Vytvoření nestrukturovaného datového kanálu pro RAG
Tento článek popisuje, jak vytvořit nestrukturovaný datový kanál pro aplikace generativní umělé inteligence. Nestrukturované kanály jsou zvláště užitečné pro aplikace Retrieval-Augmented generování (RAG).
Zjistěte, jak převést nestrukturovaný obsah, jako jsou textové soubory a soubory PDF, na vektorový index, na který můžou dotazovat agenti umělé inteligence nebo jiné načítáče. Dozvíte se také, jak experimentovat a ladit kanál tak, aby optimalizoval bloky dat, indexování a parsování dat, abyste mohli řešit potíže a experimentovat s kanálem, abyste dosáhli lepších výsledků.
Poznámkový blok nestrukturovaného datového kanálu
Následující poznámkový blok ukazuje, jak implementovat informace v tomto článku a vytvořit nestrukturovaný datový kanál.
Nestrukturovaný datový kanál Databricks
Klíčové komponenty datového kanálu

Základem jakékoli aplikace RAG s nestrukturovanými daty je datový kanál. Tento pipeline je zodpovědný za kurátorování a přípravu nestrukturovaných dat ve formátu, který může aplikace RAG účinně používat. I když se tento datový kanál může stát složitým v závislosti na případu použití, musíte při prvním sestavení aplikace RAG zvážit následující klíčové komponenty:
- Složení a příjem dat: Vyberte správné zdroje dat a obsah na základě konkrétního případu použití.
-
Předběžné zpracování dat: Transformace nezpracovaných dat na čistý, konzistentní formát vhodný pro vkládání a načítání.
- parsování: Extrahujte relevantní informace z nezpracovaných dat pomocí vhodných technik analýzy.
-
rozšíření: Rozšiřte data o další metadata a odstraňte šum.
- extrakce metadat: Extrahujte užitečná metadata pro rychlejší a efektivnější načítání dat.
- odstranění duplicitních dat: Analyzujte dokumenty a identifikujte a eliminujte duplicity nebo téměř duplicitní dokumenty.
- filtrování: Eliminujte irelevantní nebo nežádoucí dokumenty z kolekce.
- Členění: Rozdělte analyzovaná data na menší, spravovatelné části pro efektivní načítání.
- Vkládání: Převeďte segmentovaná textová data na číselnou vektorovou reprezentaci, která zachycuje jejich sémantický význam.
- indexování a ukládání: Vytváření efektivních vektorových indexů pro optimalizovaný výkon vyhledávání.
složení a příjem korpusu
Aplikace RAG nemůže načíst informace potřebné k zodpovězení uživatelského dotazu bez správného datového korpusu. Správná data jsou zcela závislá na konkrétních požadavcích a cílech vaší aplikace, takže je nezbytné věnovat čas pochopení nuancí dostupných dat. Další informace najdete v tématu vývojářský pracovní postup pro aplikace generativní AI.
Při vytváření robota zákaznické podpory můžete například zvážit následující:
- Dokumenty znalostní báze
- Nejčastější dotazy (FAQ)
- Příručky a specifikace produktů
- Průvodce řešením potíží
Zapojte odborníky na domény a zúčastněné strany od začátku jakéhokoli projektu, abyste mohli identifikovat a kurátorovat relevantní obsah, který by mohl zlepšit kvalitu a pokrytí vašeho datového korpusu. Můžou poskytnout přehled o typech dotazů, které uživatelé pravděpodobně odesílají, a pomáhají určit prioritu těch nejdůležitějších informací, které se mají zahrnout.
Databricks doporučuje ingestovat data škálovatelným a přírůstkovým způsobem. Azure Databricks nabízí různé metody pro příjem dat, včetně plně spravovaných konektorů pro aplikace SaaS a integrace rozhraní API. Osvědčeným postupem je, že nezpracovaná zdrojová data by se měla ingestovat a ukládat v cílové tabulce. Tento přístup zajišťuje zachování, sledovatelnost a auditování dat. Viz Ingestování dat doAzure Databricks Lakehouse .
předběžné zpracování dat
Po ingestování dat je nezbytné vyčistit a naformátovat nezpracovaná data do konzistentního formátu vhodného pro vkládání a načítání.
