Přírůstkové načítání dat z více tabulek v SQL Serveru do databáze ve službě Azure SQL Database pomocí webu Azure Portal
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V tomto kurzu vytvoříte Službu Azure Data Factory s kanálem, který načítá rozdílová data z více tabulek v databázi SQL Serveru do databáze v Azure SQL Database.
V tomto kurzu provedete následující kroky:
- Příprava zdrojového a cílového datového úložiště
- Vytvoření datové továrny
- Vytvořte místní prostředí Integration Runtime.
- Instalace prostředí Integration Runtime
- Vytvoření propojených služeb
- Vytvoření zdroje, jímky a datových sad mezí
- Vytvoření a spuštění kanálu a jeho monitorování
- Zkontrolujte výsledky.
- Přidání nebo aktualizace dat ve zdrojových tabulkách
- Opakované spuštění kanálu a jeho monitorování
- Kontrola konečných výsledků
Přehled
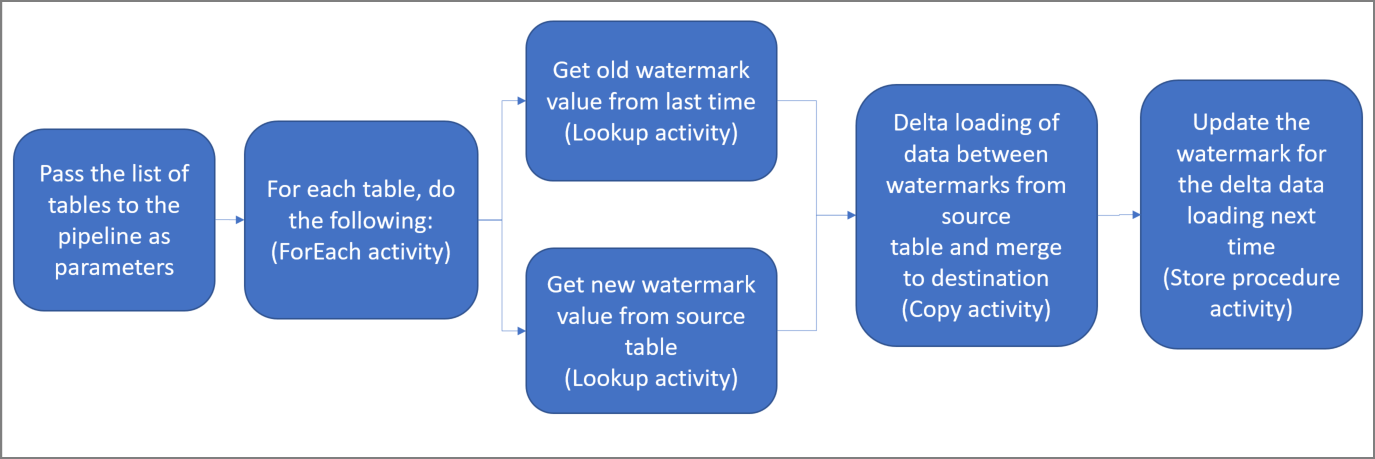
Tady jsou důležité kroky pro vytvoření tohoto řešení:
Vyberte sloupec meze.
Ve zdrojovém úložišti dat vyberte pro každou tabulku jeden sloupec, který je možné použít k identifikaci nových nebo aktualizovaných záznamů pro každé spuštění. Data v tomto vybraném sloupci (například čas_poslední_změny nebo ID) se při vytváření nebo aktualizaci řádků obvykle zvyšují. Maximální hodnota v tomto sloupci se používá jako horní mez.
Připravte úložiště dat pro uložení hodnoty meze.
V tomto kurzu uložíte hodnotu meze do databáze SQL.
Vytvořte kanál s následujícími aktivitami:
a. Vytvořte aktivitu ForEach, která prochází seznam názvů zdrojových tabulek, který je předaný kanálu jako parametr. Pro každou zdrojovou tabulku vyvolá následující aktivity, aby pro tabulku provedl rozdílové načtení.
b. Vytvořte dvě aktivity vyhledávání. První aktivitu vyhledávání použijte k načtení poslední hodnoty meze. Druhou aktivitu vyhledávání použijte k načtení nové hodnoty meze. Tyto hodnoty meze se předají aktivitě kopírování.
c. Vytvořte aktivitu kopírování, která ze zdrojového úložiště dat zkopíruje řádky, které ve sloupci horní meze mají hodnotu vyšší, než je stará hodnota meze, a nižší, než je nová hodnota meze. Potom tato rozdílová data zkopíruje ze zdrojového úložiště dat do úložiště Azure Blob Storage jako nový soubor.
d. Vytvořte aktivitu uložené procedury StoredProcedure, která aktualizuje hodnotu meze pro příští spuštění kanálu.
Tady je souhrnný diagram tohoto řešení:
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- SQL Server. Jako zdrojové úložiště dat v tomto kurzu použijete databázi SQL Serveru.
- Azure SQL Database Jako úložiště dat jímky použijete databázi ve službě Azure SQL Database. Pokud databázi nemáte ve službě SQL Database, přečtěte si téma Vytvoření databáze ve službě Azure SQL Database , kde najdete postup jeho vytvoření.
Vytvoření zdrojových tabulek v databázi SQL Serveru
Otevřete SQL Server Management Studio a připojte se k databázi SQL Serveru.
V Průzkumníku serveru klikněte pravým tlačítkem na databázi a zvolte Nový dotaz.
Spusťte na databázi následující příkaz SQL, aby se vytvořily tabulky s názvem
customer_tableaproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Vytvoření cílových tabulek v databázi
Otevřete APLIKACI SQL Server Management Studio a připojte se k databázi ve službě Azure SQL Database.
V Průzkumníku serveru klikněte pravým tlačítkem na databázi a zvolte Nový dotaz.
Spusťte na databázi následující příkaz SQL, aby se vytvořily tabulky s názvem
customer_tableaproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Vytvoření další tabulky v databázi pro uložení hodnoty horní meze
Spuštěním následujícího příkazu SQL pro vaši databázi vytvořte tabulku s názvem
watermarktablepro uložení hodnoty meze:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Do tabulky mezí vložte hodnoty počátečních mezí pro obě zdrojové tabulky.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Vytvoření uložené procedury v databázi
Spuštěním následujícího příkazu vytvořte uloženou proceduru v databázi. Tato uložená procedura aktualizuje hodnotu meze po každém spuštění kanálu.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Vytvoření datových typů a dalších uložených procedur v databázi
Spuštěním následujícího dotazu vytvořte ve své databázi dvě uložené procedury a dva datové typy. Slouží ke slučování dat ze zdrojových tabulek do cílových tabulek.
Abychom mohli snadno začít, použijeme tyto uložené procedury, které předávají rozdílová data prostřednictvím proměnné tabulky, a pak je sloučíme do cílového úložiště. Buďte opatrní, že neočekává, že se v proměnné tabulky uloží "velký" počet rozdílových řádků (více než 100).
Pokud potřebujete sloučit velký počet rozdílových řádků do cílového úložiště, doporučujeme použít aktivitu kopírování ke zkopírování všech rozdílových dat do dočasné "přípravné" tabulky v cílovém úložišti a pak vytvořit vlastní uloženou proceduru bez použití proměnné tabulky ke sloučení z "přípravné" tabulky do "konečné" tabulky.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Vytvoření datové továrny
Spusťte webový prohlížeč Microsoft Edge nebo Google Chrome. Uživatelské rozhraní služby Data Factory podporují v současnosti jenom webové prohlížeče Microsoft Edge a Google Chrome.
V nabídce vlevo vyberte Vytvořit službu Data Factory pro integraci>prostředků>:
Na stránce Nová datová továrna jako název zadejte ADFMultiIncCopyTutorialDF.
Název služby Azure Data Factory musí být globálně jedinečný. Pokud se zobrazí červený vykřičník s následující chybou, změňte název datové továrny (například na vaše_jméno_ADFIncCopyTutorialDF) a zkuste to znovu. Pravidla pojmenování artefaktů služby Data Factory najdete v článku Data Factory – pravidla pojmenování.
Data factory name "ADFIncCopyTutorialDF" is not availableVyberte své předplatné Azure, ve kterém chcete vytvořit datovou továrnu.
Pro Skupinu prostředků proveďte jeden z následujících kroků:
- Vyberte Použít existující a z rozevíracího seznamu vyberte existující skupinu prostředků.
- Vyberte Vytvořit novou a zadejte název skupiny prostředků.
Informace o skupinách prostředků najdete v článku Použití skupin prostředků ke správě prostředků Azure.
Jako verzi vyberte V2.
Vyberte umístění pro objekt pro vytváření dat. V rozevíracím seznamu se zobrazí pouze podporovaná umístění. Úložiště dat (Azure Storage, Azure SQL Database atd.) a výpočetní prostředí (HDInsight atd.) používané datovou továrnou mohou být v jiných oblastech.
Klikněte na Vytvořit.
Po vytvoření se zobrazí stránka Datová továrna, jak je znázorněno na obrázku.

Výběrem možnosti Otevřít na dlaždici Otevřít Azure Data Factory Studio spusťte uživatelské rozhraní (UI) služby Azure Data Factory na samostatné kartě.
Vytvoření místního prostředí Integration Runtime
Vzhledem k tomu, že přesouváte data z úložiště dat v privátní síti (v místním prostředí) do úložiště dat Azure, nainstalujte do svého místního prostředí místní prostředí Integration Runtime (IR). Místní prostředí IR přesouvá data mezi privátní sítí a Azure.
Na domovské stránce uživatelského rozhraní služby Azure Data Factory vyberte v levém podokně kartu Spravovat.
V levém podokně vyberte Prostředí Integration Runtime a pak vyberte +Nový.
V okně Instalace prostředí Integration Runtime vyberte Provést přesun dat a odesílání aktivit do externích výpočetních prostředků a klikněte na pokračovat.
Vyberte možnost V místním prostředí a klikněte na Pokračovat.
Jako název zadejte mySelfHostedIR a klikněte na Vytvořit.
Klikněte na text Kliknutím sem spustíte expresní instalaci pro tento počítač v části Možnost 1: Expresní instalace.
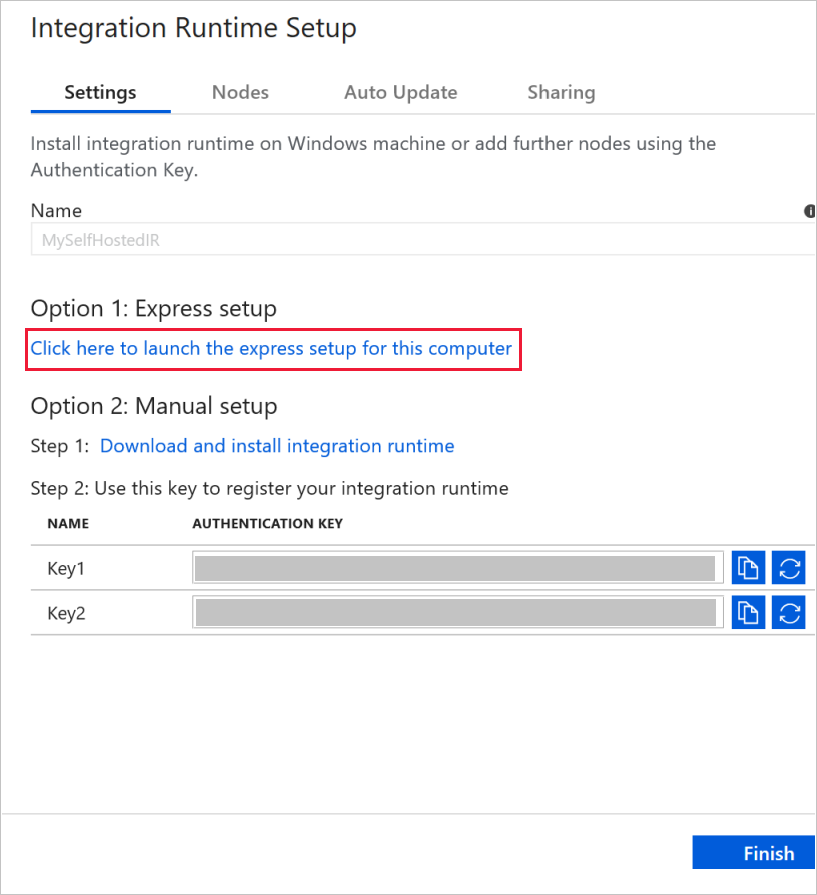
V okně Expresní instalace Integration Runtime (v místním prostředí) klikněte na Zavřít.
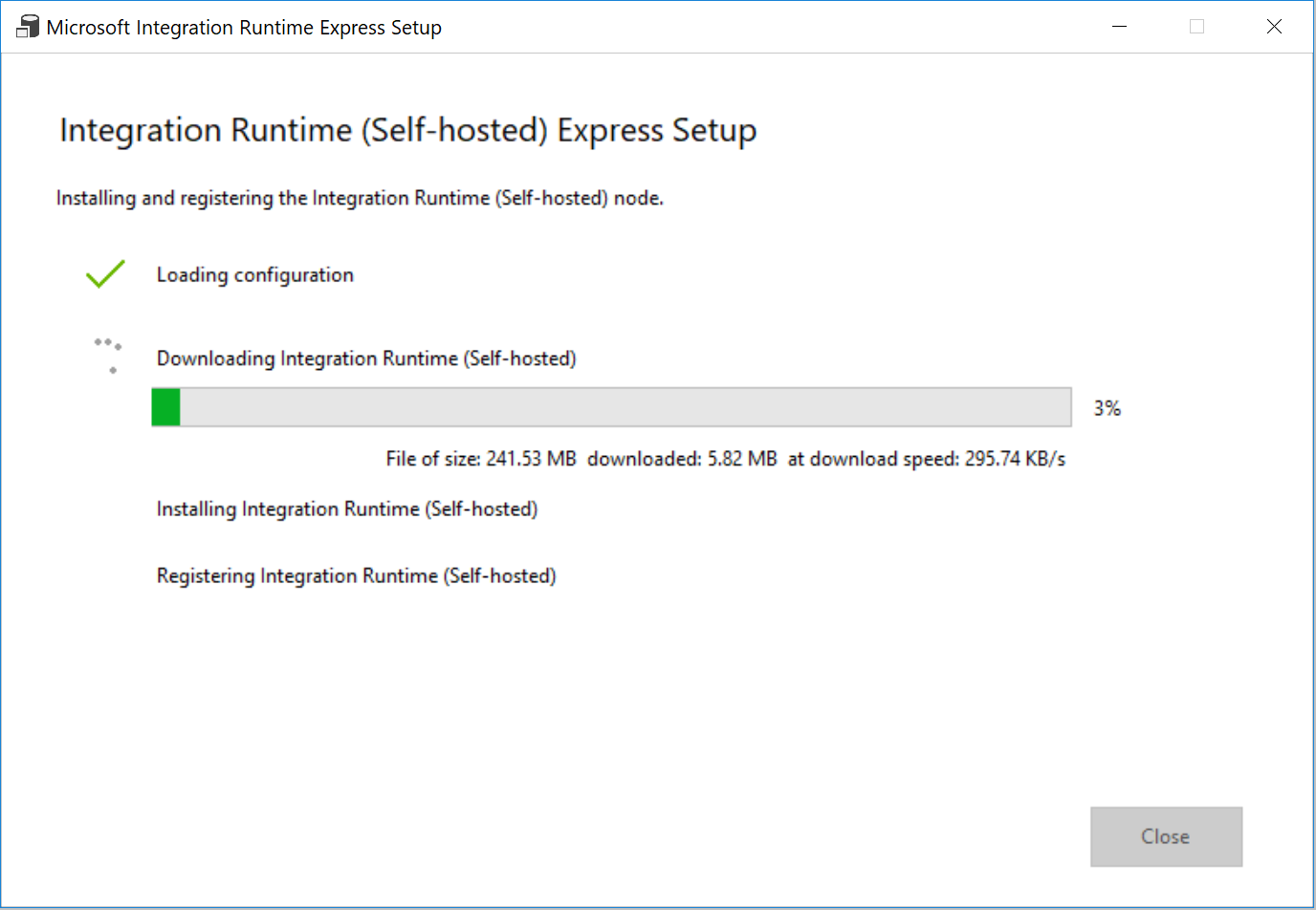
V okně Instalace prostředí Integration Runtime ve webovém prohlížeči klikněte na Dokončit.
Zkontrolujte, že se v seznamu prostředí Integration Runtime zobrazuje MySelfHostedIR.
Vytvoření propojených služeb
V datové továrně vytvoříte propojené služby, abyste svá úložiště dat a výpočetní služby spojili s datovou továrnou. V této části vytvoříte propojené služby s databází SQL Serveru a databází ve službě Azure SQL Database.
Vytvoření propojené služby SQL Serveru
V tomto kroku propočítáte databázi SQL Serveru s datovnou továrnou.
V okně Připojení přepněte z karty Prostředí Integration Runtime na kartu Propojené služby a klikněte na + Nová.
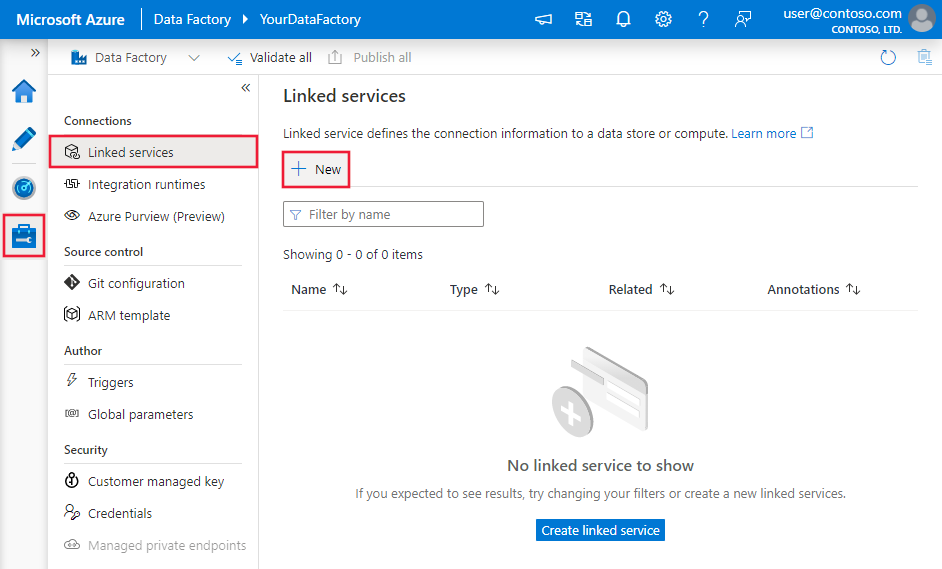
V okně Nová propojená služba vyberte SQL Server a klikněte na Pokračovat.
V okně Nová propojená služba proveďte následující kroky:
- Jako Název zadejte SqlServerLinkedService.
- V části Připojit prostřednictvím prostředí Integration Runtime zadejte MySelfHostedIR. Toto je důležitý krok. Výchozí prostředí Integration Runtime se nemůže připojit k místnímu úložišti dat. Použijte místní prostředí Integration Runtime, které jste vytvořili dříve.
- Jako Název serveru zadejte název vašeho počítače, který obsahuje databázi SQL Serveru.
- Jako Název databáze zadejte název databáze ve vašem SQL Serveru, která obsahuje zdrojová data. Tabulku jste vytvořili a do této databáze jste vložili data jako součást požadavků.
- Jako Typ ověřování vyberte typ ověřování, který chcete použít pro připojení k databázi.
- Jako Uživatelské jméno zadejte jméno uživatele, který má přístup k této databázi SQL Serveru. Pokud v názvu uživatelského účtu nebo serveru potřebujete použít znak lomítko (
\), použijte řídicí znak (\). Příklad:mydomain\\myuser. - Jako Heslo zadejte heslo pro tohoto uživatele.
- Pokud chcete otestovat, jestli se služba Data Factory může připojit k vaší databázi SQL Serveru, klikněte na Test připojení. Opravte všechny chyby, dokud připojení nebude úspěšné.
- Chcete-li propojenou službu uložit, klikněte na tlačítko Dokončit.
Vytvoření propojené služby Azure SQL Database
V posledním kroku vytvoříte propojenou službu, která propojí vaši zdrojovou databázi SQL Serveru s datovou továrnou. V tomto kroku propojíte cílovou databázi nebo databázi jímky s datovou továrnou.
V okně Připojení přepněte z karty Prostředí Integration Runtime na kartu Propojené služby a klikněte na + Nová.
V okně Nová propojená služba vyberte Azure SQL Database a klikněte na Pokračovat.
V okně Nová propojená služba proveďte následující kroky:
- Jako Název zadejte AzureSqlDatabaseLinkedService.
- Jako název serveru vyberte název serveru z rozevíracího seznamu.
- Jako název databáze vyberte databázi, ve které jste vytvořili customer_table, a project_table jako součást požadavků.
- Do pole Uživatelské jméno zadejte jméno uživatele, který má přístup k databázi.
- Jako Heslo zadejte heslo pro tohoto uživatele.
- Pokud chcete otestovat, jestli se služba Data Factory může připojit k vaší databázi SQL Serveru, klikněte na Test připojení. Opravte všechny chyby, dokud připojení nebude úspěšné.
- Chcete-li propojenou službu uložit, klikněte na tlačítko Dokončit.
Zkontrolujte, že se v seznamu zobrazují dvě propojené služby.
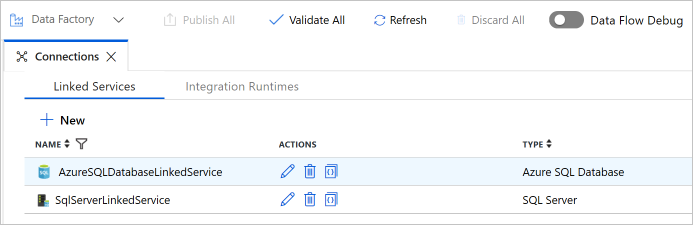
Vytvoření datových sad
V tomto kroku vytvoříte datové sady, které představují zdroj dat, cíl dat a místo pro uložení hodnoty meze.
Vytvoření zdrojové datové sady
V levém podokně klikněte na symbol + (plus) a pak klikněte na Datová sada.
V okně Nová datová sada vyberte SQL Server a klikněte na Pokračovat.
Ve webovém prohlížeči se otevře nová karta, na které můžete datovou sadu konfigurovat. Zobrazí se také datová sada ve stromovém zobrazení. Na kartě Obecné v dolní části okna Vlastnosti jako Název zadejte SourceDataset.
V okně Vlastnosti přepněte na kartu Připojení a jako Propojená služba vyberte SqlServerLinkedService. Tabulku tady nevybíráte. Aktivita kopírování v kanálu používá místo načtení celé tabulky dotaz SQL pro načtení dat.
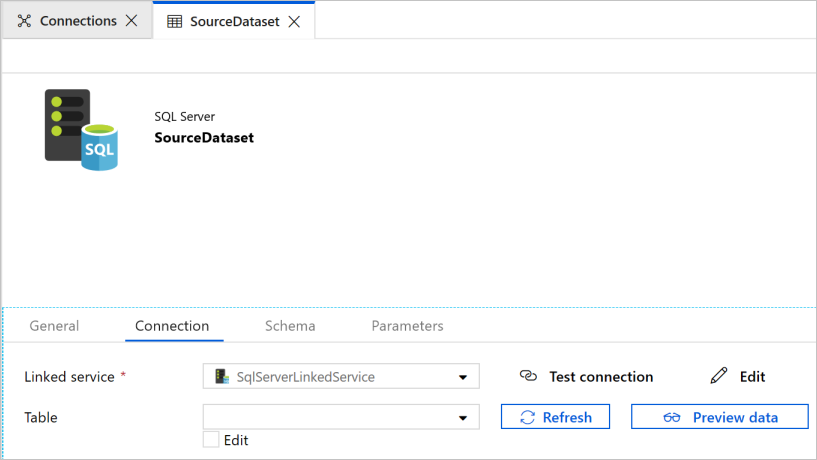
Vytvoření datové sady jímky
V levém podokně klikněte na symbol + (plus) a pak klikněte na Datová sada.
V okně Nová datová sada vyberte Azure SQL Database a klikněte na Pokračovat.
Ve webovém prohlížeči se otevře nová karta, na které můžete datovou sadu konfigurovat. Zobrazí se také datová sada ve stromovém zobrazení. Na kartě Obecné v dolní části okna Vlastnosti jako Název zadejte SinkDataset.
V okně Vlastnosti přepněte na kartu Parametry a proveďte následující kroky:
V části Vytvořit nebo aktualizovat parametry klikněte na Nový.
Jako název zadejte SinkTableName a jako typ zadejte Řetězec. Tato datová sada jako parametr přijímá SinkTableName. Parametr SinkTableName nastavuje kanál dynamicky za běhu. Aktivita ForEach v kanálu prochází seznam názvů tabulek a při každé iteraci předává název tabulky této datové sadě.
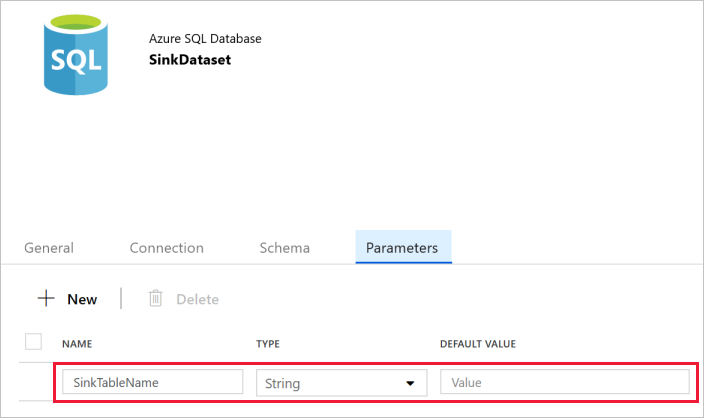
Přejděte na kartu Připojení v okno Vlastnosti a vyberte AzureSqlDatabaseLinkedService pro propojenou službu. U vlastnosti Tabulka klikněte na Přidat dynamický obsah.
V okně Přidat dynamický obsah vyberte SinkTableName v části Parametry .
Po kliknutí na Dokončit se zobrazí "@dataset(). SinkTableName jako název tabulky.
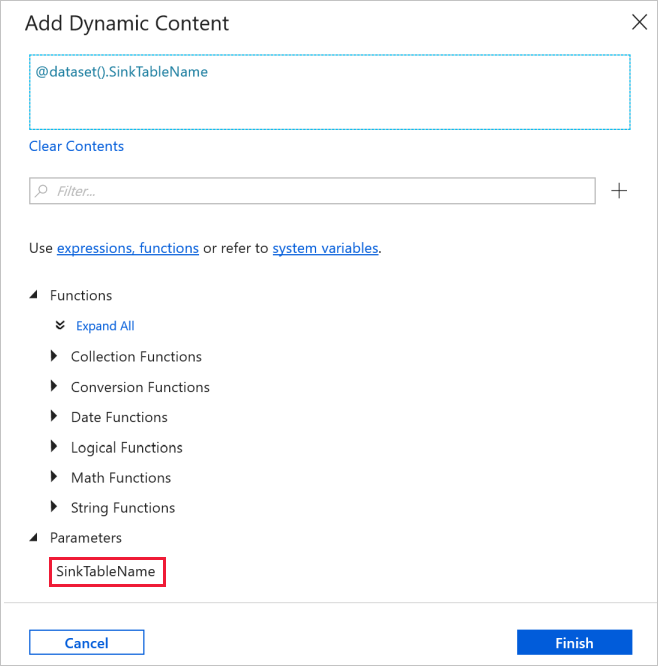
Vytvoření datové sady pro mez
V tomto kroku vytvoříte datovou sadu pro uložení hodnoty horní meze.
V levém podokně klikněte na symbol + (plus) a pak klikněte na Datová sada.
V okně Nová datová sada vyberte Azure SQL Database a klikněte na Pokračovat.
Na kartě Obecné v dolní části okna Vlastnosti jako Název zadejte WatermarkDataset.
Přepněte na kartu Připojení a proveďte následující kroky:
Jako Propojená služba vyberte AzureSqlDatabaseLinkedService.
Jako Tabulka vyberte [dbo].[watermarktable].
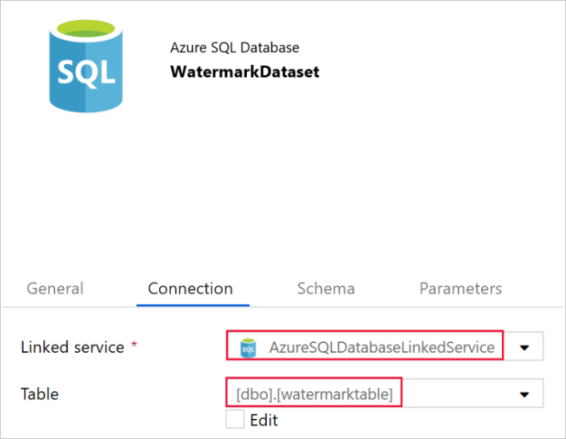
Vytvořit kanál
Tento kanál dostává jako parametr seznam tabulek. Aktivita ForEach prochází seznam názvů tabulek a provádí následující operace:
Použije aktivitu vyhledávání k načtení původní hodnoty meze (počáteční hodnota nebo hodnota použitá v poslední iteraci).
Použije aktivitu vyhledávání k načtení nové hodnoty meze (maximální hodnota sloupce mezí ve zdrojové tabulce).
Použije aktivitu kopírování ke kopírování dat, která leží mezi těmito dvěma hodnotami mezí, ze zdrojové databáze do cílové databáze.
Použije aktivitu uložené procedury StoredProcedure k aktualizaci staré hodnoty meze, která se má použít v prvním kroku další iterace.
Vytvoření kanálu
V levém podokně klikněte na symbol + (plus) a pak klikněte na Kanál.
Na panelu Obecné v části Vlastnosti zadejte IncrementalCopyPipeline pro Název. Potom panel sbalte kliknutím na ikonu Vlastnosti v pravém horním rohu.
Na kartě Parametry proveďte následující kroky:
- Klikněte na + Nový.
- Jano název parametru zadejte tableList.
- Vyberte pole pro typ parametru.
V sadě nástrojů Aktivity rozbalte Iterace a podmíněné výrazy a přetáhněte aktivitu ForEach na plochu návrháře kanálu. Na kartě Obecné v okně Vlastnosti jako název zadejte IterateSQLTables.
Přepněte na kartu Nastavení a jako Položky zadejte
@pipeline().parameters.tableList. Aktivita ForEach prochází seznam tabulek a provádí operaci přírůstkového kopírování.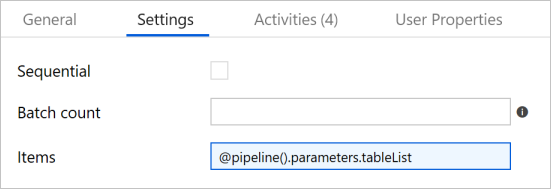
Pokud ještě není vybraná, vyberte v kanálu aktivitu ForEach. Klikněte na tlačítko Upravit (ikona tužky).
V sadě nástrojů Aktivity rozbalte Obecné a přetáhněte aktivitu Vyhledávání na plochu návrháře kanálu. Pak jako Název zadejte LookupOldWaterMarkActivity.
V okně Vlastnosti přepněte na kartu Nastavení a proveďte následující kroky:
Jako Zdrojová datová sada vyberte WatermarkDataset.
Jako Použít dotaz vyberte Dotaz.
Jako Dotaz zadejte následující příkaz jazyka SQL.
select * from watermarktable where TableName = '@{item().TABLE_NAME}'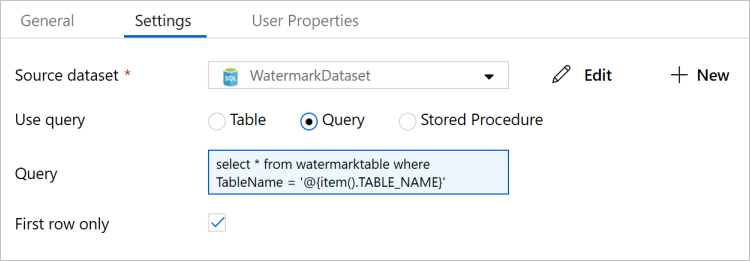
Z panelu nástrojů Aktivity přetáhněte aktivitu Vyhledávání a jako Název zadejte LookupNewWaterMarkActivity.
Přepněte na kartu Nastavení.
Jako Zdrojová datová sada vyberte SourceDataset.
Jako Použít dotaz vyberte Dotaz.
Jako Dotaz zadejte následující příkaz jazyka SQL.
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}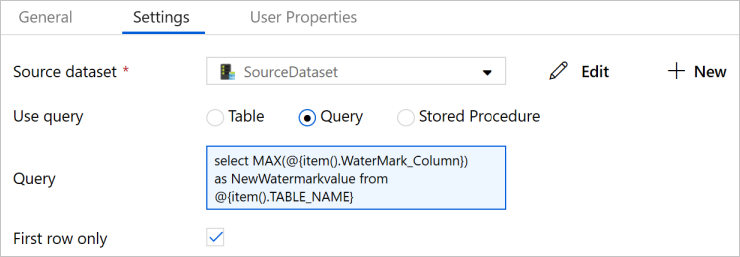
Z panelu nástrojů Aktivity přetáhněte aktivitu Kopírování a jako Název zadejte IncrementalCopyActivity.
Jednu po druhé propojte aktivity vyhledávání s aktivitou kopírování. Propojte je tak, že začnete přetahovat zelené pole připojené k aktivitě vyhledávání a přemístíte ho na aktivitu kopírování. Jakmile se barva ohraničení aktivity kopírování změní na modrou, uvolněte tlačítko myši.
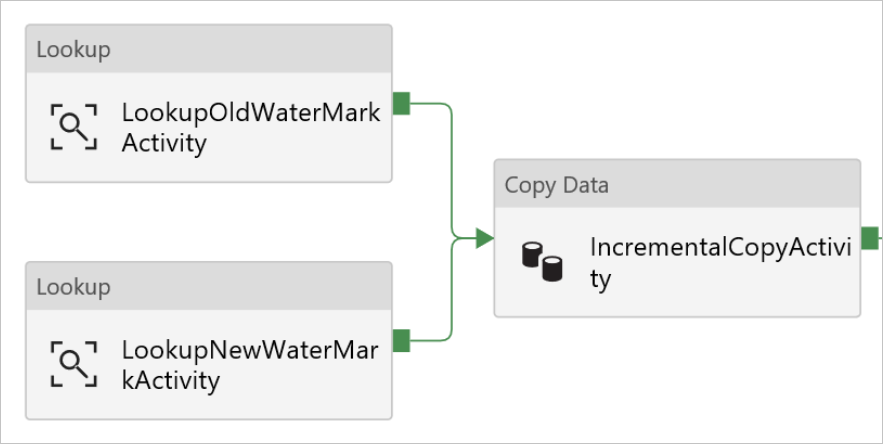
Vyberte v kanálu aktivitu kopírování. V okně Vlastnosti přepněte na kartu Zdroj.
Jako Zdrojová datová sada vyberte SourceDataset.
Jako Použít dotaz vyberte Dotaz.
Jako Dotaz zadejte následující příkaz jazyka SQL.
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'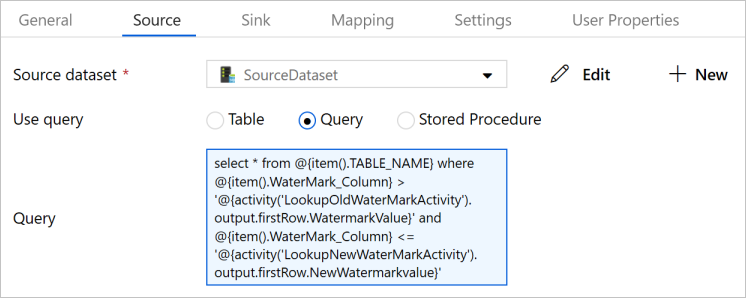
Přepněte na kartu Jímka a jako Datová sada jímky vyberte SinkDataset.
Proveďte následující kroky:
Ve vlastnostech datové sady zadejte parametr SinkTableName
@{item().TABLE_NAME}.Do vlastnosti Název uložené procedury zadejte
@{item().StoredProcedureNameForMergeOperation}.Jako vlastnost Typ tabulky zadejte
@{item().TableType}.Jako název parametru typu tabulky zadejte
@{item().TABLE_NAME}.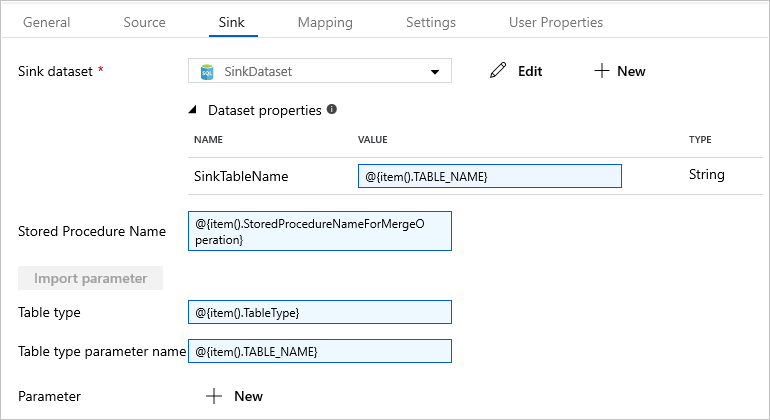
Přetáhněte aktivitu Uložená procedura z panelu nástrojů Aktivity na plochu návrháře kanálu. Propojte aktivitu kopírování s aktivitou Uložená procedura.
Vyberte v kanálu aktivitu Uložená procedura a na kartě Obecné v okně Vlastnosti jako Název zadejte StoredProceduretoWriteWatermarkActivity.
Přepněte na kartu Účet SQL a jako Propojená služba vyberte AzureSqlDatabaseLinkedService.

Přepněte na kartu Uložená procedura a proveďte následující kroky:
Jako Název uložené procedury vyberte
[dbo].[usp_write_watermark].Vyberte Importovat parametr.
Zadejte následující hodnoty parametrů:
Name Typ Hodnota LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}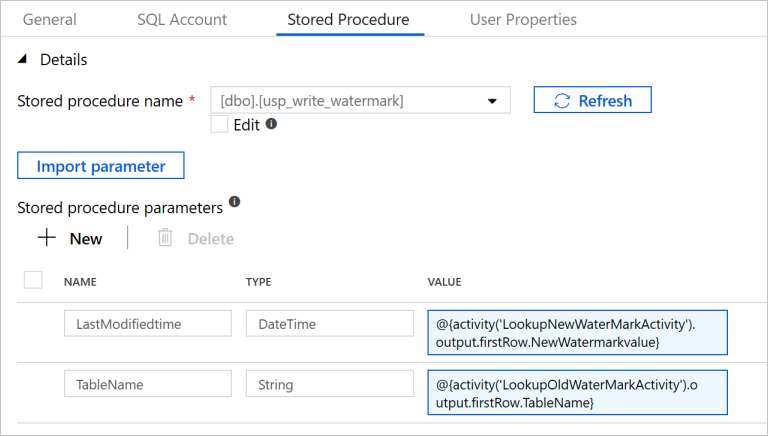
Výběrem možnosti Publikovat vše publikujte entity, které jste vytvořili ve službě Data Factory.
Počkejte, dokud se nezobrazí zpráva Publikování proběhlo úspěšně. Pokud chcete zobrazit oznámení, klikněte na odkaz Zobrazit oznámení. Zavřete okno oznámení kliknutím na X.
Spuštění kanálu
Na panelu nástrojů kanálu klikněte na Přidat trigger a klikněte na Aktivovat.
V okně Spuštění kanálu zadejte následující hodnotu parametru tableList a klikněte na Dokončit.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]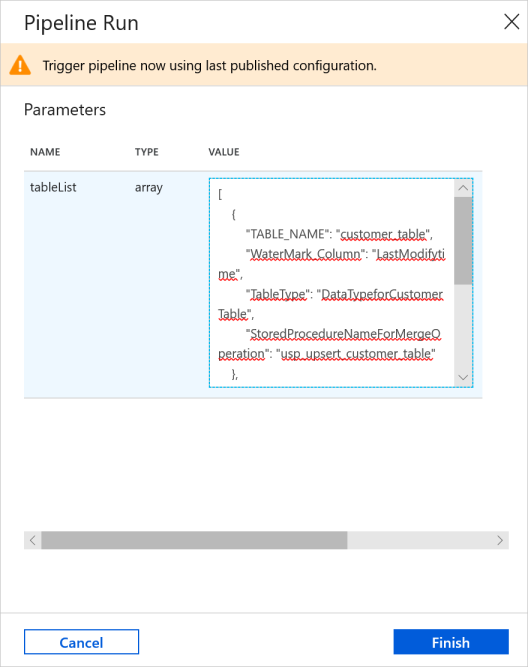
Monitorování kanálu
Vlevo přepněte na kartu Monitorování. Zobrazí se ručně aktivované spuštění kanálu. Pomocí odkazů ve sloupci NÁZEV KANÁLU můžete zobrazit podrobnosti o aktivitě a znovu spustit kanál.
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, vyberte odkaz ve sloupci NÁZEV KANÁLU. Podrobnosti o spuštěních aktivit získáte tak, že ve sloupci NÁZEV AKTIVITY vyberete odkaz Podrobnosti (ikona brýle).
Výběrem možnosti Všechny spuštění kanálu v horní části se vraťte do zobrazení Spuštění kanálu. Jestliže chcete zobrazení aktualizovat, vyberte Aktualizovat.
Kontrola výsledků
V SQL Server Management Studiu spusťte následující dotazy na cílovou databázi SQL a ověřte, že data byla ze zdrojových tabulek zkopírována do cílových tabulek:
Dotaz
select * from customer_table
Výstup
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Dotaz
select * from project_table
Výstup
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Dotaz
select * from watermarktable
Výstup
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Všimněte si, že hodnoty mezí pro obě tabulky byly aktualizovány.
Přidání dalších dat do zdrojových tabulek
Spusťte následující dotaz na zdrojovou databázi SQL Serveru, aby se aktualizoval stávající řádek v tabulce customer_table. Vložte nový řádek do tabulky project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Opětovné spuštění kanálu
V levé části okna webového prohlížeče přepněte na kartu Upravit.
Na panelu nástrojů kanálu klikněte na Přidat trigger a klikněte na Aktivovat.
V okně Spuštění kanálu zadejte následující hodnotu parametru tableList a klikněte na Dokončit.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Opětovné monitorování kanálu
Vlevo přepněte na kartu Monitorování. Zobrazí se ručně aktivované spuštění kanálu. Pomocí odkazů ve sloupci NÁZEV KANÁLU můžete zobrazit podrobnosti o aktivitě a znovu spustit kanál.
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, vyberte odkaz ve sloupci NÁZEV KANÁLU. Podrobnosti o spuštěních aktivit získáte tak, že ve sloupci NÁZEV AKTIVITY vyberete odkaz Podrobnosti (ikona brýle).
Výběrem možnosti Všechny spuštění kanálu v horní části se vraťte do zobrazení Spuštění kanálu. Jestliže chcete zobrazení aktualizovat, vyberte Aktualizovat.
Kontrola konečných výsledků
V aplikaci SQL Server Management Studio spusťte následující dotazy na cílovou databázi SQL a ověřte, že se aktualizovaná nebo nová data zkopírovala ze zdrojových tabulek do cílových tabulek.
Dotaz
select * from customer_table
Výstup
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Všimněte si nových hodnot položek Name a LastModifytime pro PersonID pro číslo 3.
Dotaz
select * from project_table
Výstup
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Všimněte si, že do tabulky project_table byla přidána položka NewProject.
Dotaz
select * from watermarktable
Výstup
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Všimněte si, že hodnoty mezí pro obě tabulky byly aktualizovány.
Související obsah
V tomto kurzu jste provedli následující kroky:
- Příprava zdrojového a cílového datového úložiště
- Vytvoření datové továrny
- Vytvoření místního prostředí Integration Runtime (IR)
- Instalace prostředí Integration Runtime
- Vytvoření propojených služeb
- Vytvoření zdroje, jímky a datových sad mezí
- Vytvoření a spuštění kanálu a jeho monitorování
- Zkontrolujte výsledky.
- Přidání nebo aktualizace dat ve zdrojových tabulkách
- Opakované spuštění kanálu a jeho monitorování
- Kontrola konečných výsledků
Pokud se chcete dozvědět víc o transformaci dat pomocí clusteru Spark v Azure, přejděte k následujícímu kurzu: