Stažení referenčních architektur lakehouse
Tento článek popisuje pokyny k architektuře pro jezero z hlediska zdroje dat, příjmu dat, transformace, dotazování a zpracování, obsluhy, analýzy/výstupu a úložiště.
Každá referenční architektura má ke stažení PDF ve formátu 11 x 17 (A3).
Obecná referenční architektura
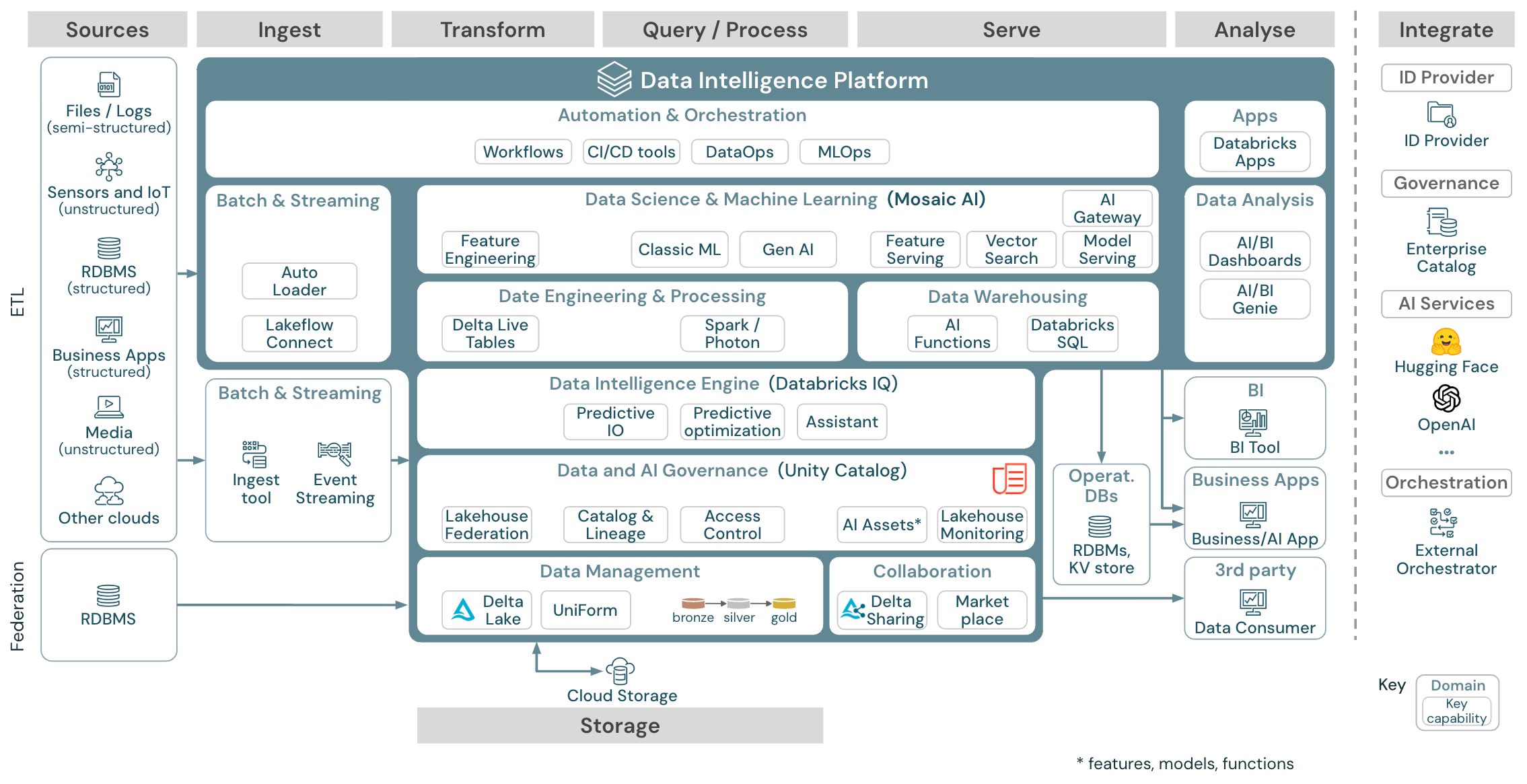
Ke stažení: Referenční architektura Generic Lakehouse pro Databricks (PDF)
Uspořádání referenčních architektur
Referenční architektura je strukturovaná podél plavecké dráhy Zdroj, Ingestování, Transformace, Dotazování a proces, Obsluha, Analýza a Úložiště:
Source
Architektura rozlišuje částečně strukturovaná a nestrukturovaná data (senzory a IoT, média, soubory/protokoly) a strukturovaná data (RDBMS, obchodní aplikace). Zdroje SQL (RDBMS) je také možné integrovat do lakehouse a katalogu Unity bez ETL prostřednictvím federace lakehouse. Kromě toho se můžou načítat data od jiných poskytovatelů cloudu.
Spolknout potravu
Data je možné ingestovat do jezera prostřednictvím dávky nebo streamování:
- Soubory doručované do cloudového úložiště je možné načíst přímo pomocí automatického zavaděče Databricks.
- V případě dávkového příjmu dat z podnikových aplikací do Delta Lake spoléhá Databricks Lakehouse na partnerské nástroje ingestování s konkrétními adaptéry pro tyto systémy záznamu.
- Události streamování se můžou ingestovat přímo ze systémů streamování událostí, jako je Kafka pomocí strukturovaného streamování Databricks. Zdroje streamování můžou být senzory, IoT nebo procesy zachytávání dat.
Úložiště
Data jsou obvykle uložená v systému cloudového úložiště, kde kanály ETL používají architekturu medailonu k ukládání dat kurátorovaným způsobem jako soubory nebo tabulky Delta.
