Mezery mezi úlohami Sparku
V časové ose úloh se zobrazují mezery, jako jsou tyto:
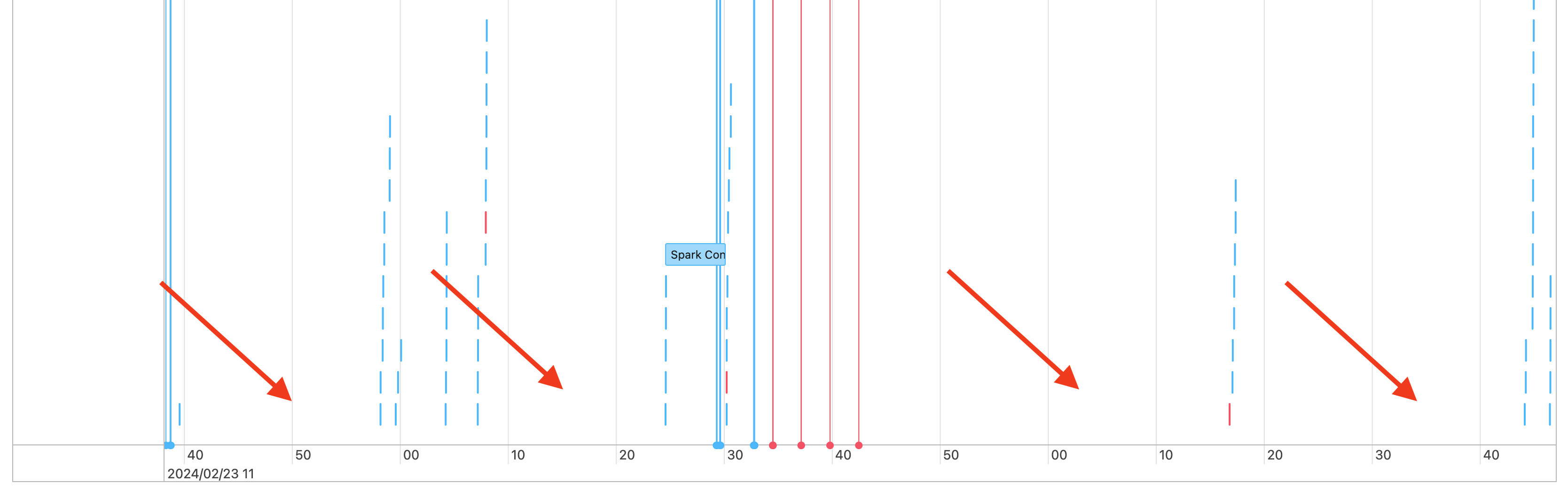
Může k tomu dojít z několika důvodů. Pokud mezery tvoří vysoký podíl času stráveného na vaší úloze, musíte zjistit, co způsobuje tyto mezery a jestli se očekává nebo ne. Během mezer může docházet k několika věcem:
- Není k dispozici žádná práce.
- Ovladač kompiluje komplexní plán provádění.
- Spuštění kódu bez sparku
- Ovladač je přetížen
- Cluster nefunguje správně
Žádná práce
Na všestranné výpočetní jednotceje nejpravděpodobnějším vysvětlením mezer to, že není žádná práce k vykonání. Vzhledem k tomu, že cluster běží a uživatelé odesílají dotazy, přerušení se očekávají. Tato přerušení představují čas mezi odesláními dotazů.
Komplexní plán provádění
Pokud například používáte withColumn() smyčku, vytvoří velmi nákladný plán zpracování. Mezery můžou být v době, kdy ovladač stráví jednoduše sestavováním a zpracováním plánu. V takovém případě zkuste kód zjednodušit. Pomocí selectExpr() zkombinujte více volání withColumn() do jednoho výrazu nebo kódu převeďte na SQL. SQL můžete i tak vložit do kódu Pythonu a použít Python k manipulaci s dotazem pomocí řetězcových funkcí. Tím se tento typ problému často vyřeší.
