Vytvoření prvního pracovního postupu pomocí úlohy Azure Databricks
Tento článek ukazuje úlohu Azure Databricks, která orchestruje úlohy pro čtení a zpracování ukázkové datové sady. V tomto rychlém startu:
- Vytvořte nový poznámkový blok a přidejte kód pro načtení ukázkové datové sady obsahující oblíbené názvy dětí podle roku.
- Uložte ukázkovou datovou sadu do katalogu Unity.
- Vytvořte nový poznámkový blok a přidejte kód pro čtení datové sady z katalogu Unity, vyfiltrujte ho podle roku a zobrazte výsledky.
- Vytvořte novou úlohu a pomocí poznámkových bloků nakonfigurujte dva úkoly.
- Spusťte úlohu a zobrazte výsledky.
Požadavky
Pokud je váš pracovní prostor s povoleným katalogem Unity a bezserverové úlohy je ve výchozím nastavení povolená, úloha běží na bezserverových výpočetních prostředcích. Ke spuštění úlohy s bezserverovým výpočetním prostředím nepotřebujete oprávnění k vytvoření clusteru.
V opačném případě musíte mít oprávnění k vytvoření výpočetních prostředků úloh nebo oprávnění k výpočetním prostředkům pro všechny účely.
V my-volume ve schématu s názvem default v katalogu s názvem main. V katalogu Unity musíte mít také následující oprávnění:
-
READ VOLUMEaWRITE VOLUME, neboALL PRIVILEGES, promy-volumesvazek. -
USE SCHEMAneboALL PRIVILEGESpro schémadefault. -
USE CATALOGneboALL PRIVILEGESpro katalogmain.
Pokud chcete tato oprávnění nastavit, obraťte se na správce Databricks nebo oprávnění katalogu Unity a zabezpečitelné položky.
Vytvoření poznámkových bloků
Načtení a uložení dat
Vytvoření poznámkového bloku pro načtení ukázkové datové sady a jeho uložení do katalogu Unity:
Přejděte na cílovou stránku Azure Databricks a na bočním panelu klikněte na
 Nová a vyberte Poznámkový blok. Databricks vytvoří a otevře nový prázdný poznámkový blok ve vaší výchozí složce. Výchozím jazykem je jazyk, který jste naposledy použili, a poznámkový blok se automaticky připojí k výpočetnímu prostředku, který jste použili naposledy.
Nová a vyberte Poznámkový blok. Databricks vytvoří a otevře nový prázdný poznámkový blok ve vaší výchozí složce. Výchozím jazykem je jazyk, který jste naposledy použili, a poznámkový blok se automaticky připojí k výpočetnímu prostředku, který jste použili naposledy.V případě potřeby změňte výchozí jazyk na Python.
Zkopírujte následující kód Pythonu a vložte ho do první buňky poznámkového bloku.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Čtení a zobrazení filtrovaných dat
Vytvoření poznámkového bloku pro čtení a prezentaci dat pro filtrování:
Přejděte na cílovou stránku Azure Databricks a na bočním panelu klikněte na
Nová a vyberte Poznámkový blok. Databricks vytvoří a otevře nový prázdný poznámkový blok ve vaší výchozí složce. Výchozím jazykem je jazyk, který jste naposledy použili, a poznámkový blok se automaticky připojí k výpočetnímu prostředku, který jste použili naposledy.V případě potřeby změňte výchozí jazyk na Python.
Zkopírujte následující kód Pythonu a vložte ho do první buňky poznámkového bloku.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Vytvoření úlohy
Na bočním panelu klikněte na
 Pracovní postupy.
Pracovní postupy.Klikněte na
 .
.Karta Úkoly se zobrazí v dialogovém okně vytvořit úkol.
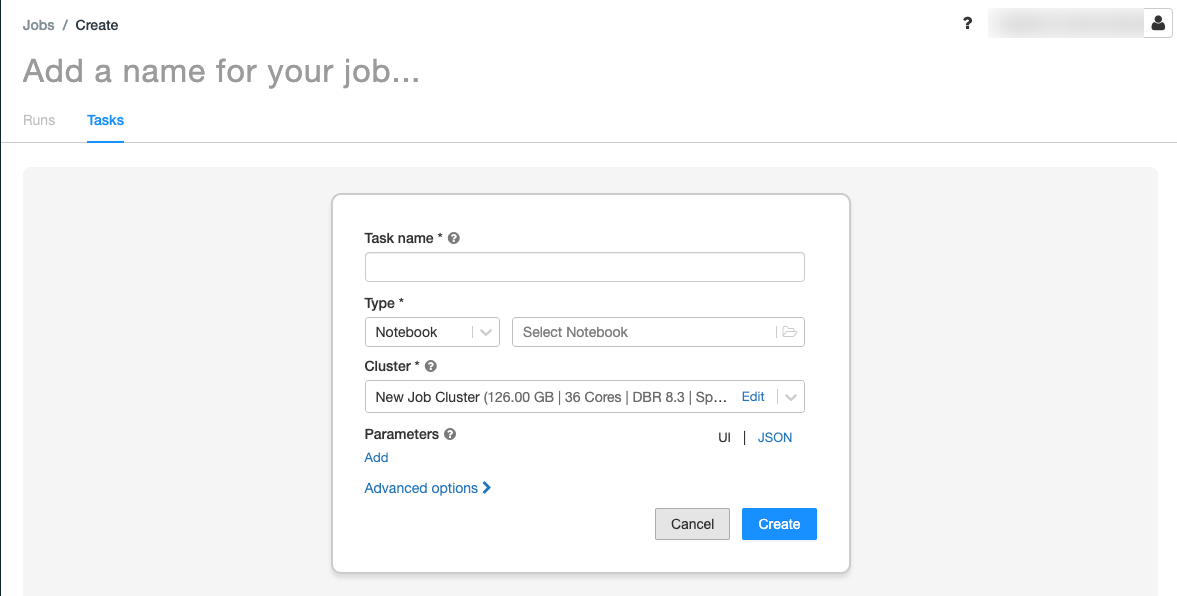
Nahraďte název vaší úlohy... názvem vaší úlohy.
Do pole Název úkolu zadejte název úkolu, například načíst jména dětí.
V rozbalovací nabídce Typ vyberte Notebook.
Pomocí prohlížeče souborů vyhledejte první poznámkový blok, který jste vytvořili, klikněte na název poznámkového bloku a klikněte na Potvrdit.
Klikněte na Vytvořit úkol.
Kliknutím pod
 úkol, který jste právě vytvořili, přidejte další úkol.
úkol, který jste právě vytvořili, přidejte další úkol.Do pole Název úkolu zadejte název úkolu, například názvy filtru pro dítě.
V rozevírací nabídce Typ vyberte Notebook.
V prohlížeči souborů vyhledejte druhý poznámkový blok, který jste vytvořili, klikněte na název poznámkového bloku a klikněte na Potvrdit.
Klikněte na Přidat pod Parametry. Do pole Klíč zadejte
year. Do pole Hodnota zadejte2014.Klikněte na Vytvořit úkol.
Spuštění úlohy
Pokud chcete úlohu spustit okamžitě, klikněte  v pravém horním rohu. Úlohu můžete spustit také kliknutím na kartu Spuštění a kliknutím na Spustit nyní v tabulce Aktivní Spuštění.
v pravém horním rohu. Úlohu můžete spustit také kliknutím na kartu Spuštění a kliknutím na Spustit nyní v tabulce Aktivní Spuštění.
Zobrazení podrobností o spuštění
Klikněte na kartu Běhy a klikněte na odkaz pro běh v tabulce Aktivní běhy nebo v tabulce Dokončené běhy (posledních 60 dnů).
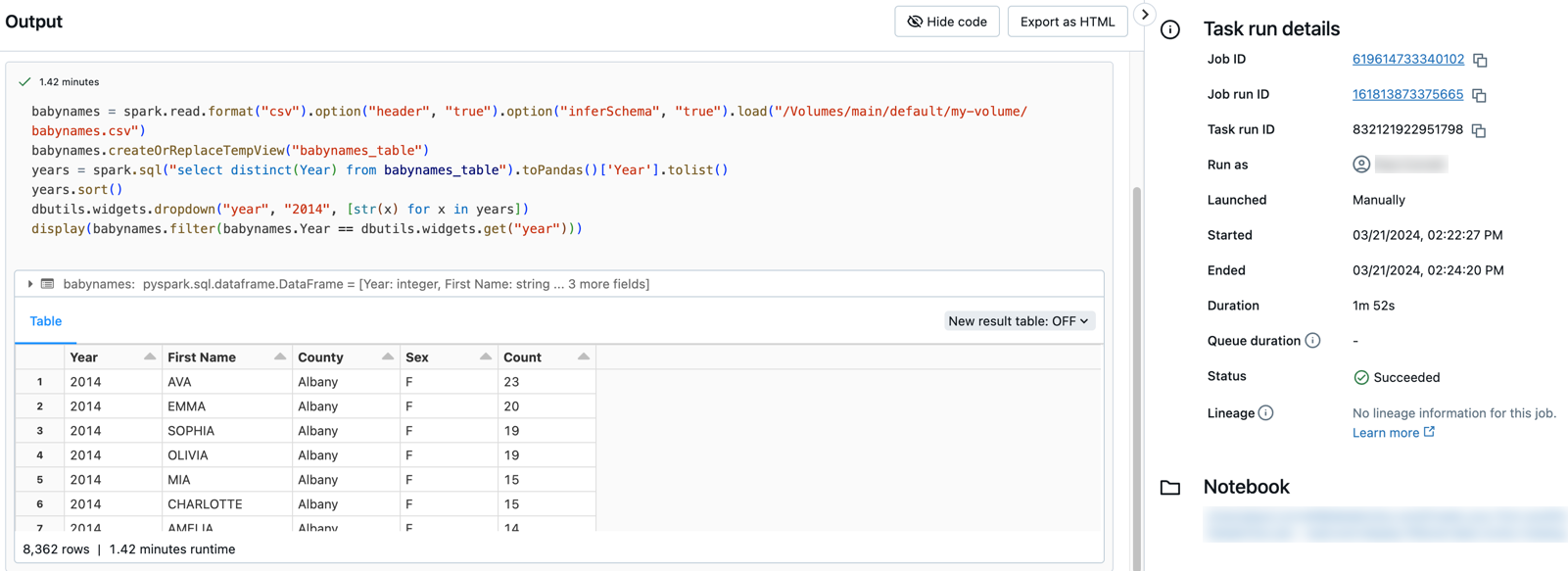
Kliknutím na některý z úkolů zobrazíte výstup a podrobnosti. Klikněte například na úlohu filtru-baby-names , abyste zobrazili výstup a spustili podrobnosti pro úlohu filtru:
Spusťte s různými parametry
Opětovné spuštění úlohy a filtrování jmen dětí pro jiný rok:
- Klikněte na
 Blue Down Caret vedle Spustit nyní a vyberte Spustit nyní s různými parametry nebo klikněte na Spustit s různými parametry v tabulce Aktivní spuštění.
Blue Down Caret vedle Spustit nyní a vyberte Spustit nyní s různými parametry nebo klikněte na Spustit s různými parametry v tabulce Aktivní spuštění. -
Do pole Hodnota zadejte
2015. - Klepněte na položku Spustit.