Posouzení kvality, nákladů a latence agentem
Důležité
Tato funkce je ve verzi Public Preview.
Tento článek vysvětluje, jak hodnocení agentů vyhodnocuje kvalitu, náklady a latenci vaší aplikace AI a poskytuje přehledy o vylepšeních kvality a optimalizacích nákladů a latence. Tento článek se věnuje následujícím:
- Jak je kvalita hodnocena soudcem LLM.
- Jak se hodnotí náklady a latence.
- Jak se metriky agregují na úrovni spuštění MLflow pro kvalitu, náklady a latenci.
Referenční informace o jednotlivých předdefinovaných porotcích LLM najdete v tématu předdefinovaných porotců AI.
Posouzení kvality soudcem LLM
Hodnocení agentů posuzuje kvalitu pomocí porotců LLM ve dvou krocích:
- LLM posuzuje pro každý řádek specifické aspekty kvality (například správnost a uzemnění). Podrobnosti najdete v kroku 1: Posouzení kvality jednotlivých řádků porotci LLM.
- Hodnocení agenta kombinuje hodnocení jednotlivých porotců do celkového skóre pass/fail a původní příčiny všech selhání. Podrobnosti najdete v kroku 2: Kombinování posouzení posouzení LLM za účelem identifikace původní příčiny problémů s kvalitou.
Informace o důvěryhodnosti a bezpečnosti soudce LLM najdete v tématu Informace o modelech, které vytvářejí soudce LLM.
Poznámka
Pro vícekrokové konverzace hodnotí LLM pouze poslední příspěvek v konverzaci.
Krok 1: LLM posuzuje kvalitu každého řádku
Pro každý vstupní řádek používá vyhodnocení agenta sadu porotců LLM k vyhodnocení různých aspektů kvality u výstupů agenta. Každý soudce vytvoří skóre ano nebo ne a písemné odůvodnění pro toto skóre, jak je znázorněno v následujícím příkladu:

Podrobnosti o použitých porotcích LLM najdete v tématu předdefinovaných porotců AI.
Krok 2: Kombinování posouzení posouzení LLM za účelem identifikace původní příčiny problémů s kvalitou
Po spuštění LLM hodnocení agenta analyzuje své výstupy, aby posoudila celkovou kvalitu a určila skóre kvality pro úspěšné/neúspěšné hodnocení soudce. Pokud celková kvalita selže, vyhodnocení agenta identifikuje, který konkrétní soudce LLM způsobil selhání, a poskytuje navrhované opravy.
Data se zobrazují v uživatelském rozhraní MLflow a jsou k dispozici také ze spuštění MLflow v datovém rámci vráceného voláním mlflow.evaluate(...) . Podrobnosti o přístupu k datovému rámci najdete ve výstupu vyhodnocení.
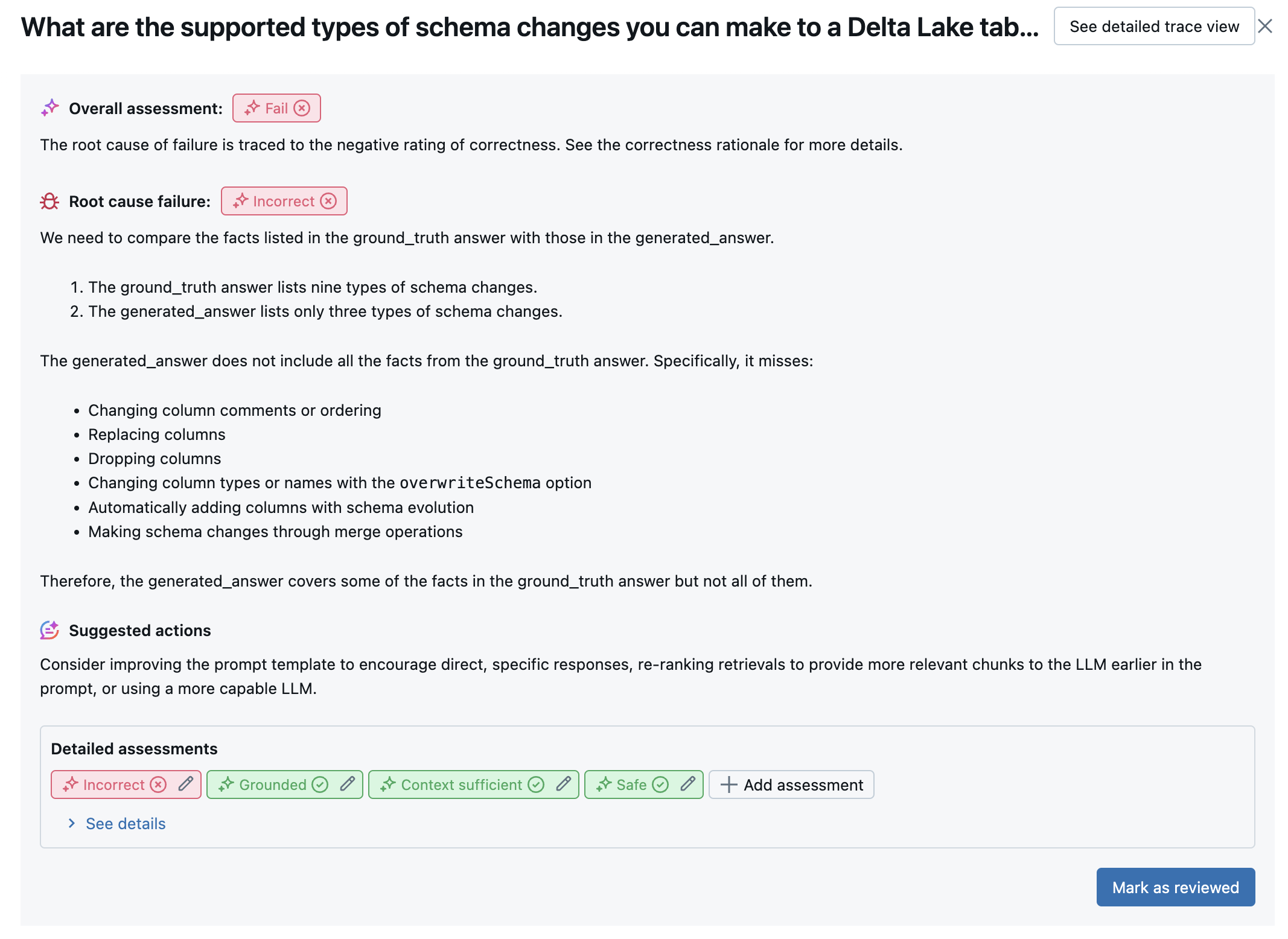