Spuštění kódu jiného než Sparku
Kód Sparku je napsaný v SQL nebo pomocí rozhraní SPARK API, jako je PySpark. Jakékoli spuštění kódu, který není Sparkem, se na časové ose zobrazí jako mezery. Můžete mít například smyčku v Pythonu, která volá nativní funkce Pythonu. Tento kód se ve Sparku nespouštějí a může se zobrazit jako mezera na časové ose. Pokud si nejste jistí, jestli váš kód používá Spark, zkuste ho spustit interaktivně v poznámkovém bloku. Pokud kód používá Spark, pod buňkou se zobrazí úlohy Sparku:

Můžete také rozbalit rozevírací seznam Úloh Sparku pod buňkou a zjistit, jestli se úlohy aktivně spouštějí (v případě, že je Spark teď nečinný). Pokud Spark nepoužíváte, nezobrazí se pod buňkou úlohy Sparku nebo uvidíte, že žádné nejsou aktivní. Pokud kód nemůžete spustit interaktivně, můžete zkusit se přihlásit do kódu a zjistit, jestli můžete spárovat mezery s oddíly kódu podle časového razítka, ale to může být složité.
Pokud na časové ose uvidíte mezery způsobené spuštěním jiného kódu než Spark, znamená to, že všechny pracovní procesy jsou nečinné a během mezer se pravděpodobně zbytečně utrácejí peníze. Možná je to úmyslné a nedá se tomu vyhnout, ale pokud můžete napsat tento kód na použití Sparku, plně využijete cluster. V tomto kurzu se dozvíte, jak pracovat se Sparkem.
Ovladač je přetížen
Chcete-li zjistit, jestli je ovladač přetížený, musíte se podívat na metriky clusteru.
Pokud je váš cluster ve verzi DBR 13.0 nebo novější, klikněte na Metriky , jak je zvýrazněno na tomto snímku obrazovky:
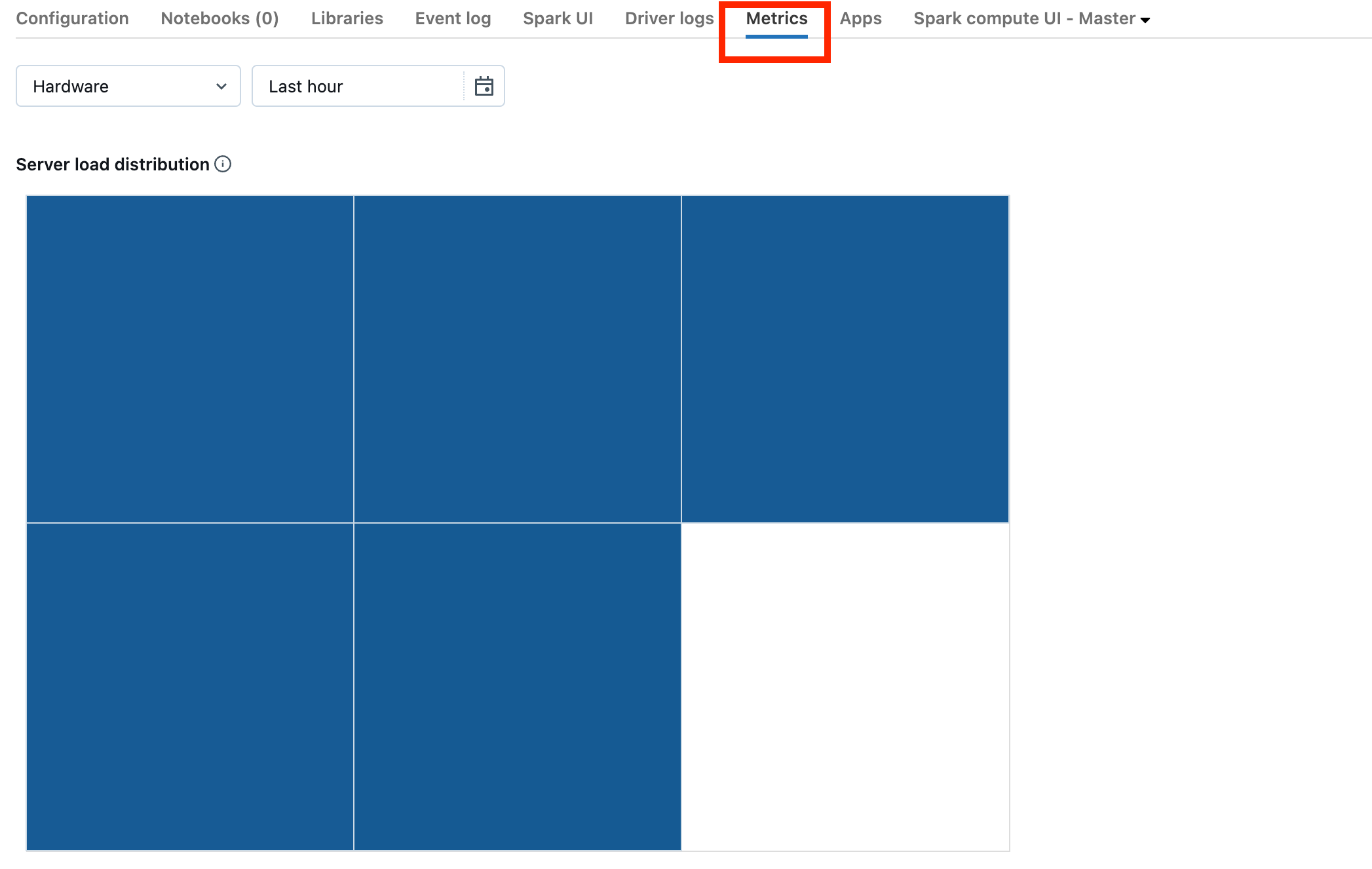
Všimněte si vizualizace distribuce zatížení serveru. Měli byste se podívat, jestli je ovladač silně zatížený. Tato vizualizace má blok barev pro každý počítač v clusteru. Červená znamená silně zatížené a modré znamená, že se vůbec nenačítají.
Předchozí snímek obrazovky ukazuje v podstatě nečinný cluster. Pokud je ovladač přetížen, vypadal by nějak takto:
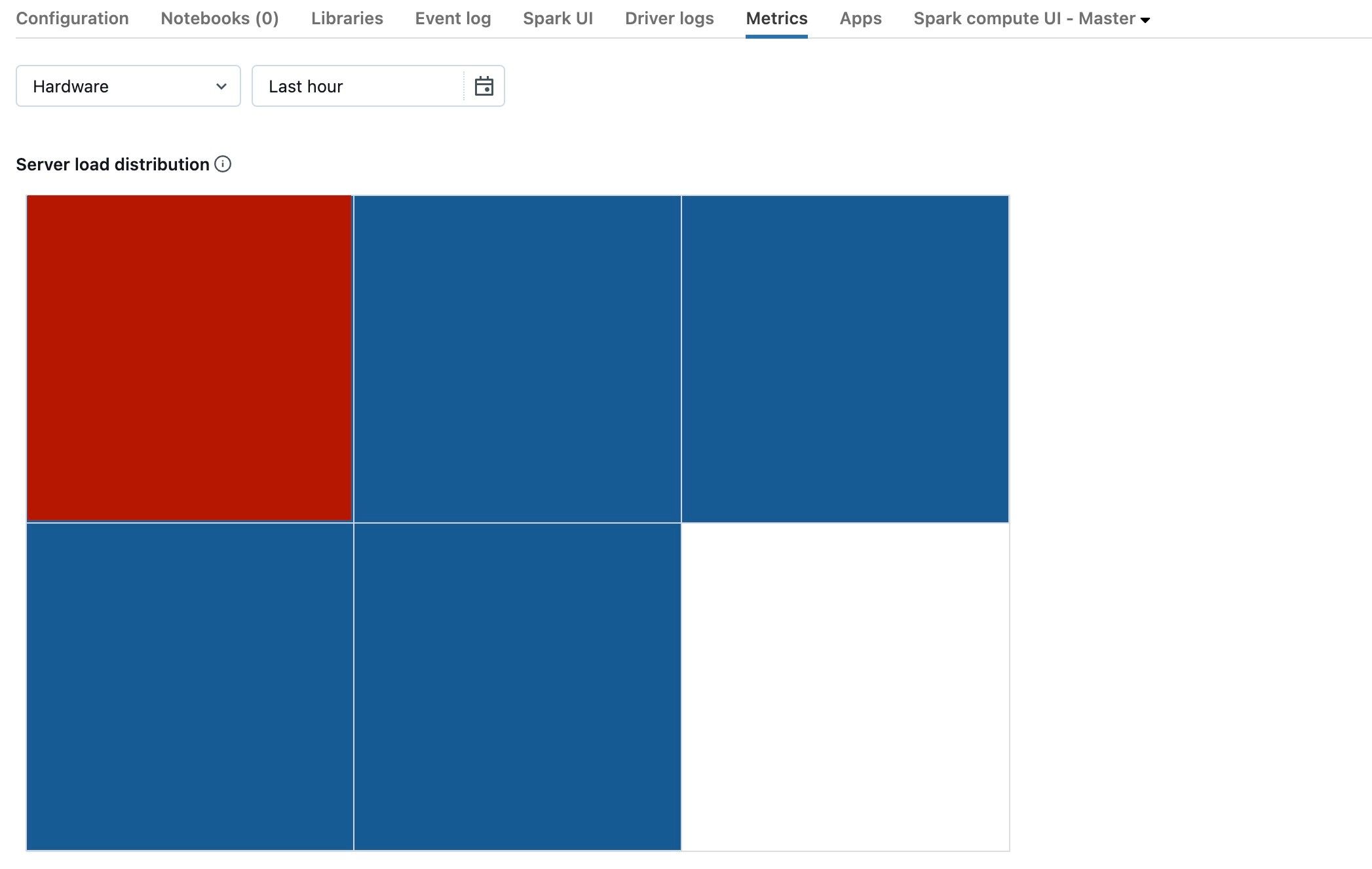
Vidíme, že jeden čtverec je červený, zatímco ostatní jsou modré. Přejíždět myší na červený čtverec, abyste měli jistotu, že červený blok představuje váš ovladač.