Analýza
Po identifikaci příslušných zdrojů dat pro vaši aplikaci retrieveru je dalším krokem extrahování požadovaných informací z nezpracovaných dat. Tento proces označovaný jako analýza zahrnuje transformaci nestrukturovaných dat do formátu, který může aplikace RAG efektivně používat.
Konkrétní techniky analýzy a nástroje, které používáte, závisí na typu dat, se kterými pracujete. Příklad:
- Textové dokumenty (PDF, wordová dokumentace): Nestrukturované knihovny, jako jsou nestrukturované a PyPDF2 , můžou zpracovávat různé formáty souborů a poskytují možnosti pro přizpůsobení procesu analýzy.
- dokumenty HTML: knihovny analýzy HTML, jako jsou beautifulSoup a lxml, lze použít k extrakci relevantního obsahu z webových stránek. Tyto knihovny můžou pomoct procházet strukturu HTML, vybrat konkrétní prvky a extrahovat požadovaný text nebo atributy.
- obrázky a naskenované dokumenty: techniky optického rozpoznávání znaků (OCR) se obvykle vyžadují k extrakci textu z obrázků. Mezi oblíbené knihovny OCR patří opensourcové knihovny, jako jsou Tesseract nebo verze SaaS, jako je Amazon Textract, Azure AI Vision OCRa rozhraní GOOGLE Cloud Vision API.
Osvědčené postupy pro analýzu dat
Analýza zajišťuje, že data jsou čistá, strukturovaná a připravená pro generování vkládání a vyhledávání pomocí vektorů. Při analýze dat zvažte následující osvědčené postupy:
- čištění dat: předzpracuje extrahovaný text, aby se odebraly irelevantní nebo hlučné informace, jako jsou záhlaví, zápatí nebo speciální znaky. Snižte množství nepotřebných nebo poškozených informací, které váš řetězec RAG potřebuje zpracovat.
- Zpracování chyb a výjimek: Implementujte mechanismy zpracování chyb a protokolování pro identifikaci a řešení jakýchkoli problémů, ke kterým došlo během procesu analýzy. To vám pomůže rychle identifikovat a opravit problémy. To často odkazuje na nadřazené problémy s kvalitou zdrojových dat.
- Přizpůsobení logiky analýzy: V závislosti na struktuře a formátu dat možná budete muset přizpůsobit logiku analýzy, aby extrahovali nejrelevavantnější informace. I když to může vyžadovat počáteční úsilí navíc, investujte čas, pokud je to potřebné, protože to často předejde mnoha následným problémům s kvalitou.
- Vyhodnocení kvality analýzy: Pravidelně vyhodnocujte kvalitu analyzovaných dat ruční kontrolou vzorku výstupu. To vám může pomoct identifikovat všechny problémy nebo oblasti pro zlepšení procesu analýzy.
rozšiřování
Rozšiřte data o další metadata a odstraňte šum. I když je rozšiřování volitelné, může výrazně zlepšit celkový výkon vaší aplikace.
extrakce metadat
Generování a extrahování metadat, která zaznamenávají základní informace o obsahu, kontextu a struktuře dokumentu, může výrazně zlepšit kvalitu získávání informací a výkon aplikace RAG. Metadata poskytují další signály, které zlepšují relevanci, umožňují rozšířené filtrování a podporují požadavky na vyhledávání specifické pro doménu.
I když knihovny, jako je LangChain a LlamaIndex, poskytují integrované analyzátory schopné automaticky extrahovat přidružená standardní metadata, je často užitečné doplnit ho vlastními metadaty přizpůsobenými vašemu konkrétnímu případu použití. Tento přístup zajišťuje zachycení důležitých informací specifických pro doménu, zlepšení načítání a generování podřízených dat. K automatizaci vylepšení metadat můžete použít také velké jazykové modely (LLM).
Mezi typy metadat patří:
- metadat na úrovni dokumentu: název souboru, adresy URL, informace o autorovi, časová razítka vytváření a úpravy, souřadnic GPS a správa verzí dokumentů.
- metadata založená na obsahu: extrahovaná klíčová slova, souhrny, témata, pojmenované entity a značky specifické pro doménu (názvy produktů a kategorie, jako jsou PII nebo HIPAA).
- strukturální metadata: záhlaví oddílů, obsah, čísla stránek a sémantické hranice obsahu (kapitoly nebo pododdíly).
- kontextová metadata: Zdrojový systém, datum příjmu dat, úroveň citlivosti dat, původní jazyk nebo nadnárodní instrukce.
K zajištění optimálního výkonu je nezbytné ukládat metadata společně s rozdělenými dokumenty nebo jejich odpovídajícími embeddingy. Pomůže také zúžit načtené informace a zlepšit přesnost a škálovatelnost aplikace. Kromě toho integrace metadat do kanálů hybridního vyhledávání, což znamená kombinování hledání vektorové podobnosti s filtrováním na základě klíčových slov, může zvýšit význam, zejména ve velkých datových sadách nebo konkrétních scénářích kritérií hledání.
odstranění duplicitních dat
V závislosti na zdrojích můžete skončit s duplicitními dokumenty nebo téměř duplicitními položkami. Pokud například stáhnete z jednoho nebo více sdílených disků, může existovat více kopií stejného dokumentu na několika různých místech. Některé z těchto kopií můžou mít drobné úpravy. Podobně může mít vaše znalostní báze kopie dokumentace k produktu nebo koncepty blogových příspěvků. Pokud tyto duplicity zůstanou v korpusu, můžete v konečném indexu skončit s vysoce redundantními bloky dat, které můžou snížit výkon vaší aplikace.
Některé duplicity můžete odstranit pomocí samotných metadat. Pokud má například položka stejný název a datum vytvoření, ale více položek z různých zdrojů nebo umístění, můžete je filtrovat na základě metadat.
To ale nemusí stačit. K identifikaci a odstranění duplicit na základě obsahu dokumentů můžete použít techniku známou jako hashování citlivé na lokalitu. Konkrétně technika označovaná jako MinHash funguje dobře zde a implementace Sparku je již k dispozici v Spark ML. Funguje tak, že na základě slov obsažených v dokumentu vytvoří hash, a poté dokáže efektivně identifikovat duplicity nebo téměř duplicity porovnáním těchto hashů. Na velmi vysoké úrovni je to čtyřstupňový proces:
- Vytvořte vektor funkce pro každý dokument. V případě potřeby zvažte použití technik, jako je zastavení odebrání slova, zvolnění a lemmatizace, aby se zlepšily výsledky, a pak tokenizovat do n-gramů.
- Přizpůsobte model MinHash a následně hashujte vektory pomocí MinHash pro Jaccardovu vzdálenost.
- Pomocí těchto hodnot hash spusťte podobnostní spojení a vytvořte sadu výsledků pro každý duplicitní nebo téměř duplicitní dokument.
- Vyfiltrujte duplicity, které nechcete zachovat.
Krok základního odstranění duplicit může vybrat, které dokumenty se mají zachovat, náhodně (například první z výsledků každého duplikátu nebo náhodnou volbou mezi duplikáty). Potenciálním vylepšením by bylo vybrat "nejlepší" verzi duplikátu pomocí jiné logiky (například nejnovější aktualizace, stav publikace nebo nejautoritativní zdroj). Všimněte si také, že možná budete muset experimentovat s krokem featurizace a počtem hodnot hash tabulek použitých v modelu MinHash ke zlepšení odpovídajících výsledků.
Další informace najdete v dokumentaci Sparku pro hashování citlivé na lokalitu.
Filtrování
Některé dokumenty, které ingestujete do korpusu, nemusí být pro vašeho agenta užitečné, protože jsou pro jeho účel irelevantní, příliš staré nebo nespolehlivé, nebo protože obsahují problematický obsah, jako je škodlivý jazyk. Jiné dokumenty ale můžou obsahovat citlivé informace, které nechcete vystavit prostřednictvím agenta.
Proto zvažte zahrnutí kroku v kanálu k vyfiltrování těchto dokumentů pomocí jakýchkoli metadat, jako je použití klasifikátoru toxicity v dokumentu k vytvoření předpovědi, kterou můžete použít jako filtr. Dalším příkladem je použití algoritmu detekce osobních údajů (PII) u dokumentů k filtrování dokumentů.
A konečně, všechny zdroje dokumentů, které do agenta zasíláte, jsou potenciální vektory útoku pro škodlivé subjekty ke spuštění útoků otravy dat. Můžete také zvážit přidání mechanismů detekce a filtrování, které vám pomůžou tyto mechanismy identifikovat a odstranit.
Rozdělování do bloků
Po parsování nezpracovaných dat do strukturovanějšího formátu, odebrání duplicit a odfiltrování nežádoucích informací je dalším krokem rozdělení dat do menších jednotek, které se nazývají bloky dat. Segmentace velkých dokumentů do menších sémanticky soustředěných bloků zajišťuje, že načtená data se vejdou do kontextu LLM a minimalizují zahrnutí rušivých nebo irelevantních informací. Volby provedené při vytváření bloků dat přímo ovlivní načtená data, která LLM poskytuje, takže se jedná o jednu z prvních vrstev optimalizace v aplikaci RAG.
Při vytváření bloků dat zvažte následující faktory:
- Strategie vytváření bloků dat: Metoda, kterou použijete k rozdělení původního textu na bloky dat. To může zahrnovat základní techniky, jako je rozdělení podle vět, odstavců, konkrétních počtu znaků/tokenů a pokročilejších strategií rozdělení specifických pro dokument.
- velikost bloku dat: Menší bloky dat se mohou zaměřit na konkrétní podrobnosti, ale ztratit některé kontextové informace. Větší bloky dat můžou zachytit více kontextu, ale můžou obsahovat irelevantní informace nebo být výpočetně nákladné.
- Překrytí mezi bloky: Abyste zajistili, že při rozdělení dat do bloků nedojde ke ztrátě důležitých informací, zvažte zahrnutí překrývajících se částí mezi sousedními bloky. Překrývající se objekty můžou zajistit zachování kontinuity a kontextu napříč bloky dat a zlepšit výsledky načítání.
- sémantické soudržnosti: Pokud je to možné, snažte se vytvořit sémanticky koherentní bloky, které obsahují související informace, ale mohou být nezávislé jako smysluplná jednotka textu. Toho lze dosáhnout zvážením struktury původních dat, jako jsou odstavce, oddíly nebo hranice tématu.
- Metadata:relevantní metadata, jako je název zdrojového dokumentu, nadpis oddílu nebo názvy produktů, může zlepšit načítání. Tyto další informace mohou pomoci při přiřazování dotazů k segmentům dat.
Strategie vytváření bloků dat
Nalezení správné metody bloků dat je iterativní i kontextově závislé. Neexistuje univerzální přístup pro všechny situace. Optimální velikost a metoda bloků dat závisí na konkrétním případu použití a povaze zpracovávaných dat. Obecně platí, že strategie vytváření bloků dat se dají zobrazit takto:
- Bloky s pevnou velikostí: Rozdělte text na bloky předem určené velikosti, například pevný počet znaků nebo tokenů (například LangChain CharacterTextSplitter). Rozdělení libovolným počtem znaků/tokenů je rychlé a snadno se nastavuje, ale obvykle nebude mít za následek konzistentní sémanticky koherentní bloky dat. Tento přístup zřídka funguje pro aplikace na úrovni produkce.
- Bloky dat založené na odstavcích: K definování bloků dat použijte přirozené hranice odstavce v textu. Tato metoda může pomoct zachovat sémantickou soudržnost bloků dat, protože odstavce často obsahují související informace (například LangChain RecursiveCharacterTextSplitter).