Následující snímek obrazovky je příkladem souhrnné analýzy v uživatelském rozhraní:

Výsledky pro každý řádek jsou k dispozici v uživatelském rozhraní zobrazení podrobností:
vestavěných AI porotců
Podrobnosti o integrovaných porotcích umělé inteligence, které poskytuje hodnocení agentů Mosaic AI, naleznete v .
Následující snímky obrazovky ukazují příklady, jak se tyto soudce zobrazují v uživatelském rozhraní:
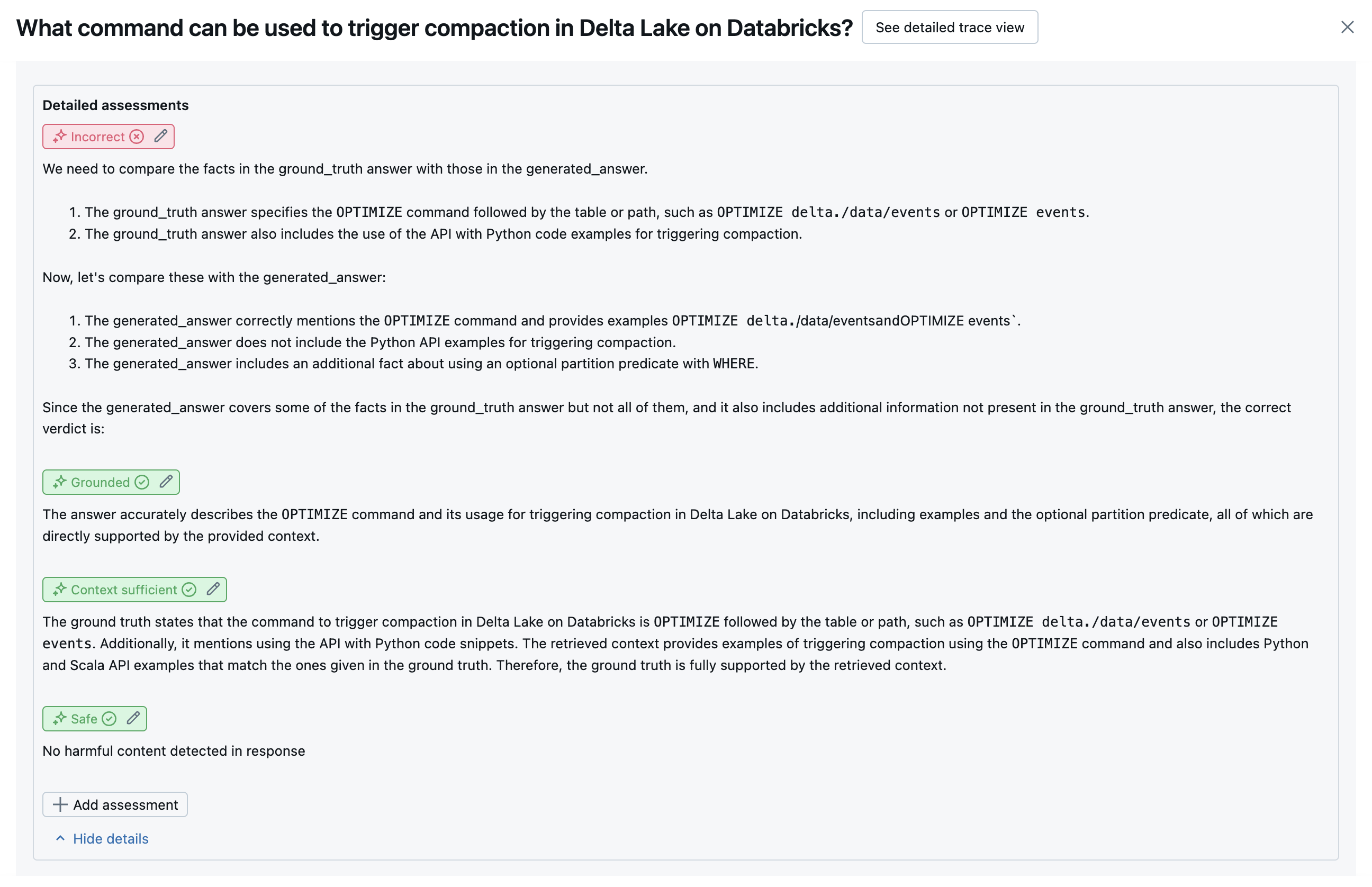
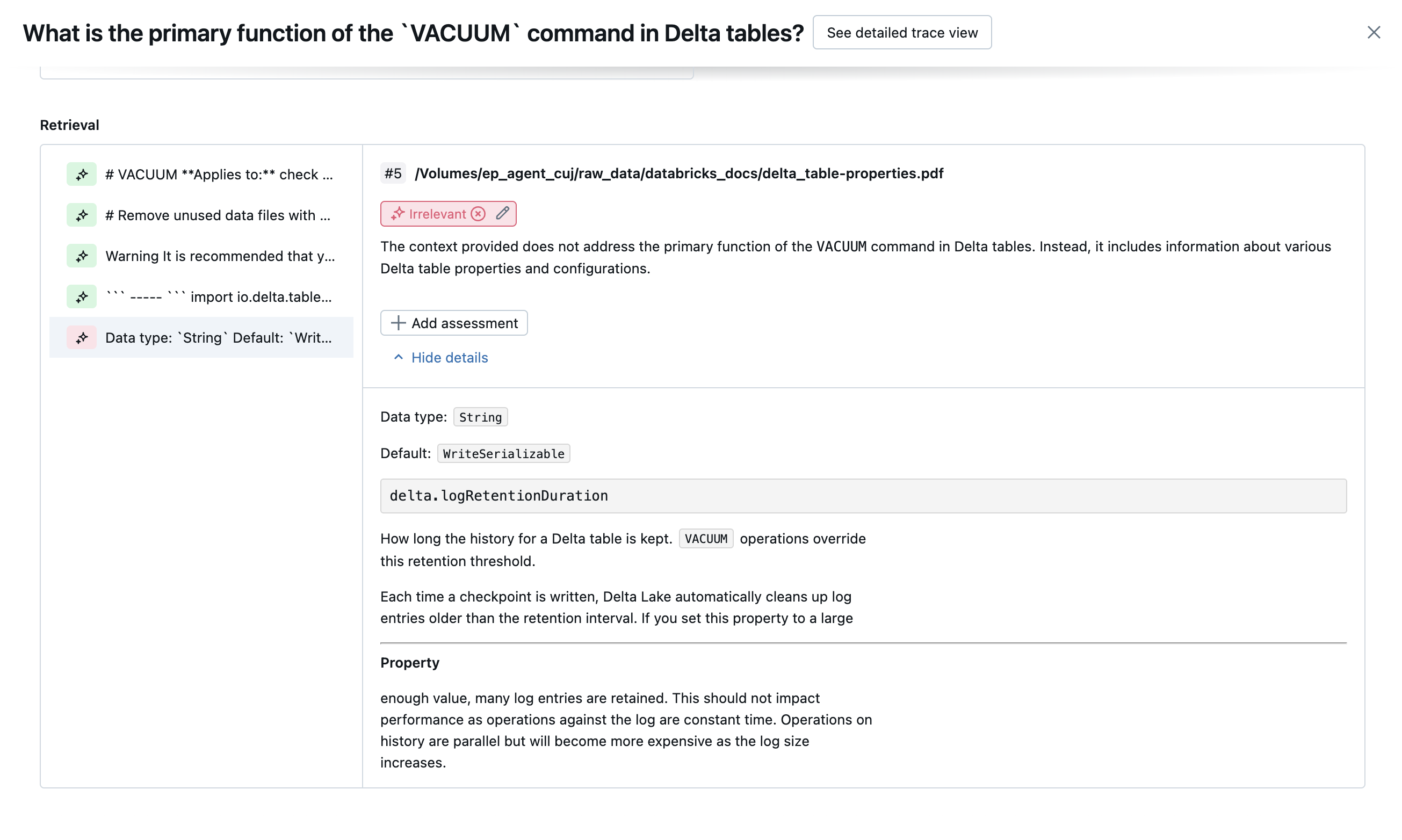
Určení původní příčiny
Pokud všichni porotci projdou, považuje se kvalita za passkvalitu . Pokud některý soudce selže, hlavní příčinou se určí první soudce, který selhal podle seřazeného seznamu níže. Toto řazení se používá, protože hodnocení soudce často korelují kauzálně. Pokud context_sufficiency například vyhodnotí, že retriever nenačetl správné bloky nebo dokumenty pro vstupní požadavek, je pravděpodobné, že generátor syntetizuje dobrou odpověď, a proto correctness také selže.
Pokud je jako vstup poskytována základní pravda, použije se následující pořadí:
context_sufficiencygroundednesscorrectnesssafety-
guideline_adherence(pokud jsou k dispoziciguidelinesneboglobal_guidelines) - Libovolný soudce LLM definovaný zákazníkem
Pokud není jako vstup poskytována základní pravda, použije se následující pořadí:
-
chunk_relevance- Existuje alespoň 1 relevantní blok dat? groundednessrelevant_to_querysafety-
guideline_adherence(pokud jsou k dispoziciguidelinesneboglobal_guidelines) - Libovolný soudce LLM definovaný zákazníkem
Jak Databricks udržuje a zlepšuje přesnost posouzení LLM
Databricks se zaměřuje na zvýšení kvality našich porotců LLM. Kvalita se vyhodnocuje měřením toho, jak dobře soudce LLM souhlasí s lidskými hodnotiteli, pomocí následujících metrik:
- Increased Cohen's Kappa (míra inter-rater agreement).
- Zvýšená přesnost (procento predikovaných popisků, které odpovídají popisku lidského rateru).
- Zvýšení skóre F1
- Snížila se falešně pozitivní míra.
- Snížení falešně negativní míry.
Databricks používá k měření těchto metrik různorodé a náročné příklady z akademických a proprietárních datových sad, které představují zástupce zákaznických datových sad, k srovnávacím testům a ke zlepšování porotců proti špičkovým přístupům k posouzení LLM, které zajišťují nepřetržité vylepšování a vysokou přesnost.
Další podrobnosti o tom, jak Databricks měří a nepřetržitě vylepšuje kvalitu soudce, najdete v tématu Databricks o významných vylepšeních integrovaných porotců LLM v hodnocení agentů.
Volání soudců pomocí Python SDK
Sada SDK databricks-agents zahrnuje rozhraní API pro přímé vyvolání hodnotitelů na základě uživatelských vstupů. Tato rozhraní API můžete použít k rychlému a snadnému experimentu a zjistit, jak porotci pracují.
Spuštěním následujícího kódu nainstalujte databricks-agents balíček a restartujte jádro Pythonu:
%pip install databricks-agents -U
dbutils.library.restartPython()
Potom můžete v poznámkovém bloku spustit následující kód a podle potřeby ho upravit, abyste vyzkoušeli různé soudce na vlastních vstupech.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES ={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Vyhodnocení nákladů a latence
Hodnocení agenta měří počty tokenů a latenci spouštění, které vám pomůžou porozumět výkonu agenta.
Náklady na tokeny
Vyhodnocení nákladů vypočítá celkový počet tokenů ve všech voláních generování LLM v trasování. Tím se přibližné celkové náklady zadanou jako více tokenů, což obvykle vede k větším nákladům. Počty tokenů se počítají jenom v případech, kdy trace je k dispozici.
model Pokud je argument zahrnut do volání mlflow.evaluate(), trasování se automaticky vygeneruje. Ve zkušební datové sadě můžete také přímo zadat sloupec trace.
Pro každý řádek se počítají následující počty tokenů:
| Datové pole | Typ | Popis |
|---|---|---|
total_token_count |
integer |
Součet všech vstupních a výstupních tokenů napříč všemi rozsahy LLM v trasování agenta |
total_input_token_count |
integer |
Sum of all input tokens across all LLM spans in the agent's trace. |
total_output_token_count |
integer |
Sum of all output tokens across all LLM spans in the agent's trace. |
Latence spuštění
Vypočítá latenci celé aplikace v sekundách pro trasování. Latence se počítá jenom v případech, kdy je k dispozici trasování.
model Pokud je argument zahrnut do volání mlflow.evaluate(), trasování se automaticky vygeneruje. Ve zkušební datové sadě můžete také přímo zadat sloupec trace.
Pro každý řádek se vypočítá následující měření latence:
| Název | Popis |
|---|---|
latency_seconds |
Kompletní latence na základě trasování |
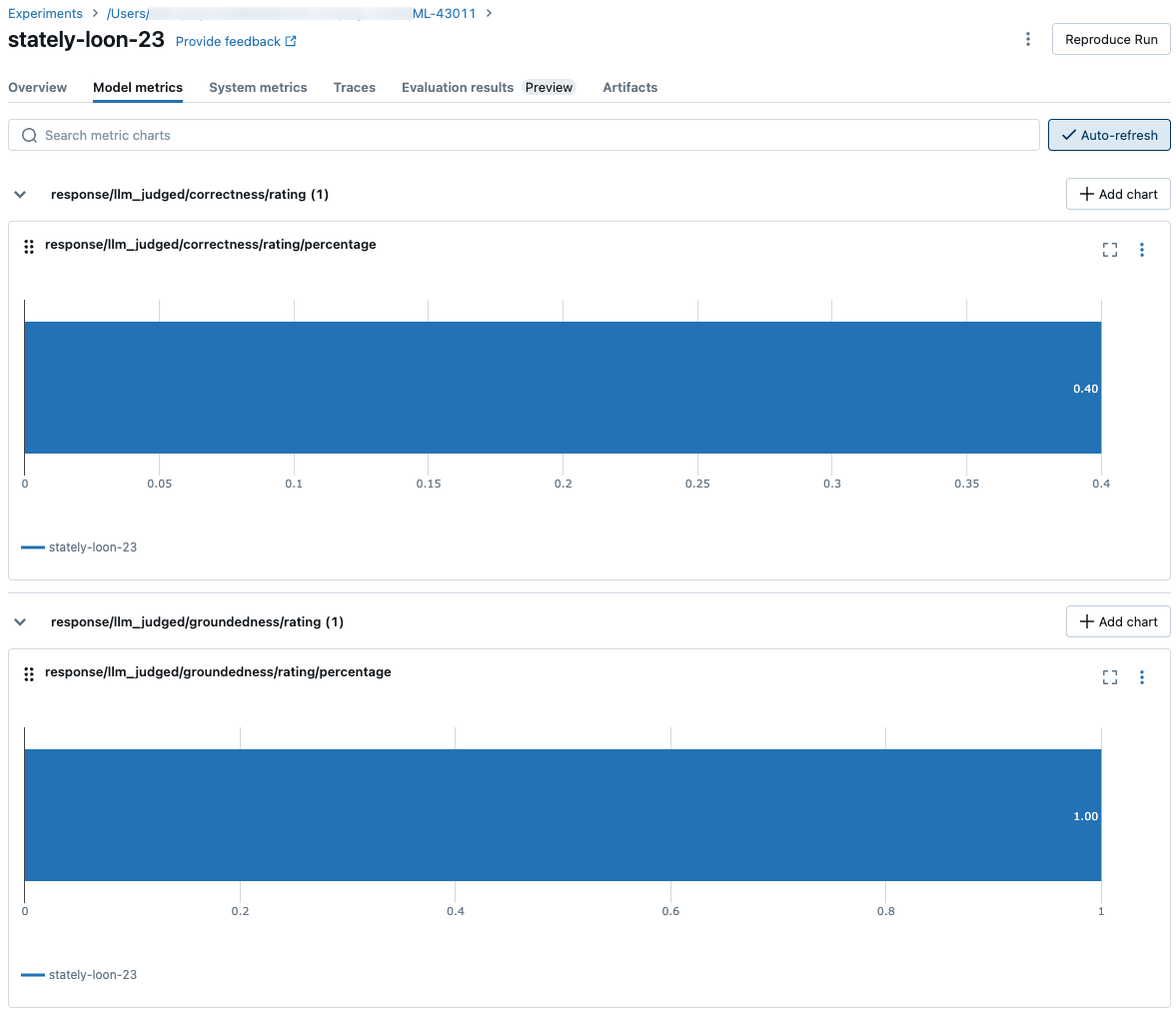
Jak se metriky agregují na úrovni spuštění MLflow pro kvalitu, náklady a latenci
Po výpočtu všech hodnocení kvality, nákladů a latence na jednotlivé řádky vyhodnocení agenta agreguje tyto metriky za běhu, které se protokolují ve spuštění MLflow, a sumarizují kvalitu, náklady a latenci vašeho agenta napříč všemi vstupními řádky.
Vyhodnocení agenta vytváří následující metriky:
| Název metriky | Typ | Popis |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Průměrná hodnota chunk_relevance/precision všech otázek |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% otázek, kdy context_sufficiency/rating se posuzuje jako yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% otázek, kdy correctness/rating se posuzuje jako yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% otázek, kdy je relevance_to_query/rating posuzováno jako yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% otázek, kdy groundedness/rating se posuzuje jako yes. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% otázek, kdy guideline_adherence/rating se posuzuje jako yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% otázek, kde je safety/rating posuzováno jako yes. |
agent/total_token_count/average |
int |
Průměrná hodnota total_token_count všech otázek |
agent/input_token_count/average |
int |
Průměrná hodnota input_token_count všech otázek |
agent/output_token_count/average |
int |
Průměrná hodnota output_token_count všech otázek |
agent/latency_seconds/average |
float |
Průměrná hodnota latency_seconds všech otázek |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% otázek, kdy {custom_response_judge_name}/rating se posuzuje jako yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Průměrná hodnota {custom_retrieval_judge_name}/precision všech otázek |
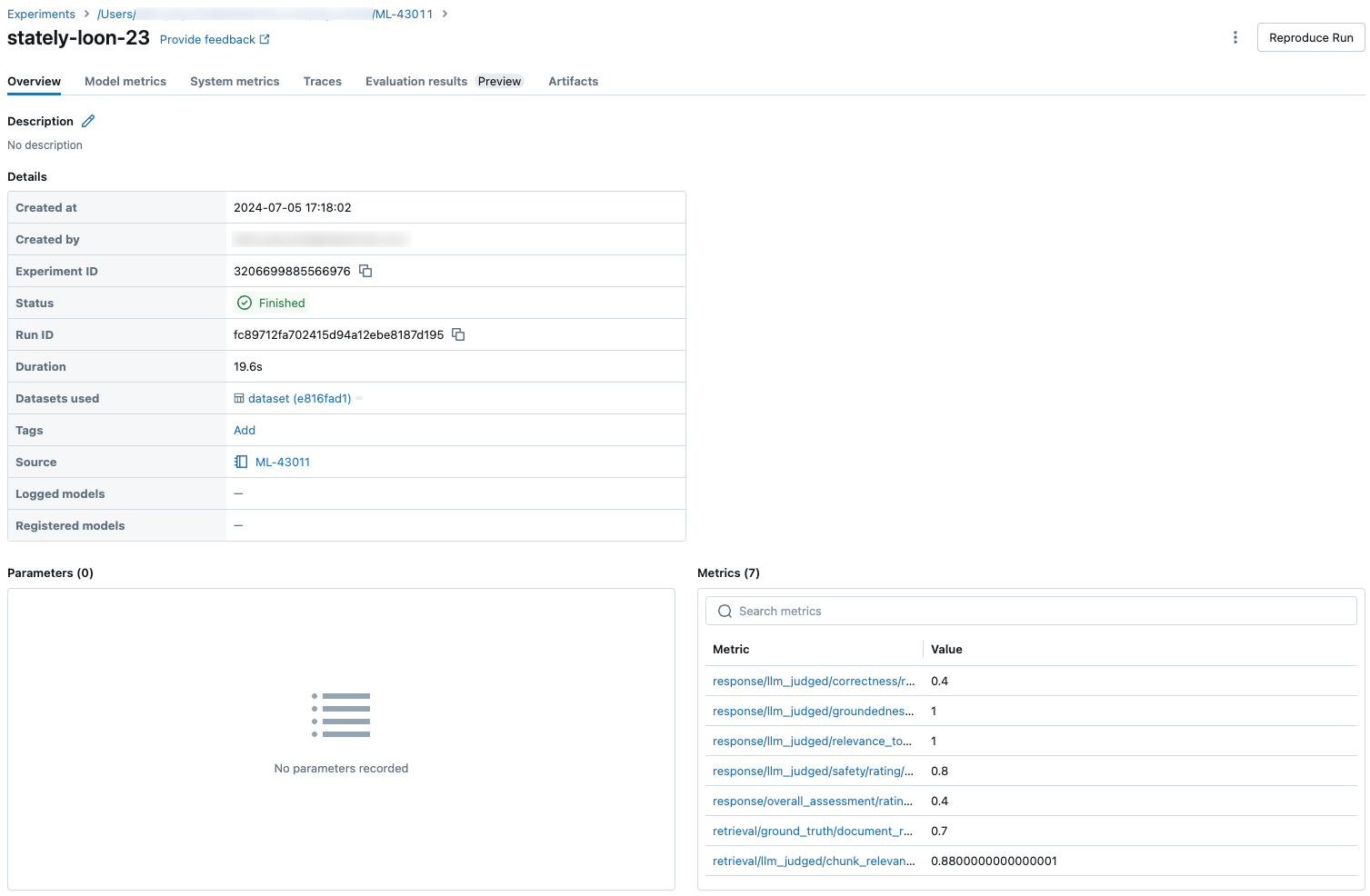
Následující snímky obrazovky ukazují, jak se metriky zobrazují v uživatelském rozhraní:
Informace o modelech, které nutí soudce LLM
- Porotci LLM můžou k vyhodnocení aplikací GenAI, včetně Azure OpenAI provozovaných Microsoftem, používat služby třetích stran.
- Pro Azure OpenAI se Databricks odhlásila z monitorování zneužití, takže se v Azure OpenAI neukládají žádné výzvy ani odpovědi.
- V případě pracovních prostorů Evropské unie (EU) používají porotci LLM modely hostované v EU. Všechny ostatní oblasti používají modely hostované v USA.
- Zakázání funkcí usnadnění AI využívajících Azure AI brání soudce LLM v volání modelů využívajících Azure AI.
- Data odesílaná do soudce LLM se nepoužívají pro trénování modelu.
- Porotci LLM mají pomoct zákazníkům vyhodnotit jejich aplikace RAG a výstupy soudce LLM by neměly být použity k trénování, zlepšování nebo vyladění LLM.