě.
Vytvoření topologie zotavení po havárii v jednotlivých oblastech
V předchozím popisu architektury existuje celá řada komponent používaných pro kanál pro velké objemy dat s Azure Databricks: Azure Storage, Azure Database a další zdroje dat. Azure Databricks je výpočetní prostředky pro kanál pro velké objemy dat. Je dočasný v podstatě, což znamená, že i když jsou vaše data stále dostupná ve službě Azure Storage, výpočetní prostředky (cluster Azure Databricks) se dají ukončit, aby se zabránilo placení výpočetních prostředků, když je nepotřebujete. Výpočetní prostředky (Azure Databricks) a zdroje úložiště musí být ve stejné oblasti, aby úlohy nezískaly vysokou latenci.
Pokud chcete vytvořit vlastní topologii zotavení po havárii, postupujte podle těchto požadavků:
Zřízení několika pracovních prostorů Azure Databricks v samostatných oblastech Azure Vytvořte například primární pracovní prostor Azure Databricks v oblasti USA – východ. Vytvořte sekundární pracovní prostor Azure Databricks pro zotavení po havárii v samostatné oblasti, jako je USA – západ. Seznam spárovaných oblastí Azure najdete v tématu Replikace mezi oblastmi. Podrobnosti o oblastech Azure Databricks najdete v tématu Podporované oblasti.
Použijte geograficky redundantní úložiště. Ve výchozím nastavení se data přidružená k Azure Databricks ukládají ve službě Azure Storage a výsledky úloh Databricks se ukládají ve službě Azure Blob Storage, aby zpracovávaná data byla odolná a po ukončení clusteru zůstala vysoce dostupná. Úložiště clusteru a úložiště úloh se nacházejí ve stejné zóně dostupnosti. Kvůli ochraně před regionální nedostupností používají pracovní prostory Azure Databricks ve výchozím nastavení geograficky redundantní úložiště. S geograficky redundantním úložištěm se data replikují do spárované oblasti Azure. Databricks doporučuje zachovat výchozí geograficky redundantní úložiště, ale pokud místo toho potřebujete použít místně redundantní úložiště, můžete pro pracovní prostor nastavit
storageAccountSkuNamešablonuStandard_LRSARM .Po vytvoření sekundární oblasti musíte migrovat uživatele, uživatelské složky, poznámkové bloky, konfiguraci clusteru, konfiguraci úloh, knihovny, úložiště, inicializační skripty a překonfigurovat řízení přístupu. Další podrobnosti jsou popsané v následující části.
Regionální havárie
Pokud se chcete připravit na regionální havárie, musíte explicitně udržovat další sadu pracovních prostorů Azure Databricks v sekundární oblasti. Viz Zotavení po havárii.
Naše doporučené nástroje pro zotavení po havárii jsou hlavně Terraform (pro replikaci infra) a Delta Deep Clone (pro replikaci dat).
Podrobný postup migrace
Instalace rozhraní příkazového řádku Databricks
Příklady v tomto článku používají rozhraní příkazového řádku (CLI) Databricks, což je snadno použitelný obálka přes rozhraní REST API Azure Databricks.
Před provedením jakýchkoli kroků migrace nainstalujte rozhraní příkazového řádku Databricks na místní počítač nebo virtuální počítač. Další informace najdete v tématu Instalace rozhraní příkazového řádku Databricks.
Poznámka:
Skripty Pythonu uvedené v tomto článku fungují s Pythonem 2.7 a novějším.
Nakonfigurujte dva profily.
Postupujte podle kroků v části _, nakonfigurujte dva profily: jeden pro primární pracovní prostor a druhý pro sekundární pracovní prostor.
databricks configure --profile primary databricks configure --profile secondaryBloky kódu v tomto článku přepíná mezi profily v každém dalším kroku pomocí odpovídajícího příkazu pracovního prostoru. Ujistěte se, že názvy profilů, které vytvoříte, se nahradí do každého bloku kódu.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"V případě potřeby můžete ručně přepnout na příkazový řádek:
databricks workspace list --profile primary databricks workspace list --profile secondaryMigrace microsoft entra ID (dříve Azure Active Directory)
Do sekundárního pracovního prostoru, který existuje v primárním pracovním prostoru, přidejte ručně stejné uživatele Microsoft Entra ID (dříve Azure Active Directory).
Migrace uživatelských složek a poznámkových bloků
Pomocí následujícího kódu Pythonu můžete migrovat uživatelská prostředí v izolovaném prostoru (sandbox), která zahrnují strukturu vnořených složek a poznámkové bloky na uživatele.
Poznámka:
Knihovny se v tomto kroku nekopírují, protože základní rozhraní API je nepodporuje.