Pokud chcete opravit přetížený ovladač, přečtěte si téma Přetížení ovladače Spark.
Cluster nefunguje správně
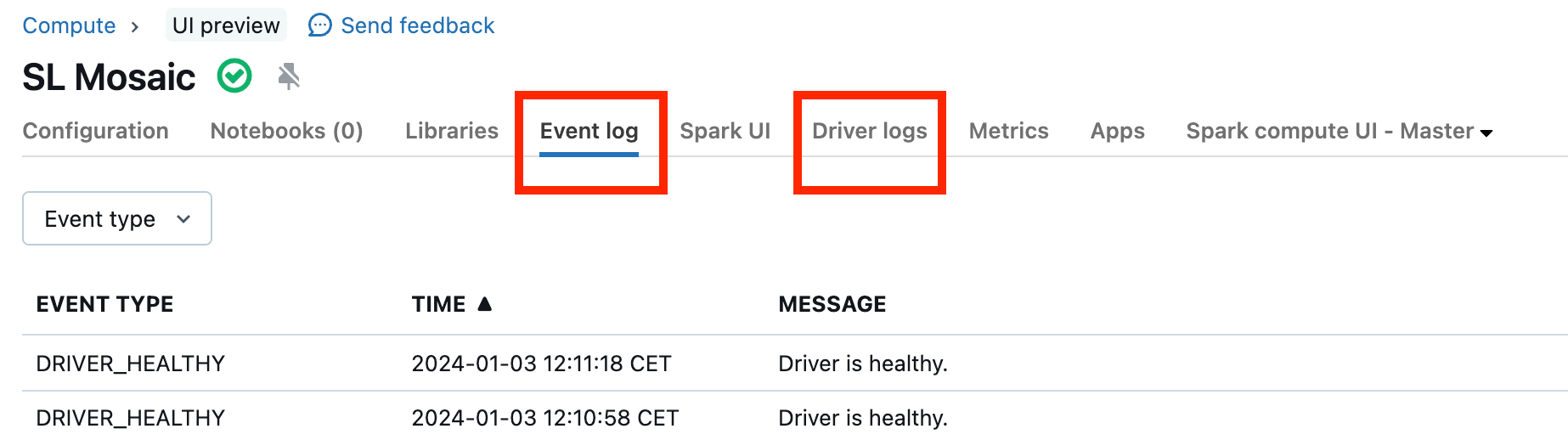
Poruchy clusterů jsou vzácné, ale pokud k nim dojde, může být obtížné určit, co se stalo. Možná bude vhodné cluster restartovat, abyste zjistili, jestli se tím problém vyřeší. Můžete se také podívat na protokoly a zjistit, jestli je v nich něco podezřelého. Na kartě Protokol událostí a na kartě Protokoly ovladačů, které jsou zvýrazněné na následujícím snímku obrazovky, budou místa, kam se chcete podívat:
Pro přístup k protokolům pracovních procesů může být vhodné povolit doručování protokolů clusteru. Můžete také změnit úroveň protokolu, ale možná budete muset požádat o pomoc tým účtu Databricks.