- Zpracování bloků specifické pro formát: Formáty, jako je Markdown nebo HTML, mají inherentní strukturu, která může definovat hranice bloků (například záhlaví Markdownu). K tomuto účelu lze použít nástroje, jako je LangChainův MarkdownHeaderTextSplitter nebo děliče založené na hlavičkách/sekcí HTML.
- Sémantické členění textu: Techniky, jako je modelování témat, lze použít k identifikaci sémanticky soudržných částí v textu. Tyto přístupy analyzují obsah nebo strukturu každého dokumentu a určují nejvhodnější hranice bloků dat na základě posunů témat. I když je sémantické vytváření bloků složitější než základní přístupy, může pomoci vytvořit bloky, které jsou v souladu s přirozenými sémantickými děleními v textu (viz například LangChain SemanticChunker).
Příklad: Chunking s pevnou velikostí
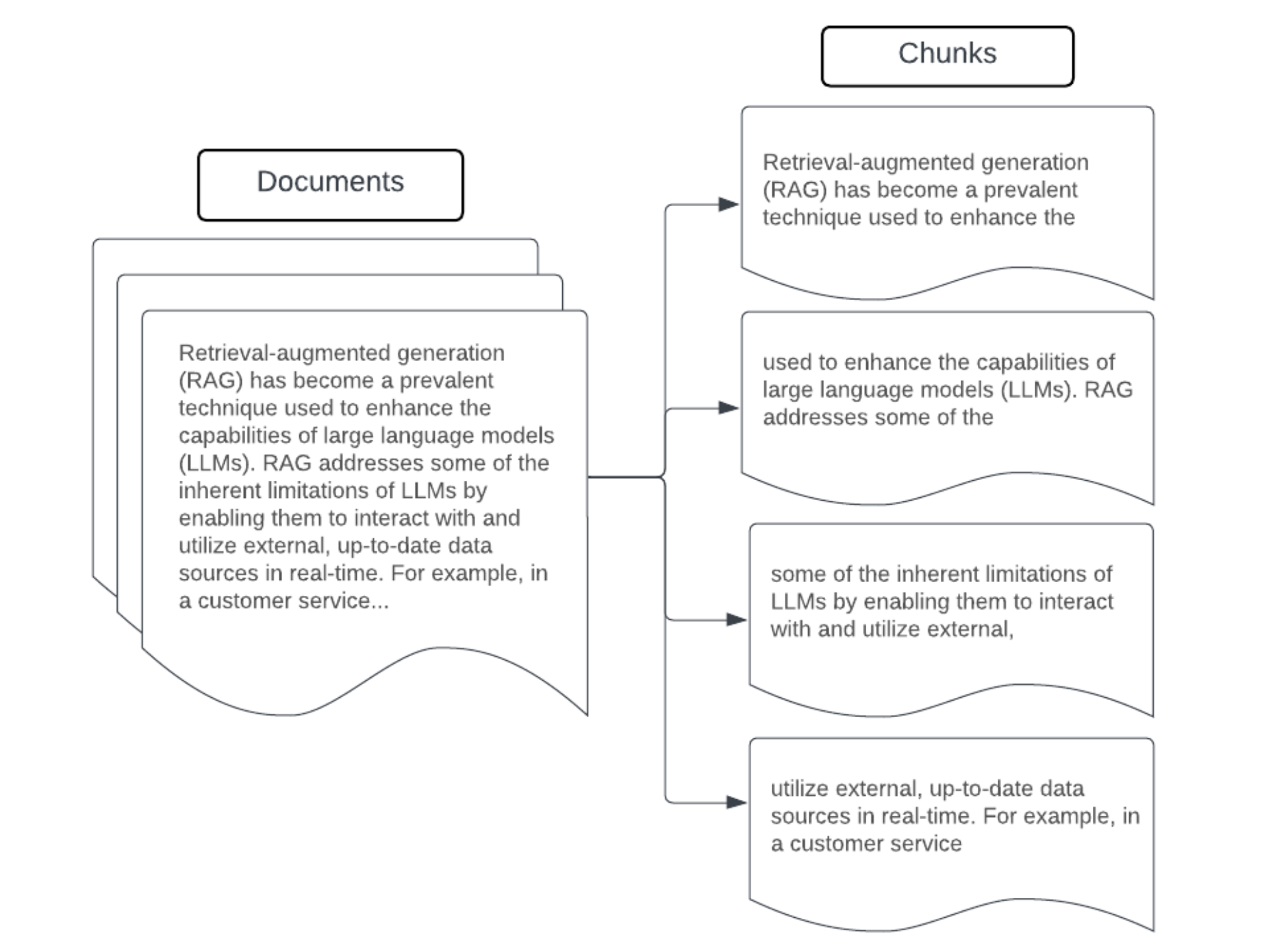
Příklad blokování s pevnou velikostí pomocí Rekurzivního textuCharacterTextSplitter jazyka LangChain s chunk_size=100 a chunk_overlap=20. ChunkViz poskytuje interaktivní způsob, jak vizualizovat, jak různé velikosti úseků a hodnoty překrytí úseků pomocí rozdělovačů znaků Langchain ovlivňují výsledné úseky.
vkládání
Po vytvoření bloku dat je dalším krokem převod textových bloků na vektorové znázornění pomocí vloženého modelu. Vložený model převede každý textový blok na vektorovou reprezentaci, která zachycuje jeho sémantický význam. Díky reprezentaci bloků dat jako hustých vektorů umožňují vkládání rychlé a přesné načítání nejrelevavantnějších bloků dat na základě jejich sémantické podobnosti s dotazem na načtení. Dotaz načítání se transformuje v době dotazu pomocí stejného modelu vkládání, který se používá k vložení bloků dat do datového kanálu.
Při výběru modelu vkládání zvažte následující faktory:
- Volba modelu: Každý vložený model má drobné odlišnosti a dostupné srovnávací testy nemusí zachytit konkrétní charakteristiky vašich dat. Je důležité vybrat model, který byl natrénován na podobných datech. Může být také užitečné prozkoumat všechny dostupné modely vkládání, které jsou navržené pro konkrétní úlohy. Experimentujte s různými předpřipravenými modely pro vkládání, a to i s těmi, které můžou být méně hodnocené na standardních žebříčcích, jako je MTEB. Příklady, které je potřeba vzít v úvahu:
- maximální počet tokenů: Znát maximální limit tokenů pro vybraný model vkládání. Pokud předáte bloky, které tento limit překročí, dojde ke zkrácení, což může vést ke ztrátě důležitých informací. Například bge-large-en-v1.5 má maximální limit tokenu 512.
- velikost modelu : větší modely vkládání obecně fungují lépe, ale vyžadují více výpočetních prostředků. Na základě vašeho konkrétního případu použití a dostupných prostředků budete muset vyvážit výkon a efektivitu.
- jemné ladění: Pokud vaše aplikace RAG pracuje s jazykem specifickým pro doménu (jako jsou interní zkratky nebo terminologie společnosti), zvažte vyladění modelu vkládání na data specifická pro doménu. To může pomoci modelu lépe zachytit nuance a terminologii vaší konkrétní domény a často může vést k lepšímu výkonu načítání.
indexování a úložiště
Dalším krokem v procesu je vytvoření indexů na vytváraných reprezentací a metadatech generovaných v předchozích krocích. Tato fáze zahrnuje uspořádání vysocerozměrných vektorových vkládání do efektivních datových struktur, které umožňují rychlé a přesné vyhledávání podobnosti.
Mosaic AI Vector Search používá nejnovější techniky indexování, když nasadíte koncový bod a index vektorového vyhledávání, aby bylo zajištěno rychlé a efektivní hledání pro vaše dotazy. Nemusíte se starat o testování a volbu nejlepších technik indexování.
Jakmile se index sestaví a nasadí, je připravený se uložit do systému, který podporuje škálovatelné dotazy s nízkou latencí. Pro produkční kanály RAG s velkými datovými sadami použijte vektorovou databázi nebo škálovatelnou vyhledávací službu k zajištění nízké latence a vysoké propustnosti. Uložte další metadata spolu s vkládáním, abyste během načítání umožnili efektivní filtrování.