Transformace a dotazování a zpracování
Databricks Lakehouse používá své moduly Apache Spark a Photon pro všechny transformace a dotazy.
Vzhledem k jednoduchosti je deklarativní architektura DLT (Delta Live Tables) dobrou volbou pro vytváření spolehlivých, udržovatelných a testovatelných kanálů zpracování dat.
Platforma Databricks Data Intelligence Platform s podporou Apache Sparku a Photonu podporuje oba typy úloh: dotazy SQL prostřednictvím sql warehouse a úlohy SQL, Python a Scala prostřednictvím clusterů pracovních prostorů.
V případě datových věd (ML Modeling and Gen AI) poskytuje platforma Databricks AI a Machine Learning specializované moduly runtime ML pro AutoML a pro kódování úloh ML. MLflow nejlépe podporuje všechny pracovní postupy datových věd a MLOps.
Sloužit
Pro případy použití DWH a BI poskytuje Databricks Lakehouse Databricks SQL, datový sklad využívající sql warehouse a bezserverové služby SQL Warehouse.
Pro strojové učení je obsluha modelů škálovatelný model na podnikové úrovni hostovaný v řídicí rovině Databricks.
Provozní databáze: Externí systémy, jako jsou provozní databáze, se dají použít k ukládání a doručování konečných datových produktů do uživatelských aplikací.
Spolupráce: Obchodní partneři získají zabezpečený přístup k datům, která potřebují prostřednictvím rozdílového sdílení. Na základě rozdílového sdílení je Databricks Marketplace otevřeným fórem pro výměnu datových produktů.
Analýza
Poslední obchodní aplikace jsou v této plavecké dráhou. Mezi příklady patří vlastní klienti, jako jsou aplikace AI připojené k rozhraní AI Model Serving pro odvozování v reálném čase, nebo aplikace, které přistupují k datům odsílaným z jezera do provozní databáze.
V případě použití BI analytici obvykle používají nástroje BI pro přístup k datovému skladu. Vývojáři SQL můžou navíc použít Editor SQL Databricks (nezobrazuje se v diagramu) pro dotazy a řídicí panely.
Platforma data Intelligence také nabízí řídicí panely pro vytváření vizualizací dat a sdílení přehledů.
Možnosti pro vaše úlohy
Kromě toho databricks lakehouse nabízí možnosti správy, které podporují všechny úlohy:
Zásady správného řízení pro data a AI
Centrální systém zásad správného řízení dat a AI v platformě Databricks Data Intelligence Platform je katalog Unity. Katalog Unity poskytuje jediné místo pro správu zásad přístupu k datům, které se vztahují na všechny pracovní prostory, a podporuje všechny prostředky vytvořené nebo používané v jezeře, jako jsou tabulky, svazky, funkce (úložiště funkcí) a modely (registr modelů). Katalog Unity se dá použít také k zachycení rodokmenu dat modulu runtime napříč dotazy spuštěným v Databricks.
Monitorování Databricks Lakehouse umožňuje monitorovat kvalitu dat ve všech tabulkách ve vašem účtu. Může také sledovat výkon modelů strojového učení a koncových bodů obsluhy modelů.
Pro pozorovatelnost jsou systémové tabulky analytické úložiště provozních dat vašeho účtu hostované službou Databricks. Systémové tabulky se dají použít pro historickou pozorovatelnost v rámci vašeho účtu.
Modul pro analýzu dat
Platforma Databricks Data Intelligence umožňuje celé organizaci používat data a umělou inteligenci. Využívá databricksIQ a kombinuje generování umělé inteligence s unifikačními výhodami jezera, aby porozuměla jedinečné sémantice vašich dat.
Databricks Assistant je k dispozici v poznámkových blocích Databricks, editoru SQL a editoru souborů jako pomocník pro AI pracující s kontextem pro vývojáře.
Orchestrace
Úlohy Databricks orchestrují zpracování dat, strojové učení a analytické kanály na platformě Databricks Data Intelligence. Delta Live Tables umožňuje vytvářet spolehlivé a udržovatelné kanály ETL s deklarativní syntaxí.
Referenční architektura platformy Data Intelligence v Azure
Referenční architektura Azure Databricks je odvozená od obecné referenční architektury přidáním služeb specifických pro Azure pro elementy Source, Ingest, Serve, Analysis/Output a Storage.
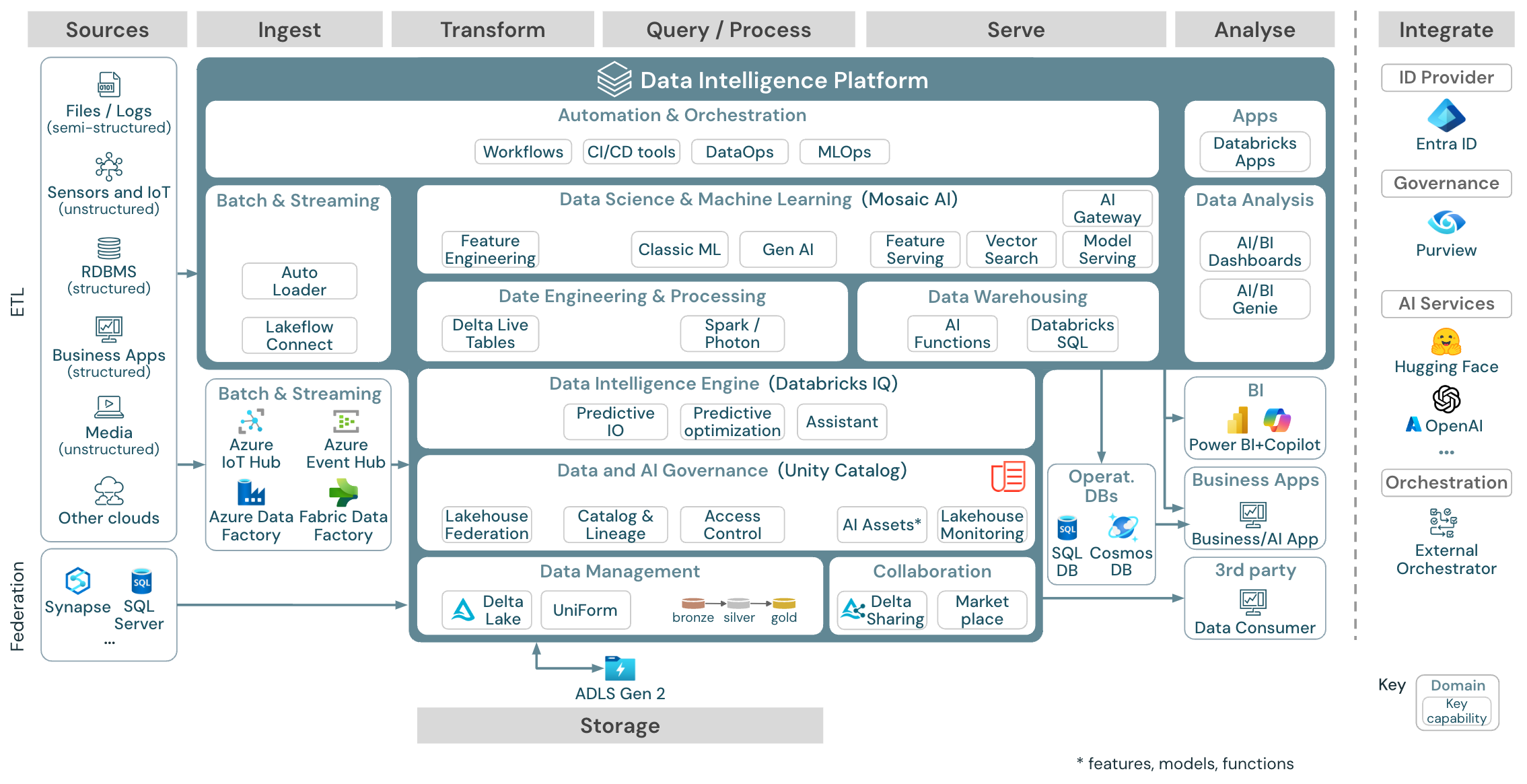
Ke stažení: Referenční architektura pro Databricks Lakehouse v Azure
Referenční architektura Azure ukazuje následující služby specifické pro Azure pro ingestování, úložiště, obsluhu a analýzu a výstup:
- Azure Synapse a SQL Server jako zdrojové systémy pro Federaci Lakehouse
- Azure IoT Hub a Azure Event Hubs pro příjem streamování
- Azure Data Factory pro dávkové ingestování
- Azure Data Lake Storage Gen2 (ADLS) jako úložiště objektů
- Azure SQL DB a Azure Cosmos DB jako provozní databáze
- Azure Purview jako podnikový katalog, do kterého uc exportuje informace o schématu a rodokmenu
- Power BI jako nástroj BI
Poznámka:
- Toto zobrazení referenční architektury se zaměřuje pouze na služby Azure a databricks lakehouse. Lakehouse v Databricks je otevřená platforma, která se integruje s rozsáhlým ekosystémem partnerských nástrojů.
- Zobrazené služby poskytovatele cloudu nejsou vyčerpávající. Jsou vybrány k ilustraci konceptu.
Případ použití: Batch ETL
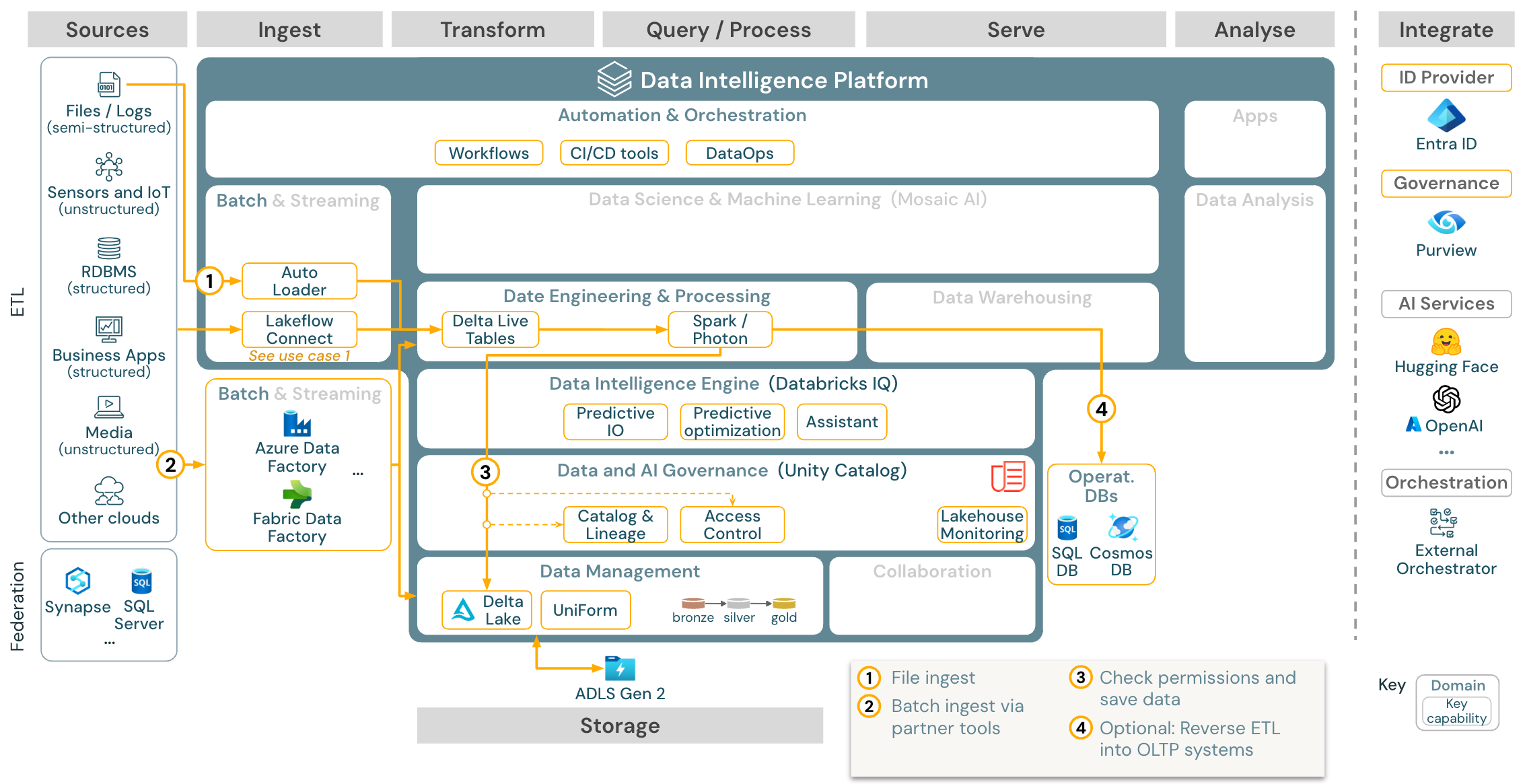
Stáhnout: Referenční architektura Batch ETL pro Azure Databricks
