Vytváření agentů AI v kódu
V tomto článku se dozvíte, jak v Pythonu vytvořit agenta AI s využitím architektury agenta Mosaic AI a oblíbených knihoven pro vytváření agentů, jako jsou LangGraph, PyFunc a OpenAI.
Požadavky
Databricks při vývoji agentů doporučuje nainstalovat nejnovější verzi klienta Pythonu MLflow.
Pokud chcete vytvářet a nasazovat agenty pomocí přístupu v tomto článku, musíte mít následující minimální verze balíčků:
-
databricks-agentsverze 0.16.0 a vyšší -
mlflowverze 2.20.2 a vyšší - Python 3.10 nebo novější K splnění tohoto požadavku můžete použít bezserverové výpočetní prostředky nebo Databricks Runtime 13.3 LTS a vyšší.
%pip install -U -qqqq databricks-agents>=0.16.0 mlflow>=2.20.2
Databricks také při vytváření agentů doporučuje nainstalovat integrační balíčky mostu Databricks AI. Tyto integrační balíčky (například databricks-langchain, databricks-openai) poskytují sdílenou vrstvu rozhraní API pro interakci s funkcemi AI Databricks, jako jsou Databricks AI/BI Genie a Vector Search, napříč architekturami pro vytváření agentů a sadami SDK.
LangChain/LangGraph
%pip install -U -qqqq databricks-langchain
OpenAI
%pip install -U -qqqq databricks-openai
Čistě agenti Pythonu
%pip install -U -qqqq databricks-ai-bridge
Vytváření agentů pomocí ChatAgent
Databricks doporučuje k vytváření agentů na produkční úrovni používat rozhraní ChatAgent MLflow. Tato specifikace schématu chatu je určená pro scénáře agentů a je podobná schématu OpenAI ChatCompletion, ale není přísně kompatibilní.
ChatAgent také přidává funkcionalitu pro agenty pro vícero interakcí a volání nástrojů.
Vytvoření agenta pomocí ChatAgent poskytuje následující výhody:
Pokročilé možnosti agenta
- Streamování výstupu: Povolte interaktivní uživatelské prostředí streamováním výstupu v menších blocích.
- Úplná historie volání nástrojů: Vrátí více zpráv, včetně mezikrokových zpráv volání nástrojů, pro lepší kvalitu a správu konverzace.
- podpora potvrzení tool-call
- Podpora systému s více agenty
Zjednodušený vývoj, nasazení a monitorování
- Nezávislé na frameworku, integrace funkcí Databricks: Napište svého agenta v libovolném frameworku podle vašeho výběru a získejte okamžitou kompatibilitu s AI Playground, hodnocením agenta a monitorováním agentů.
- Rozhraní pro psaní s typy: Psaní kódu agenta pomocí typovaných tříd Pythonu, které využívají integrované vývojové prostředí (IDE) a automatické dokončování poznámkových bloků.
-
automatické odvozování podpisů: MLflow automaticky odvodí
ChatAgentpodpisy při protokolování agenta, zjednoduší registraci a nasazení. Viz Zjištění podpisu modelu při protokolování. - tabulky odvození rozšířené brány AI: Pro nasazené agenty jsou automaticky povolené tabulky odvozování brány AI, které poskytují přístup k podrobným metadatům protokolu požadavků.
Informace o vytvoření ChatAgentnajdete v příkladech v následující části a dokumentaci K MLflow – co je rozhraní ChatAgent.
příklady ChatAgent
Následující poznámkové bloky ukazují, jak vytvářet streamované a nestreamované ChatAgents pomocí oblíbených knihoven OpenAI a LangGraph.
Agent pro volání nástrojů LangGraph
Získejte poznámkový blok
Agent volání nástrojů OpenAI
Pořiďte si poznámkový blok
Chatovací agent pouze pro OpenAI
Získejte poznámkový blok
Informace o tom, jak rozšířit možnosti těchto agentů přidáním nástrojů, najdete v tématu nástroje agenta AI.
Vytváření ChatAgentpřipravených k nasazení pro službu modelu Databricks
Databricks nasadí ChatAgents v distribuovaném prostředí ve službě Databricks Model Serving, což znamená, že během vícenásobné konverzace nemusí stejná replika obsluhy zpracovávat všechny požadavky. Věnujte pozornost následujícím vlivům na správu stavu agenta.
Vyhněte se místnímu ukládání do mezipaměti: Když nasazujete
ChatAgent, nepředpokládejte, že stejná replika bude zpracovávat všechny požadavky ve vícekrokovém dialogu. Rekonstruujte vnitřní stav pomocí schématu slovníkuChatAgentRequestpro každý krok.vláknově bezpečný stav: Navrhněte stav agenta tak, aby byl vláknově bezpečný a bránil konfliktům v prostředí více vláken.
Inicializovat stav ve funkci
predict: Inicializovat stav při každém zavolánípredictfunkce, ne během inicializaceChatAgent. Ukládání stavu na úrovniChatAgentmůže způsobit únik informací mezi konverzacemi a způsobit konflikty, protože jedna replikaChatAgentmůže zpracovávat žádosti z více konverzací.
uživatelsky definovaných vstupů a výstupů
Některé scénáře mohou vyžadovat další vstupy agenta, jako jsou client_type a session_id, nebo výstupy, jako jsou odkazy na načtení zdroje, které by neměly být zahrnuty do historie chatu pro budoucí interakce.
V těchto scénářích ChatAgent MLflow nativně podporuje pole custom_inputs a custom_outputs.
Varování
Aplikace pro vyhodnocení agenta v současné době nepodporuje vykreslování tras pro agenty s dalšími vstupními poli.
V následujících příkladech se dozvíte, jak nastavit vlastní vstupy a výstupy pro agenty OpenAI/PyFunc a LangGraph.
Poznámkový blok agenta vlastního schématu OpenAI + PyFunc
Získání poznámkového bloku
Poznámkový blok agenta vlastního schématu LangGraph
Pořiďte si poznámkový blok
poskytnout custom_inputs v aplikaci AI Playground a aplikace pro kontrolu agentů
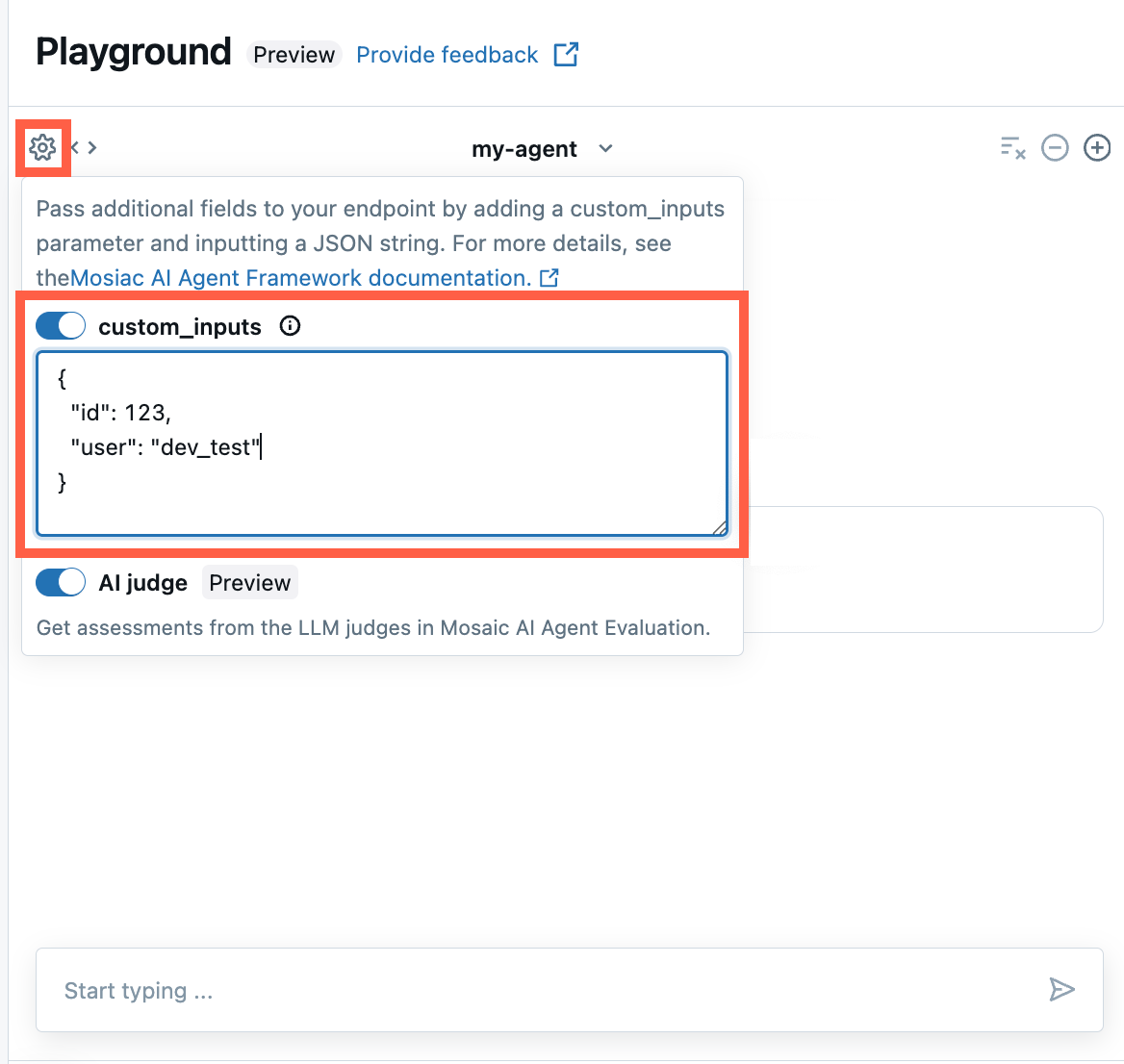
Pokud váš agent přijímá další vstupy pomocí pole custom_inputs, můžete tyto vstupy zadat ručně jak v aplikaci AI Playground, tak v aplikaci pro kontrolu agenta .
V aplikaci AI Playground nebo Agent Review App vyberte ikonu ozubeného kola
 .
.Povolte custom_inputs.
Zadejte objekt JSON, který odpovídá definovanému schématu vstupu vašeho agenta.
Určení vlastních schémat pro vyhledávač dat
Agenti umělé inteligence běžně používají retrievery k vyhledávání a dotazování nestrukturovaných dat z indexů vektorového vyhledávání. Například nástroje pro vyhledávání, viz Nestrukturované vyhledávací nástroje agenta AI.
Trasujte tyto retrievery ve vašem agentovi pomocí MLflow RETRIEVER spans pro aktivaci funkcí produktu Databricks, mezi které patří:
- Automatické zobrazení odkazů na načtené zdrojové dokumenty v uživatelském rozhraní AI Playground
- Automatické spouštění správnosti načítání a hodnocení relevance při vyhodnocení agenta
Poznámka
Databricks doporučuje používat nástroje pro načítání poskytované balíčky Databricks AI Bridge, jako jsou databricks_langchain.VectorSearchRetrieverTool a databricks_openai.VectorSearchRetrieverTool, protože již odpovídají schématu retrieveru MLflow. Viz Vyvíjejte místně nástroje pro vyhledávání vektorů s AI Bridge.
Pokud váš agent zahrnuje rozsahy retrieveru s vlastním schématem, zavolejte funkci mlflow.models.set_retriever_schema při definování agenta v kódu. To mapuje výstupní sloupce vašeho retrieveru na očekávaná pole MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="chunk_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="text_column",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
)
Poznámka
Sloupec doc_uri je zvlášť důležitý při vyhodnocování výkonu vyhledávače.
doc_uri je hlavním identifikátorem dokumentů vrácených retrieverem, což vám umožní porovnat je se sadami vyhodnocení základní pravdy. Podívejte se na sady vyhodnocení .
parametrizovat kód agenta pro nasazení napříč prostředími
Kód agenta můžete parametrizovat tak, aby znovu používal stejný kód agenta v různých prostředích.
Parametry jsou páry klíč-hodnota, které definujete ve slovníku Pythonu nebo v souboru .yaml.
Pokud chcete kód nakonfigurovat, vytvořte ModelConfig pomocí slovníku Pythonu nebo souboru .yaml .
ModelConfig je soubor parametrů ve formátu klíč-hodnota, který umožňuje flexibilní správu konfigurace. Můžete například použít slovník během vývoje a pak ho převést na soubor .yaml pro produkční nasazení a CI/CD.
Podrobnosti o ModelConfignajdete v dokumentaci MLflow.
Příklad ModelConfig je uvedený níže:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
V kódu agenta můžete odkazovat na výchozí konfiguraci (vývoj) ze souboru .yaml nebo slovníku:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Poté při protokolování agenta zadejte hodnotu parametru model_config na log_model, abyste určili vlastní sadu parametrů k použití při načítání protokolovaného agenta. Viz dokumentaci k MLflow - ModelConfig.
Šíření chyb streamování
Mosaic AI přenáší všechny chyby, ke kterým dochází při streamování s posledním tokenem pod databricks_output.error. Je na volajícím klientovi, aby správně zvládl a zobrazil tuto chybu.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}