Prognózování pomocí AutoML (klasické výpočetní prostředí)
Pomocí AutoML můžete automaticky najít nejlepší algoritmus prognózování a konfiguraci hyperparametrů k predikci hodnot na základě dat časových řad.
Prognózování časových řad je k dispozici pouze pro Databricks Runtime 10.0 ML nebo novější.
Nastavení experimentu prognózování s uživatelským rozhraním
Pomocí uživatelského rozhraní AutoML můžete nastavit problém s prognózováním pomocí následujícího postupu:
- Na bočním panelu vyberte Experimenty.
- Na kartě Prognózování vyberte Zahájit trénování.
Uživatelské rozhraní je ve výchozím nastavení prognózování bez použití serveru. Pokud chcete získat přístup k prognózování pomocí vlastních výpočetních prostředků, vyberte možnost vrátit se ke staré verzi.
konfigurace experimentu AutoML
Zobrazí se stránka konfigurace experimentu AutoML. Na této stránce nakonfigurujete proces AutoML, zadáte datovou sadu, typ úlohy, cílový nebo popisný sloupec, který chcete předpovědět, metriku pro hodnocení, které se použijí ke zhodnocení a skórování spuštění experimentu, a podmínky zastavení.
V poli Compute vyberte cluster se spuštěným Databricks Runtime 10.0 ML nebo novějším.
V části Datová sada klikněte na Procházet. Přejděte do tabulky, kterou chcete použít, a klikněte na Vybrat. Zobrazí se schéma tabulky.
Klikněte do pole Cíl předpovědi. Zobrazí se rozevírací nabídka se seznamem sloupců zobrazených ve schématu. Vyberte sloupec, který má model předpovědět.
Klikněte na pole Čas. Zobrazí se rozevírací seznam se sloupci datové sady, které jsou typu
timestampnebodate. Vyberte sloupec obsahující časová období časové řady.Při prognózování více řad vyberte sloupce, které identifikují jednotlivé časové řady z identifikátorů časových řad rozevíracího seznamu. AutoML seskupí data podle těchto sloupců jako různé časové řady a vytrénuje model pro každou řadu nezávisle. Pokud toto pole necháte prázdné, AutoML předpokládá, že datová sada obsahuje jednu časovou řadu.
V polích Horizont prognózy a frekvence zadejte počet časových období do budoucnosti, pro které má AutoML vypočítat předpokládané hodnoty. Do levého pole zadejte celočíselné číslo období, která se mají prognózovat. V pravém poli vyberte jednotky.
Poznámka:
Aby bylo možné použít funkci Auto-ARIMA, musí mít časová řada běžnou frekvenci, ve které musí být interval mezi dvěma body stejný v průběhu časové řady. Frekvence se musí shodovat s jednotkou frekvence zadanou ve volání rozhraní API nebo v uživatelském rozhraní AutoML. AutoML zpracovává chybějící kroky času vyplněním těchto hodnot předchozí hodnotou.
Ve službě Databricks Runtime 11.3 LTS ML a novějších můžete uložit výsledky předpovědi. Uděláte to tak, že do pole Výstupní databáze zadáte databázi. Klikněte na Procházet a v dialogovém okně vyberte databázi. AutoML zapíše výsledky předpovědi do tabulky v této databázi.
Pole Název experimentu zobrazuje výchozí název. Pokud ho chcete změnit, zadejte nový název do pole.
Můžete také:
- Zadejte další možnosti konfigurace.
- Pomocí existujících tabulek funkcí v úložišti funkcí můžete rozšířit původní vstupní datovou sadu.
Pokročilé konfigurace
Otevřete oddíl Advanced Configuration (volitelné) pro přístup k těmto parametrům.
- Metrika vyhodnocení je primární metrika použitá k určení skóre spuštění.
- Ve službě Databricks Runtime 10.4 LTS ML a novějších můžete vyloučit z úvahy trénovací architektury. AutoML ve výchozím nastavení trénuje modely pomocí architektur uvedených v algoritmech AutoML.
