RAG (generování s podporou vyhledávání) v Azure Databricks
Agent Framework se skládá ze sady nástrojů v Databricks, které jsou navrženy tak, aby vývojářům pomohly sestavovat, nasazovat a vyhodnocovat agenty umělé inteligence produkční kvality, jako jsou RAG aplikace (Retrieval Augmented Generation).
Tento článek popisuje, co je RAG a jaké jsou výhody vývoje aplikací RAG v Azure Databricks.
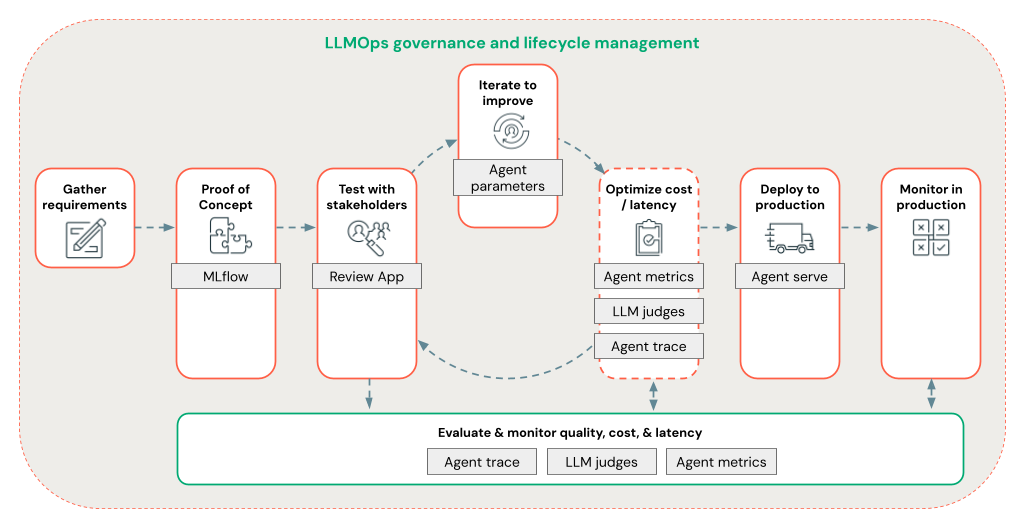
Agent Framework umožňuje vývojářům rychle iterovat všechny aspekty vývoje RAG pomocí kompletního pracovního postupu LLMOps.
Požadavky
- Pro váš pracovní prostor musí být povolené asistivní funkce AI využívající Azure AI.
- Všechny komponenty aplikace agentů musí být v jednom pracovním prostoru. Například v případě aplikace RAG musí být obslužný model a instance vektorového vyhledávání ve stejném pracovním prostoru.
Co je RAG?
RAG je metoda návrhu generující AI, která vylepšuje rozsáhlé jazykové modely (LLM) s externími znalostmi. Tato technika zlepšuje LLM následujícími způsoby:
- Proprietární znalosti: RAG může obsahovat proprietární informace, které se zpočátku nepoužívají k trénování LLM, jako jsou memo, e-maily a dokumenty pro zodpovězení otázek specifických pro doménu.
- Aktuální informace: Aplikace RAG může poskytnout LLM s informacemi z aktualizovaných zdrojů dat.
- Citace zdrojů: RAG umožňuje LLM citovat konkrétní zdroje, což uživatelům umožňuje ověřit faktickou přesnost odpovědí.
- seznamy zabezpečení dat a řízení přístupu (ACL): Krok načítání lze navrhnout tak, aby selektivně načítal osobní nebo proprietární informace na základě přihlašovacích údajů uživatele.
Složené systémy AI
Aplikace RAG je příkladem složeného systému AI: rozšiřuje možnosti jazyka LLM tím, že ho zkombinuje s dalšími nástroji a postupy.
V nejjednodušší podobě aplikace RAG provede následující:
- Načtení: Požadavek uživatele se používá k dotazování mimo úložiště dat, jako je úložiště vektorů, vyhledávání textových klíčových slov nebo databáze SQL. Cílem je získat podpůrná data pro odpověď LLM.
- Rozšíření: Načtená data se kombinují s požadavkem uživatele, často pomocí šablony s dalšími formátováními a pokyny k vytvoření výzvy.
- Generování: Výzva se předá LLM, která pak vygeneruje odpověď na dotaz.
Nestrukturovaná a strukturovaná data RAG
Architektura RAG může pracovat s nestrukturovanými nebo strukturovanými podpůrnými daty. Data, která používáte s RAG, závisí na vašem případu použití.
Nestrukturovaná data: Data bez konkrétní struktury nebo organizace Dokumenty, které obsahují text a obrázky nebo multimediální obsah, například zvuk nebo videa.
- Soubory PDF
- Dokumenty Google nebo Office
- wiki
- Obrázky
- Videa
strukturovaná data: tabulková data uspořádaná do řádků a sloupců s určitým schématem, jako jsou tabulky v databázi.
- Záznamy zákazníků v systému BI nebo datového skladu
- Transakční data z databáze SQL
- Data z rozhraní API aplikací (např. SAP, Salesforce atd.)
Následující části popisují aplikaci RAG pro nestrukturovaná data.
Datový kanál RAG
Datový kanál RAG předzpracovává a indexuje dokumenty pro rychlé a přesné vyhledávání.
Následující diagram znázorňuje ukázkový datový kanál pro nestrukturovanou datovou sadu pomocí sémantického vyhledávacího algoritmu. Úlohy v Databricks orchestruji každý krok.
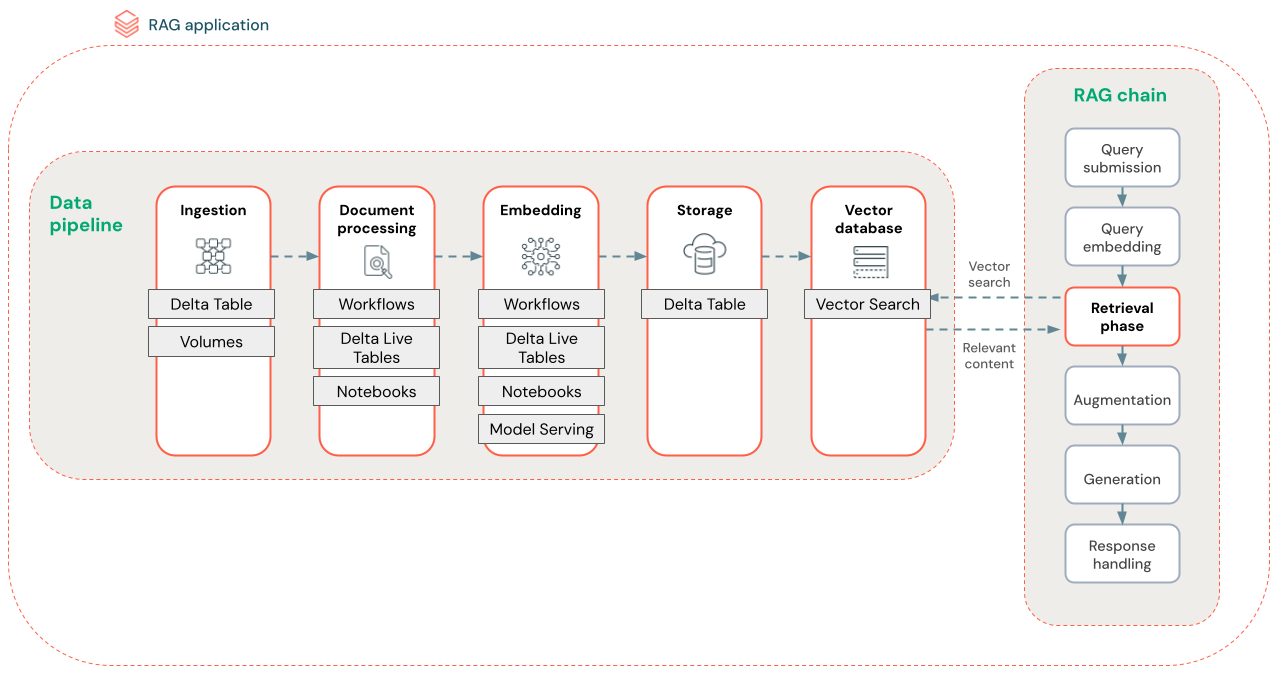
- Příjem dat – Ingestování dat z vašeho vlastního zdroje Tato data můžete uložit do tabulky Delta nebo svazku katalogu Unity.
-
zpracování dokumentů: Tyto úlohy můžete provádět pomocí úloh Databricks, poznámkových bloků Databricks a DLT.
- Parsování nezpracovaných dokumentů: Transformujte nezpracovaná data do použitelného formátu. Například extrahování textu, tabulek a obrázků z kolekce souborů PDF nebo použití technik optického rozpoznávání znaků k extrakci textu z obrázků.
- Extrahování metadat: Extrahujte metadata dokumentu, jako jsou názvy dokumentů, čísla stránek a adresy URL, aby byl dotaz na krok načítání přesnější.
- Kousky dokumentů: Rozdělte data do segmentů, které se vejdou do kontextového okna LLM. Načtení těchto zaměřených bloků dat, nikoli celých dokumentů, dává LLM cílenější obsah pro generování odpovědí.
- Vkládání bloků dat – vložený model využívá bloky dat k vytvoření číselných reprezentací informací, které se nazývají vektorové vkládání. Vektory představují sémantický význam textu, nejen klíčová slova na úrovni povrchu. V tomto scénáři vypočítáte vložené reprezentace a použijete službu modelu k obsluhování modelu generujícího vložené reprezentace.
- Uložení vektorových vložek – uložte vektorové vložky a text segmentu do tabulky Delta synchronizované s vektorovým vyhledáváním.
- Vektorová databáze – V rámci vektorového vyhledávání se vkládání a metadat indexují a ukládají do vektorové databáze pro snadné dotazování agentem RAG. Když uživatel vytvoří dotaz, jeho požadavek se vloží do vektoru. Databáze pak pomocí vektorového indexu vyhledá a vrátí nejvíce podobné bloky dat.
Každý krok zahrnuje technická rozhodnutí, která ovlivňují kvalitu aplikace RAG. Například výběr správné velikosti bloku dat v kroku (3) zajistí, že LLM obdrží konkrétní kontextové informace, zatímco výběr vhodného modelu vložení v kroku (4) určuje přesnost bloků dat vrácených během načítání.
Vyhledávání vektorů Databricks
Podobnost výpočtů je často výpočetně náročná, ale vektorové indexy, jako je Databricks Vector Search, optimalizují tuto funkci efektivním uspořádáním vkládání. Vektorové vyhledávání rychle řadí nejrelevavantnější výsledky, aniž by se jednotlivé vkládání porovnávaly s dotazem uživatele jednotlivě.
Vektorové vyhledávání automaticky synchronizuje nové vložené položky přidané do tabulky Delta a aktualizuje index Vector Search.
Co je agent RAG?
Agent RAG (Retrieval Augmented Generation) je klíčovou součástí aplikace RAG, která vylepšuje možnosti velkých jazykových modelů (LLM) integrací načítání externích dat. Agent RAG zpracovává dotazy uživatelů, načítá relevantní data z vektorové databáze a předává tato data do LLM, aby vygeneroval odpověď.
Nástroje, jako je LangChain nebo Pyfunc, propojují tyto kroky propojením jejich vstupů a výstupů.
Následující diagram znázorňuje agenta RAG pro chatovacího robota a funkce Databricks používané k sestavení jednotlivých agentů.
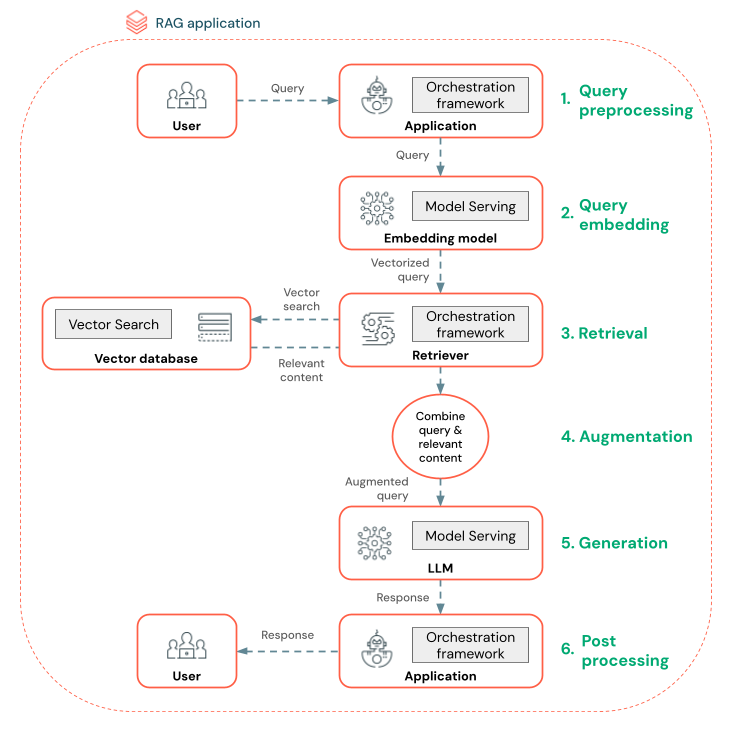
- Předběžné zpracování dotazu – Uživatel odešle dotaz, který se pak předzpracuje, aby byl vhodný pro dotazování vektorové databáze. To může zahrnovat umístění požadavku do šablony nebo extrahování klíčových slov.
