Spuštění poznámkového bloku Databricks s využitím aktivity poznámkového bloku Databricks ve službě Azure Data Factory
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V tomto kurzu pomocí webu Azure Portal vytvoříte kanál Azure Data Factory, který spustí poznámkový blok Databricks pro cluster úloh Databricks. Kanál do poznámkového bloku Databricks během provádění také předá parametry Azure Data Factory.
V tomto kurzu provedete následující kroky:
Vytvoření datové továrny
Vytvoření kanálu využívajícího aktivitu poznámkového bloku Databricks
Aktivace spuštění kanálu
Monitorování spuštění kanálu
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Poznámka:
Úplné podrobnosti o tom, jak používat aktivitu poznámkového bloku Databricks, včetně použití knihoven a předávání vstupních a výstupních parametrů, najdete v dokumentaci k aktivitě poznámkového bloku Databricks.
Požadavky
- Pracovní prostor Azure Databricks. Vytvořte pracovní prostor Databricks nebo použijte existující. V pracovním prostoru Azure Databricks vytvoříte poznámkový blok Python. Pak poznámkový blok spustíte a pomocí služby Azure Data Factory do něj předáte parametry.
Vytvoření datové továrny
Spusťte webový prohlížeč Microsoft Edge nebo Google Chrome. Uživatelské rozhraní služby Data Factory podporují v současnosti jenom webové prohlížeče Microsoft Edge a Google Chrome.
V nabídce webu Azure Portal vyberte Vytvořit prostředek , vyberte Integrace a pak vyberte Data Factory.
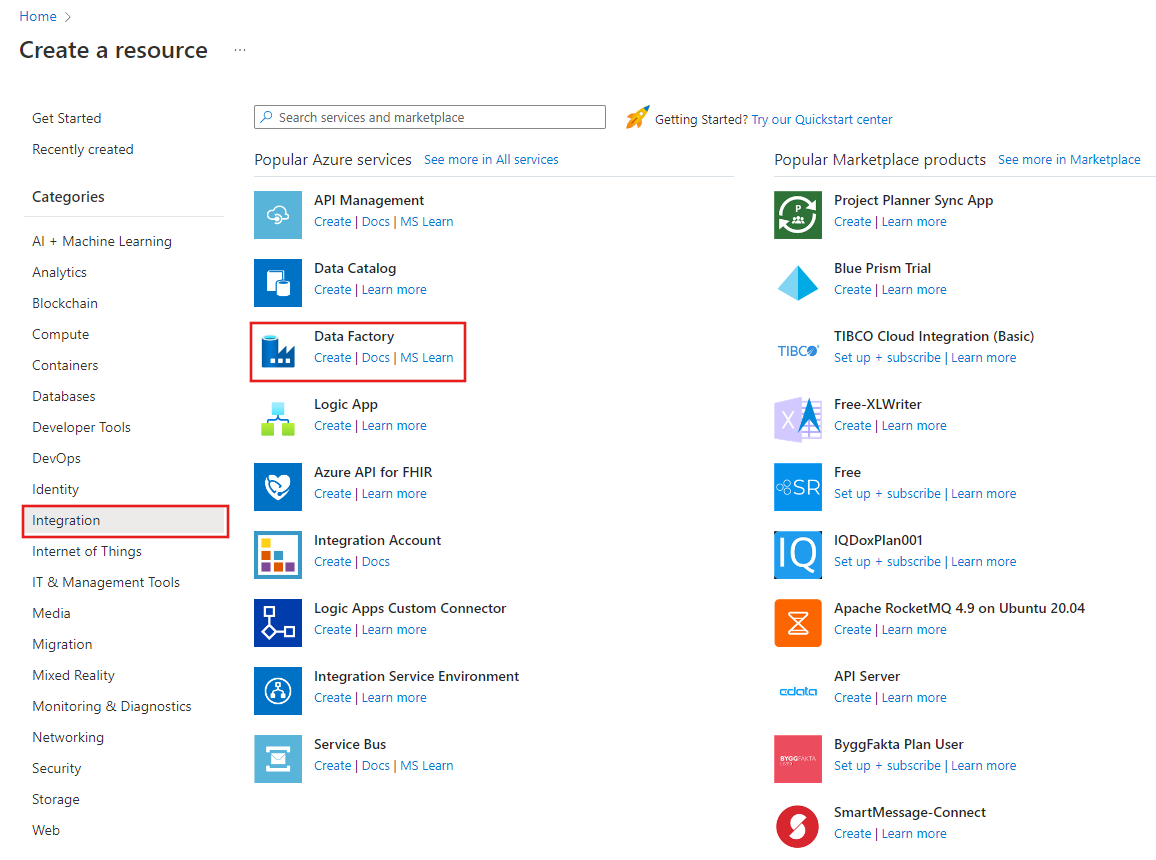
Na stránce Vytvořit datovou továrnu na kartě Základy vyberte své předplatné Azure, ve kterém chcete vytvořit datovou továrnu.
U položky Skupina prostředků proveďte jeden z následujících kroků:
V rozevíracím seznamu vyberte existující skupinu prostředků.
Vyberte Vytvořit nový a zadejte název nové skupiny prostředků.
Informace o skupinách prostředků najdete v článku Použití skupin prostředků ke správě prostředků Azure.
V části Oblast vyberte umístění datové továrny.
Seznam obsahuje jenom umístění podporovaná službou Data Factory, do kterých se budou ukládat vaše metadata Azure Data Factory. Přidružená úložiště dat (například Azure Storage a Azure SQL Database) a výpočty (jako Azure HDInsight), které služba Data Factory používá, se můžou spouštět v jiných oblastech.
Jako název zadejte ADFTutorialDataFactory.
Název objektu pro vytváření dat Azure musí být globálně jedinečný. Pokud se zobrazí následující chyba, změňte název datové továrny (například použijte <název>ADFTutorialDataFactory). Pravidla pojmenování artefaktů služby Data Factory najdete v článku Data Factory – pravidla pojmenování.
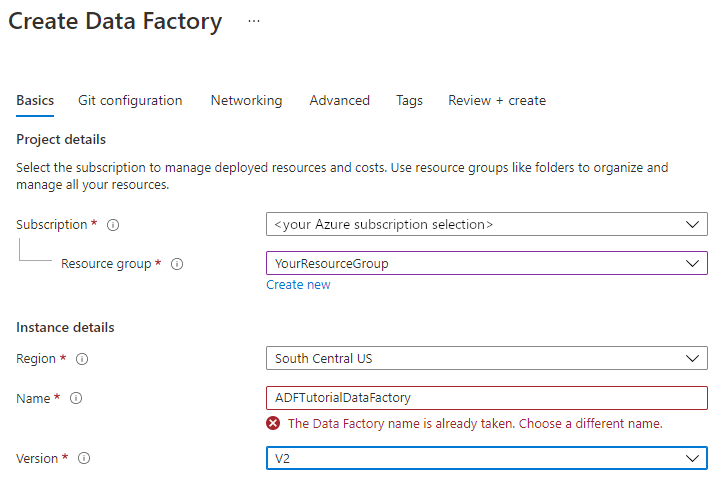
Jako Verzi vyberte V2.
Vyberte Další: Konfigurace Gitu a pak zaškrtněte políčko Konfigurovat Git později .
Vyberte Zkontrolovat a vytvořit a po úspěšném ověření vyberte Vytvořit .
Po vytvoření vyberte Přejít k prostředku a přejděte na stránku Data Factory . Výběrem dlaždice Otevřít Azure Data Factory Studio spusťte aplikaci uživatelského rozhraní (UI) služby Azure Data Factory na samostatné kartě prohlížeče.

Vytvoření propojených služeb
V této části vytvoříte propojenou službu Databricks. Tato propojená služba obsahuje informace o připojení ke clusteru Databricks:
Vytvoření propojené služby Azure Databricks
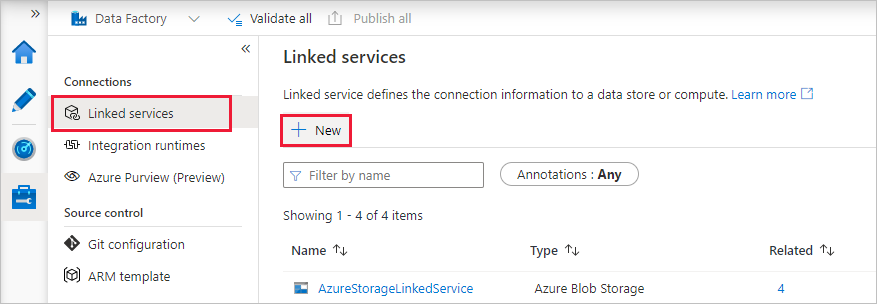
Na domovské stránce přepněte na kartu Spravovat na levém panelu.
V části Připojení vyberte Propojené služby a pak vyberte + Nový.
V okně Nová propojená služba vyberte Compute>Azure Databricks a pak vyberte Pokračovat.

V okně Nová propojená služba proveďte následující kroky:
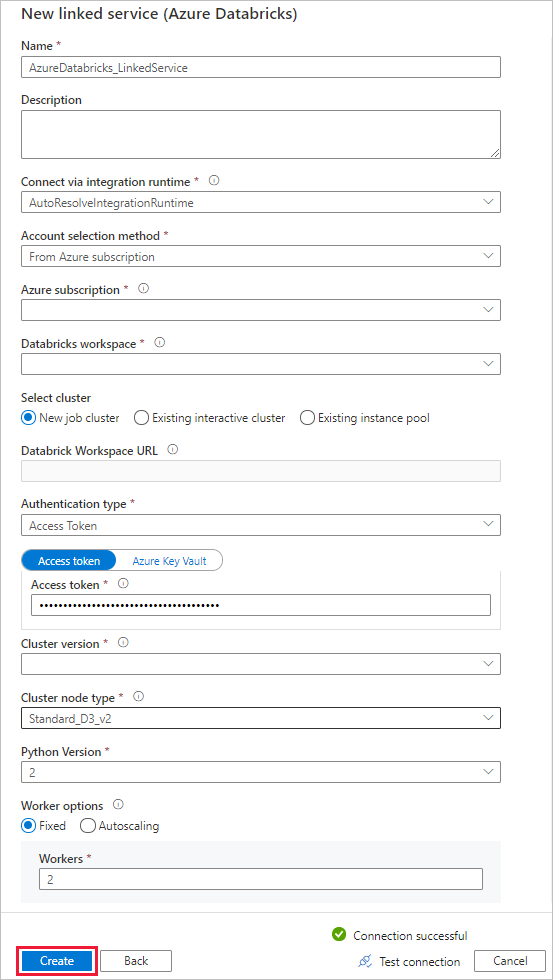
Jako název zadejte AzureDatabricks_LinkedService.
Vyberte příslušný pracovní prostor Databricks, ve které poznámkový blok spustíte.
Pro výběr clusteru vyberte Nový cluster úloh.
U adresy URL pracovního prostoru Databricks by se měly automaticky vyplněné informace.
Pokud jako typ ověřování vyberete Přístupový token, vygenerujte ho z pracoviště Azure Databricks. Postup najdete tady. Pro identitu spravované služby a spravovanou identitu přiřazenou uživatelem udělte roli Přispěvatel oběma identitám v nabídce řízení přístupu k prostředku Azure Databricks.
Pro verzi clusteru vyberte verzi, kterou chcete použít.
Jako typ uzlu clusteru vyberte Standard_D3_v2 v kategorii Pro obecné účely (HDD) pro účely tohoto kurzu.
V části Pracovní procesy zadejte hodnotu 2.
Vyberte Vytvořit.
Vytvořit kanál
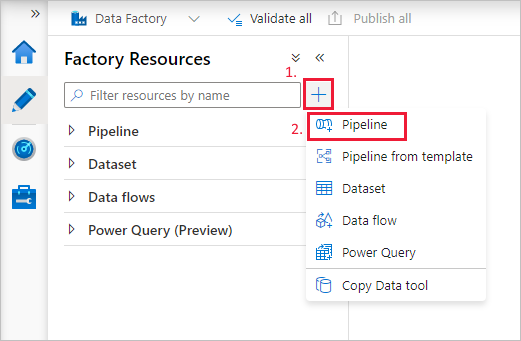
Vyberte tlačítko + (plus) a potom v nabídce vyberte Kanál.
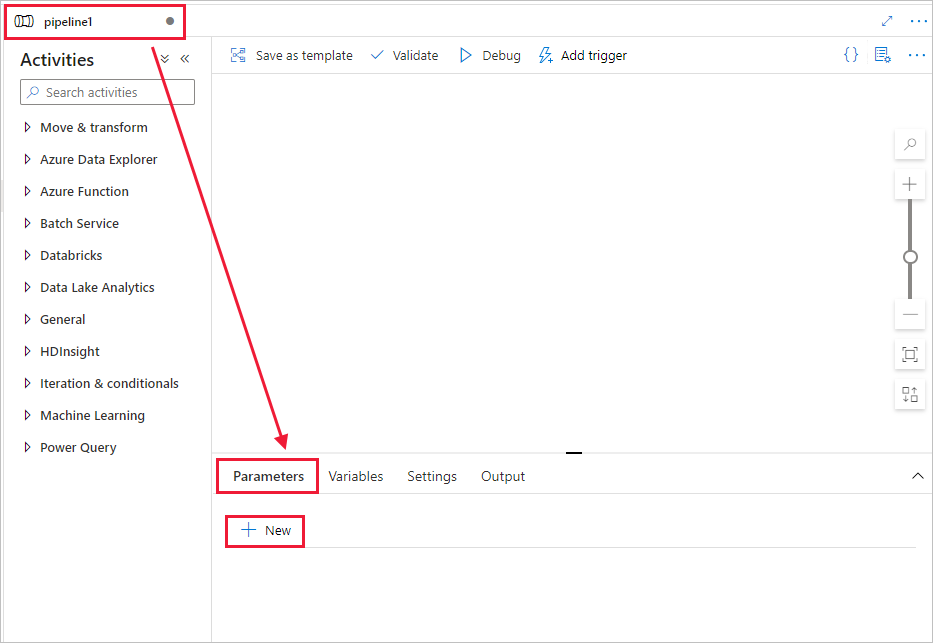
Vytvořte parametr, který se použije v kanálu. Později tento parametr předáte do aktivity poznámkového bloku Databricks. V prázdném kanálu vyberte kartu Parametry a pak vyberte + Nový a pojmenujte ho jako "název".
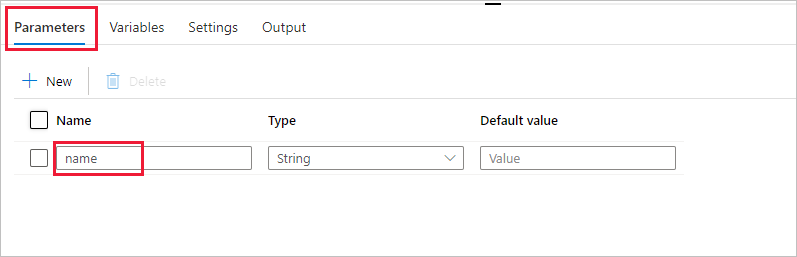
Na panelu nástrojů Aktivity rozbalte Databricks. Přetáhněte aktivitu Poznámkový blok z panelu nástrojů Aktivity na plochu návrháře kanálu.
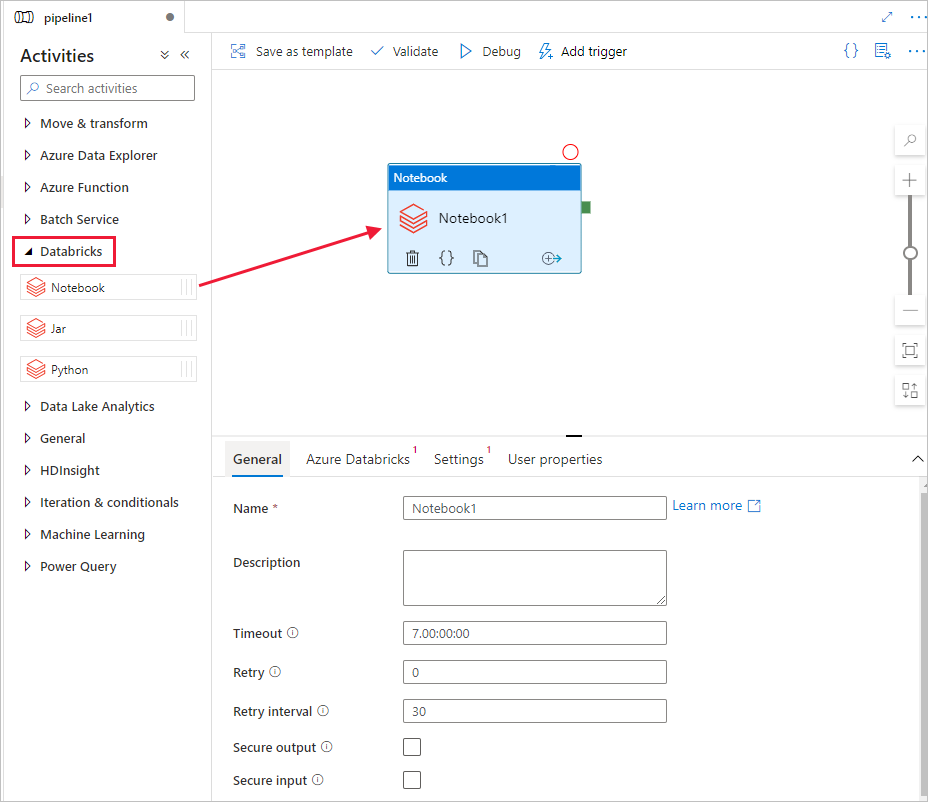
Ve vlastnostech okna aktivity poznámkového bloku Databricksv dolní části proveďte následující kroky:
Přepněte na kartu Azure Databricks.
Vyberte AzureDatabricks_LinkedService (kterou jste vytvořili v předchozím postupu).
Přepněte na kartu Nastavení.
Přejděte na cestu k poznámkovému bloku Databricks. Teď vytvoříme poznámkový blok a zadáme cestu. Cestu k poznámkovému bloku získáte pomocí následujících několika kroků.
Spusťte pracovní prostor Azure Databricks.
Vytvořte v pracovním prostoru novou složku a pojmenujte ji adftutorial.
Vytvořte nový poznámkový blok, pojmenujme ho mynotebook. Klikněte pravým tlačítkem na složku adftutorial a vyberte Vytvořit.
Do nově vytvořeného poznámkového bloku mynotebook přidejte následující kód:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)Cesta k poznámkovému bloku v tomto případě je /adftutorial/mynotebook.
Přepněte zpět do nástroje pro vytváření v uživatelském rozhraní Data Factory. V aktivitě Poznámkový blok1 přejděte na kartu Nastavení.
a. Přidejte parametr do aktivity poznámkového bloku. Použijte stejný parametr, který jste dříve přidali do kanálu.
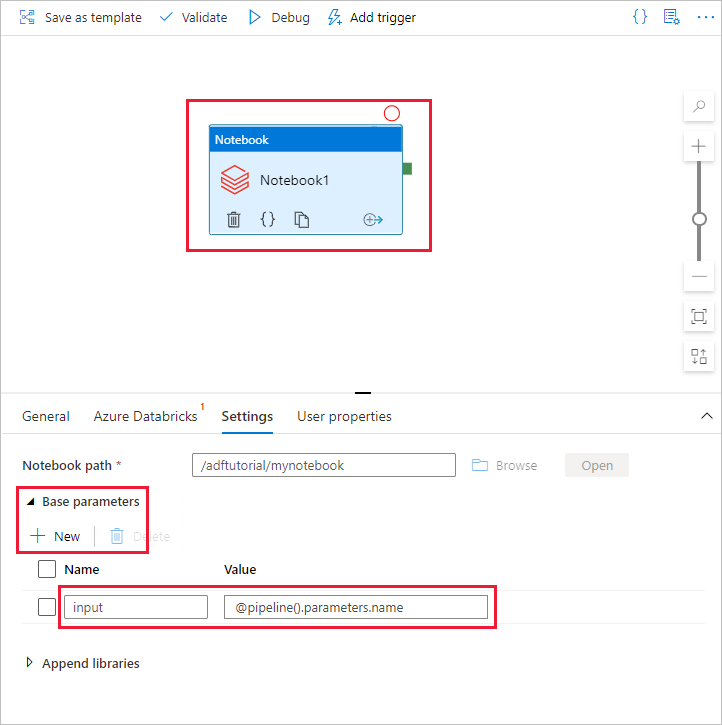
b. Parametr pojmenujte jako vstup a zadejte hodnotu jako výraz @pipeline().parameters.name.
Pokud chcete kanál ověřit, vyberte tlačítko Ověřit na panelu nástrojů. Okno ověření zavřete tak, že vyberete tlačítko Zavřít .
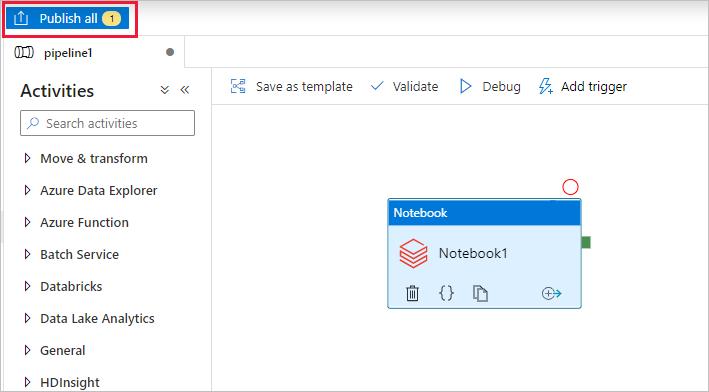
Zvolte Publikovat vše. Uživatelské rozhraní služby Data Factory publikuje entity (propojené služby a kanál) do služby Azure Data Factory.
Aktivace spuštění kanálu
Na panelu nástrojů vyberte Přidat aktivační událost a pak vyberte Aktivovat.
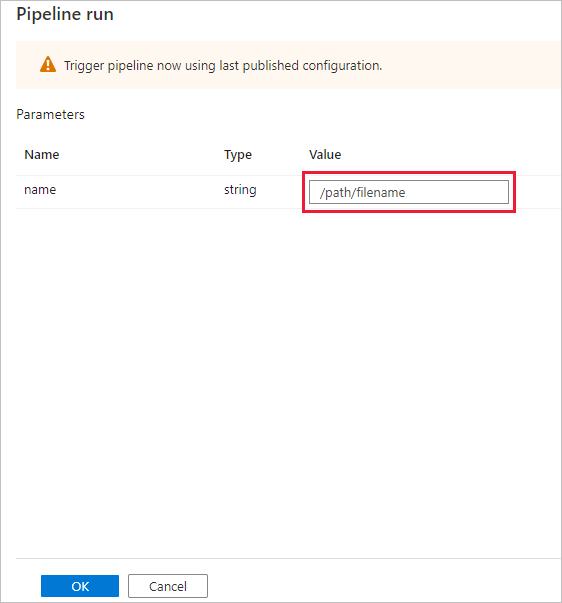
Dialogové okno Spuštění kanálu požádá o parametr name . Jako parametr zde použijte /path/filename. Vyberte OK.
Monitorování spuštění kanálu
Přepněte na kartu Monitorování . Potvrďte, že se zobrazuje spuštění kanálu. Vytvoření clusteru úloh Databricks, ve kterém se poznámkový blok spustí, trvá přibližně 5 až 8 minut.
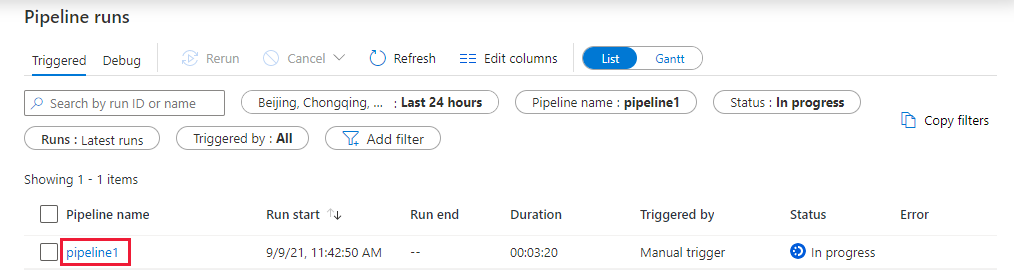
Pravidelně klikejte na Aktualizovat a kontrolujte stav spuštění kanálu.
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, vyberte ve sloupci Název kanálu odkaz kanál1.
Na stránce Spuštění aktivity vyberte výstup ve sloupci Název aktivity, abyste zobrazili výstup jednotlivých aktivit, a odkaz na protokoly Databricks najdete v podokně Výstup, kde najdete podrobnější protokoly Sparku.
Zpět do zobrazení spuštění kanálu můžete přepnout výběrem odkazu Všechna spuštění kanálu v nabídce s popisem cesty v horní části.
Ověření výstupu
Můžete se přihlásit k pracovnímu prostoru Azure Databricks, přejít na Spuštění úloh a zobrazit stav úlohy jako čekající spuštění, spuštění nebo ukončení.
Můžete vybrat název úlohy a přejít k dalším podrobnostem. Po úspěšném spuštění můžete ověřit předané parametry a výstup poznámkového bloku Python.
Shrnutí
Kanál v této ukázce aktivuje aktivitu poznámkového bloku Databricks a předává do ní parametr. Naučili jste se:
Vytvoření datové továrny
Vytvoření kanálu využívajícího aktivitu poznámkového bloku Databricks
Aktivace spuštění kanálu
Monitorování spuštění kanálu