HorovodRunner: distribuované hluboké učení s využitím Horovodu
Důležité
Horovod a HorovodRunner jsou teď zastaralé. Verze po 15.4 LTS ML nebudou mít tento balíček předinstalovaný. Pro distribuované hluboké učení doporučuje Databricks používat TorchDistributor pro distribuované trénování pomocí PyTorchu nebo tf.distribute.Strategy rozhraní API pro distribuované trénování pomocí TensorFlow.
Naučte se provádět distribuované trénování modelů strojového učení pomocí HorovodRunneru ke spouštění trénovacích úloh Horovod jako úloh Sparku v Azure Databricks.
Co je HorovodRunner?
HorovodRunner je obecné rozhraní API pro spouštění distribuovaných úloh hlubokého učení v Azure Databricks pomocí architektury Horovod . Díky integraci Horovodu s režimem bariéry Sparku dokáže Azure Databricks poskytovat vyšší stabilitu pro dlouhotrvající úlohy trénování hlubokého učení ve Sparku. HorovodRunner používá metodu Pythonu, která obsahuje trénovací kód hlubokého učení s háky Horovod. HorovodRunner vybírá metodu na ovladači a distribuuje ji pracovníkům Sparku. Úloha MPI Horovod je vložena jako úloha Sparku pomocí režimu spuštění bariéry. První exekutor shromažďuje IP adresy všech exekutorů úkolů pomocí BarrierTaskContext a aktivuje úlohu Horovod pomocí mpirun. Každý proces MPI Pythonu načte pickovaný uživatelský program, deserializuje ho a spustí ho.
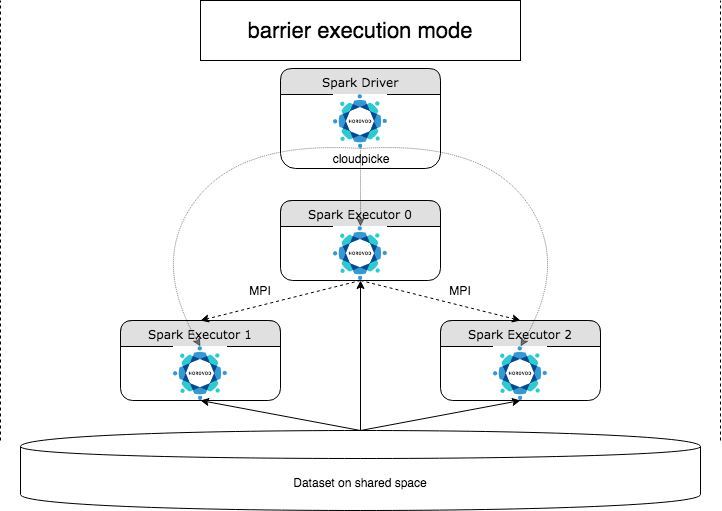
Distribuované trénování pomocí HorovodRunneru
HorovodRunner umožňuje spustit úlohy trénování Horovod jako úlohy Sparku. Rozhraní API HorovodRunner podporuje metody uvedené v tabulce. Podrobnosti najdete v dokumentaci k rozhraní API HorovodRunneru.
| Metoda a podpis | Popis |
|---|---|
init(self, np) |
Vytvořte instanci HorovodRunneru. |
run(self, main, **kwargs) |
Spusťte trénovací úlohu Horovodu, která vyvolá main(**kwargs). Hlavní funkce a argumenty klíčového slova jsou serializovány pomocí cloudpickle a distribuovány do pracovních procesů clusteru. |
Obecný přístup k vývoji distribuovaného trénovacího programu pomocí HorovodRunneru je:
HorovodRunnerVytvořte instanci inicializovanou s počtem uzlů.- Definujte metodu trénování Horovod podle metod popsaných v použití Horovod a nezapomeňte do metody přidat všechny příkazy importu.
- Předejte trénovací metodu instanci
HorovodRunner.
Příklad:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Chcete-li spustit HorovodRunner na ovladači pouze s n podprocesy, použijte hr = HorovodRunner(np=-n). Pokud je například na uzlu ovladače 4 GPU, můžete zvolit n až 4. Podrobnosti o parametru npnajdete v dokumentaci k rozhraní API HorovodRunneru. Podrobnosti o tom, jak připnout jeden GPU na podproces, najdete v průvodci používáním Horovodu.
Běžnou chybou je, že objekty TensorFlow nelze najít nebo vybrat. K tomu dochází v případě, že příkazy importu knihovny nejsou distribuovány do jiných exekutorů. Abyste se tomuto problému vyhnuli, zahrňte všechny příkazy importu (napříkladimport tensorflow as tf) do horní části metody trénování Horovod a do všech dalších uživatelem definovaných funkcí volaných v metodě trénování Horovod.
Záznam tréninku Horovod s časovou osou Horovod
Horovod má možnost zaznamenávat časovou osu své aktivity s názvem Horovod Timeline.
Důležité
Horovod Timeline má významný dopad na výkon. Pokud je povolená časová osa Horovod, může propustnost 3 snížit o ~40 %. Chcete-li urychlit úlohy HorovodRunner, nepoužívejte Horovod Timeline.
Během trénování nelze zobrazit časovou osu Horovod.
Pokud chcete zaznamenat časovou osu Horovod, nastavte HOROVOD_TIMELINE proměnnou prostředí na umístění, kam chcete soubor časové osy uložit. Databricks doporučuje použít umístění ve sdíleném úložišti, aby bylo možné soubor časové osy snadno načíst. Můžete například použít rozhraní API místních souborů DBFS, jak je znázorněno níže:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Pak na začátek a konec trénovací funkce přidejte kód specifický pro časovou osu. Následující ukázkový poznámkový blok obsahuje ukázkový kód, který můžete použít jako alternativní řešení k zobrazení průběhu trénování.
Ukázkový poznámkový blok časové osy Horovod
Pokud chcete stáhnout soubor časové osy, použijte Rozhraní příkazového řádku Databricks a pak ho chrome://tracing zobrazte pomocí zařízení prohlížeče Chrome. Příklad:
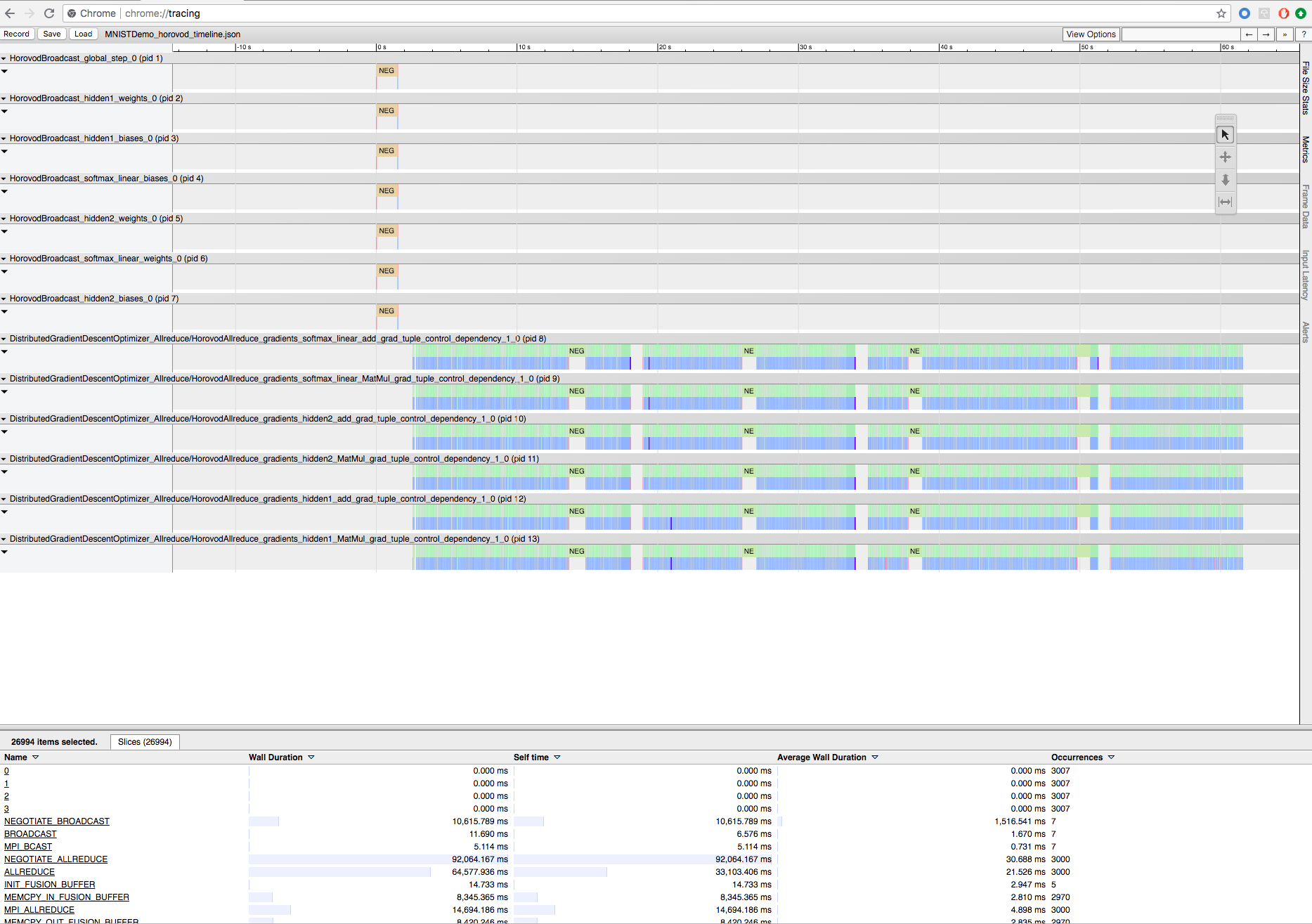
Pracovní postup vývoje
Toto jsou obecné kroky při migraci kódu hlubokého učení s jedním uzlem na distribuované trénování. Příklady: Migrace na distribuované hluboké učení pomocí HorovodRunneru v této části znázorňuje tyto kroky.
- Příprava kódu s jedním uzlem: Připravte a otestujte kód jednoho uzlu pomocí TensorFlow, Kerasu nebo PyTorchu.
- Migrace na Horovod: Postupujte podle pokynů z použití Horovod a migrujte kód pomocí Horovodu a otestujte ho na ovladači:
- Přidejte
hvd.init()k inicializaci Horovodu. - Připněte serverový GPU, který bude tento proces používat pomocí
config.gpu_options.visible_device_list. Při typickém nastavení jednoho GPU na proces se dá nastavit na místní pořadí. V takovém případě bude první proces na serveru přidělen první GPU, druhý proces bude přidělen druhý GPU atd. - Zahrňte horizontální oddíl datové sady. Tento operátor datové sady je velmi užitečný při spouštění distribuovaného trénování, protože každému pracovnímu procesu umožňuje číst jedinečnou podmnožinu.
- Škálujte rychlost učení podle počtu pracovních procesů. Efektivní velikost dávky v synchronním distribuovaném trénování se škáluje podle počtu pracovních procesů. Zvýšení rychlosti učení kompenzuje zvýšenou velikost dávky.
- Zabalte optimalizátor do
hvd.DistributedOptimizersouboru . Distribuovaný optimalizátor deleguje výpočet přechodu na původní optimalizátor, průměruje přechody pomocí allreduce nebo allgather a pak použije průměrované přechody. - Přidejte
hvd.BroadcastGlobalVariablesHook(0)do počátečních stavů proměnných vysílání z pořadí 0 do všech ostatních procesů. To je nezbytné k zajištění konzistentní inicializace všech pracovníků při zahájení trénování s náhodnými váhami nebo obnovením z kontrolního bodu. Pokud nepoužíváteMonitoredTrainingSession, můžete operaci spustithvd.broadcast_global_variablesi po inicializaci globálních proměnných. - Upravte kód tak, aby se kontrolní body ukládaly jenom na pracovní proces 0, aby je ostatní pracovníci nemohli poškodit.
- Přidejte
- Migrace na HorovodRunner: HorovodRunner spustí trénovací úlohu Horovod vyvoláním funkce Pythonu. Hlavní trénovací proceduru musíte zabalit do jedné funkce Pythonu. Pak můžete horovodRunner otestovat v místním režimu a distribuovaném režimu.
Aktualizace knihoven hlubokého učení
Pokud upgradujete nebo downgrade TensorFlow, Keras nebo PyTorch, musíte přeinstalovat Horovod, aby byl zkompilován proti nově nainstalované knihovně. Pokud například chcete upgradovat TensorFlow, databricks doporučuje použít inicializační skript z pokynů k instalaci TensorFlow a připojit následující kód instalace TensorFlow specifický pro Horovod na konec. Pokyny k instalaci horovodu vám pomůžou pracovat s různými kombinacemi, jako je upgrade nebo downgradování PyTorchu a dalších knihoven.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Příklady: Migrace do distribuovaného hlubokého učení pomocí HorovodRunneru
Následující příklady založené na datové sadě MNIST ukazují, jak migrovat program hlubokého učení s jedním uzlem do distribuovaného hlubokého učení pomocí HorovodRunneru.
- Hluboké učení s využitím TensorFlow s HorovodRunnerem pro MNIST
- Přizpůsobení PyTorchu s jedním uzlem pro distribuované hluboké učení
Omezení
- Při práci se soubory pracovního prostoru nebude HorovodRunner fungovat, pokud
npje nastavená hodnota větší než 1 a poznámkový blok importuje z jiných relativních souborů. Zvažte použití horovod.spark místoHorovodRunner. - Pokud narazíte na podobné chyby
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer, znamená to problém se síťovým komunikacem mezi uzly ve vašem clusteru. Pokud chcete tuto chybu vyřešit, přidejte do trénovacího kódu následující fragment kódu pro použití primárního síťového rozhraní.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"