Prognózování (bezserverové) pomocí AutoML
Důležitý
Tato funkce je ve verzi Public Preview.
V tomto článku se dozvíte, jak spustit bezserverový experiment prognózování pomocí uživatelského rozhraní pro trénování modelu Mosaic AI.
Mosaic AI Model Training - prognózování zjednodušuje práci s daty časových řad tím, že automaticky vybírá nejlepší algoritmus a hyperparametry, a to vše při běhu na plně spravovaných výpočetních prostředcích.
Pokud chcete porozumět rozdílu mezi bezserverovými prognózami a klasickými prognózami výpočetních prostředků, přečtěte si téma Bezserverové prognózování a klasické prognózování výpočetních prostředků.
Požadavky
Tréninková data se sloupcem časových řad, uložená jako tabulka katalogu Unity.
Pokud má pracovní prostor povolenou bránu SEG (Secure Egress Gateway),
pypi.orgmusí být přidána do seznamu Povolené domény. Viz Správa zásad sítě pro řízení výchozího přenosu dat bez serveru.
Vytvoření experimentu prognózování s uživatelským rozhraním
Přejděte na cílovou stránku Azure Databricks a na bočním panelu klikněte na Experimenty.
Na dlaždici prognózy
vyberte Zahájit trénování .Ze seznamu tabulek katalogu Unity, ke kterým máte přístup, vyberte tréninková data .
-
Sloupec času: Vyberte sloupec obsahující časová období pro časovou řadu. Sloupce musí být typu
timestampnebodate. - frekvence prognózy: Vyberte časovou jednotku, která představuje frekvenci vstupních dat. Například minuty, hodiny, dny, měsíce. Tím se určuje členitost časové řady.
- horizont prognózy: Určete, kolik jednotek vybrané frekvence se má prognózovat do budoucna. Společně s frekvencí prognózy se definují jak časové jednotky, tak i počet časových jednotek, které se mají prognózovat.
Poznámka
Aby bylo možné použít algoritmus Auto-ARIMA, musí mít časová řada běžnou frekvenci, ve které musí být interval mezi dvěma body stejný v průběhu časové řady. AutoML zpracovává chybějící kroky času vyplněním těchto hodnot předchozí hodnotou.
-
Sloupec času: Vyberte sloupec obsahující časová období pro časovou řadu. Sloupce musí být typu
Vyberte cílový sloupec predikce, který má model předpovědět.
Volitelně můžete zadat tabulku v katalogu Unity jako cestu k datům předpovědi, kde budou uloženy výstupní prognózy.
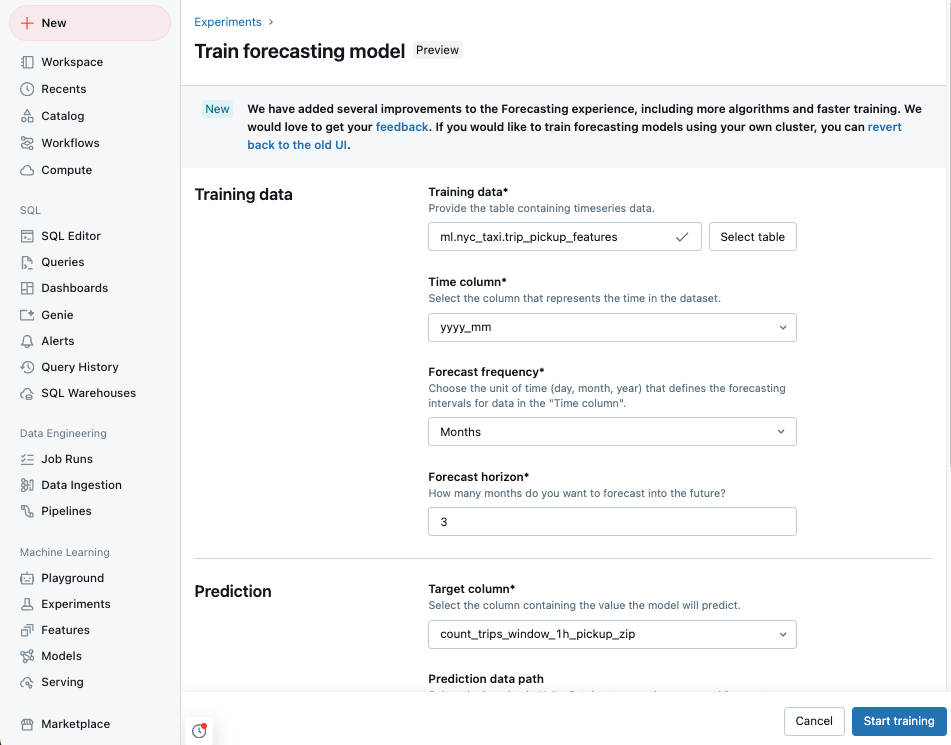
Vyberte registraci modelu umístění a názvu katalogu Unity.
Volitelně můžete nastavit rozšířené možnosti:
- název experimentu: Zadejte název experimentu MLflow.
- sloupce identifikátoru časové řady – pro prognózování s více řadami vyberte sloupce, které identifikují jednotlivé časové řady. Databricks seskupuje data podle těchto sloupců jako různé časové řady a trénuje model pro každou řadu nezávisle.
- primární metrika: Vyberte primární metriku použitou k vyhodnocení a výběru nejlepšího modelu.
- trénovací rozhraní: Vyberte architektury pro AutoML, které chcete prozkoumat.
- Rozdělení sloupce: Vyberte sloupec obsahující vlastní rozdělení dat. Hodnoty musí být „train“, „validate“, „test“
- Sloupec hmotnosti: Zadejte sloupec, který se má použít pro váhu časových řad. Všechny vzorky pro danou časovou řadu musí mít stejnou váhu. Hmotnost musí být v rozsahu [0, 10000].
- prázdninové oblasti: Vyberte oblast svátků, která se má použít jako kovariance při trénování modelu.
- Časový limit: Nastavte maximální dobu trvání experimentu AutoML.
Spuštění experimentu a monitorování výsledků
Chcete-li spustit experiment AutoML, klepněte na tlačítko Zahájit trénování. Na stránce pro trénování experimentu můžete udělat toto:
- Experiment můžete kdykoli zastavit.
- Spuštění monitoru
- Přejděte na stránku běhu pro libovolné spuštění.
Zobrazení výsledků nebo použití nejlepšího modelu
Po dokončení trénování se výsledky předpovědi uloží do zadané tabulky Delta a nejlepší model se zaregistruje do katalogu Unity.
Na stránce experimentů si můžete vybrat z následujících kroků:
- Výběrem možnosti Zobrazit předpovědi zobrazte tabulku výsledků prognózování.
- Výběrem poznámkového bloku pro dávkovou inferenci otevřete automaticky vygenerovaný poznámkový blok pro dávkové inferenční použití nejlepšího modelu.
- Vyberte Vytvořit obslužný koncový bod a nasaďte nejlepší model do koncového bodu obsluhy modelu.
bezserverové prognózování versus klasické prognózování výpočetních prostředků
Následující tabulka shrnuje rozdíly mezi bezserverovým prognózováním a prognózováním s klasickými výpočetními zdroji.
| Funkce | Prognózování bez serveru | Klasické prognózování výpočetní techniky |
|---|---|---|
| Výpočetní infrastruktura | Azure Databricks spravuje konfiguraci výpočetních prostředků a automaticky optimalizuje náklady a výkon. | Výpočetní prostředky nakonfigurované uživatelem |
| Vládnutí | Modely a artefakty zaregistrované v katalogu Unity | Úložiště souborů pracovního prostoru nakonfigurované uživatelem |
| Výběr algoritmu | statistické modely plus algoritmus neurální sítě hlubokého učení DeepAR | statistické modely |
| Integrace úložiště funkcí | Nepodporováno | podporované |
| Automaticky generované poznámkové bloky | Poznámkový blok pro odvození služby Batch | Zdrojový kód pro všechny zkušební verze |
| Jednoklikový model obsluhující nasazení | Podporovaný | Nepodporovaný |
| Vlastní rozdělení trénování, ověřování a testování | Podporovaný | Nepodporováno |
| Vlastní váhy pro jednotlivé časové řady | Podporovaný | Nepodporováno |