Trasování MLflow pro agenty
Důležité
Tato funkce je ve verzi Public Preview.
Tento článek popisuje trasování MLflow v Databricks a jeho použití k přidání pozorovatelnosti do aplikací generující umělé inteligence.
Co je trasování MLflow?
Trasování MLflow zachycuje podrobné informace o provádění generativní AI aplikací. Trasování zaznamenává vstupy, výstupy a metadata přidružená ke každému přechodnému kroku požadavku, abyste mohli určit zdroj chyb a neočekávané chování. Pokud například model halucinuje, můžete rychle zkontrolovat každý krok, který vedl k halucinaci.
Trasování MLflow je integrované s nástroji a infrastrukturou Databricks a umožňuje ukládat a zobrazovat trasování v poznámkových blocích Databricks nebo v uživatelském rozhraní experimentu MLflow.
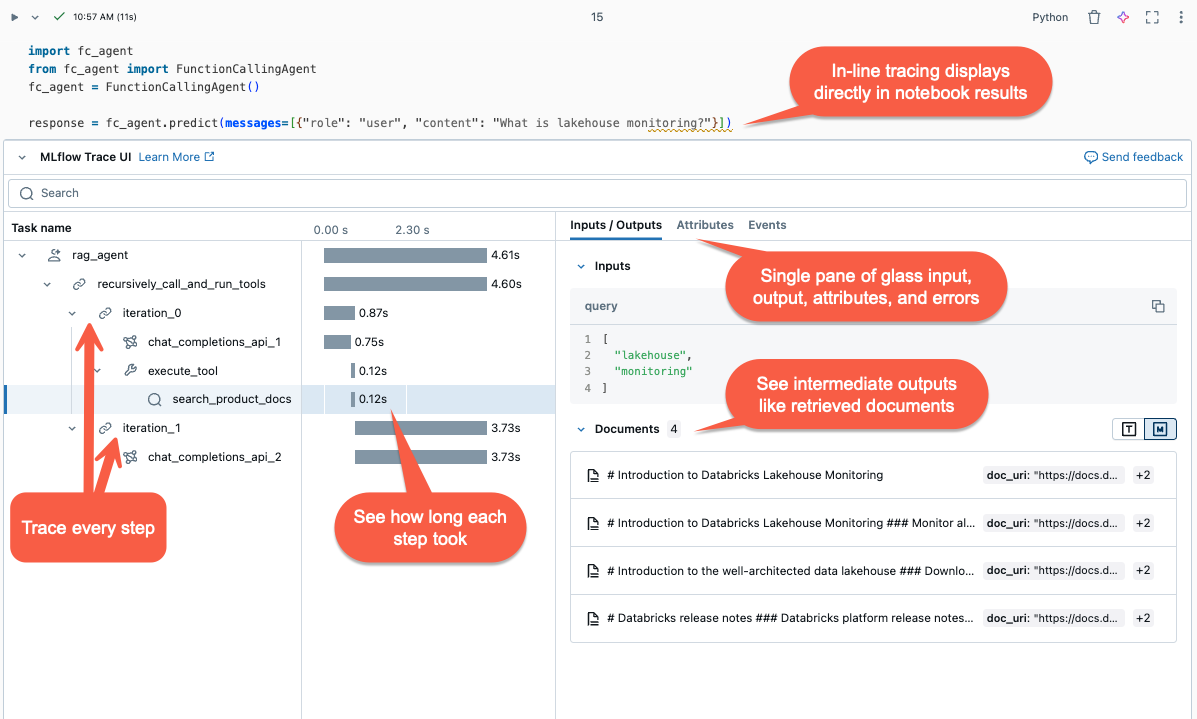 .
.
Proč používat trasování MLflow?
Trasování MLflow nabízí několik výhod:
- Projděte si interaktivní vizualizaci trasování a pomocí nástroje pro šetření můžete diagnostikovat problémy.
- Ověřte, že šablony podnětů a pravidla vytvářejí rozumné výsledky.
- Analyzujte latenci různých architektur, modelů a velikostí bloků dat.
- Odhad nákladů na aplikace měřením využití tokenů v různých modelech
- Vytvořte "zlaté" datové sady srovnávacího testu, abyste mohli vyhodnotit výkon různých verzí.
- Ukládejte stopy z koncových bodů produkčního modelu, abyste mohli řešit problémy a provádět offline kontrolu a hodnocení.
Přidání trasování do agenta
Trasování MLflow podporuje tři metody pro přidávání stop do aplikací generativní umělé inteligence. Podrobné informace o rozhraní API najdete v dokumentaci k MLflow.
| rozhraní API | Doporučený případ použití | Popis |
|---|---|---|
| automatické zaznamenávání MLflow | Vývoj s integrovanými knihovnami GenAI | Automatické zaznamenávání automaticky zaznamenává stopy pro podporované open-source frameworky, jako jsou LangChain, LlamaIndex a OpenAI. |
| rozhraní FLUENT API |
Vlastní agent s Pyfunc | Rozhraní nízkokódové API pro přidávání trasování, aniž byste se museli starat o správu stromové struktury trasování. MLflow automaticky určuje odpovídající nadřazené a podřízené vztahy pomocí Pythonového stacku. |
| klientská rozhraní API MLflow | Pokročilé případy použití, jako je vícevláknové |
MLflowClient poskytuje podrobná rozhraní API s bezpečností pro více vláken pro pokročilé scénáře použití. Musíte ručně spravovat vztah mezi nadřazeným a podřízeným úsekem. To vám dává lepší kontrolu nad životním cyklem trasování, zejména pro případy použití s více vlákny. |
Instalace trasování MLflow
Trasování MLflow je k dispozici v verzích MLflow 2.13.0 a vyšších, které jsou předinstalovány v <DBR< 15.4 LTS ML a vyšších. V případě potřeby nainstalujte MLflow s následujícím kódem:
%pip install mlflow>=2.13.0 -qqqU
%restart_python
Alternativně můžete nainstalovat nejnovější verzi databricks-agents, která zahrnuje kompatibilní verzi MLflow:
%pip install databricks-agents
Použijte autologování pro přidání tras k vašim agentům
Pokud knihovna GenAI podporuje trasování, jako je LangChain nebo OpenAI, povolte automatické protokolování přidáním mlflow.<library>.autolog() do kódu. Například:
mlflow.langchain.autolog()
Poznámka:
Od databricks Runtime 15.4 LTS ML je trasování MLflow ve výchozím nastavení povolené v poznámkových blocích. Pokud chcete například zakázat trasování pomocí jazyka LangChain, můžete v poznámkovém bloku spustit mlflow.langchain.autolog(log_traces=False).
MLflow podporuje další knihovny pro automatické trasování. Úplný seznam integrovaných knihoven najdete v dokumentaci sledování MLflow.
Ruční přidání trasování do agenta pomocí rozhraní Fluent API
Fluent API v MLflow automaticky vytváří hierarchie trasování na základě toku provádění kódu.
Vyzdobit funkci
Pomocí dekorátoru @mlflow.trace vytvořte rozsah pro dekorovanou funkci.
Objekt MLflow Span uspořádá kroky trasování. Spans zaznamenává informace o jednotlivých operacích nebo krocích, jako jsou volání rozhraní API nebo dotazy na úložiště vektorů v rámci pracovního postupu.
Délka začíná, když je funkce vyvolána, a končí, když se funkce vrátí. MLflow zaznamenává vstup a výstup funkce a všechny výjimky vyvolané funkcí.
Například následující kód vytvoří rozsah pojmenovaný my_function, který zachycuje vstupní argumenty x a y a výstup.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
Použití správce kontextu trasování
Pokud chcete vytvořit rozsah pro libovolný blok kódu, nejen pro funkci, můžete použít mlflow.start_span() jako správce kontextu, který zabalí blok kódu. Interval začíná při vstupu do kontextu a končí při výstupu z kontextu. Vstupy a výstupy span by měly být poskytovány ručně pomocí metod setter objektu span, který poskytuje správce kontextu.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Zabalte externí funkci
Chcete-li sledovat funkce externí knihovny, obalte funkci pomocí mlflow.trace.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
Příklad rozhraní FLUENT API
Následující příklad ukazuje, jak pomocí rozhraní Fluent API mlflow.trace a mlflow.start_span trasovat quickstart-agent:
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
Po přidání trasování spusťte funkci. Následující příklad pokračuje s funkcí predict() v předchozí části. Trasování se automaticky zobrazí při spuštění metody vyvolání predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
Klientské API rozhraní MLflow
MlflowClient zpřístupňuje podrobná rozhraní API bezpečná pro přístup z více vláken pro spuštění a ukončení sledování, správu rozsahů a nastavení polí rozsahu. Poskytuje úplnou kontrolu nad životním cyklem a strukturou trasovacích procesů. Tato rozhraní API jsou užitečná, když rozhraní Fluent API nejsou dostatečná pro vaše požadavky, jako jsou aplikace s více vlákny a zpětná volání.
Následující postup slouží k vytvoření kompletního trasování pomocí klienta MLflow.
Vytvořte instanci MLflowClient pomocí
client = MlflowClient().Spusťte trasování pomocí metody
client.start_trace(). Tím se zahájí kontext trasování, spustí se absolutní kořenový úsek a vrátí kořenový objekt úseku. Tato metoda musí být spuštěna před rozhraním APIstart_span().- Nastavte atributy, vstupy a výstupy pro trasování v
client.start_trace().
Poznámka:
V rozhraních FLUENT API neexistuje ekvivalent metody
start_trace(). Důvodem je to, že rozhraní Fluent API automaticky inicializují kontext trasování a určují, jestli se jedná o kořenové rozpětí na základě spravovaného stavu.- Nastavte atributy, vstupy a výstupy pro trasování v
Rozhraní API start_trace() vrátí rozsah. Získejte ID požadavku, jedinečný identifikátor trasování označovaný také jako
trace_ida ID vráceného rozsahu pomocíspan.request_idaspan.span_id.Spusťte podřízený rozsah pomocí
client.start_span(request_id, parent_id=span_id)k nastavení atributů, prvků a výstupů pro rozsah.- Tato metoda vyžaduje, aby
request_idaparent_idpřidružily úsek ke správné pozici v hierarchii trasování. Vrátí další objekt typu span.
- Tato metoda vyžaduje, aby
Ukončete dětský úsek voláním
client.end_span(request_id, span_id).Opakujte kroky 3 až 5 pro všechny podřízené rozsahy, které chcete vytvořit.
Po ukončení všech podřízených volání
client.end_trace(request_id)zavřete trasování a zaznamenejte ho.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
Kontrola trasování
Pokud chcete zkontrolovat trasování po spuštění agenta, použijte jednu z následujících možností:
- Vizualizace trasování se vykreslí přímo ve výstupu buňky.
- Trasování se protokoluje do experimentu MLflow. Úplný seznam historických trasování můžete zkontrolovat a prohledat na kartě Trasování na stránce Experiment. Když agent běží v rámci aktivního spuštění MLflow, stopy se objeví na stránce Run.
- Trasování načítá programově pomocí rozhraní API search_traces().
Použití trasování MLflow v produkčním prostředí
Trasování MLflow je také integrováno s obsluhou modelu Mosaic AI, která umožňuje efektivně ladit problémy, monitorovat výkon a vytvořit zlatou datovou sadu pro offline vyhodnocení. Pokud je pro váš koncový bod obsluhy povolené trasování MLflow, trasování se zaznamená do tabulky odvozování pod sloupcem response.
Trasy, které jsou protokolovány do inferenčních tabulek, můžete vizualizovat dotazem na tabulku a zobrazením výsledků v notebooku. Použijte display(<the request logs table>) v poznámkovém bloku a vyberte jednotlivé řádky stop, které chcete vizualizovat.
Pokud chcete povolit trasování MLflow pro váš obslužný koncový bod, musíte v konfiguraci koncového bodu nastavit proměnnou prostředí ENABLE_MLFLOW_TRACING na True. Informace o nasazení koncového bodu s vlastními proměnnými prostředí najdete v tématu Přidání proměnných prostředí ve formátu prostého textu. Pokud jste nasadili agenta pomocí rozhraní API deploy(), trasování se automaticky zaprotokoluje do tabulky odvozování. Viz Nasazení agenta pro generování aplikace AI.
Poznámka:
Zápis trasování do odvozovací tabulky se provádí asynchronně, takže během vývoje nepřidává stejnou režii jako v prostředí poznámkového bloku. Přesto ale může do rychlosti odezvy koncového bodu zavádět určité režijní náklady, zejména pokud je velikost trasování pro každý požadavek na odvozování velká. Databricks nezaručuje žádnou smlouvu o úrovni služeb (SLA) pro skutečný dopad latence na koncový bod modelu, protože výrazně závisí na prostředí a implementaci modelu. Databricks doporučuje otestovat výkon koncového bodu a získat přehled o režii trasování před nasazením do produkční aplikace.
Následující tabulka poskytuje přibližný přehled o dopadu na latenci u různých velikostí stop.
| Velikost trasování na požadavek | Dopad na latenci (ms) |
|---|---|
| ~10 kB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Omezení
- Trasování MLflow je k dispozici v poznámkových blocích Databricks, úlohách poznámkových bloků a obsluhě modelů.
Automatické protokolování jazyka LangChain nemusí podporovat všechna rozhraní API pro predikce jazyka LangChain. Úplný seznam podporovaných rozhraní API najdete v dokumentaci k MLflow.