Posouzení výkonu: Metriky, které jsou důležité
Tento článek popisuje měření výkonu aplikace RAG pro kvalitu načítání, odezvy a výkonu systému.
Načítání, odezva a výkon
Pomocí sady vyhodnocení můžete měřit výkon aplikace RAG v řadě různých dimenzí, mezi které patří:
- Kvalita načítání: Metriky načítání vyhodnocují, jak úspěšně vaše aplikace RAG načte relevantní podpůrná data. Přesnost a úplnost jsou dvě klíčové metriky načítání.
- Kvalita odpovědi: Metriky kvality odpovědí vyhodnocují, jak dobře aplikace RAG reaguje na žádost uživatele. Metriky odpovědí můžou například měřit, pokud je výsledná odpověď přesná podle základní pravdy, jak dobře uzemněná byla odpověď udělena načteným kontextem (například halucinát LLM?) nebo jak bezpečná byla odpověď (jinými slovy, žádná toxicita).
- Výkon systému (náklady a latence): Metriky zaznamenávají celkové náklady a výkon aplikací RAG. Celková latence a spotřeba tokenů jsou příklady řetězových metrik výkonu.
Je velmi důležité shromáždit metriky odpovědi i načítání. Aplikace RAG může reagovat špatně, i když načítá správný kontext; může také poskytovat dobré odpovědi na základě chybných načítání. Pouze měřením obou komponent můžeme přesně diagnostikovat a řešit problémy v aplikaci.
Přístupy k měření výkonu
Existují dva klíčové přístupy k měření výkonu napříč těmito metrikami:
- Deterministické měření: Metriky nákladů a latence se dají vypočítat deterministicky na základě výstupů aplikace. Pokud vaše testovací sada obsahuje seznam dokumentů, které obsahují odpověď na otázku, je možné deterministicky vypočítat také podmnožinu metrik načítání.
- Měření na základě soudce LLM: V tomto přístupu samostatný LLM funguje jako soudce , který vyhodnocuje kvalitu načítání a odpovědí aplikace RAG. Někteří porotci LLM, jako je správnost odpovědí, porovnávají lidské základní pravdy a výstupy aplikace. Jiní porotci LLM, jako je uzemnění, nevyžadují, aby lidé označili základní pravdu k posouzení výstupů aplikace.
Důležité
Aby byl soudce LLM účinný, musí být vyladěn, aby porozuměl případu použití. To vyžaduje pečlivou pozornost, abyste pochopili, kde soudce funguje dobře a kde ne, a poté upravili jeho činnost pro zlepšení v případech selhání.
Hodnocení agenta pro architekturu AI s využitím hostovaných modelů posouzení LLM poskytuje připravenou implementaci pro každou metriku probíranou na této stránce. Dokumentace k vyhodnocení agenta popisuje podrobnosti o tom, jak se tyto metriky a porotci implementují, a poskytuje možnosti ladění porotců s vašimi daty za účelem zvýšení jejich přesnosti.
Přehled metrik
Níže je souhrn metrik, které Databricks doporučuje pro měření kvality, nákladů a latence vaší aplikace RAG. Tyto metriky jsou implementovány ve vyhodnocení agenta systému Mosaic AI.
| Dimenze | Název metriky | Otázka | Měřeno podle | Potřebuje základní pravdu? |
|---|---|---|---|---|
| Načtení | chunk_relevance/přesnost | Jaké procento načtených bloků dat je pro požadavek relevantní? | Soudce LLM | No |
| Načtení | document_recall | Jaké % podkladových dokumentů pravdy jsou reprezentovány v načtených blocích? | Deterministický | Ano |
| Načtení | dostatečnost kontextu | Jsou načtené bloky dat dostatek k získání očekávané odpovědi? | soudce LLM | Ano |
| Response | korektnost | Celkově, vygeneroval agent správnou odpověď? | Soudce LLM | Ano |
| Response | relevance_to_query | Je odpověď relevantní pro požadavek? | Soudce LLM | No |
| Response | uzemnění | Je odpověď halucinace nebo uzemněná v kontextu? | Soudce LLM | No |
| Response | bezpečnost | Je v odpovědi škodlivý obsah? | Soudce LLM | No |
| Náklady | total_token_count, total_input_token_count, total_output_token_count | Jaký je celkový počet tokenů pro generace LLM? | Deterministický | No |
| Latence | latency_seconds | Jaká je latence spuštění aplikace? | Deterministický | No |
Jak fungují metriky načítání
Metriky načítání vám pomůžou pochopit, jestli váš retriever doručuje relevantní výsledky. Metriky načítání jsou založené na přesnosti a úplnosti.
| Název metriky | Odpověď na otázku | Detaily |
|---|---|---|
| Počet deset. míst | Jaké procento načtených bloků dat je pro požadavek relevantní? | Přesnost je poměr načtených dokumentů, které jsou skutečně relevantní pro požadavek uživatele. K posouzení relevance každého načteného bloku dat na žádost uživatele je možné použít soudce LLM. |
| Odvolat | Jaké % podkladových dokumentů pravdy jsou reprezentovány v načtených blocích? | Připomínáme, že podíl podkladových dokumentů pravdy, které jsou reprezentovány v načtených blocích. Toto je míra úplnosti výsledků. |
Přesnost a úplnost
Níže je rychlý úvod k přesnosti a úplnosti přizpůsoben z vynikajícího článku Wikipedie.
Vzorec přesnosti
Přesnost měří "Z načtených bloků dat, jaké procento těchto položek je skutečně relevantní pro dotaz uživatele?". Přesnost výpočtů nevyžaduje znalost všech relevantních položek.
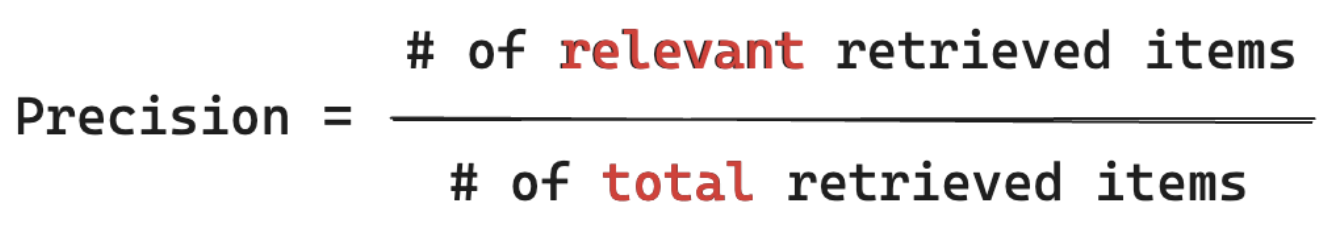
Vzorec pro odvolání
Vzpomeňte si, že všechny dokumenty, které vím, jsou relevantní pro dotaz uživatele, jaké % jsem načetl blok dat? Výpočetní úplnost vyžaduje, aby vaše základní pravda obsahovala všechny relevantní položky. Položky můžou být buď dokument, nebo blok dokumentu.
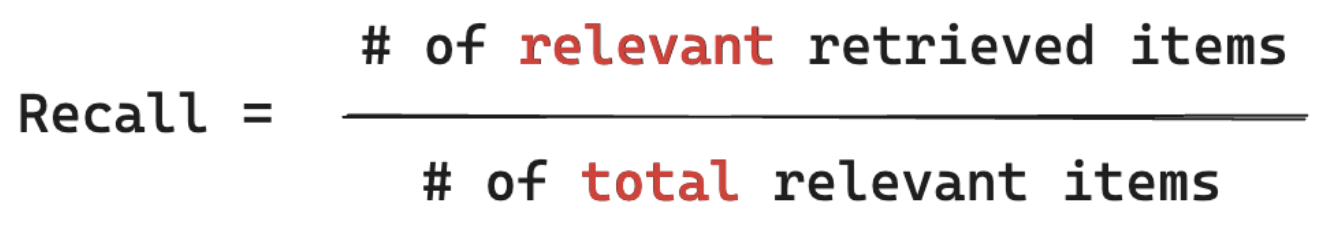
V následujícím příkladu byly dva ze tří načtených výsledků relevantní pro dotaz uživatele, takže přesnost byla 0,66 (2/3). Načtené dokumenty obsahovaly dva z celkem čtyř relevantních dokumentů, takže odvolání bylo 0,5 (2/4).