Správa kvality dat pomocí očekávání datové pipeline
Pomocí očekávání použijte omezení kvality, která ověřují data při jejich toku prostřednictvím kanálů ETL. Očekávání poskytují lepší přehled o metrikách kvality dat a umožňují selhání aktualizací nebo vyřazení záznamů při zjišťování neplatných záznamů.
Tento článek obsahuje přehled očekávání, včetně příkladů syntaxe a možností chování. Pokročilejší případy použití a doporučené osvědčené postupy najdete v tématu Doporučení k očekávání a pokročilé vzory.
graf průtokových očekávání 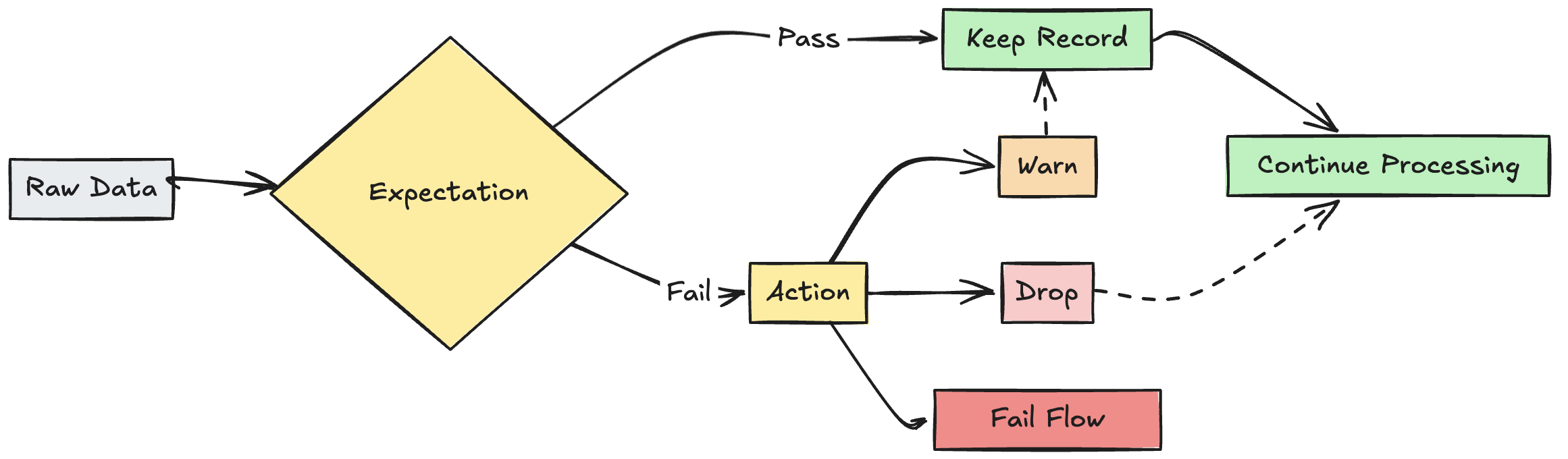
Co jsou očekávání?
Očekávání jsou volitelné klauzule v materializovaném zobrazení pipeline, streamovaném zobrazení tablenebo v příkazech pro vytváření zobrazení, které provádějí kontroly kvality dat u každého záznamu procházejícího dotazem. Očekávání používají standardní logické příkazy SQL k určení omezení. Můžete kombinovat více očekávání pro jednu datovou sadu a set očekávání napříč všemi deklaracemi datových sad v pipeline.
Následující části představují tři komponenty očekávání a poskytují příklady syntaxe.
Název očekávání
Každé očekávání musí mít název, který se používá jako identifier, aby bylo možné očekávání sledovat a monitorovat. Zvolte název, který oznamuje ověřované metriky. Následující příklad definuje očekávání valid_customer_age pro potvrzení, že věk je mezi 0 a 120 lety.
Důležité
Pro danou datovou sadu musí být jedinečný název očekávání. Očekávání můžete znovu použít napříč několika datovými sadami ve zpracovávacím toku. Viz Přenosné a opakovaně použitelné očekávání.