- Vektorizace dotazů – Pomocí služby Model Serving můžete vložit požadavek pomocí stejného modelu vložení, který se používá k vložení bloků dat do datového kanálu. Tato vkládání umožňují porovnání sémantické podobnosti mezi požadavkem a předzpracovanými bloky dat.
- Fáze načítání – retriever, aplikace zodpovědná za načítání relevantních informací, přebírá vektorizovaný dotaz a provádí vyhledávání vektorové podobnosti pomocí vektorového vyhledávání. Nejdůležitější datové bloky jsou seřazené a načtené na základě jejich podobnosti s dotazem.
- Rozšíření výzvy - Retriever kombinuje získané datové části s původním dotazem pro poskytnutí dalšího kontextu LLM. Výzva je pečlivě strukturovaná, aby se zajistilo, že LLM rozumí kontextu dotazu. LLM často obsahuje šablonu pro formátování odpovědi. Tento proces úpravy výzvy se označuje jako navrhování promptů.
- Fáze generování LLM – LLM vygeneruje odpověď pomocí vylepšeného dotazu obohaceného výsledky vyhledávání. LLM může být vlastní model nebo základní model.
- Následné zpracování – Odpověď LLM může být zpracována za účelem použití další obchodní logiky, přidání citací nebo jiného upřesnění generovaného textu na základě předdefinovaných pravidel nebo omezení.
V rámci tohoto procesu se můžou použít různé mantinely, aby se zajistilo dodržování podnikových zásad. To může zahrnovat filtrování příslušných požadavků, kontrolu uživatelských oprávnění před přístupem ke zdrojům dat a použití technik moderování obsahu u vygenerovaných odpovědí.
Vývoj agenta RAG na úrovni produkčního prostředí
Pomocí následujících funkcí můžete rychle iterovat vývoj agentů:
Vytvářejte a protokolujte agenty pomocí libovolné knihovny a MLflow. Parametrizujte agenty, abyste mohli rychle experimentovat a iterovat při vývoji agentů.
Nasazení agentů do produkčního prostředí s nativní podporou streamování tokenů a protokolování požadavků a odpovědí a integrované aplikace pro kontrolu, která vám umožní získat zpětnou vazbu od uživatelů pro vašeho agenta.
Trasování agentů umožňuje protokolovat, analyzovat a porovnávat trasování napříč kódem agenta, abyste mohli ladit a pochopit, jak agent reaguje na požadavky.
Vyhodnocení a monitorování
Vyhodnocení a monitorování vám pomůže určit, jestli vaše aplikace RAG splňuje vaše požadavky na kvalitu, náklady a latenci. Vyhodnocení probíhá během vývoje, zatímco monitorování probíhá po nasazení aplikace do produkčního prostředí.
RAG nad nestrukturovanými daty má mnoho komponent, které mají vliv na kvalitu. Změny formátování dat můžou například ovlivnit načtené bloky dat a schopnost LLM generovat relevantní odpovědi. Proto je důležité kromě celkové aplikace vyhodnotit i jednotlivé komponenty.
Další informace najdete v tématu Co je Hodnocení agenta AI pro Mozaiku?.
Regionální dostupnost
Informace o regionální dostupnosti rozhraní Agent Framework najdete v tématu Funkce s omezenou regionální dostupností.