Nástroje Ingestování používají adaptéry specifické pro zdroj ke čtení dat ze zdroje a pak je buď ukládají do cloudového úložiště, odkud ho může automatický zavaděč číst, nebo volat Databricks přímo (například s nástroji pro příjem partnerských ingestací integrovaných do Databricks Lakehouse). Pokud chcete načíst data, spouští dotazy modul ETL a zpracování Databricks prostřednictvím DLT. Pracovní postupy s jedním nebo více úkoly je možné orchestrovat pomocí úloh Databricks a řídit se katalogem Unity (řízení přístupu, audit, rodokmen atd.). Pokud provozní systémy s nízkou latencí vyžadují přístup ke konkrétním zlatým tabulkám, je možné je exportovat do provozní databáze, jako je rdBMS nebo úložiště klíč-hodnota na konci kanálu ETL.
Případ použití: Streamování a zachytávání dat změn (CDC)
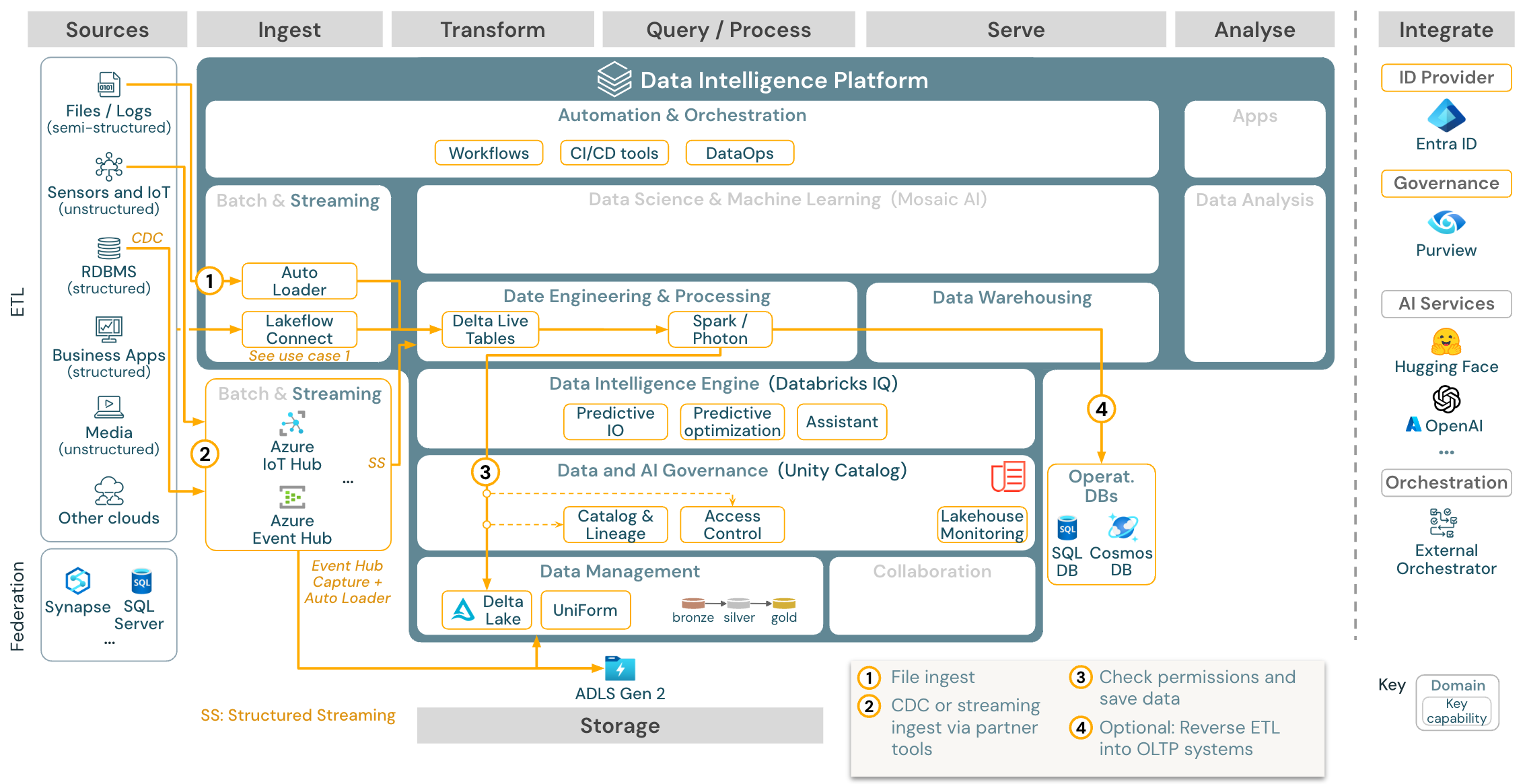
Stažení: Architektura strukturovaného streamování Sparku pro Azure Databricks
Modul ETL pro Databricks používá strukturované streamování Sparku ke čtení z front událostí, jako je Apache Kafka nebo Azure Event Hub. Následující kroky se řídí přístupem výše uvedeného případu použití služby Batch.
Zachytávání dat změn v reálném čase (CDC) obvykle používá frontu událostí k ukládání extrahovaných událostí. Odsud se případ použití řídí případem použití streamování.
Pokud se CDC provádí v dávce, kde jsou extrahované záznamy nejprve uložené v cloudovém úložišti, může je autoloader Databricks přečíst a případ použití následuje po dávkovém ETL.
Případ použití: Strojové učení a AI
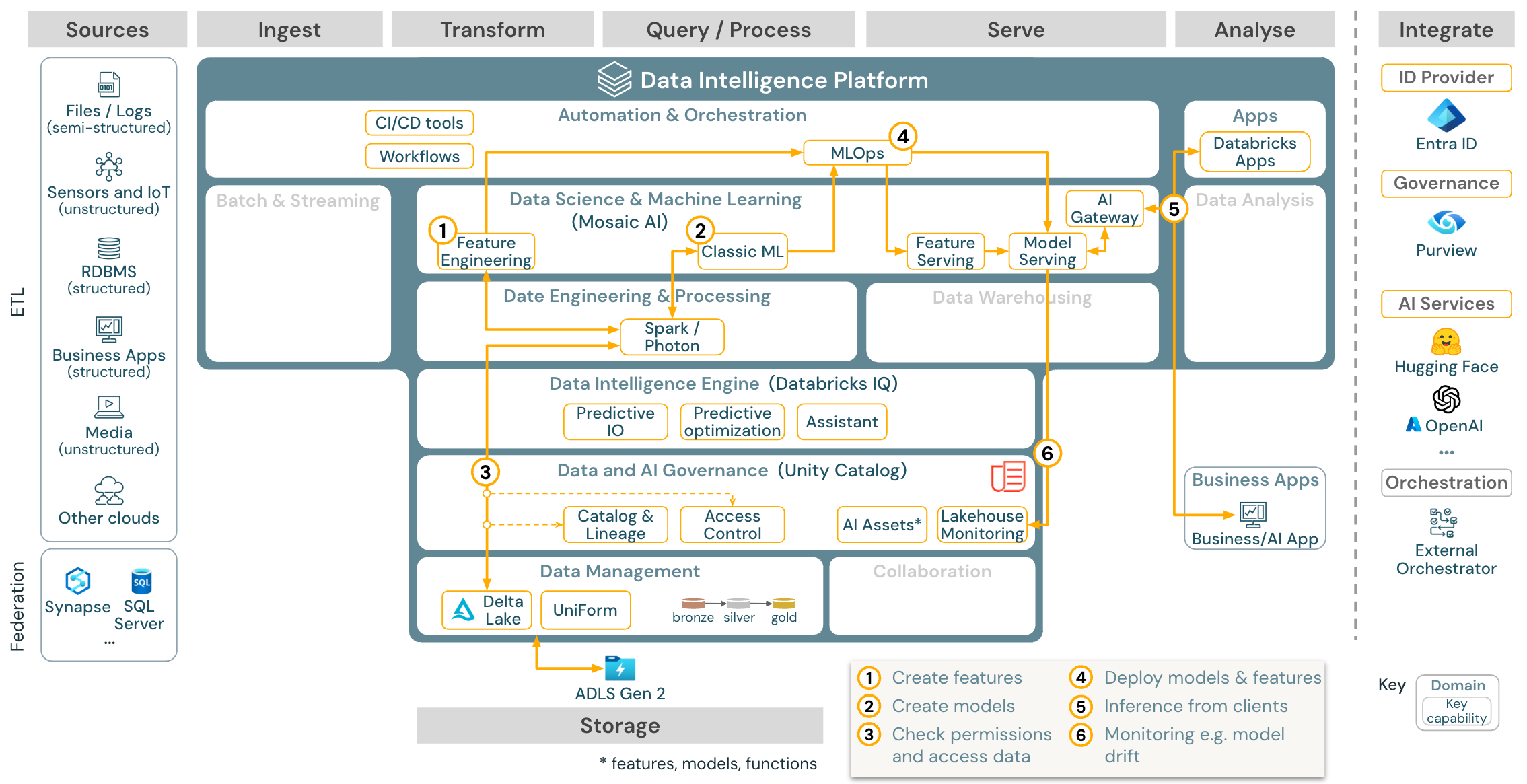
Stáhnout: Referenční architektura strojového učení a AI pro Azure Databricks
Pro strojové učení poskytuje platforma Databricks Data Intelligence AI umělou inteligenci, která se dodává s nejmodernějšími knihovnami strojového a hlubokého učení. Poskytuje funkce, jako je úložiště funkcí a registr modelů (integrované do katalogu Unity), funkce s nízkým kódem s AutoML a integrace MLflow do životního cyklu datových věd.
Všechny prostředky související s datovými vědami (tabulky, funkce a modely) se řídí katalogem Unity a datoví vědci můžou k orchestraci svých úloh použít Databricks Jobs.
Pokud chcete nasazovat modely škálovatelným a podnikovým způsobem, použijte funkce MLOps k publikování modelů v obsluhě modelu.
Případ použití: Načtení rozšířené generace (Gen AI)
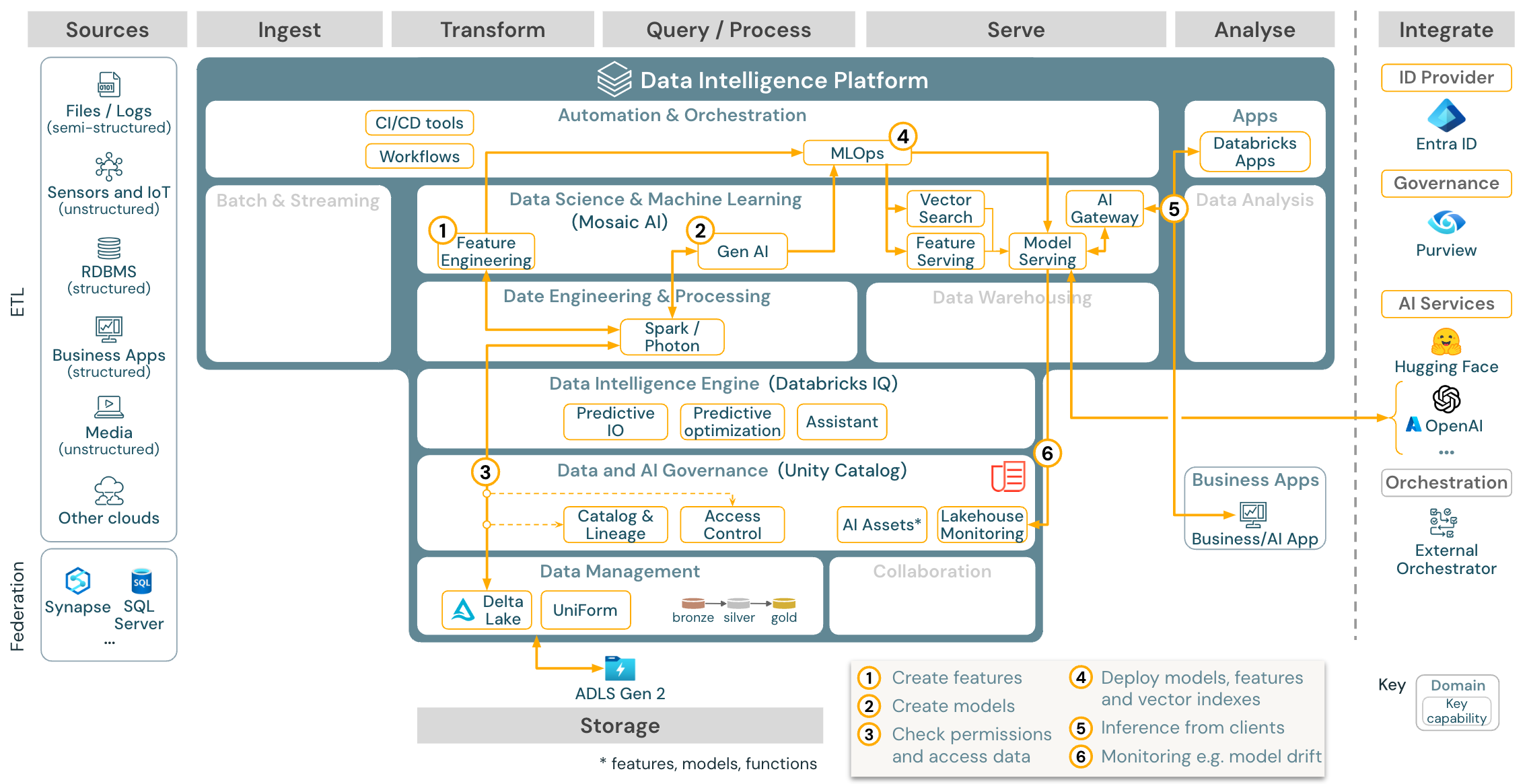
Stáhnout: Referenční architektura AI RAG genu pro Azure Databricks
Pro případy použití generující umělé inteligence přichází systém Mosaic AI se špičkovými knihovnami a konkrétními možnostmi Gen AI od výzev k doladění stávajících modelů a předběžného trénování od nuly. Výše uvedená architektura ukazuje příklad toho, jak je možné integrovat vektorové vyhledávání k vytvoření aplikace AI (rag (načítání rozšířené generace).
Pokud chcete nasazovat modely škálovatelným a podnikovým způsobem, použijte funkce MLOps k publikování modelů v obsluhě modelu.