- Podmínky zastavení můžete upravit. Výchozí podmínky zastavení jsou:
- U předpovědí experimentů zastavte po 120 minutách.
- V Databricks Runtime 10.4 LTS ML a níže pro klasifikační a regresní experimenty zastavte po 60 minutách nebo po dokončení 200 pokusů, podle toho, co nastane dříve. Pro Databricks Runtime 11.0 ML a vyšší se počet pokusů nepoužívá jako stav zastavení.
- V Databricks Runtime 10.4 LTS ML a novějších, pro klasifikační a regresní experimenty autoML zahrnuje předčasné zastavení; zastaví trénování a ladění modelů, pokud se metrika ověřování už nelepší.
- V Databricks Runtime 10.4 LTS ML a vyšších verzích můžete vybrat
time columnk rozdělení dat pro trénink, ověřování a testování v chronologickém pořadí (platí jen u klasifikaci a regresi). - Databricks doporučuje nenaplnění pole Adresář dat. Tím se aktivuje výchozí chování zabezpečeného ukládání datové sady jako artefaktu MLflow. Je možné zadat cestu DBFS, ale v tomto případě datová sada nedědí přístupová oprávnění experimentu AutoML.
Spuštění experimentu a monitorování výsledků
Chcete-li spustit experiment AutoML, klepněte na tlačítko Spustit AutoML. Experiment se spustí a zobrazí se stránka pro trénování AutoML. Pokud chcete aktualizovat tabulku spuštění, klikněte na tlačítko  .
.
Zobrazení průběhu experimentu
Z této stránky můžete:
- Experiment můžete kdykoli zastavit.
- Otevřete poznámkový blok pro zkoumání dat.
- Monitorování spuštění.
- Přejděte na stránku spuštění pro jakékoli spuštění.
S modulem Databricks Runtime 10.1 ML a novějším zobrazí AutoML upozornění na potenciální problémy s datovou sadou, jako jsou nepodporované typy sloupců nebo sloupce s vysokou kardinalitou.
Poznámka:
Databricks nejlépe indikuje potenciální chyby nebo problémy. To ale nemusí být komplexní a nemusí zaznamenávat problémy nebo chyby, které hledáte.
Pokud chcete zobrazit všechna upozornění pro datovou sadu, klikněte na kartu Upozornění na stránce školení nebo na stránce experimentu po dokončení experimentu.
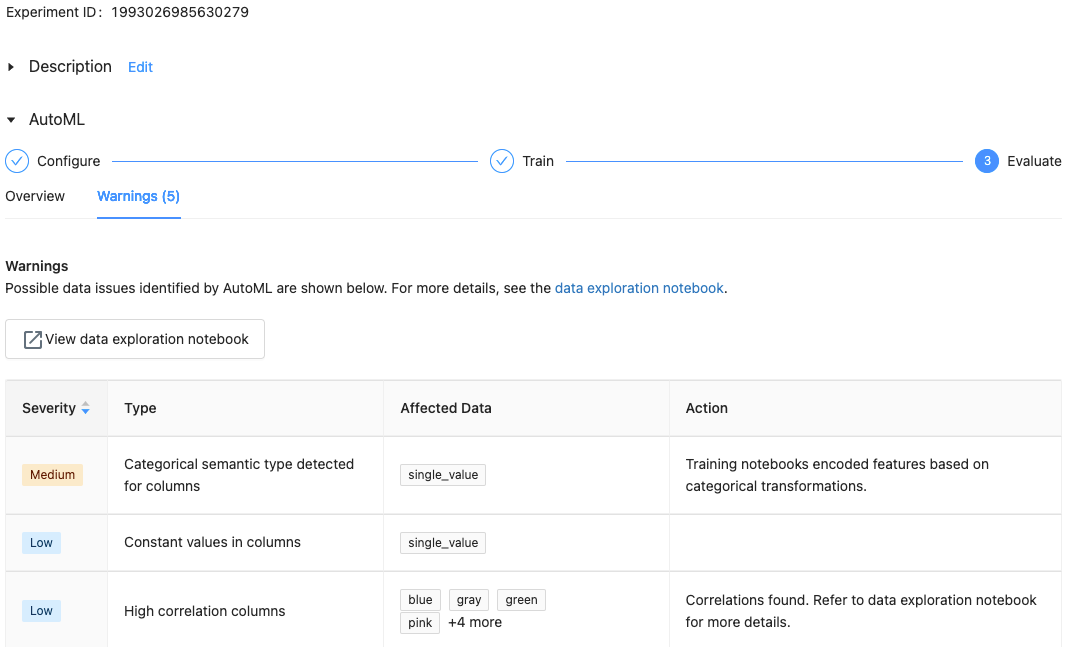
Zobrazení výsledků
Po dokončení experimentu můžete:
- Zaregistrujte a nasaďte jeden z modelů pomocí MLflow.
- Vyberte Zobrazit poznámkový blok pro nejlepší model a zkontrolujte a upravte poznámkový blok, který vytvořil nejlepší model.
- Výběrem Zobrazit poznámkový blok pro zkoumání dat otevřete poznámkový blok pro zkoumání dat.
- Vyhledávání, filtrování a řazení běhů v tabulce běhů.
- Podrobnosti o každém spuštění:
- Vygenerovaný poznámkový blok obsahující zdrojový kód pro zkušební spuštění najdete kliknutím na spuštění MLflow. Poznámkový blok se uloží v části Artefakty na stránce spuštění. Tento poznámkový blok si můžete stáhnout a importovat do pracovního prostoru, pokud správce pracovního prostoru povolí stahování artefaktů.
- Pokud chcete zobrazit výsledky spuštění, klikněte ve sloupci Modely nebo ve sloupci Čas zahájení. Zobrazí se stránka spuštění s informacemi o zkušebním spuštění (například parametry, metriky a značky) a artefaktech vytvořených spuštěním, včetně modelu. Tato stránka obsahuje také fragmenty kódu, které můžete použít k předpovědím s modelem.
Pokud se chcete vrátit k tomuto experimentu AutoML později, najděte ho v tabulce na stránce Experimenty. Výsledky každého experimentu AutoML, včetně zkoumání dat a trénovacích poznámkových bloků, jsou uložené ve databricks_automl složce v domovské složce uživatele, který experiment spustil.
Registrace a nasazení modelu
Model můžete zaregistrovat a nasadit pomocí uživatelského rozhraní AutoML:
- Vyberte odkaz ve sloupci Modely, aby se model zaregistroval. Po dokončení spuštění je nejlepším modelem horního řádku (na základě primární metriky).
- Výběrem tlačítka
 zaregistrujte model v registru modelů.
zaregistrujte model v registru modelů. - Výběrem ikony
 Modely na bočním panelu přejděte do registru modelů.
Modely na bočním panelu přejděte do registru modelů. - V tabulce modelu vyberte název modelu.
- Na stránce zaregistrovaného modelu můžete model obsluhovat pomocí obsluhy modelů.
Žádný modul s názvem pandas.core.indexes.numeric
Při poskytování modelu vytvořeného pomocí AutoML s obsluhou modelů se může zobrazit chyba: No module named 'pandas.core.indexes.numeric.
Důvodem je nekompatibilní pandas verze mezi AutoML a modelem obsluhující prostředí koncového bodu. Tuto chybu můžete vyřešit spuštěním skriptu add-pandas-dependency.py. Skript upraví requirements.txt protokolovaný model tak conda.yaml , aby zahrnoval příslušnou pandas verzi závislostí: pandas==1.5.3
- Upravte skript tak, aby obsahoval
run_idběhu MLflow, ve kterém byl váš model zaznamenán. - Opětovná registrace modelu do registru modelů MLflow
- Zkuste obsluhovat novou verzi modelu MLflow.