Doporučení týkající se očekávání a pokročilé vzory
Tento článek obsahuje doporučení pro implementaci očekávání ve velkém měřítku a příklady pokročilých vzorů podporovaných očekáváními. Tyto vzory používají více datových sad ve spojení s očekáváními a vyžadují, aby uživatelé pochopili syntaxi a sémantiku materializovaných zobrazení, streamovaných tabulek a očekávání.
Základní přehled chování a syntaxe očekávání najdete v tématu Řízení kvality dat s využitím očekávání řetězce úloh.
přenosná a opakovaně použitelná očekávání
Databricks doporučuje následující osvědčené postupy při implementaci očekávání, aby se zlepšila přenositelnost a snížila zatížení údržby:
| Doporučení | Dopad |
|---|---|
| Uložte očekávané definice odděleně od logiky kanálu. | Snadno použijte očekávání u více datových sad nebo kanálů. Aktualizujte, auditujte a udržujte očekávání beze změny zdrojového kódu kanálu. |
| Přidejte vlastní značky pro vytváření skupin souvisejících očekávání. | Filtrování očekávání na základě značek |
| Konzistentně použijte očekávání napříč podobnými datovými sadami. | Pomocí stejných očekávání v různých datových sadách a kanálech vyhodnoťte identickou logiku. |
Následující příklady ukazují použití tabulky Delta nebo slovníku k vytvoření centrálního úložiště očekávání. Vlastní funkce Pythonu pak aplikují tato očekávání na datové sady v příkladu datového potrubí:
Tabulka Delta
Následující příklad vytvoří tabulku s názvem rules pro správu pravidel:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
Následující příklad Pythonu definuje očekávání kvality dat na základě pravidel v tabulce rules. Funkce get_rules() přečte pravidla z tabulky rules a vrátí slovník Pythonu obsahující pravidla odpovídající argumentu tag předaného funkci.
V tomto příkladu se slovník použije pomocí @dlt.expect_all_or_drop() dekoračních prvků k zajištění omezení kvality dat.
Například všechny záznamy, které nevyhovují pravidlům označeným validity, budou z tabulky raw_farmers_market odstraněny.
import dlt
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Modul Pythonu
Následující příklad vytvoří modul Pythonu pro údržbu pravidel. V tomto příkladu uložte tento kód do souboru s názvem rules_module.py ve stejné složce jako poznámkový blok použitý jako zdrojový kód pro kanál:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
Následující příklad Pythonu definuje očekávání kvality dat na základě pravidel definovaných v souboru rules_module.py. Funkce get_rules() vrátí slovník Pythonu obsahující pravidla odpovídající tag argumentu.
V tomto příkladu se slovník použije pomocí @dlt.expect_all_or_drop() dekoračních prvků k zajištění omezení kvality dat.
Například všechny záznamy, které nevyhovují pravidlům označeným validity, budou z tabulky raw_farmers_market odstraněny.
import dlt
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Ověření počtu řádků
Následující příklad ověří rovnost počtu řádků mezi table_a a table_b a zkontroluje, jestli během transformací nedojde ke ztrátě dat:
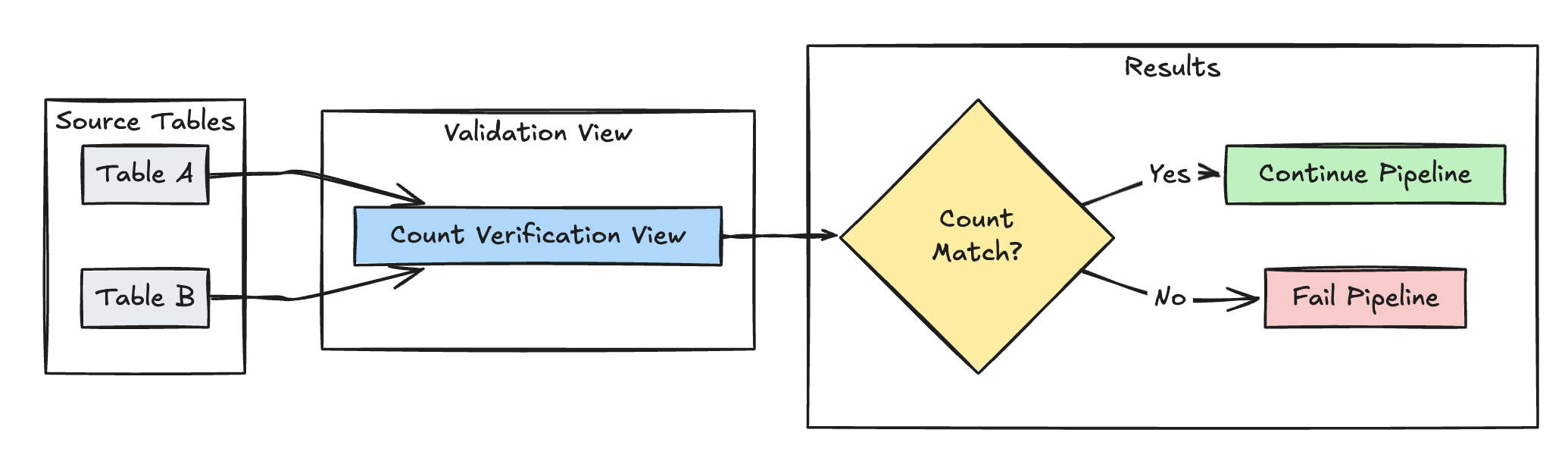
Python
@dlt.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dlt.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Detekce chybějícího záznamu
Následující příklad ověří, že jsou v tabulce report přítomny všechny očekávané záznamy:
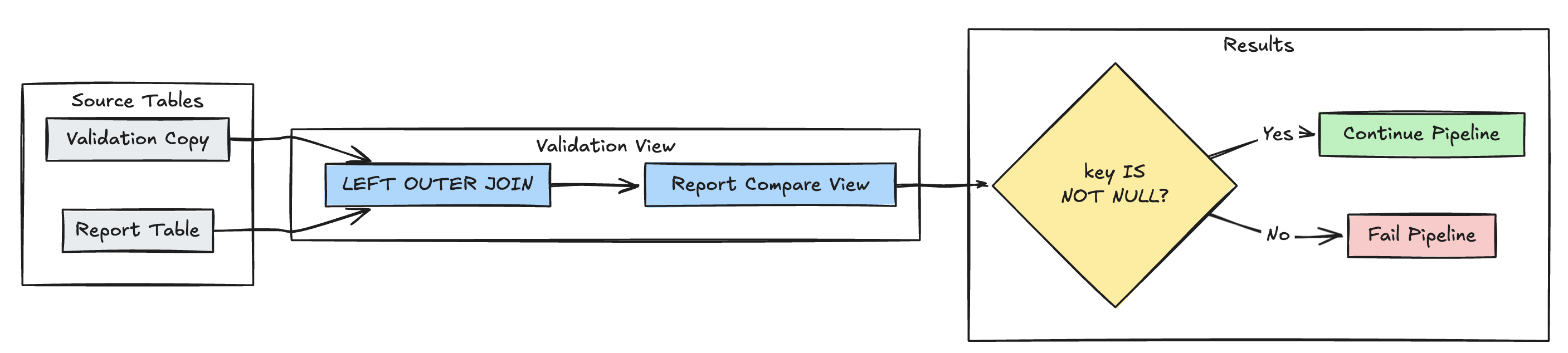
Python
@dlt.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dlt.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
dlt.read("validation_copy").alias("v")
.join(
dlt.read("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
jedinečnost primárního klíče
Následující příklad ověřuje omezení primárního klíče napříč tabulkami:
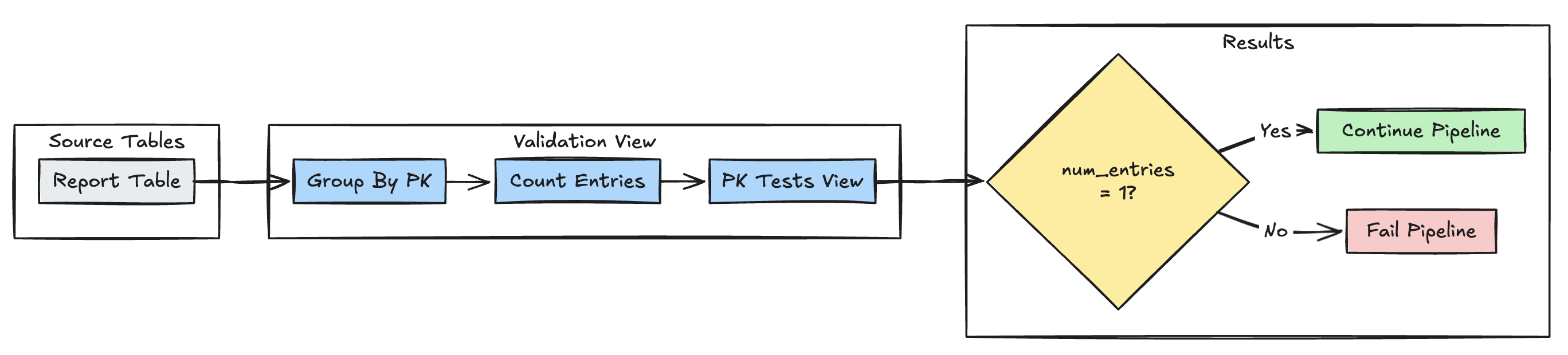
Python
@dlt.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dlt.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
dlt.read("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Vzorec evoluce schématu
Následující příklad ukazuje, jak zpracovat vývoj schématu pro další sloupce. Tento model použijte při migraci zdrojů dat nebo zpracování více verzí upstreamových dat a zajištění zpětné kompatibility při vynucování kvality dat:
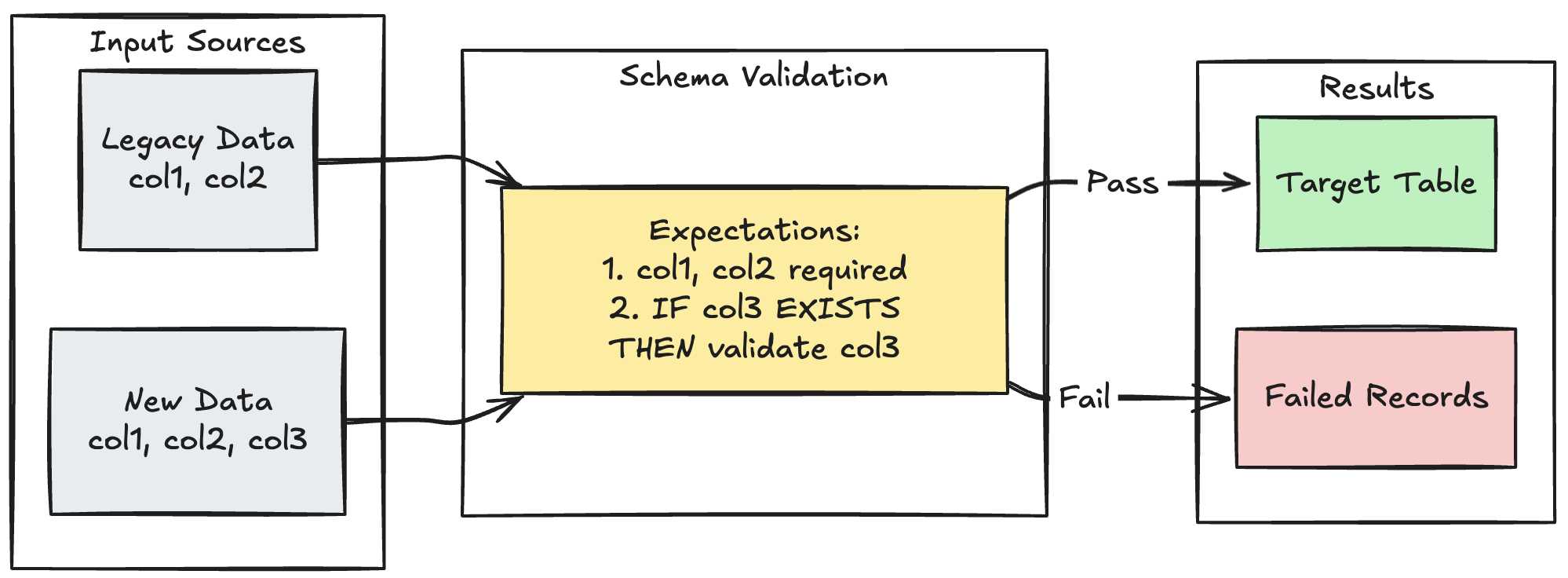
Python
@dlt.table
@dlt.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
model ověřování založený na rozsahu
Následující příklad ukazuje, jak ověřit nové datové body proti historickým statistickým rozsahům, což pomáhá identifikovat odlehlé hodnoty a anomálie ve vašem toku dat:
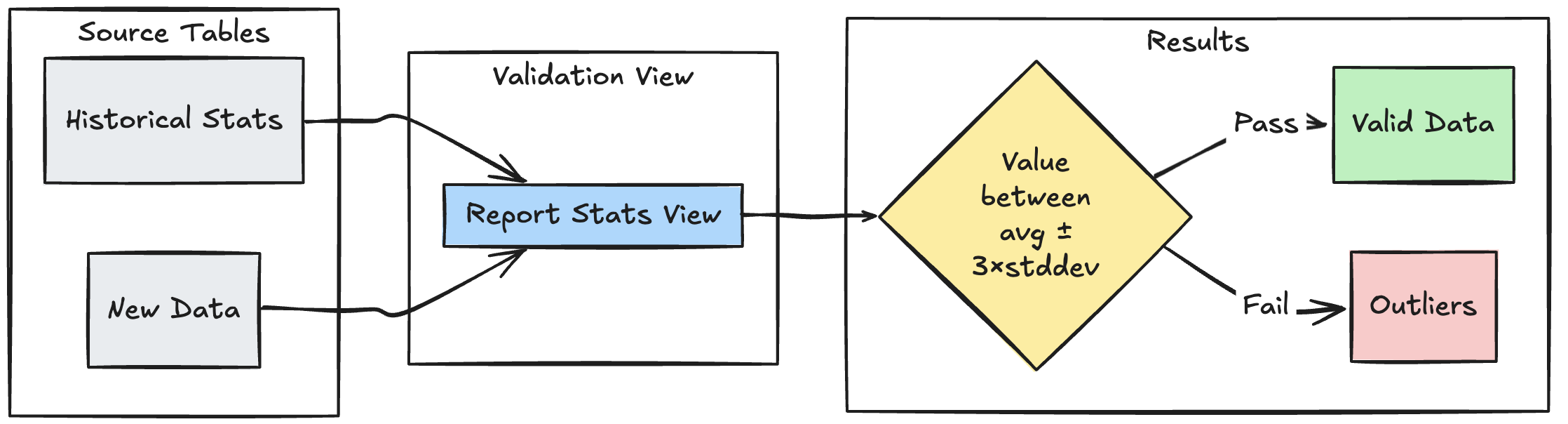
Python
@dlt.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dlt.table
@dlt.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return dlt.read("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
umístit neplatné záznamy do karantény
Tento vzor kombinuje očekávání s dočasnými tabulkami a pohledy ke sledování metrik kvality dat během aktualizací datových toků a umožnění samostatných zpracovatelských cest pro platné a neplatné záznamy v následných operacích.
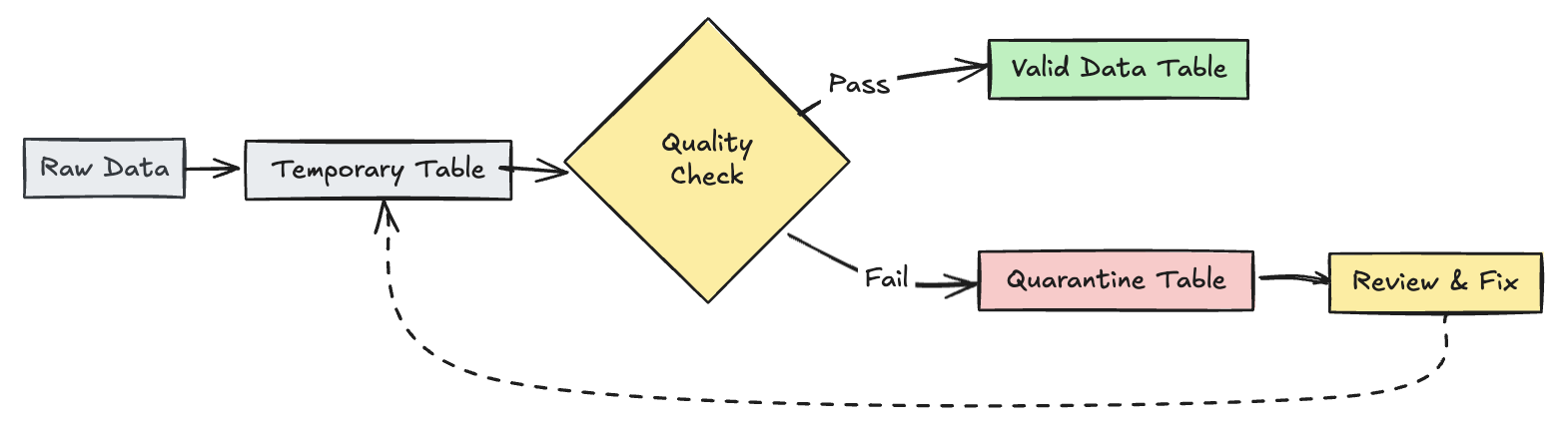
Python
import dlt
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dlt.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dlt.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dlt.expect_all(rules)
def trips_data_quarantine():
return (
dlt.readStream("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dlt.view
def valid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=false")
@dlt.view
def invalid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;