Trénování modelů doporučovačů
Tento článek obsahuje dva příklady modelů doporučení založených na hlubokém učení v Azure Databricks. V porovnání s tradičními modely doporučení můžou modely hlubokého učení dosáhnout vyšších výsledků kvality a škálovat na větší objemy dat. Vzhledem k tomu, že se tyto modely stále vyvíjejí, databricks poskytuje architekturu pro efektivní trénování rozsáhlých modelů doporučení, které umožňují zpracovávat stovky milionů uživatelů.
Obecný systém doporučení lze zobrazit jako trychtýř s fázemi zobrazenými v diagramu.
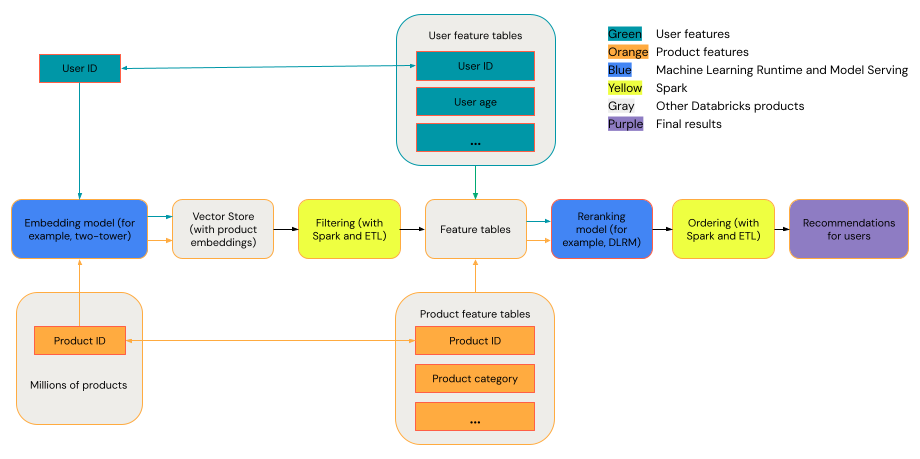
Některé modely, jako je dvouvěžový model, fungují lépe jako modely načítání. Tyto modely jsou menší a můžou efektivně pracovat s miliony datových bodů. Jiné modely, jako je DLRM nebo DeepFM, fungují lépe jako modely opětovného řazení. Tyto modely můžou využívat více dat, jsou větší a můžou poskytovat jemně odstupňovaná doporučení.
Požadavky
Databricks Runtime 14.3 LTS ML
Nástroje
Příklady v tomto článku ilustrují následující nástroje:
- TorchDistributor: TorchDistributor je architektura, která umožňuje spouštět rozsáhlé trénování modelů PyTorch v Databricks. Používá Spark k orchestraci a může škálovat na tolik GPU, kolik je v clusteru k dispozici.
- Mosaic StreamingDataset: StreamingDataset zlepšuje výkon a škálovatelnost trénování velkých datových sad v Databricks pomocí funkcí, jako je předběžné načítání a prokládání.
- MLflow: Mlflow umožňuje sledovat parameters, metriky a kontrolní body modelu.
- torchRec: Moderní doporučovací systémy používají vkládání vyhledávacích tables ke zpracování milionů uživatelů a položek, aby generate vysoce kvalitní doporučení. Větší velikosti vkládání zlepšují výkon modelu, ale vyžadují dodatečné nastavení paměti GPU a více GPU. TorchRec poskytuje architekturu pro škálování modelů doporučení a vyhledávání tables napříč několika grafickými procesory, což je ideální pro velké vkládání.
Příklad: Doporučení pro film s využitím architektury modelu se dvěma věžmi
Model se dvěma věžmi je navržený tak, aby zpracovával úlohy přizpůsobení ve velkém měřítku tím, že před jejich kombinováním zpracovává data uživatelů a položek samostatně. Dokáže efektivně generovat stovky nebo tisíce slušných doporučení pro kvalitu. Model obecně očekává tři vstupy: funkci user_id, funkci product_id a binární popisek definující, jestli <uživatel, interakce s produktem> byla kladná (uživatel produkt zakoupil) nebo negativní (uživatel dal produktu jedno hodnocení hvězdičkou). Výstupy modelu se vkládají pro uživatele i položky, které se obvykle kombinují (často používají tečkovaný produkt nebo kosinus) k predikci interakcí s položkami uživatele.
Vzhledem k tomu, že model se dvěma věžmi poskytuje vkládání pro uživatele i produkty, můžete je umístit do vektorové databáze, jako je Databricks Vector Store, a provádět operace podobné vyhledávání uživatelů a položek. Můžete například umístit všechny položky do vektorového úložiště a pro každého uživatele zadávat dotaz na úložiště vektorů, aby našel prvních sto položek, jejichž vkládání je podobné uživateli.
Následující ukázkový poznámkový blok implementuje trénování modelu se dvěma věžmi pomocí datové sady "Learning from Sets of Items" k predikci pravděpodobnosti, že uživatel bude ohodnotit určitý film vysoce. K načítání distribuovaných dat, torchDistributorutoru pro trénování distribuovaného modelu a mlflow pro sledování a protokolování modelů používá platformu Mosaic StreamingDataset.
Poznámkový blok modelu s doporučením pro dvou věží
Tento poznámkový blok je k dispozici také na Webu Databricks Marketplace: dvouvěžový modelový poznámkový blok
Poznámka:
- Vstupy modelu se dvěma věžmi jsou nejčastěji kategorické funkce user_id a product_id. Model lze upravit tak, aby podporoval více vektorů funkcí pro uživatele i produkty.
- Výstupy modelu se dvěma věžmi jsou obvykle binární values označující, jestli uživatel bude mít kladnou nebo negativní interakci s produktem. Model lze upravit pro jiné aplikace, jako je regrese, klasifikace s více třídami a pravděpodobnosti pro více uživatelských akcí (například zavření nebo nákup). Složité výstupy by se měly implementovat pečlivě, protože konkurenční cíle mohou snížit kvalitu vkládání generovaných modelem.
Příklad: Trénujte architekturu DLRM pomocí syntetické datové sady.
DLRM je nejmodernější architektura neurální sítě navržená speciálně pro personalizaci a systémy doporučení. Kombinuje kategorické a číselné vstupy, které efektivně modelují interakce uživatelských položek a predikují uživatelské předvolby. Moduly DLRM obvykle očekávají vstupy, které zahrnují jak řídké funkce (například ID uživatele, ID položky, zeměpisné umístění nebo kategorii produktu), tak i zhuštěné funkce (například věk uživatele nebo cena položky). Výstupem DLRM je obvykle predikce zapojení uživatelů, například míra prokliku nebo pravděpodobnost nákupu.
DlRM nabízejí vysoce přizpůsobitelnou architekturu, která dokáže zpracovávat rozsáhlá data, takže je vhodná pro složité úlohy doporučení napříč různými doménami. Vzhledem k tomu, že se jedná o větší model než dvouvěžová architektura, tento model se často používá ve fázi opětovného řazení.
Následující ukázkový poznámkový blok vytvoří model DLRM, který předpovídá binární popisky pomocí hustých (číselných) funkcí a řídkých (kategorických) funkcí. Používá k trénování modelu syntetickou datovou sadu, sadu Mosaic StreamingDataset pro distribuované načítání dat, TorchDistributor pro trénování distribuovaného modelu a mlflow pro sledování a protokolování modelu.
Poznámkový blok DLRM
Tento poznámkový blok je také k dispozici na Webu Databricks Marketplace: poznámkový blok DLRM.
Porovnání dvou věží a modelů DLRM
V table jsou uvedeny některé pokyny pro výběr modelu doporučeného k použití.
| Typ modelu | Velikost datové sady potřebná pro trénování | Velikost modelu | Podporované vstupní typy | Podporované typy výstupu | Případy použití |
|---|---|---|---|---|---|
| Dvouvěžová věž | Menší | Menší | Obvykle dva funkce (user_id, product_id) | Generování hlavně binární klasifikace a vkládání | Generování stovek nebo tisíců možných doporučení |
| DLRM | Větší | Větší | Různé kategorické a zhuštěné rysy (user_id, pohlaví, geographic_location, product_id, product_category, ...) | Klasifikace více tříd, regrese, další | Jemně odstupňované načítání (doporučení desítek vysoce relevantních položek) |
Stručně řečeno, dvouvěžový model je nejvhodnější pro generování tisíců kvalitních doporučení velmi efektivně. Příkladem může být doporučení filmů od poskytovatele kabelu. Model DLRM je nejvhodnější pro generování velmi specifických doporučení na základě více dat. Příkladem může být prodejce, který chce zákazníkovi předložit menší počet položek, které si s vysokou pravděpodobností koupí.