Výpočetní funkce na vyžádání s využitím uživatelem definovaných funkcí Pythonu
Tento článek popisuje, jak vytvářet a používat funkce na vyžádání v Azure Databricks.
Pokud chcete používat funkce na vyžádání, musí být váš pracovní prostor povolený pro katalog Unity a musíte použít Databricks Runtime 13.3 LTS ML nebo novější.
Co jsou funkce na vyžádání?
"Na vyžádání" odkazuje na funkce, jejichž hodnoty nejsou předem známé, ale počítají se v době odvozování. V Azure Databricks použijete uživatelem definované funkce Pythonu (UDF) k určení způsobu výpočtu funkcí na vyžádání. Tyto funkce se řídí katalogem Unity a zjistitelné prostřednictvím Průzkumníka katalogu.
Požadavky
- Pokud chcete použít uživatelem definovanou funkci (UDF) k vytvoření trénovací sady nebo k vytvoření koncového bodu obsluhy funkcí, musíte mít
USE CATALOGoprávněnísystemk katalogu v katalogu Unity.
Workflow
Pokud chcete vypočítat funkce na vyžádání, zadáte uživatelem definovanou funkci Pythonu (UDF), která popisuje, jak vypočítat hodnoty funkcí.
- Během trénování zadáte tuto funkci a její vstupní vazby v
feature_lookupsparametrucreate_training_setrozhraní API. - Vytrénovaný model je nutné protokolovat pomocí metody
log_modelÚložiště funkcí . Tím se zajistí, že model automaticky vyhodnocuje funkce na vyžádání, když se použije k odvozování. - Pro dávkové vyhodnocování
score_batchrozhraní API automaticky vypočítá a vrátí všechny hodnoty funkcí, včetně funkcí na vyžádání. - Když obsluhujete model s obsluhou modelu Mosaic AI, model automaticky použije uživatelem definované uživatelem Pythonu k výpočtu funkcí na vyžádání pro každou žádost o bodování.
Vytvoření uživatelem definovaného uživatelem Pythonu
Uživatelem definované uživatelem Pythonu můžete vytvořit v poznámkovém bloku nebo v Databricks SQL.
Spuštěním následujícího kódu v buňce poznámkového bloku například vytvoříte uživatelem definované uživatelem Pythonu example_feature v katalogu main a schématu default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Po spuštění kódu můžete procházet tříúrovňový obor názvů v Průzkumníku katalogu a zobrazit definici funkce:
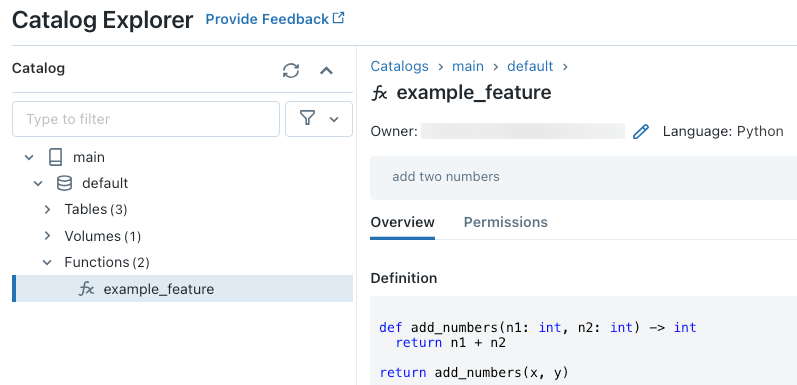
Další podrobnosti o vytváření uživatelem definovaných uživatelem Pythonu najdete v tématu Registrace uživatelem definovaného uživatelem Pythonu do katalogu Unity a příručky k jazyku SQL.
Zpracování chybějících hodnot funkcí
Pokud UDF Pythonu závisí na výsledku funkceLookup, hodnota vrácená v případě, že požadovaný vyhledávací klíč nebyl nalezen, závisí na prostředí. Při použití score_batchje Nonevrácena hodnota . Při použití online obsluhy je float("nan")vrácena hodnota .
Následující kód je příkladem způsobu zpracování obou případů.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Trénování modelu pomocí funkcí na vyžádání
K trénování modelu použijete FeatureFunctionrozhraní create_training_set API předávané do rozhraní API v parametru feature_lookups .
Následující příklad kódu používá uživatelem main.default.example_feature definované uživatelem Pythonu definované v předchozí části.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Protokolujte model a zaregistrujte ho do katalogu Unity.
Modely zabalené s metadaty funkcí je možné zaregistrovat do katalogu Unity. Tabulky funkcí použité k vytvoření modelu musí být uložené v katalogu Unity.
Pokud chcete zajistit, aby model při odvozování automaticky vyhodnocoval funkce na vyžádání, musíte nastavit identifikátor URI registru a pak model protokolovat následujícím způsobem:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Pokud uživatelem definovaným funkcím Pythonu, které definují funkce na vyžádání, importují všechny balíčky Pythonu, musíte tyto balíčky zadat pomocí argumentu extra_pip_requirements. Příklad:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Omezení
Funkce na vyžádání můžou vypisovat všechny datové typy podporované úložištěm funkcí s výjimkou MapType a ArrayType.
Příklady poznámkových bloků: Funkce na vyžádání
Následující poznámkový blok ukazuje příklad trénování a hodnocení modelu, který používá funkci na vyžádání.
Ukázkový poznámkový blok se základními funkcemi na vyžádání
Následující poznámkový blok ukazuje příklad modelu doporučení restaurace. Poloha restaurace se hledá z online tabulky Databricks. Aktuální umístění uživatele se odešle jako součást žádosti o bodování. Model používá funkci na vyžádání k výpočtu vzdálenosti v reálném čase od uživatele do restaurace. Tato vzdálenost se pak použije jako vstup do modelu.