Python
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
Constraint pro vyhodnocení
Klauzule constraint je podmíněný příkaz SQL, který musí být pro každý záznam vyhodnocen jako true nebo false. constraint obsahuje skutečnou logiku toho, co se ověřuje. Pokud záznam nesplňuje tuto podmínku, aktivuje se očekávání.
Omezení musí používat platnou syntaxi SQL a nesmí obsahovat následující:
- Vlastní funkce Pythonu
- Volání externích služeb
- Poddotazy odkazující na jiné tables
Tady jsou příklady omezení, která je možné přidat do příkazů pro vytváření datových sad:
Python
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0)
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
Akce s neplatným záznamem
Je nutné zadat akci, která určí, co se stane, když záznam selže při kontrole ověření. Následující table popisuje dostupné akce:
| Akce | Syntaxe SQL | Syntaxe Pythonu | Výsledek |
|---|---|---|---|
| upozornění (výchozí) | EXPECT |
dlt.expect |
Na cílové místo se zapisují neplatné záznamy. Počet platných a neplatných záznamů se protokoluje spolu s dalšími metrikami datové sady. |
| kapka | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
Neplatné záznamy jsou odstraněny před zápisem dat do cílového místa. Počet vynechaných záznamů se protokoluje spolu s dalšími metrikami datové sady. |
| selhat | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
Neplatné záznamy brání úspěšnému dokončení update. Před opětovnou úpravou je vyžadován ruční zásah. Toto očekávání způsobí selhání jednoho toku a nezpůsobí selhání jiných toků ve vašem kanálu. |
Můžete také implementovat pokročilou logiku pro karanténu neplatných záznamů bez selhání nebo vyřazení dat. Vizte Neplatné záznamy pro karanténu.
Metriky sledování očekávání
Z uživatelského rozhraní pipeline můžete zobrazit metriky sledování akcí warn nebo drop. Vzhledem k tomu, že fail způsobí selhání update při zjištění neplatného záznamu, metriky se nezaznamenávají.
Pokud chcete zobrazit očekávané metriky, proveďte následující kroky:
- Na bočním panelu klikněte na Delta Live Tables.
- Klikněte na název vašeho potrubí.
- Klikněte na datovou sadu s definovaným očekáváním.
- Select karta Kvalita dat na pravém bočním panelu.
Metriky kvality dat můžete zobrazit dotazem na protokol událostí Delta Live Tables. Podívejte se na kvalitu dotazovaných dat z protokolu událostí.
Zachování neplatných záznamů
Zachování neplatných záznamů je výchozím chováním pro očekávání. Operátor expect použijte, pokud chcete uchovávat záznamy, které porušují očekávání, ale zároveň shromažďovat metriky o tom, kolik záznamů projde nebo selže v rámci constraint. Záznamy, které porušují očekávání, se přidají do cílové datové sady spolu s platnými záznamy:
Python
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
Odstranění neplatných záznamů
Pomocí operátoru expect_or_drop můžete zabránit dalšímu zpracování neplatných záznamů. Záznamy, které porušují očekávání, se z cílové datové sady zahodí:
Python
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
Selhání u neplatných záznamů
Pokud jsou neplatné záznamy nepřijatelné, ukončete expect_or_fail spuštění okamžitě, když záznam selže s ověřením. Pokud je operace tableupdate, systém atomicky vrátí zpět tuto transakci.
Python
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
Důležité
Pokud máte v kanálu definovaných více paralelních toků, selhání jednoho toku nezpůsobí selhání jiných toků.
