Konfigurace brány AI pro koncové body pro poskytování modelů
V tomto článku se dozvíte, jak nakonfigurovat Mosaic AI Gateway na koncovém bodu pro obsluhu modelu.
Požadavky
- Pracovní prostor Databricks v oblasti, kde jsou podporovány externí modely , nebo v oblasti s podporovanou propustností .
- Model obsluhující koncový bod
- Pokud chcete vytvořit koncový bod pro externí modely, proveďte kroky 1 a 2 Vytvoření externího modelu obsluhujícího koncový bod.
- Pokud chcete vytvořit koncový bod pro zřízenou propustnost, přečtěte si téma rozhraní API základního modelu zřízené propustnosti.
Konfigurace brány AI pomocí uživatelského rozhraní
V části AI Gateway na stránce pro vytvoření koncového bodu můžete jednotlivě nakonfigurovat funkce AI Gateway. Viz Podporované funkce, které funkce jsou dostupné na externích koncových bodech modelového servisu a na koncových bodech se zajištěnou propustností.
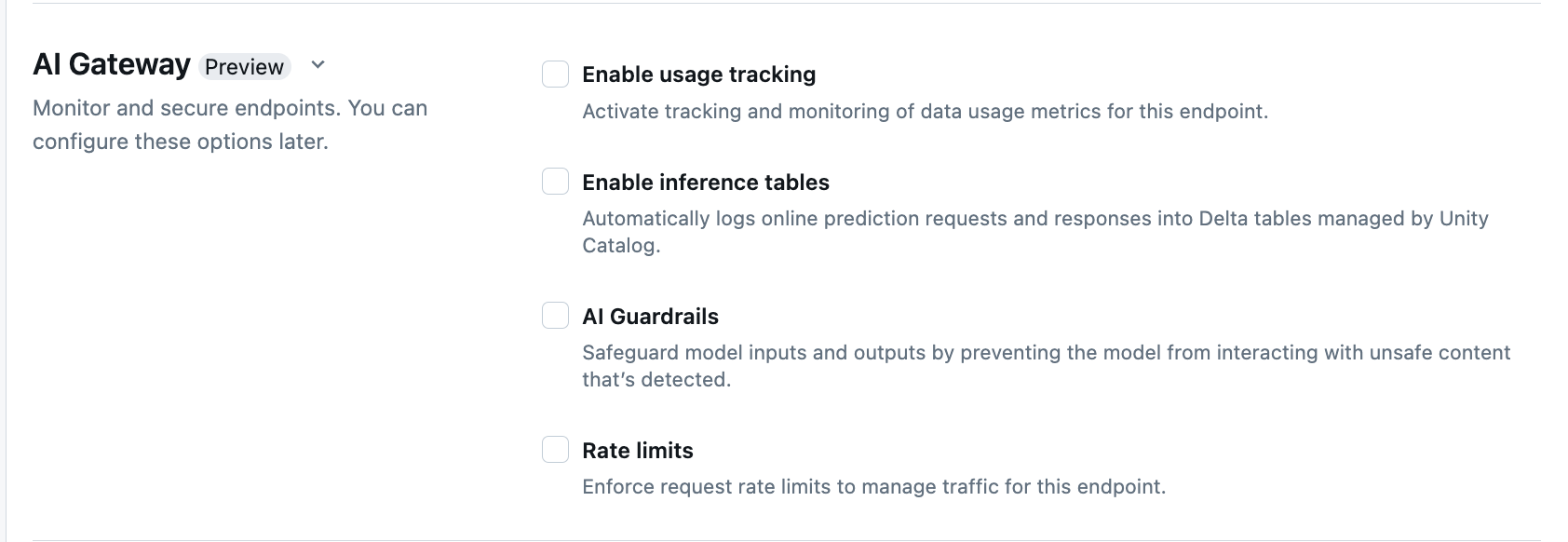
Následující tabulka shrnuje, jak nakonfigurovat AI Gateway během vytváření koncového bodu pomocí uživatelského rozhraní obsluhy. Pokud to chcete udělat programově, podívejte se na příklad poznámkového bloku.
| Funkce | Jak povolit | Detaily |
|---|---|---|
| Sledování využití | Vyberte Povolit sledování využití pro povolení sledování metrik využití dat. | – Musíte mít povolený katalog Unity. – Správci účtů musí povolit obslužné schéma systémových tabulek před použitím systémových tabulek: system.serving.endpoint_usage, která zachytává počty tokenů pro každý požadavek na koncový bod a system.serving.served_entities, který ukládá metadata pro každý základní model.– Viz schémata tabulek sledování využití – K zobrazení nebo dotazování tabulky served_entities nebo endpoint_usage tabulky mají oprávnění pouze správci účtu, i když uživatel, který spravuje koncový bod, musí povolit sledování využití. Viz Udělení přístupu k systémovým tabulkám– Počet vstupních a výstupních tokenů se odhaduje jako ( text_length+1)/4, pokud model nevrátí počet tokenů. |
| Protokolování datové části | Vyberte Povolit inferenční tabulky, aby automaticky zaznamenávaly požadavky a odpovědi z vašeho koncového bodu do Delta tabulek spravovaných katalogem Unity. | – Musíte mít povolený katalog Unity a přístup CREATE_TABLE ve zadaném schématu katalogu.- Inference tabulky podporované službou AI Gateway mají jiné schéma než inference tabulky vytvořené pro koncové body, které obsluhují vlastní modely. Viz schéma tabulky odvození s podporou AI Gateway. Data záznamu zátěže naplní tyto tabulky méně než hodinu po dotazování na koncový bod. – Datové části větší než 1 MB nejsou zaznamenány. – Datová část odpovědi agreguje odpověď všech vrácených bloků dat. – Streamování se podporuje. Ve scénářích streamování datový obsah odpovědi agreguje odpovědi z jednotlivých vrácených bloků. |
| Ochranná opatření AI | Viz Konfigurace mantinelí AI v uživatelském rozhraní. | - Mantinely brání modelu v interakci s nebezpečným a škodlivým obsahem, který je zjištěn ve vstupech a výstupech modelu. – Výstupní mantinely nejsou podporovány pro modely vkládání ani pro streamování. |
| Omezení přenosové rychlosti | Vyberte omezení rychlosti, pokud chcete vynutit omezení rychlosti požadavků, které spravují provoz pro váš koncový bod na základě jednotlivých uživatelů a koncových bodů. | – Omezení rychlosti se definují v dotazech za minutu (QPM). – Výchozí hodnota je bez omezení pro jednotlivé uživatele i koncové body. |
| Rozdělení provozu | V části Obsluhované entity zadejte procento provozu, chcete směrovat na konkrétní modely. Pokud chcete nakonfigurovat rozdělení provozu v koncovém bodu prostřednictvím kódu programu, přečtěte si téma Obsluha více externích modelů do koncového bodu. |
- Pokud chcete směrovat veškerý provoz do konkrétního modelu, nastavte ho na 100%. - Pokud chcete zadat náhradní model, přidejte ho do koncového bodu a nastavte jeho procento provozu na 0%. – Pokud chcete vyrovnávat zatížení provozu mezi modely a nastavit náhradní provoz, můžete očekávat následující chování: – Požadavky se náhodně rozdělí mezi entity na základě přiřazených procent provozu. – Pokud požadavek dosáhne první entity a selže, vrátí se k další entitě v pořadí, v jakém byly obsluhované entity uvedeny během vytváření koncového bodu nebo nejnovější aktualizace koncového bodu. - Rozdělení provozu nemá vliv na pořadí náhradních pokusů. |
| Záložní možnosti | V části Brána AI vyberte Povolit záložní řešení a odeslat žádost na jiné obsluhované modely na koncovém bodu jako záložní řešení. | – Pokud počáteční požadavek směrovaný na určitou entitu vrátí chybu 429 nebo 5XX, požadavek se vrátí k další entitě uvedené v koncovém bodu.– Pořadí, ve kterém se požadavky přesměrují na náhradní obsluhované entity, závisí na pořadí, ve kterém jsou modely uvedeny během vytváření koncového bodu nebo nejnovější aktualizace koncového bodu. Procento provozu nemá vliv na pořadí náhradních pokusů posílaných do obsluhovaných entit. - Náhradní možnosti jsou podporovány pouze pro externí modely. – Před povolením přepnutí na externí modely je nutné přiřadit procenta provozu jiným modelům obsluhovaným na koncovém bodu. – Jakýkoli externí model přiřazeném 0% provozu funguje výhradně jako záložní model. - Můžete mít maximálně dvě náhradní. – Každá entita se pokusí jednou v sekvenčním pořadí, dokud požadavek nebude úspěšný. Pokud se všechny uvedené entity vyzkoušely bez úspěchu, požadavek selže. – První úspěšný nebo poslední neúspěšný pokus o odeslání požadavku a jeho odpověď se zaznamenávají jak do tabulek sledování využití, tak i do tabulek záznamu datové části. |
Následující diagram znázorňuje příklad, kde:
- Na koncovém bodu pro nasazení modelu jsou obsluhovány tři entity.
- Žádost je původně směrována na Obsluhovaná entita 3.
- Pokud požadavek vrátí odpověď 200, požadavek byl úspěšný u obsluhované entity 3 a požadavek a jeho odpověď se zaprotokolují do tabulek protokolování využití a datové části koncového bodu.
- Pokud požadavek vrátí chybu 429 nebo 5xx u obsluhované entity 3, požadavek se vrátí k další obsluhované entitě v koncovém bodu Obsluhovaná entita 1.
- Pokud požadavek vrátí chybu 429 nebo 5xx u obsluhované entity 1, požadavek se vrátí k další obsluhované entitě v koncovém bodu Obsluhovaná entita 2.
- Pokud požadavek vrátí chybu 429 nebo 5xx u entity Obsluhovaná entita 2, požadavek selže, protože tento počet představuje maximální množství záložních entit. Neúspěšný požadavek a chyba odpovědi jsou zaznamenány do tabulek pro sledování využití a uživatelská data.
příklad 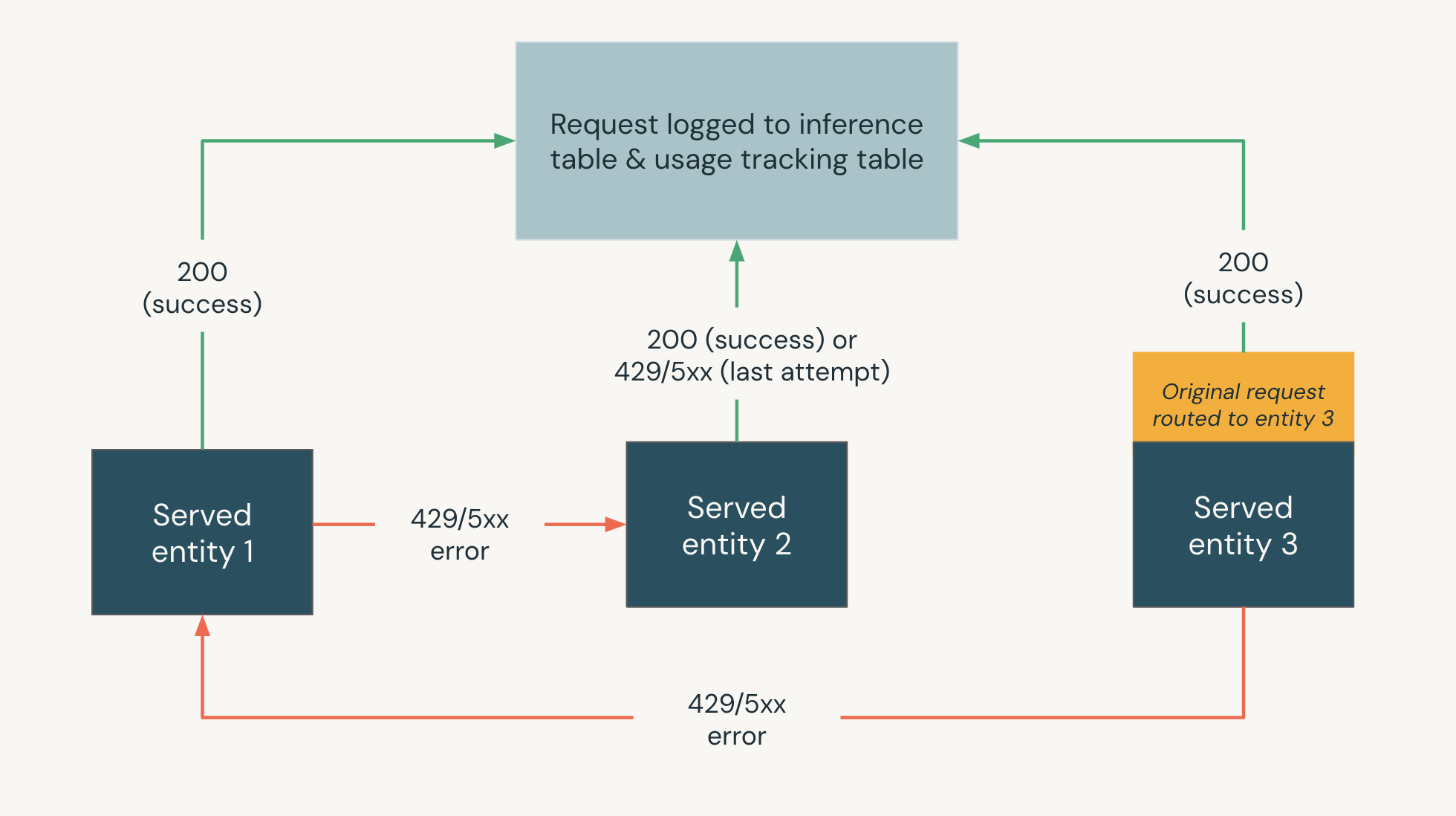
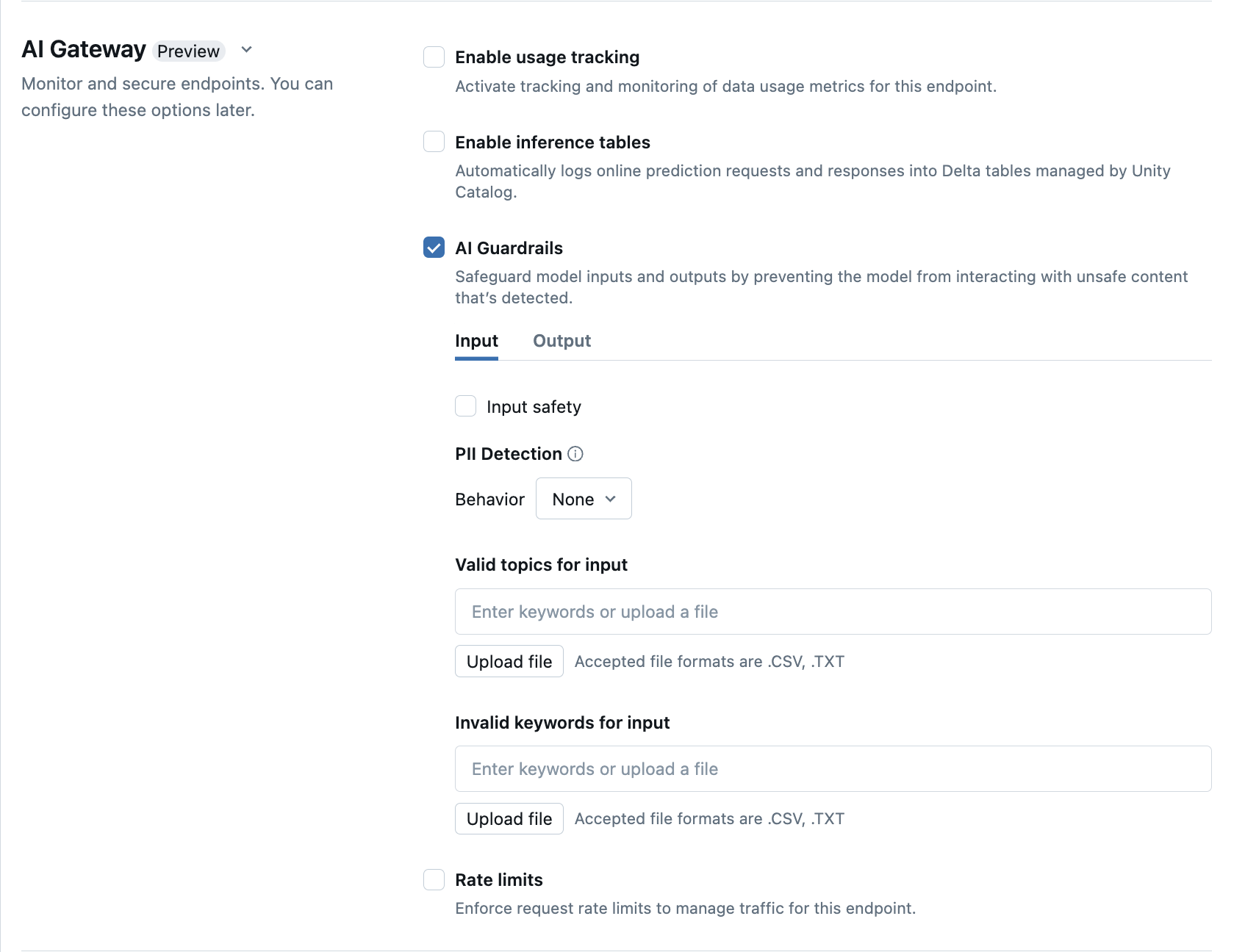
Konfigurace mantinely AI v uživatelském rozhraní
Následující tabulka ukazuje, jak nakonfigurovat mantinely podporované .
| Zábradlí | Jak povolit | Detaily |
|---|---|---|
| Bezpečnost | Vyberte Bezpečnostní a povolte tak ochranu, abyste zabránili vašemu modelu v interakci s nebezpečným a škodlivým obsahem. | |
| Detekce identifikovatelných osobních údajů (PII) | Vyberte zjišťování PII a detekujte data PII, jako jsou jména, adresy, čísla platebních karet. | |
| Platná témata | Témata můžete zadat přímo do tohoto pole. Pokud máte více položek, nezapomeňte po každém tématu stisknout klávesu Enter. Alternativně můžete nahrát .csv soubor nebo .txt soubor. |
Lze zadat maximálně 50 platných témat. Každé téma nesmí překročit 100 znaků. |
| Neplatná klíčová slova | Témata můžete zadat přímo do tohoto pole. Pokud máte více položek, nezapomeňte po každém tématu stisknout klávesu Enter. Alternativně můžete nahrát .csv soubor nebo .txt soubor. |
Lze zadat maximálně 50 neplatných klíčových slov. Každé klíčové slovo nesmí překročit 100 znaků. |
schémata tabulek sledování využití
Následující části shrnují schémata tabulek sledování využití pro systémové tabulky system.serving.served_entities a system.serving.endpoint_usage.
system.serving.served_entities schéma tabulky sledování využití
Tabulka systému sledování využití system.serving.served_entities má následující schéma:
| Název sloupce | Popis | Typ |
|---|---|---|
served_entity_id |
Jedinečné ID obsluhované entity. | STRING |
account_id |
ID účtu zákazníka pro Delta Sharing. | STRING |
workspace_id |
ID pracovního prostoru zákazníka pro obsluhující koncový bod. | STRING |
created_by |
ID tvůrce. | STRING |
endpoint_name |
Název obslužného koncového bodu. | STRING |
endpoint_id |
Jedinečné ID koncového bodu obsluhy. | STRING |
served_entity_name |
Název obsluhované entity. | STRING |
entity_type |
Typ entity, která se obsluhuje. Může to být FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODELnebo CUSTOM_MODEL |
STRING |
entity_name |
Základní název entity. Liší se od served_entity_name uživatelského zadaného jména. Například entity_name je název modelu katalogu Unity. |
STRING |
entity_version |
Verze obsluhované entity. | STRING |
endpoint_config_version |
Verze konfigurace koncového bodu. | INT |
task |
Typ úkolu. Může být llm/v1/chat, llm/v1/completionsnebo llm/v1/embeddings. |
STRING |
external_model_config |
Konfigurace pro externí modely Například {Provider: OpenAI} |
STRUKTURA |
foundation_model_config |
Konfigurace základních modelů Například{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
Struktura |
custom_model_config |
Konfigurace pro vlastní modely Například{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Konfigurace pro specifikace funkcí Například { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Časové razítko změny pro obsluhovanou entitu. | ČASOVÉ RAZÍTKO |
endpoint_delete_time |
Časové razítko odstranění entity Koncový bod je kontejner pro obsluhované entity. Po odstranění koncového bodu se také obsluhovaná entita odstraní. | ČASOVÉ RAZÍTKO |
system.serving.endpoint_usage schéma tabulky sledování využití
Tabulka systému sledování využití system.serving.endpoint_usage má následující schéma:
| Název sloupce | Popis | Typ |
|---|---|---|
account_id |
ID účtu zákazníka. | STRING |
workspace_id |
ID pracovního prostoru zákazníka pro služební koncový bod. | STRING |
client_request_id |
Identifikátor požadavku poskytnutý uživatelem, který lze specifikovat v těle požadavku na obsluhu modelu. | STRING |
databricks_request_id |
Identifikátor požadavku vygenerovaný službou Azure Databricks připojený ke všem žádostem obsluhující model | STRING |
requester |
ID uživatele nebo služebního hlavního objektu, jehož oprávnění se používají k vyvolání požadavku servisního koncového bodu. | STRING |
status_code |
Stavový kód HTTP vrácený z modelu. | CELÉ ČÍSLO |
request_time |
Časové razítko, kdy je požadavek přijat. | ČASOVÉ RAZÍTKO |
input_token_count |
Počet tokenů vstupu. | DLOUHÝ |
output_token_count |
Počet tokenů výstupu. | DLOUHÝ |
input_character_count |
Počet znaků vstupního řetězce nebo podnětu. | DLOUHÝ |
output_character_count |
Počet znaků výstupního řetězce odpovědi. | DLOUHÝ |
usage_context |
Uživatel poskytl mapu obsahující identifikátory koncového uživatele nebo aplikace zákazníka, která provádí volání koncového bodu. Viz Další definování využití s usage_context. |
MAPA |
request_streaming |
Určuje, jestli je požadavek v režimu streamu. | BOOLEOVSKÝ |
served_entity_id |
Jedinečné ID použité pro spojení s tabulkou dimenzí system.serving.served_entities k vyhledání informací o koncovém bodu a obsluhované entitě. |
STRING |
Další definování využití s využitím usage_context
Při dotazování externího modelu s povoleným sledováním využití můžete zadat usage_context parametr s typem Map[String, String]. Mapování kontextu využití se zobrazí v tabulce sledování využití ve sloupci usage_context. Velikost usage_context mapy nesmí překročit 10 KiB.
Správci účtů můžou agregovat různé řádky na základě kontextu využití, aby získali přehledy a mohli tyto informace spojit s informacemi v tabulce protokolování datové části. Můžete například přidat end_user_to_charge do usage_context pro sledování nákladů a připsání pro koncové uživatele.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Aktualizace funkcí služby AI Gateway na koncových bodech
Funkce služby AI Gateway můžete aktualizovat u modelů obsluhujících koncové body, které byly dříve povolené, a koncových bodů, které nebyly povolené. Instalace aktualizací konfigurace AI Gateway trvá přibližně 20 až 40 sekund, ale omezování rychlosti aktualizací může trvat až 60 sekund.
Následující příklad ukazuje, jak aktualizovat funkce brány AI v modelu obsluhující koncový bod pomocí uživatelského rozhraní obsluhy.
Na stránce koncového bodu v části Brána můžete vidět, které funkce jsou povolené. Chcete-li tyto funkce aktualizovat, klikněte na Upravit AI bránu.

Příklad poznámkového bloku
Následující poznámkový blok ukazuje, jak programově povolit a používat funkce brány Databricks Mosaic AI ke správě a řízení modelů od poskytovatelů. Podrobnosti o rozhraní REST API najdete v PUT /api/2.0/serving-endpoints/{name}/ai- gateway.
Povolit funkce brány Databricks Mosaic AI v poznámkovém bloku
Pořiďte si poznámkový blok