Co je datové jezero?
Data Lakehouse je systém pro správu dat, který kombinuje výhody datových jezer a datových skladů. Tento článek popisuje model architektury lakehouse a to, co s ním můžete dělat v Azure Databricks.
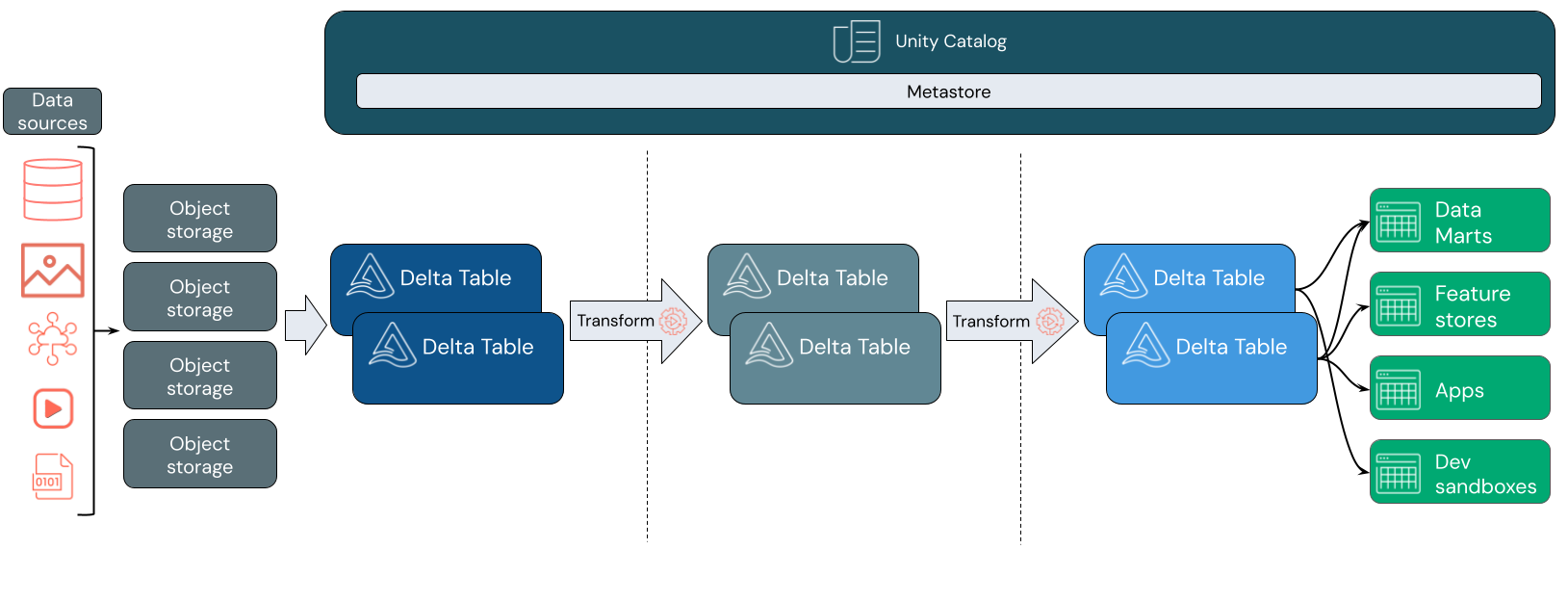
K čemu se používá datové jezero?
Data Lakehouse poskytuje škálovatelné možnosti úložiště a zpracování pro moderní organizace, které se chtějí vyhnout izolovaným systémům pro zpracování různých úloh, jako je strojové učení (ML) a business intelligence (BI). Datové jezero může pomoct vytvořit jeden zdroj pravdy, eliminovat redundantní náklady a zajistit aktuálnost dat.
Data Lakehouses často používají vzor návrhu dat, který přírůstkově vylepšuje, rozšiřuje a zpřesňuje data při procházení vrstvami přípravy a transformace. Každá vrstva jezera může obsahovat jednu nebo více vrstev. Tento model se často označuje jako architektura medailonu. Další informace najdete v tématu Co znamená architektura medallion lakehouse?
Jak funguje Databricks Lakehouse?
Databricks je založená na Apache Sparku. Apache Spark umožňuje masivně škálovatelný modul, který běží na výpočetních prostředcích oddělených od úložiště. Další informace najdete v tématu Apache Spark v Azure Databricks
Databricks Lakehouse používá dvě další klíčové technologie:
- Delta Lake: optimalizovaná vrstva úložiště, která podporuje transakce ACID a vynucení schématu.
- Katalog Unity: jednotné a jemně odstupňované řešení zásad správného řízení pro data a AI.
Příjem dat
Ve vrstvě příjmu dat přicházejí dávková nebo streamovaná data z různých zdrojů a v různých formátech. Tato první logická vrstva poskytuje místo pro to, aby data přistála v nezpracované podobě. Při převodu těchto souborů do tabulek Delta můžete pomocí funkcí vynucení schématu Delta Lake zkontrolovat chybějící nebo neočekávaná data. Katalog Unity můžete použít k registraci tabulek podle modelu zásad správného řízení dat a požadovaných hranic izolace dat. Katalog Unity umožňuje sledovat původ dat při jejich transformaci a rafinaci a také uplatnit jednotný model řízení pro zachování soukromí a zabezpečení citlivých dat.
Zpracování, správa a integrace dat
Po ověření můžete začít spravovat a zdokonalovat svá data. Odborníci na data a odborníci na strojové učení často pracují s daty v této fázi, aby mohli začít kombinovat nebo vytvářet nové funkce a dokončit čištění dat. Po důkladném vyčištění dat je možné je integrovat a přeuspořádat do tabulek navržených tak, aby vyhovovaly vašim konkrétním obchodním potřebám.
Přístup založený na schématu v kombinaci s možnostmi vývoje schématu Delta znamená, že v této vrstvě můžete provádět změny, aniž byste museli přepisovat podřízenou logiku, která obsluhuje data koncovým uživatelům.
Poskytování dat
Poslední vrstva slouží čistým a obohaceným datům koncovým uživatelům. Konečné tabulky by měly být navržené tak, aby sloužily datům pro všechny případy použití. Jednotný model zásad správného řízení znamená, že rodokmen dat můžete sledovat zpět ke svému jedinému zdroji pravdy. Rozložení dat optimalizovaná pro různé úlohy umožňují koncovým uživatelům přístup k datům pro aplikace strojového učení, datové inženýrství a business intelligence a reporting.
Další informace o Delta Lake najdete v tématu Co je Delta Lake? Další informace o katalogu Unity najdete v tématu Co je Katalog Unity?
Možnosti datového jezera Databricks
Lakehouse postavený na Databricks nahrazuje aktuální závislost na datových jezerech a datových skladech pro moderní datové společnosti. Mezi klíčové úlohy, které můžete provést, patří:
- zpracování dat v reálném čase: Zpracování streamovaných dat v reálném čase pro okamžitou analýzu a akci.
- integrace dat : sjednocení dat v jednom systému, abyste umožnili spolupráci a vytvořili jediný zdroj pravdy pro vaši organizaci.
- vývoj schématu : upravit schéma dat v průběhu času tak, aby se přizpůsobilo měnícím se obchodním potřebám bez narušení stávajících datových kanálů.
- transformace dat : Použití Apache Sparku a Delta Lake přináší vašim datům rychlost, škálovatelnost a spolehlivost.
- Analýza a vytváření sestav dat: Spouštění složitých analytických dotazů pomocí modulu optimalizovaného pro úlohy datových skladů.
- Strojové učení a AI: Použití pokročilých analytických technik na všechna vaše data. Využijte ML k obohacení dat a podpoře dalších úloh.
- správa verzí dat a rodokmen: Udržovat historii verzí datových sad a sledovat rodokmen, aby se zajistila původ a sledovatelnost dat.
- zásady správného řízení dat: Pomocí jednoho sjednoceného systému můžete řídit přístup k datům a provádět audity.
- sdílení dat : Usnadnit spolupráci tím, že umožňuje sdílení kurátorovaných datových sad, sestav a přehledů napříč týmy.
- Provozní analýza: Monitorujte ukazatele kvality dat, ukazatele kvality modelu a posunu pomocí strojového učení na data pro monitorování lakehouse.
Lakehouse vs Data Lake vs Data Warehouse
Datové sklady pohánějí rozhodování v oblasti business intelligence (BI) přibližně 30 let a vyvinuly se jako soubor návrhových pokynů pro systémy řízení toku dat. Podnikové datové sklady optimalizují dotazy pro sestavy BI, ale generování výsledků může trvat několik minut nebo i hodin. Datové sklady navržené pro data, která se pravděpodobně nemění s vysokou frekvencí, se snaží zabránit konfliktům mezi souběžně běžícími dotazy. Mnoho datových skladů spoléhá na proprietární formáty, které často omezují podporu strojového učení. Datové sklady na platformě Azure Databricks využívají možnosti Databricks Lakehouse a Databricks SQL. Další informace najdete v tématu Co je datový sklad v Azure Databricks?.
Díky technologickým pokrokům v oblasti ukládání dat a řízená exponenciálním nárůstem typů a objemu dat se datová jezera v posledních deseti letech běžně používají. Datová jezera ukládají a zpracovávají data levně a efektivně. Datová jezera jsou často definována v rozporu s datovými sklady: Datový sklad poskytuje čistá a strukturovaná data pro analýzy BI, zatímco datové jezero trvale a levně ukládá data libovolné povahy v libovolném formátu. Mnoho organizací používá datová jezera pro datové vědy a strojové učení, ale ne pro vytváření sestav BI kvůli své zastaralé povaze.
Data Lakehouse kombinuje výhody datových jezer a datových skladů a poskytuje:
- Otevřený přímý přístup k datům uloženým ve standardních datových formátech.
- Indexovací protokoly optimalizované pro strojové učení a datové vědy
- Nízká latence dotazů a vysoká spolehlivost pro BI a pokročilou analýzu
Kombinací optimalizované vrstvy metadat s ověřenými daty uloženými ve standardních formátech v cloudovém úložišti objektů umožňuje data lakehouse datovým vědcům a technikům STROJOVÉho učení vytvářet modely ze stejných sestav BI řízených daty.
Další krok
Další informace o principech a osvědčených postupech pro implementaci a provozování jezera s využitím Databricks najdete v tématu Úvod k dobře navrženým datovým jezerům