Případ použití: ANALÝZY BI a SQL
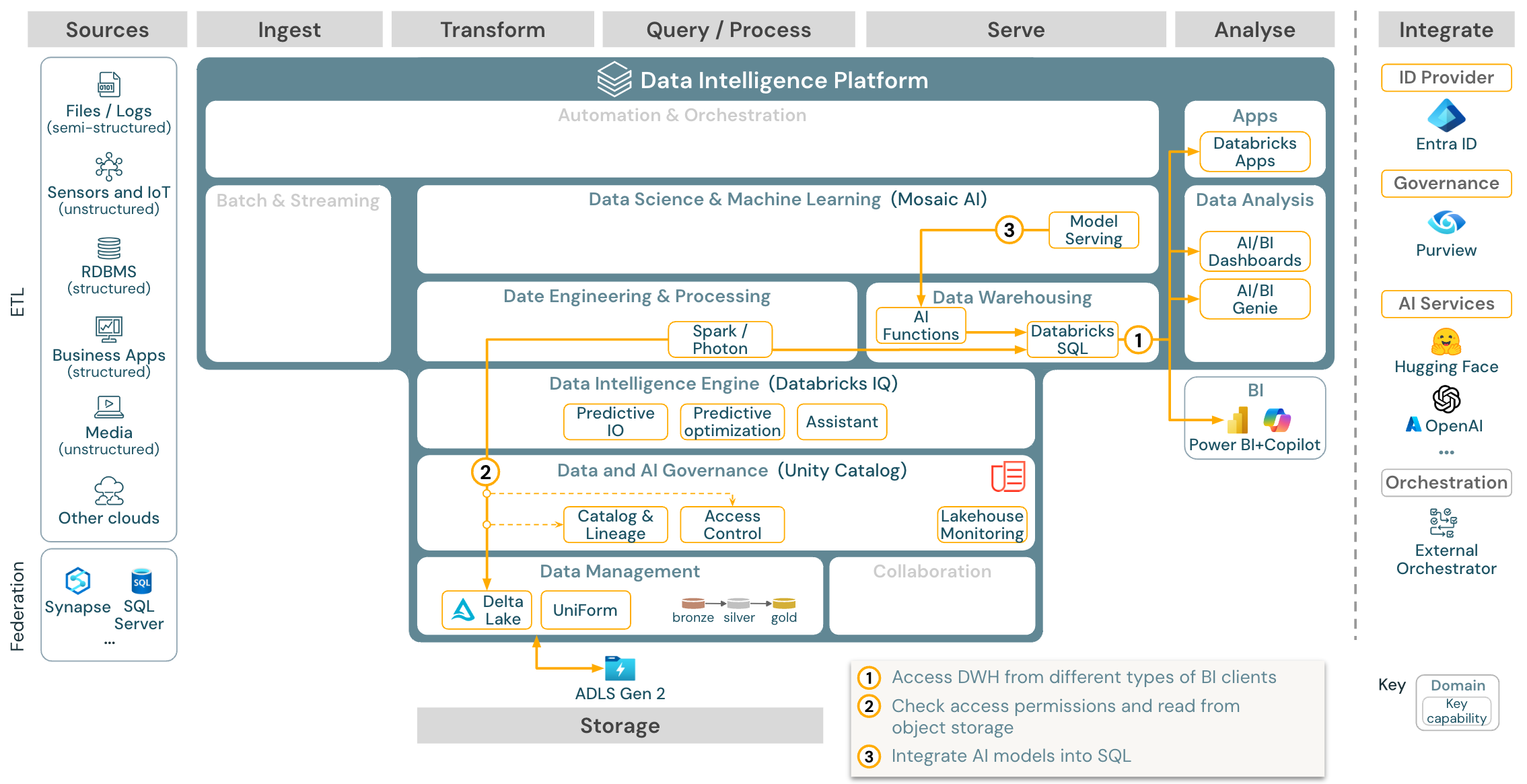
Stažení: Referenční architektura analýz BI a SQL pro Azure Databricks
V případě použití BI můžou obchodní analytici používat řídicí panely, editor SQL Databricks nebo konkrétní nástroje BI, jako je Tableau nebo Power BI. Ve všech případech je modul Databricks SQL (bezserverový nebo bezserverový) a zjišťování, zkoumání a řízení přístupu k datům poskytuje Katalog Unity.
Případ použití: Federace Lakehouse
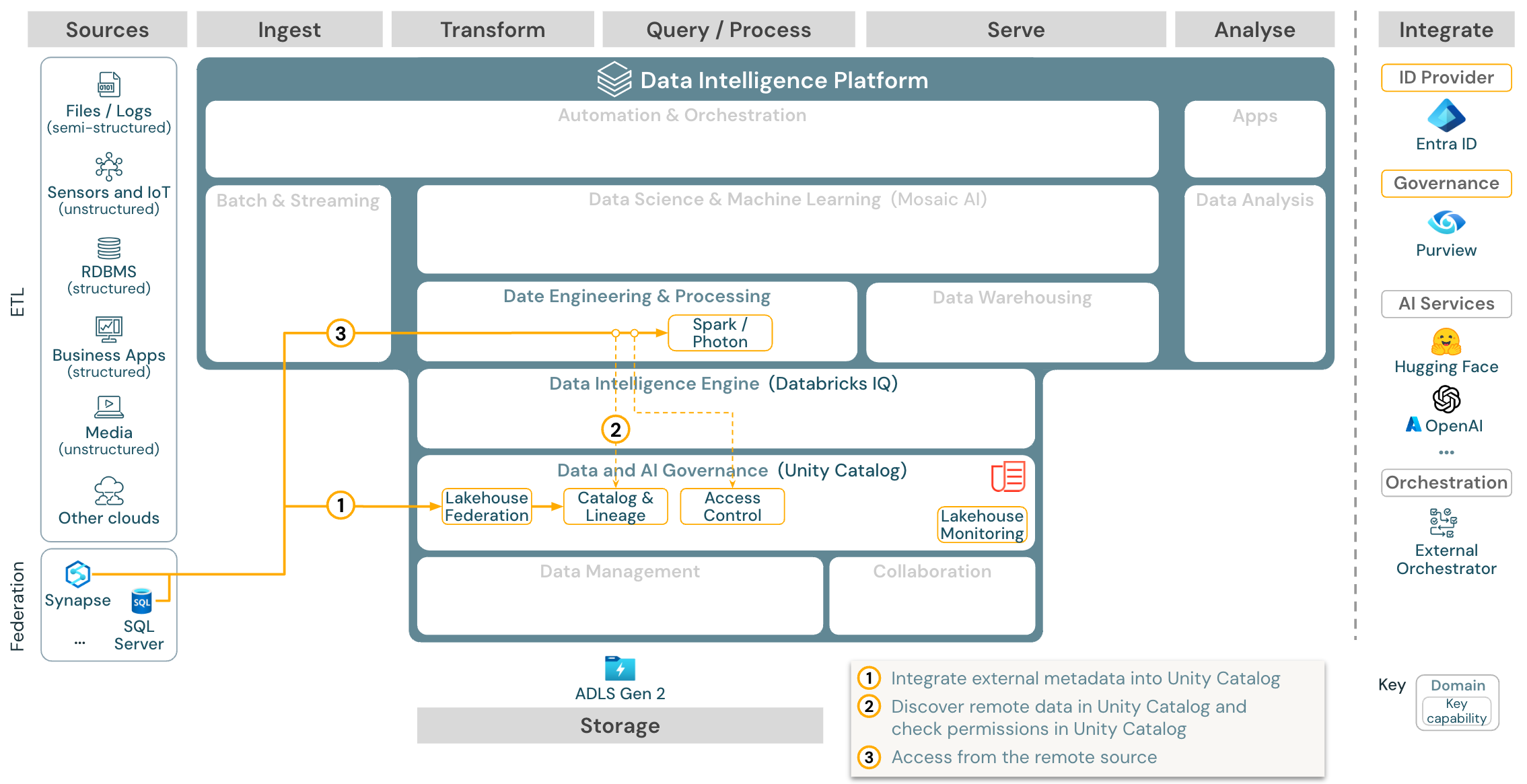
Stáhnout: Referenční architektura federace Lakehouse pro Azure Databricks
Federace Lakehouse umožňuje integraci externích databází SQL dat (například MySQL, Postgres, SQL Serveru nebo Azure Synapse) s Databricks.
Všechny úlohy (AI, DWH a BI) z toho můžou těžit, aniž by bylo nutné nejprve data etL do úložiště objektů. Externí zdrojový katalog je mapován do katalogu Unity a jemně odstupňované řízení přístupu lze použít pro přístup přes platformu Databricks.
Případ použití: Sdílení podnikových dat
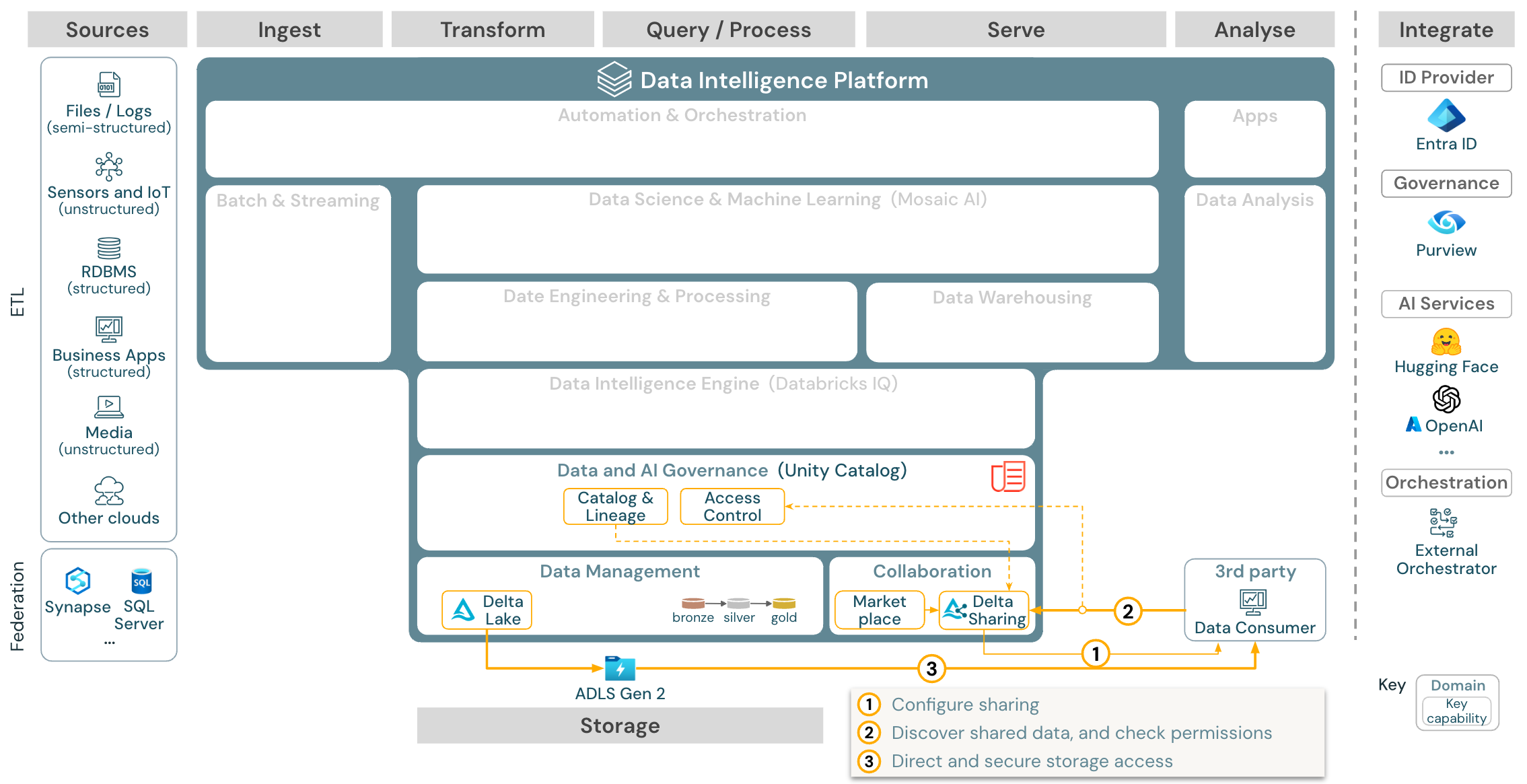
Stáhnout: Referenční architektura sdílení podnikových dat pro Azure Databricks
Sdílení dat na podnikové úrovni poskytuje rozdílové sdílení. Poskytuje přímý přístup k datům v úložišti objektů zabezpečených službou Unity Catalog a Databricks Marketplace je otevřené fórum pro výměnu datových produktů.