Zkopírujte a uložte následující skript Pythonu do souboru a spusťte ho na příkazovém řádku. Například
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Migrace konfigurací clusteru
Po migraci poznámkových bloků můžete volitelně migrovat konfigurace clusteru do nového pracovního prostoru. Jedná se téměř o plně automatizovaný krok pomocí rozhraní příkazového řádku Databricks, pokud nechcete provést selektivní migraci konfigurace clusteru.
Poznámka:
Neexistuje žádný koncový bod konfigurace clusteru a tento skript se pokusí vytvořit každý cluster hned. Pokud ve vašem předplatném není k dispozici dostatek jader, může vytvoření clusteru selhat. Selhání je možné ignorovat, pokud se konfigurace úspěšně přenese.
Následující skript vypíše mapování ze starého na nové ID clusteru, které je možné později použít k migraci úloh (pro úlohy, které jsou nakonfigurované tak, aby používaly existující clustery).
Zkopírujte a uložte následující skript Pythonu do souboru a spusťte ho na příkazovém řádku. Například
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines() print("Printing Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append(cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Migrace konfigurace úloh
Pokud jste migrovali konfigurace clusteru v předchozím kroku, můžete se rozhodnout migrovat konfigurace úloh do nového pracovního prostoru. Jedná se o plně automatizovaný krok pomocí rozhraní příkazového řádku Databricks, pokud nechcete provádět selektivní migraci konfigurace úloh, a ne pro všechny úlohy.
Poznámka:
Konfigurace naplánované úlohy obsahuje také informace o plánu, takže ve výchozím nastavení začnou fungovat podle nakonfigurovaného načasování, jakmile se migruje. Následující blok kódu proto během migrace odebere všechny informace o plánu (aby nedocházelo k duplicitním spuštěním ve starých a nových pracovních prostorech). Jakmile budete připraveni na přímou migraci, nakonfigurujte plány těchto úloh.
Konfigurace úlohy vyžaduje nastavení pro nový nebo existující cluster. Pokud používáte existující cluster, skript /code níže se pokusí nahradit původní ID clusteru novým ID clusteru.
Zkopírujte a uložte následující skript Pythonu do souboru. Nahraďte hodnotu a
old_cluster_idnew_cluster_idnahraďte výstupem migrace clusteru provedenou v předchozím kroku. Spusťte ho napříkladpython scriptname.pyna příkazovém řádku .import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate " + str(job)) job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id'])) continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Migrace knihoven
V současné době neexistuje žádný jednoduchý způsob, jak migrovat knihovny z jednoho pracovního prostoru do druhého. Místo toho tyto knihovny přeinstalujte do nového pracovního prostoru ručně. Můžete to automatizovat pomocí rozhraní příkazového řádku Databricks k nahrání vlastních knihoven do pracovního prostoru.
Migrace úložiště objektů blob v Azure a připojení služby Azure Data Lake Storage
Ručně připojte všechny přípojné body Azure Blob Storage a Azure Data Lake Storage (Gen 2) pomocí řešení založeného na poznámkovém bloku. Prostředky úložiště by byly připojeny v primárním pracovním prostoru a musí se opakovat v sekundárním pracovním prostoru. Pro připojení neexistuje žádné externí rozhraní API.
Migrace inicializačních skriptů clusteru
Pomocí rozhraní příkazového řádku Databricks je možné migrovat všechny skripty inicializace clusteru ze starého do nového pracovního prostoru. Nejprve zkopírujte potřebné skripty do místního počítače nebo virtuálního počítače. Potom tyto skripty zkopírujte do nového pracovního prostoru ve stejné cestě.
Poznámka:
Pokud máte inicializační skripty uložené v DBFS, nejprve je migrujte do podporovaného umístění. Viz _.
// Primary to local databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary // Local to Secondary workspace databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondaryRuční změna konfigurace a opětovného použití řízení přístupu
Pokud je váš stávající primární pracovní prostor nakonfigurovaný tak, aby používal úroveň Premium nebo Enterprise (SKU), pravděpodobně používáte také řízení přístupu.
Pokud používáte řízení přístupu, ručně znovu použijte řízení přístupu k prostředkům (poznámkové bloky, clustery, úlohy, tabulky).
Zotavení po havárii pro ekosystém Azure
Pokud používáte jiné služby Azure, nezapomeňte implementovat osvědčené postupy zotavení po havárii pro tyto služby. Pokud se například rozhodnete použít externí instanci metastoru Hive, měli byste zvážit zotavení po havárii pro Azure SQL Database, Azure HDInsight a/nebo Azure Database for MySQL. Obecné informace o zotavení po havárii najdete v tématu Zotavení po havárii pro aplikace Azure.
Další kroky
Další informace najdete v dokumentaci k Azure Databricks.