Graf vysvětlení selhání toku 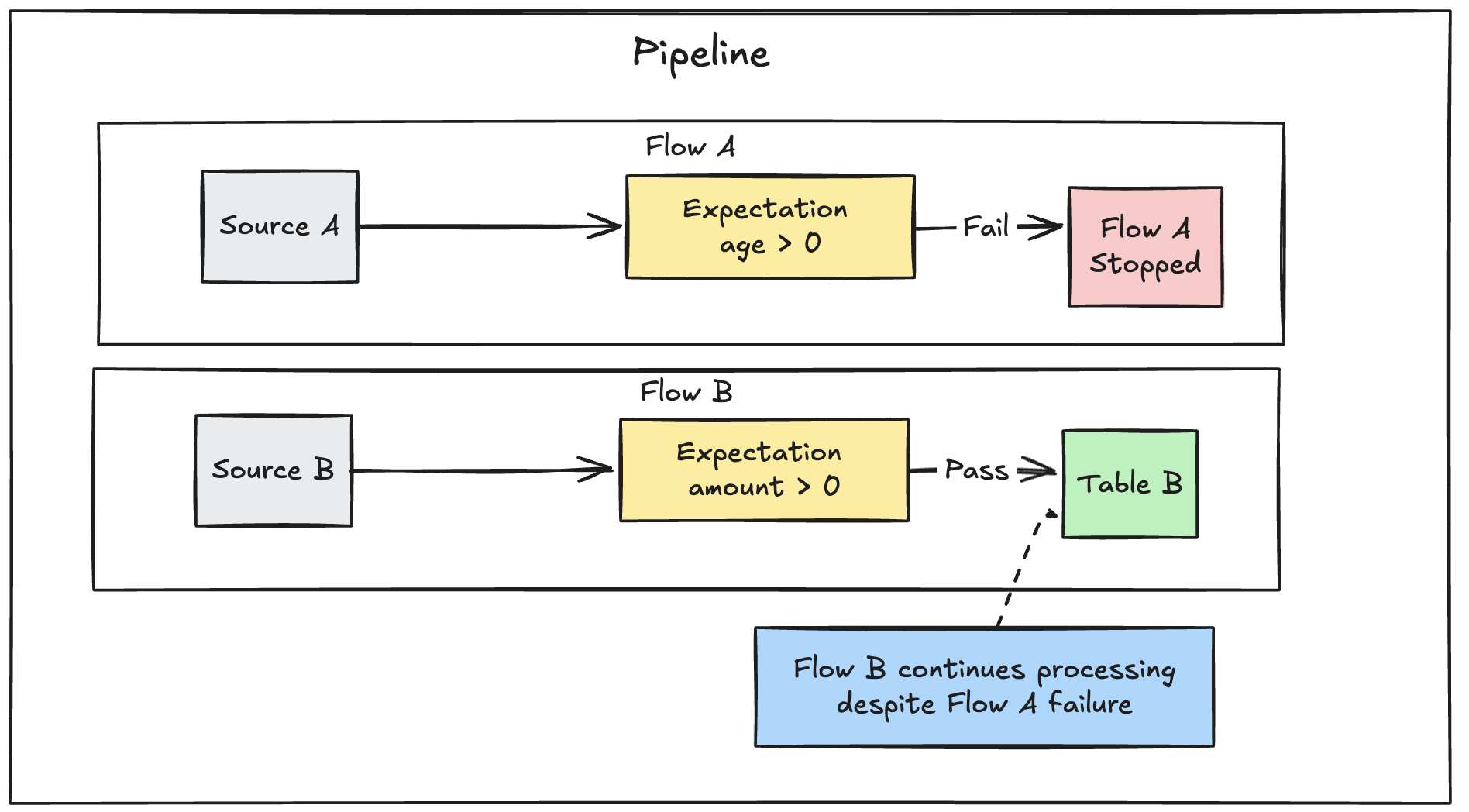
Řešení potíží s aktualizacemi, které neodpovídají očekávaným výsledkům
Pokud kanál selže z důvodu porušení očekávání, musíte před opětovným spuštěním kanálu opravit kód kanálu, který zpracuje neplatná data správně.
Očekávání nakonfigurovaná pro testování selhání v kanálech upravují plán dotazů Sparku pro vaše transformace, aby sledovalo informace potřebné k detekci a hlášení porušení. Tyto informace můžete použít k identifikaci toho, který vstupní záznam způsobil porušení mnoha dotazů. Následuje příklad očekávání:
Expectation Violated:
{
"flowName": "sensor-pipeline",
"verboseInfo": {
"expectationsViolated": [
"temperature_in_valid_range"
],
"inputData": {
"id": "TEMP_001",
"temperature": -500,
"timestamp_ms": "1710498600"
},
"outputRecord": {
"sensor_id": "TEMP_001",
"temperature": -500,
"change_time": "2024-03-15 10:30:00"
},
"missingInputData": false
}
}
Správa více očekávání
Poznámka:
I když SQL i Python podporují více očekávání v rámci jedné datové sady, umožňuje pouze Python seskupit několik samostatných očekávání a zadat kolektivní akce.
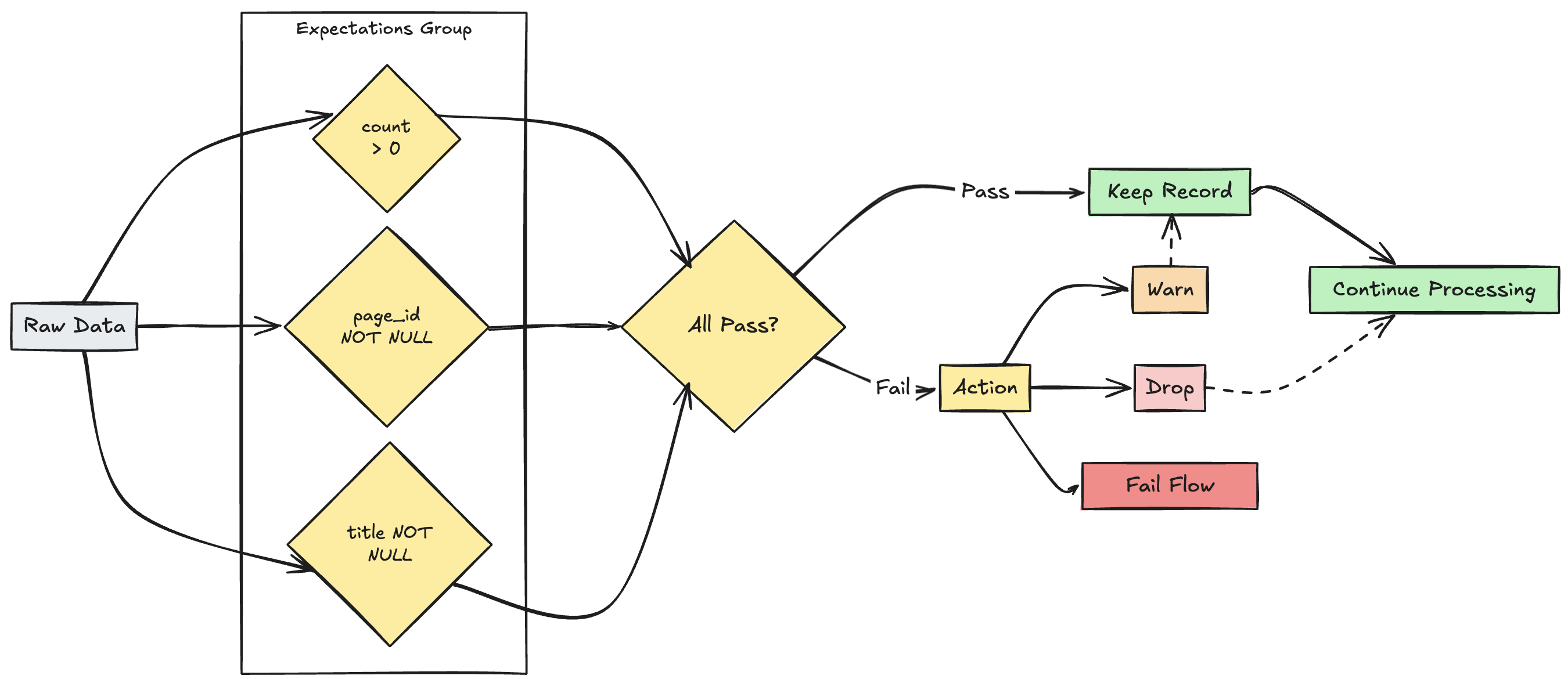 grafu fLow
grafu fLow
Pomocí funkcí expect_all, expect_all_or_dropa expect_all_or_failmůžete seskupit více očekávání a určit kolektivní akce.
Tyto dekorátory přijímají slovník Pythonu jako argument, where klíč je název očekávání a hodnota je očekávání constraint. Stejnou set očekávání můžete znovu použít ve více datových sadách ve vašem datovém kanálu. Následující příklady ukazují jednotlivé operátory expect_all Pythonu:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset