Přírůstkové kopírování dat z Azure SQL Database do blob Storage pomocí sledování změn na webu Azure Portal
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V řešení integrace dat je přírůstkové načítání dat po počátečním načtení dat často používaný scénář. Změněná data v rámci období ve zdrojovém úložišti dat lze snadno rozdělit (například LastModifyTime, CreationTime). V některých případech ale neexistuje žádný explicitní způsob, jak identifikovat rozdílová data od posledního zpracování dat. K identifikaci rozdílových dat můžete použít technologii sledování změn podporovanou úložišti dat, jako je Azure SQL Database a SQL Server.
Tento kurz popisuje, jak pomocí služby Azure Data Factory se sledováním změn přírůstkově načítat rozdílová data ze služby Azure SQL Database do služby Azure Blob Storage. Další informace o sledování změn naleznete v tématu Sledování změn na SQL Serveru.
V tomto kurzu provedete následující kroky:
- Připravte zdrojové úložiště dat.
- Vytvoření datové továrny
- Vytvoření propojených služeb
- Vytvoření datových sad pro zdroj, jímku a sledování změn
- Vytvořte, spusťte a monitorujte kanál úplného kopírování.
- Přidejte nebo aktualizujte data ve zdrojové tabulce.
- Vytvoření, spuštění a monitorování kanálu přírůstkové kopie
Řešení na nejvyšší úrovni
V tomto kurzu vytvoříte dva kanály, které provádějí následující operace.
Poznámka:
Tento kurz využívá Azure SQL Database jako zdrojové úložiště dat. Můžete také použít SQL Server.
Počáteční načítání historických dat: Vytvoříte kanál s aktivitou kopírování, která kopíruje celá data ze zdrojového úložiště dat (Azure SQL Database) do cílového úložiště dat (Azure Blob Storage):
- Povolte technologii sledování změn ve zdrojové databázi ve službě Azure SQL Database.
- Získejte počáteční hodnotu
SYS_CHANGE_VERSIONv databázi jako směrný plán pro zaznamenání změněných dat. - Načtěte úplná data ze zdrojové databáze do služby Azure Blob Storage.

Přírůstkové načítání rozdílových dat podle plánu: Vytvoříte kanál s následujícími aktivitami a pravidelně je spustíte:
Vytvořte dvě vyhledávací aktivity pro získání starých a nových
SYS_CHANGE_VERSIONhodnot ze služby Azure SQL Database.Vytvořte jednu aktivitu kopírování, která zkopíruje vložená, aktualizovaná nebo odstraněná data (rozdílová data) mezi dvěma
SYS_CHANGE_VERSIONhodnotami ze služby Azure SQL Database do služby Azure Blob Storage.Rozdílová data načtete spojením primárních klíčů změněných řádků (mezi dvěma
SYS_CHANGE_VERSIONhodnotami) zsys.change_tracking_tablesdat ve zdrojové tabulce a následným přesunem rozdílových dat do cíle.Vytvořte jednu aktivitu uložené procedury, která aktualizuje hodnotu
SYS_CHANGE_VERSIONdalšího spuštění kanálu.

Požadavky
- Předplatné Azure. Pokud ho nemáte, vytvořte si bezplatný účet před tím, než začnete.
- Azure SQL Database Jako zdrojové úložiště dat použijete databázi ve službě Azure SQL Database. Pokud ji nemáte, přečtěte si téma Vytvoření databáze ve službě Azure SQL Database , kde najdete postup jeho vytvoření.
- Účet služby Azure Storage. Blob Storage použijete jako úložiště dat jímky . Pokud účet úložiště Azure nemáte, přečtěte si téma Vytvoření účtu úložiště, kde najdete postup jeho vytvoření. Vytvořte kontejner s názvem adftutorial.
Poznámka:
Při práci s Azure doporučujeme používat modul Azure Az PowerShellu. Začněte tím, že si projdete téma Instalace Azure PowerShellu. Informace o tom, jak migrovat na modul Az PowerShell, najdete v tématu Migrace Azure PowerShellu z AzureRM na Az.
Vytvoření tabulky zdroje dat ve službě Azure SQL Database
Otevřete SQL Server Management Studio a připojte se k SQL Database.
V Průzkumníku serveru klikněte pravým tlačítkem myši na databázi a pak vyberte Nový dotaz.
Spuštěním následujícího příkazu SQL pro vaši databázi vytvořte tabulku pojmenovanou
data_source_tablejako zdrojové úložiště dat:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Spuštěním následujícího dotazu SQL povolte sledování změn v databázi a zdrojové tabulce (
data_source_table).Poznámka:
- Nahraďte
<your database name>názvem databáze ve službě Azure SQL Database, která obsahujedata_source_table. - V uvedeném příkladě se změněná data uchovávají po dobu dvou dnů. Pokud načtete změněná data vždy po třech nebo více dnech, některá změněná data nejsou zahrnuta. Musíte změnit hodnotu
CHANGE_RETENTIONna větší číslo nebo zajistit, aby vaše období načítání změněných dat bylo do dvou dnů. Další informace naleznete v tématu Povolení sledování změn pro databázi.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Nahraďte
Spuštěním následujícího dotazu vytvořte novou tabulku a uložte
ChangeTracking_versionji s výchozí hodnotou:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Poznámka:
Pokud se data po povolení sledování změn pro SLUŽBU SQL Database nezmění, hodnota verze sledování změn je
0.Spuštěním následujícího dotazu vytvořte uloženou proceduru v databázi. Kanál vyvolá tuto uloženou proceduru a aktualizuje verzi sledování změn v tabulce, kterou jste vytvořili v předchozím kroku.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Vytvoření datové továrny
Otevřete webový prohlížeč Microsoft Edge nebo Google Chrome. V současné době podporují uživatelské rozhraní služby Data Factory pouze tyto prohlížeče.
Na webu Azure Portal v nabídce vlevo vyberte Vytvořit prostředek.
Vyberte Integrační>datová továrna.
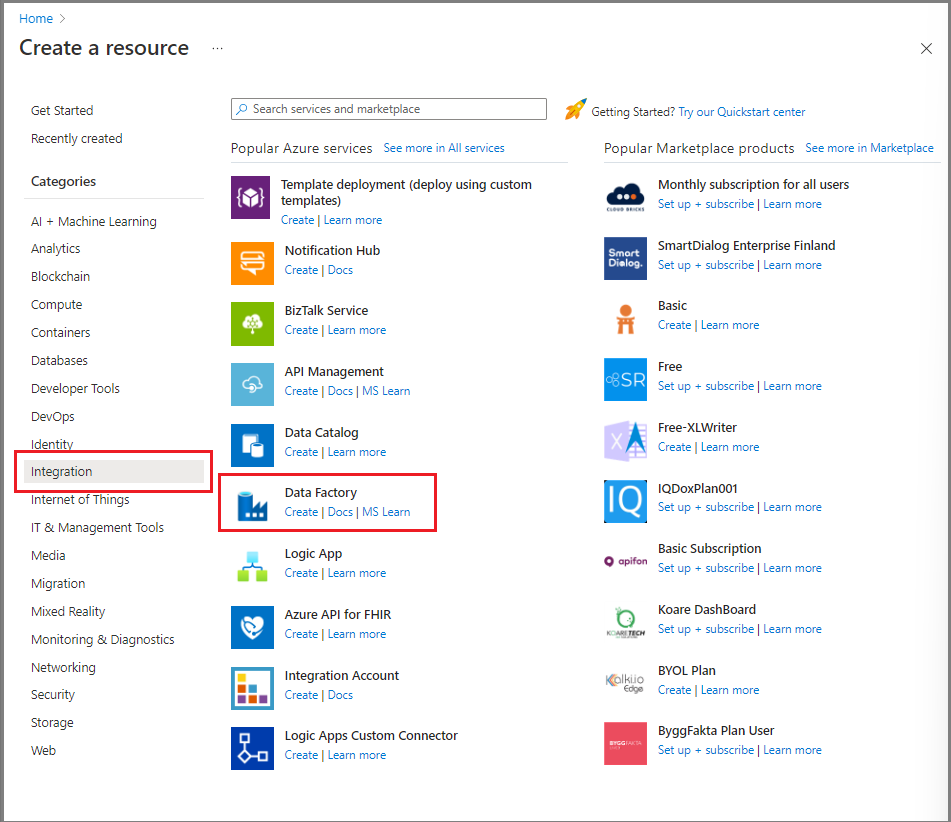
Na stránce Nová datová továrna zadejte název ADFTutorialDataFactory.
Název datové továrny musí být globálně jedinečný. Pokud se zobrazí chyba s názvem, který jste zvolili, není k dispozici, změňte název (například na názevADFTutorialDataFactory) a zkuste objekt pro vytváření dat vytvořit znovu. Další informace najdete v tématu Pravidla pojmenování služby Azure Data Factory.
Vyberte předplatné Azure, v rámci kterého chcete datovou továrnu vytvořit.
U položky Skupina prostředků proveďte jeden z následujících kroků:
- V rozevíracím seznamu vyberte Použít existující skupinu prostředků a pak vyberte existující skupinu prostředků.
- Vyberte Vytvořit nový a zadejte název skupiny prostředků.
Informace o skupinách prostředků najdete v článku Použití skupin prostředků ke správě prostředků Azure.
Jako Verzi vyberte V2.
V části Oblast vyberte oblast datové továrny.
V rozevíracím seznamu se zobrazí jenom podporovaná umístění. Úložiště dat (například Azure Storage a Azure SQL Database) a výpočty (například Azure HDInsight), které datová továrna používá, můžou být v jiných oblastech.
Vyberte Další: Konfigurace Gitu. Nastavte úložiště podle pokynů v metodě konfigurace 4: Během vytváření továrny nebo zaškrtněte políčko Konfigurovat Git později .
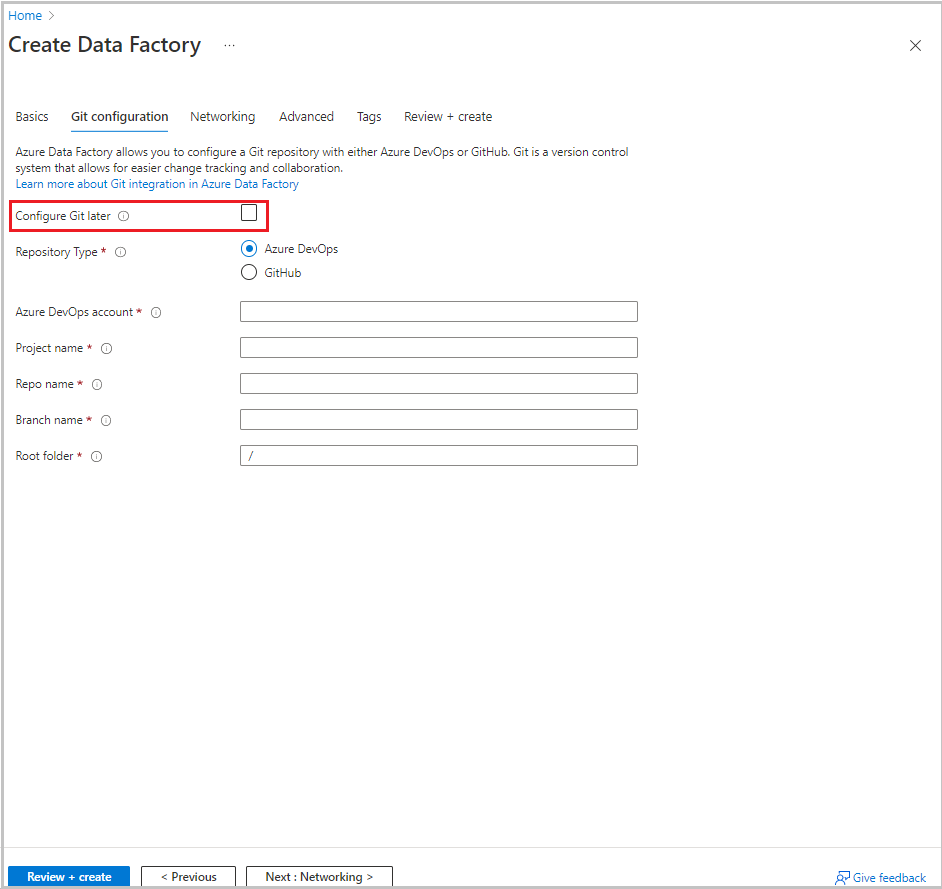
Vyberte Zkontrolovat a vytvořit.
Vyberte Vytvořit.
Na řídicím panelu se na dlaždici Nasazení služby Data Factory zobrazuje stav.

Po vytvoření se zobrazí stránka Data Factory . Výběrem dlaždice Spustit studio otevřete uživatelské rozhraní služby Azure Data Factory na samostatné kartě.
Vytvoření propojených služeb
V datové továrně vytvoříte propojené služby, abyste svá úložiště dat a výpočetní služby spojili s datovou továrnou. V této části vytvoříte propojené služby s účtem úložiště Azure a databází ve službě Azure SQL Database.
Vytvoření propojené služby Azure Storage
Propojení účtu úložiště s objektem pro vytváření dat:
- V uživatelském rozhraní služby Data Factory na kartě Spravovat v části Připojení vyberte Propojené služby. Pak vyberte + Nový nebo tlačítko Vytvořit propojenou službu .
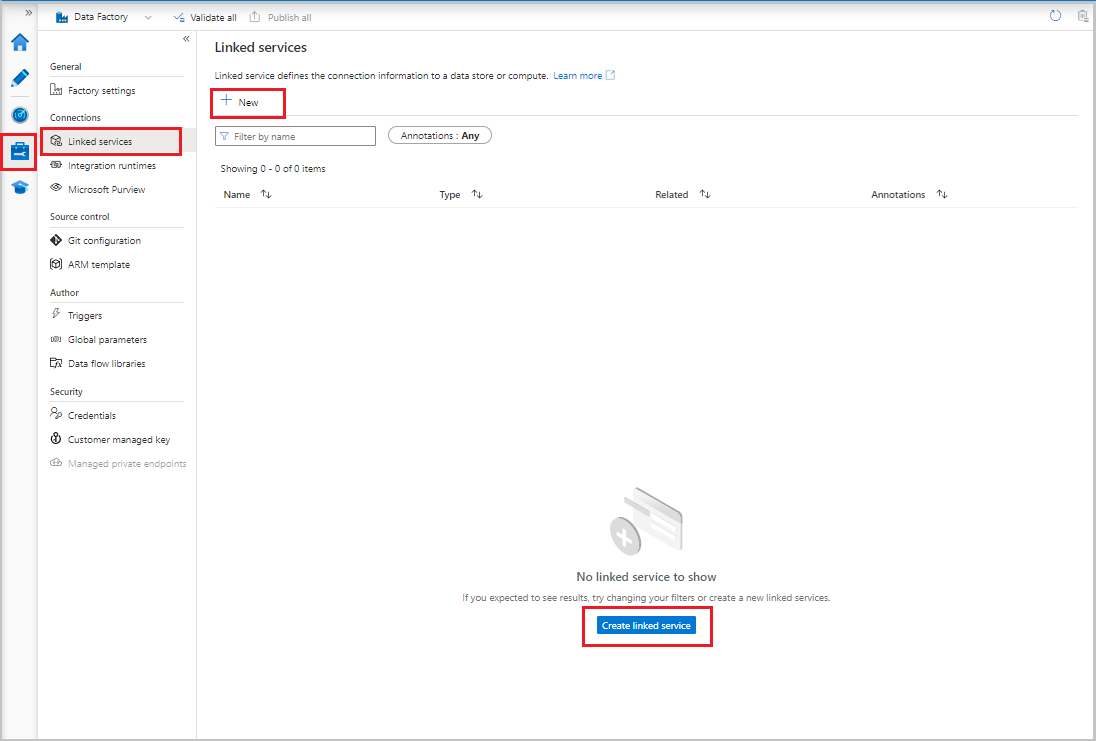
- V okně Nová propojená služba vyberte Azure Blob Storage a pak vyberte Pokračovat.
- Zadejte následující informace:
- Jako Název zadejte AzureStorageLinkedService.
- V části Připojit přes prostředí Integration Runtime vyberte prostředí Integration Runtime.
- Jako typ ověřování vyberte metodu ověřování.
- Jako název účtu úložiště vyberte svůj účet úložiště Azure.
- Vyberte Vytvořit.
Vytvoření propojené služby Azure SQL Database
Propojení databáze s objektem pro vytváření dat:
V uživatelském rozhraní služby Data Factory na kartě Spravovat v části Připojení vyberte Propojené služby. Pak vyberte + Nový.
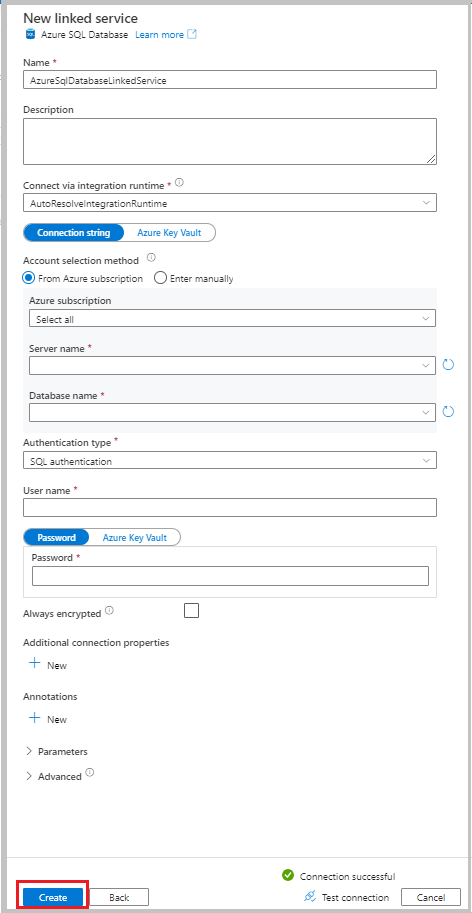
V okně Nová propojená služba vyberte Azure SQL Database a pak vyberte Pokračovat.
Zadejte následující údaje:
- Jako název zadejte AzureSqlDatabaseLinkedService.
- Jako název serveru vyberte server.
- Jako název databáze vyberte databázi.
- Jako typ ověřování vyberte metodu ověřování. V tomto kurzu se k demonstraci používá ověřování SQL.
- Do pole Uživatelské jméno zadejte jméno uživatele.
- Do pole Heslo zadejte heslo pro uživatele. Nebo zadejte informace pro službu Azure Key Vault – propojenou službu AKV, název tajného kódu a verzi tajného kódu.
Vyberte Otestovat připojení a připojení otestujte.
Výběrem možnosti Vytvořit vytvořte propojenou službu.
Vytvoření datových sad
V této části vytvoříte datové sady, které představují zdroj dat a cíl dat a místo pro uložení SYS_CHANGE_VERSION hodnot.
Vytvoření datové sady představující zdrojová data
V uživatelském rozhraní služby Data Factory na kartě Autor vyberte znaménko plus (+). Pak vyberte Datová sada nebo vyberte tři tečky pro akce datové sady.
Vyberte Azure SQL Database a pak vyberte Pokračovat.
V okně Nastavit vlastnosti proveďte následující kroky:
- Jako název zadejte SourceDataset.
- Pro propojenou službu vyberte AzureSqlDatabaseLinkedService.
- Jako název tabulky vyberte dbo.data_source_table.
- Pro schéma importu vyberte možnost Z připojení nebo úložiště .
- Vyberte OK.

Vytvoření datové sady představující data zkopírovaná do úložiště dat jímky
V následujícím postupu vytvoříte datovou sadu, která bude představovat data zkopírovaná ze zdrojového úložiště dat. Kontejner adftutorial jste vytvořili ve službě Azure Blob Storage jako součást požadavků. Pokud tento kontejner neexistuje, vytvořte ho nebo použijte název existujícího kontejneru. V tomto kurzu je název výstupního souboru dynamicky generován z výrazu @CONCAT('Incremental-', pipeline().RunId, '.txt').
V uživatelském rozhraní služby Data Factory vyberte na kartě Autor možnost +. Pak vyberte Datová sada nebo vyberte tři tečky pro akce datové sady.
Vyberte Azure Blob Storage a pak vyberte Pokračovat.
Jako oddělovač textu vyberte formát datového typu a pak vyberte Pokračovat.
V okně Nastavit vlastnosti proveďte následující kroky:
- Jako název zadejte SinkDataset.
- Pro propojenou službu vyberte AzureBlobStorageLinkedService.
- Do pole Cesta k souboru zadejte adftutorial/incchgtracking.
- Vyberte OK.
Jakmile se datová sada zobrazí ve stromovém zobrazení, přejděte na kartu Připojení a vyberte textové pole Název souboru. Když se zobrazí možnost Přidat dynamický obsah, vyberte ji.
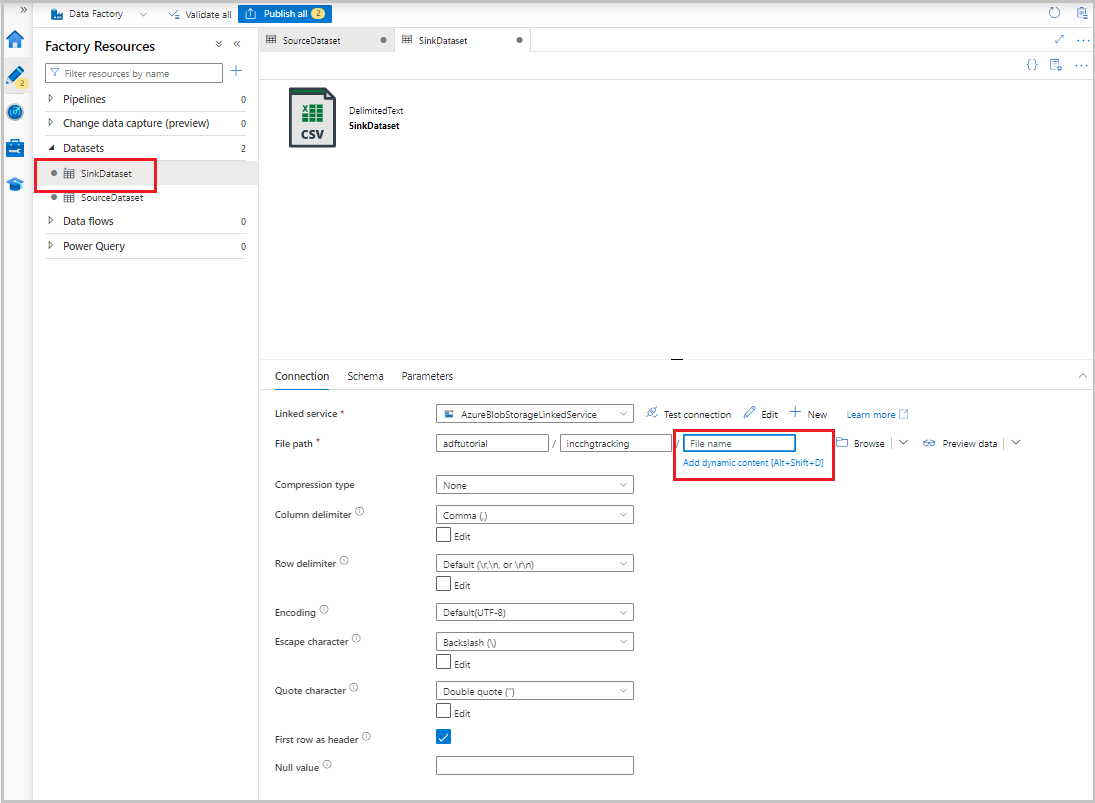
Zobrazí se okno Tvůrce výrazů kanálu. Vložte
@concat('Incremental-',pipeline().RunId,'.csv')textové pole.Vyberte OK.
Vytvoření datové sady představující data sledování změn
V následujícím postupu vytvoříte datovou sadu pro uložení verze sledování změn. Tabulku jste vytvořili table_store_ChangeTracking_version jako součást požadavků.
- V uživatelském rozhraní služby Data Factory na kartě Autor vyberte +a pak vyberte Datová sada.
- Vyberte Azure SQL Database a pak vyberte Pokračovat.
- V okně Nastavit vlastnosti proveďte následující kroky:
- Jako název zadejte ChangeTrackingDataset.
- Pro propojenou službu vyberte AzureSqlDatabaseLinkedService.
- Jako název tabulky vyberte dbo.table_store_ChangeTracking_version.
- Pro schéma importu vyberte možnost Z připojení nebo úložiště .
- Vyberte OK.
Vytvoření kanálu pro úplné kopírování
V následujícím postupu vytvoříte kanál s aktivitou kopírování, která kopíruje celá data ze zdrojového úložiště dat (Azure SQL Database) do cílového úložiště dat (Azure Blob Storage):
V uživatelském rozhraní služby Data Factory na kartě Autor vyberte +a pak vyberte Kanál kanálu>.
Zobrazí se nová karta pro konfiguraci kanálu. Kanál se také zobrazí ve stromovém zobrazení. V okně Vlastnosti změňte název kanálu na FullCopyPipeline.
V sadě nástrojů Aktivity rozbalte položku Přesunout a transformovat. Proveďte jeden z následujících kroků:
- Přetáhněte aktivitu kopírování na plochu návrháře kanálu.
- Na panelu hledání v části Aktivity vyhledejte aktivitu kopírování dat a pak nastavte název na FullCopyActivity.
Přepněte na kartu Zdroj . Jako zdrojovou datovou sadu vyberte SourceDataset.
Přepněte na kartu Jímka . Jako datovou sadu jímky vyberte SinkDataset.
Pokud chcete ověřit definici kanálu, vyberte Na panelu nástrojů možnost Ověřit . Ověřte, že se nezobrazí žádná chyba ověření. Zavřete výstup ověření kanálu.
Pokud chcete publikovat entity (propojené služby, datové sady a kanály), vyberte Publikovat vše. Počkejte, dokud se nezobrazí zpráva Publikování proběhlo úspěšně.
Pokud chcete zobrazit oznámení, vyberte tlačítko Zobrazit oznámení .
Spuštění kanálu úplného kopírování
V uživatelském rozhraní služby Data Factory vyberte na panelu nástrojů kanálu možnost Přidat trigger a pak vyberte Aktivovat.
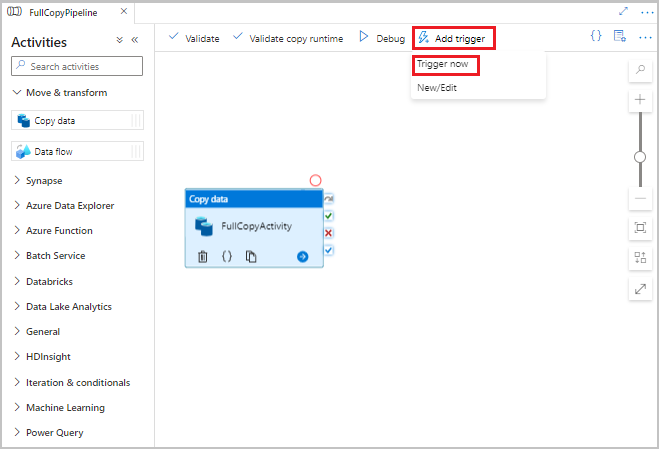
V okně Spuštění kanálu vyberte OK.

Monitorování kanálu úplného kopírování
V uživatelském rozhraní služby Data Factory vyberte kartu Monitorování . V seznamu se zobrazí spuštění kanálu a jeho stav. Seznam aktualizujete tak, že vyberete Aktualizovat. Najeďte myší na spuštění kanálu a získejte možnost Znovu spustit nebo Spotřeba .
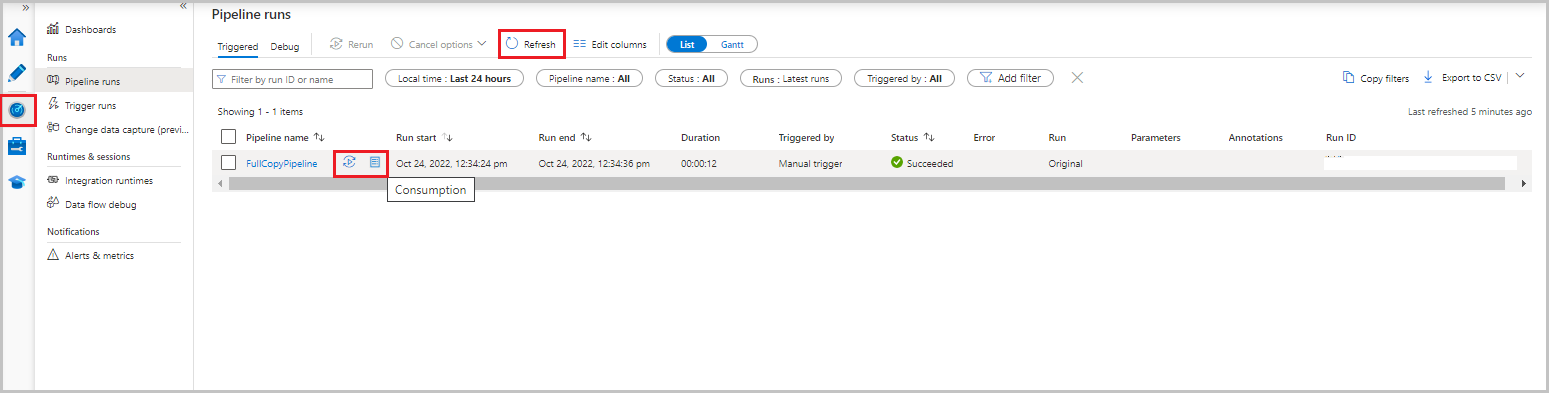
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, vyberte název kanálu ze sloupce Název kanálu. Kanál obsahuje jenom jednu aktivitu, takže v seznamu je jenom jedna položka. Pokud chcete přepnout zpět do zobrazení spuštění kanálu, vyberte odkaz Všechna spuštění kanálu v horní části.
Kontrola výsledků
Složka incchgtracking kontejneru adftutorial obsahuje soubor s názvem incremental-<GUID>.csv.
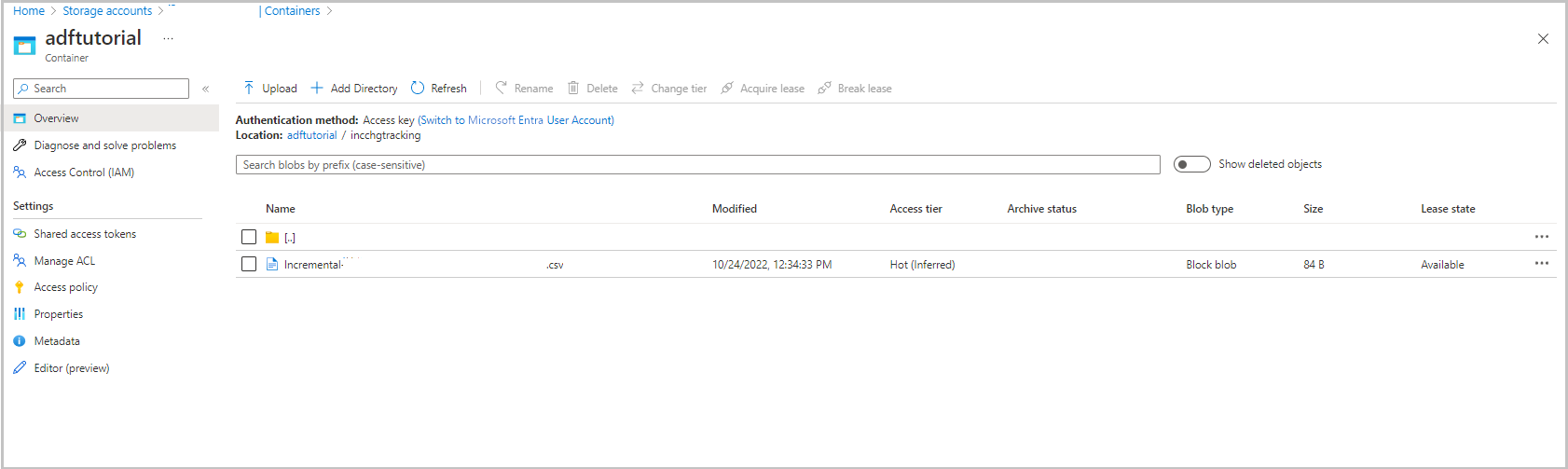
Soubor by měl obsahovat data z vaší databáze:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Přidání dalších dat do zdrojové tabulky
Spuštěním následujícího dotazu na databázi přidejte řádek a aktualizujte řádek:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Vytvoření kanálu pro rozdílové kopírování
V následujícím postupu vytvoříte kanál s aktivitami a pravidelně ho spustíte. Při spuštění kanálu:
- Aktivity vyhledávání získají staré a nové
SYS_CHANGE_VERSIONhodnoty ze služby Azure SQL Database a předají je do aktivity kopírování. - Aktivita kopírování zkopíruje vložená, aktualizovaná nebo odstraněná data mezi těmito dvěma
SYS_CHANGE_VERSIONhodnotami ze služby Azure SQL Database do služby Azure Blob Storage. - Aktivita uložené procedury aktualizuje hodnotu dalšího
SYS_CHANGE_VERSIONspuštění kanálu.
V uživatelském rozhraní služby Data Factory přepněte na kartu Autor. Vyberte +a pak vyberte Kanál kanálu>.
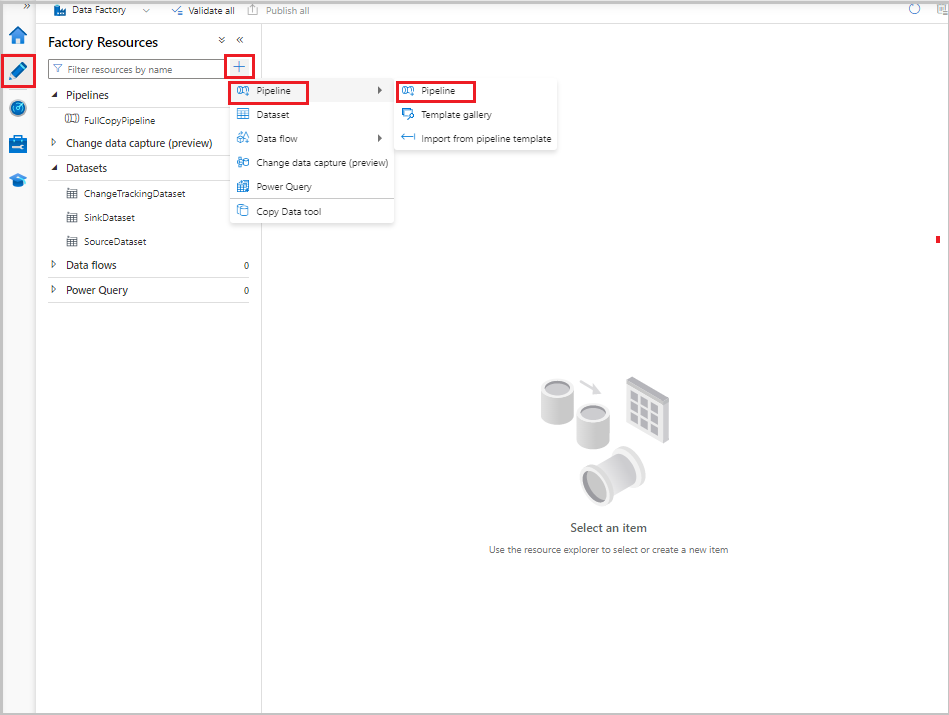
Zobrazí se nová karta pro konfiguraci kanálu. Kanál se také zobrazí ve stromovém zobrazení. V okně Vlastnosti změňte název kanálu na IncrementalCopyPipeline.
Rozbalte položku Obecné v sadě nástrojů Aktivity . Přetáhněte vyhledávací aktivitu na plochu návrháře kanálu nebo vyhledejte v poli Aktivity hledání. Nastavte název aktivity na LookupLastChangeTrackingVersionActivity. Tato aktivita získá verzi sledování změn použitou v poslední operaci kopírování, která je uložena
table_store_ChangeTracking_versionv tabulce.Přepněte na kartu Nastavení v okně Vlastnosti . Jako zdrojovou datovou sadu vyberte ChangeTrackingDataset.
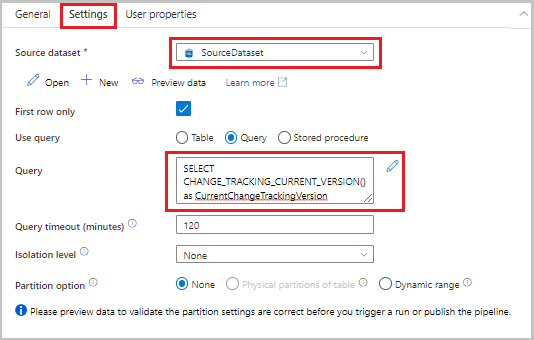
Přetáhněte aktivitu vyhledávání z panelu nástrojů Aktivity na plochu návrháře kanálu. Nastavte název aktivity na LookupCurrentChangeTrackingVersionActivity. Tato aktivita získá aktuální verzi sledování změn.
V okně Vlastnosti přepněte na kartu Nastavení a pak proveďte následující kroky:
Jako zdrojovou datovou sadu vyberte SourceDataset.
Pokud chcete použít dotaz, vyberte Dotaz.
Jako dotaz zadejte následující dotaz SQL:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
V sadě nástrojů Aktivity rozbalte položku Přesunout a transformovat. Přetáhněte aktivitu kopírování dat na plochu návrháře kanálu. Nastavte název aktivity na IncrementalCopyActivity. Tato aktivita kopíruje data mezi poslední verzí sledování změn a aktuální verzí sledování změn do cílového úložiště dat.
V okně Vlastnosti přepněte na kartu Zdroj a proveďte následující kroky:
Jako zdrojovou datovou sadu vyberte SourceDataset.
Pokud chcete použít dotaz, vyberte Dotaz.
Jako dotaz zadejte následující dotaz SQL:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
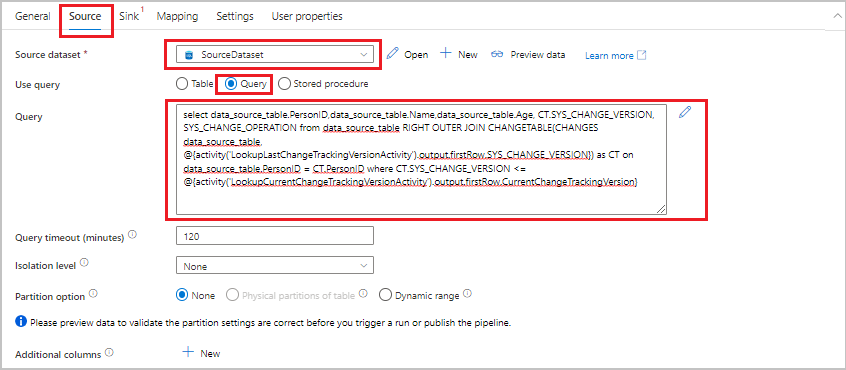
Přepněte na kartu Jímka . Jako datovou sadu jímky vyberte SinkDataset.
Obě aktivity vyhledávání propojte s aktivitou kopírování jednu po druhé. Přetáhněte zelené tlačítko připojené k aktivitě vyhledávání do aktivity kopírování.
Přetáhněte aktivitu uložené procedury z panelu nástrojů Aktivity na plochu návrháře kanálu. Nastavte název aktivity na StoredProceduretoUpdateChangeTrackingActivity. Tato aktivita aktualizuje verzi sledování změn v
table_store_ChangeTracking_versiontabulce.Přepněte na kartu Nastavení a pak proveďte následující kroky:
- Pro propojenou službu vyberte AzureSqlDatabaseLinkedService.
- Jako Název uložené procedury vyberte Update_ChangeTracking_Version.
- Vyberte Importovat.
- V části Parametry uložené procedury zadejte následující hodnoty parametrů:
Name Typ Hodnota CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}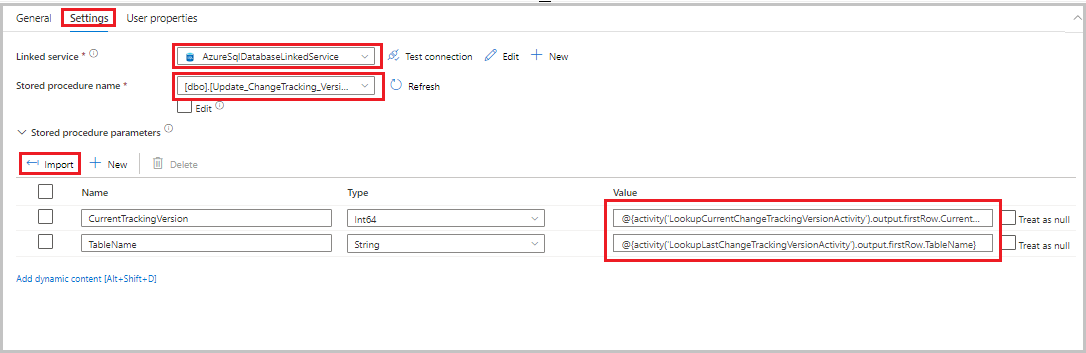
Připojte aktivitu kopírování k aktivitě uložené procedury. Přetáhněte zelené tlačítko připojené k aktivitě kopírování do aktivity uložené procedury.
Na panelu nástrojů vyberte Ověřit . Ověřte, že se nezobrazí žádné chyby ověření. Zavřete okno sestavy ověření kanálu.
Výběrem tlačítka Publikovat vše publikujte entity (propojené služby, datové sady a kanály) do služby Data Factory. Počkejte, až se zobrazí zpráva Publikování byla úspěšná .
Spuštění kanálu přírůstkového kopírování
Vyberte Přidat aktivační událost na panelu nástrojů kanálu a pak vyberte Aktivovat.
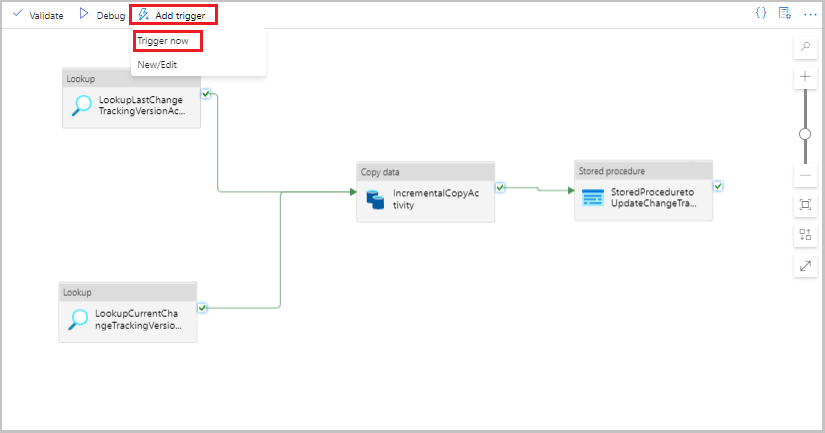
V okně Spuštění kanálu vyberte OK.
Monitorování kanálu přírůstkového kopírování
Vyberte kartu Monitorování. V seznamu se zobrazí spuštění kanálu a jeho stav. Seznam aktualizujete tak, že vyberete Aktualizovat.
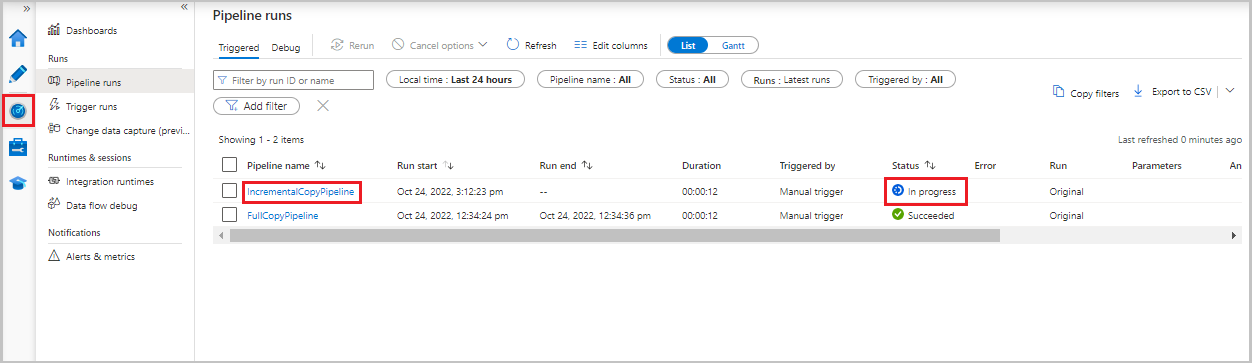
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, vyberte ve sloupci Název kanálu odkaz IncrementalCopyPipeline. Spuštění aktivit se zobrazí v seznamu.
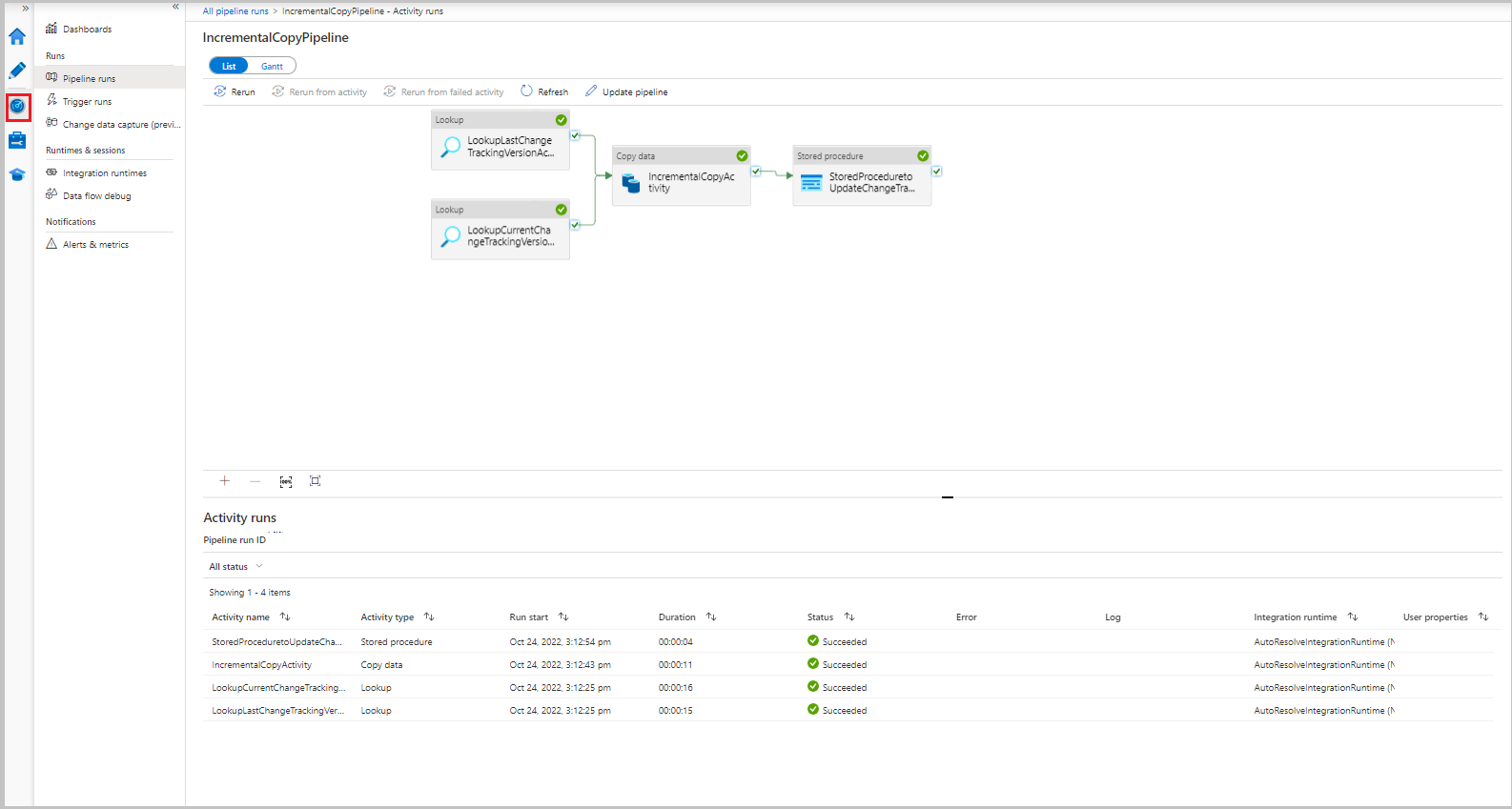
Kontrola výsledků
Druhý soubor se zobrazí ve složce incchgtracking kontejneru adftutorial .
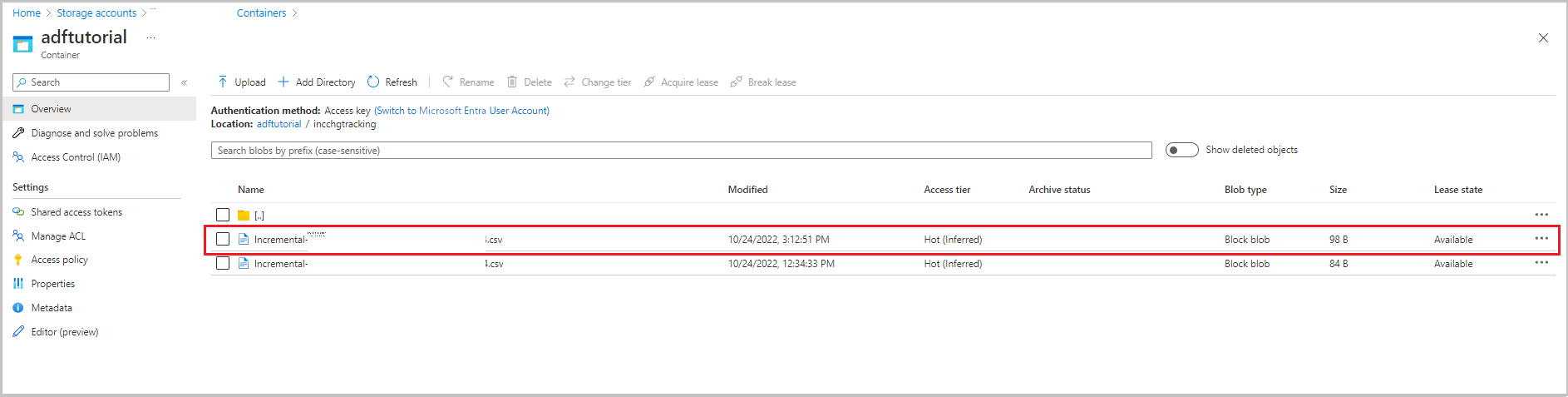
Soubor by měl obsahovat pouze rozdílová data z vaší databáze. Záznam s U je aktualizovaný řádek v databázi a I je jedním přidaným řádkem.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
První tři sloupce jsou změněna data z data_source_table. Poslední dva sloupce jsou metadata z tabulky pro systém sledování změn. Čtvrtý sloupec je SYS_CHANGE_VERSION hodnota pro každý změněný řádek. Pátým sloupcem je operace: U = update, I = insert. Podrobné informace o sledování změn najdete v tématu CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Související obsah
V následujícím kurzu se dozvíte, jak kopírovat pouze nové a změněné soubory na LastModifiedDatezákladě: