Výpočetní prostředí bez serveru pro poznámkové bloky
Tento článek vysvětluje, jak používat bezserverové výpočetní prostředky pro poznámkové bloky. Informace o používání bezserverových výpočetních prostředků pro úlohy najdete v tématu Spuštění úlohy Azure Databricks s bezserverovými výpočetními prostředky pro pracovní postupy.
Informace o cenách najdete v tématu o cenách Databricks.
Požadavky
- Pro katalog Unity musí být povolený váš pracovní prostor.
- Váš pracovní prostor musí být v podporované oblasti. Viz oblasti Azure Databricks.
- Váš účet musí být povolený pro výpočetní prostředky bez serveru. Viz Povolení výpočetních prostředků bez serveru.
Připojení poznámkového bloku k bezserverovým výpočetním prostředkům
Pokud je váš pracovní prostor povolený pro bezserverové interaktivní výpočetní prostředky, mají všichni uživatelé v pracovním prostoru přístup k bezserverovému výpočetnímu prostředí pro poznámkové bloky. Nejsou vyžadována žádná další oprávnění.
Pokud se chcete připojit k bezserverovému výpočetnímu prostředí, klikněte v poznámkovém bloku na rozevírací nabídku Připojení a vyberte „serverless“ (bezserverové výpočetní prostředí). U nových poznámkových bloků se připojené výpočetní prostředky automaticky po spuštění kódu automaticky nastaví na bezserverové, pokud nebyl vybrán žádný jiný prostředek.
Vyberte zásady rozpočtu pro bezserverové využití
Důležité
Tato funkce je ve verzi Public Preview.
Zásady rozpočtu umožňují vaší organizaci používat vlastní značky na bezserverové využití pro podrobné přisuzování fakturace.
Pokud váš pracovní prostor používá zásady rozpočtu k atributu bezserverového využití, můžete vybrat zásady rozpočtu, které chcete použít pro poznámkový blok. Pokud je uživatel přiřazený jenom k jedné zásadě rozpočtu, bude tato zásada ve výchozím nastavení vybraná.
Zásady rozpočtu můžete vybrat po tom, co je váš poznámkový blok připojen k výpočetnímu prostředí bez serverů, pomocí bočního panelu Environment:
- V uživatelském rozhraní poznámkového bloku klikněte na Environment side panelboční panel Prostředí .
- V části Zásady rozpočtu vyberte zásady rozpočtu, které chcete u poznámkového bloku použít.
- Klikněte na tlačítko Použit.
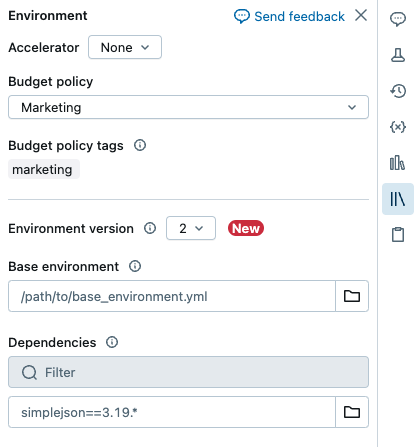
Od tohoto okamžiku zdědí veškeré využití z poznámkového bloku vlastní značky zásad rozpočtu.
Poznámka:
Pokud váš poznámkový blok pochází z úložiště Git nebo nemá přiřazenou zásadu rozpočtu, při příštím připojení k bezserverovým výpočetním prostředkům se ve výchozím nastavení nastaví na poslední zvolenou zásadu rozpočtu.
Konfigurace vysoké paměti pro bezserverové úlohy
Důležité
Tato funkce je ve verzi Public Preview.
Pokud ke spouštění úloh bez serveru potřebujete více paměti, můžete notebook nakonfigurovat tak, aby používal větší množství paměti. Bezserverové využití s vysokou pamětí má vyšší rychlost emisí DBU než standardní paměť.
- V uživatelském rozhraní poznámkového bloku klikněte na Environment side panelboční panel Prostředí .
- V části Paměťvyberte možnost Vysoká paměť.
- Klikněte na tlačítko Použit.
Toto nastavení platí také pro úlohy poznámkového bloku, které se spouštějí pomocí paměťových nastavení poznámkového bloku. Aktualizace předvoleb paměti v poznámkovém bloku ovlivní další spuštění úlohy.
Zobrazení přehledů dotazů
Bezserverové výpočetní prostředky pro poznámkové bloky a úlohy používají přehledy dotazů k vyhodnocení výkonu spouštění Sparku. Po spuštění buňky v poznámkovém bloku můžete zobrazit přehledy související s dotazy SQL a Pythonu kliknutím na odkaz Zobrazit výkon .
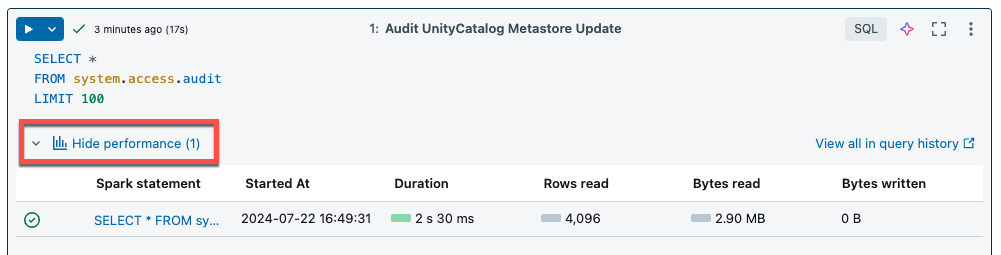
Kliknutím na některý z příkazů Sparku zobrazíte metriky dotazů. Odtud můžete kliknout na Zobrazit profil dotazu a zobrazit vizualizaci provádění dotazu. Další informace o profilech dotazů najdete v tématu Profil dotazu.
Poznámka:
Pokud chcete zobrazit přehledy výkonu pro spuštění úloh, podívejte se na zobrazení přehledů dotazů spuštění úlohy.
Historie dotazů
Všechny dotazy spouštěné na bezserverových výpočetních prostředcích se také zaznamenají na stránce historie dotazů vašeho pracovního prostoru. Informace o historii dotazů najdete v tématu Historie dotazů.
Omezení přehledů dotazů
- Profil dotazu je k dispozici pouze po ukončení provádění dotazu.
- Metriky se aktualizují živě, i když se profil dotazu během provádění nezobrazuje.
- Probírá se jenom následující stav dotazu: RUNNING, CANCELED, FAILED, FINISHED.
- Spuštěné dotazy nelze zrušit ze stránky historie dotazů. Dají se zrušit v poznámkových blocích nebo úlohách.
- Podrobné metriky nejsou k dispozici.
- Stažení profilu dotazu není k dispozici.
- Přístup k uživatelskému rozhraní Sparku není k dispozici.
- Text příkazu obsahuje pouze poslední řádek, který byl spuštěn. Před tímto řádkem však může být několik řádků, které byly spuštěny jako součást stejného příkazu.