Transformace dat spuštěním poznámkového bloku Databricks
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Aktivita poznámkového bloku Azure Databricks v kanálu spouští poznámkový blok Databricks ve vašem pracovním prostoru Azure Databricks. Tento článek vychází z článku o aktivitách transformace dat, který představuje obecný přehled transformace dat a podporovaných transformačních aktivit. Azure Databricks je spravovaná platforma pro spouštění Apache Sparku.
Poznámkový blok Databricks můžete vytvořit pomocí šablony ARM pomocí KÓDU JSON nebo přímo prostřednictvím uživatelského rozhraní azure Data Factory Studio. Podrobný návod, jak vytvořit aktivitu poznámkového bloku Databricks pomocí uživatelského rozhraní, najdete v kurzu Spuštění poznámkového bloku Databricks s aktivitou poznámkového bloku Databricks ve službě Azure Data Factory.
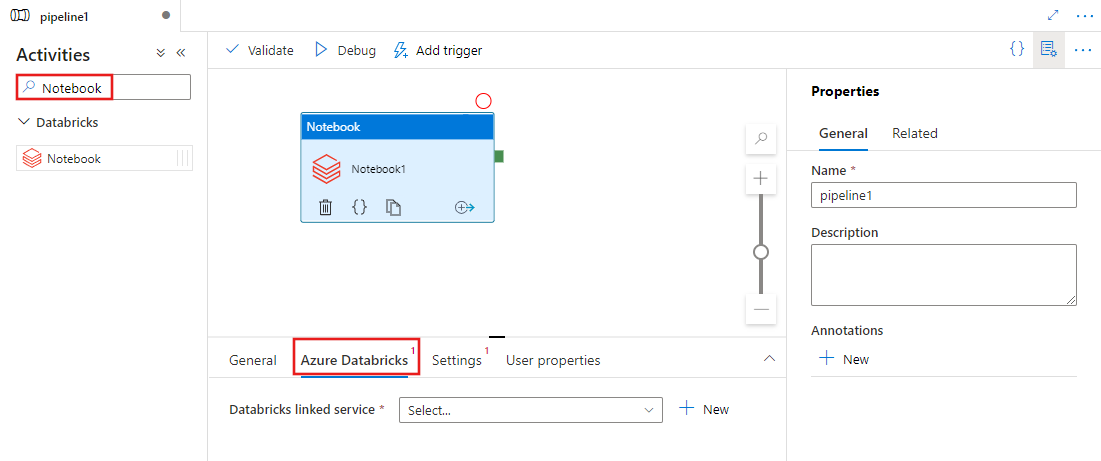
Přidání aktivity poznámkového bloku pro Azure Databricks do kanálu s uživatelským rozhraním
Pokud chcete v kanálu použít aktivitu poznámkového bloku pro Azure Databricks, proveďte následující kroky:
Vyhledejte poznámkový blok v podokně Aktivity kanálu a přetáhněte aktivitu poznámkového bloku na plátno kanálu.
Pokud ještě není vybraná, vyberte na plátně novou aktivitu poznámkového bloku.
Výběrem karty Azure Databricks vyberte nebo vytvořte novou propojenou službu Azure Databricks, která spustí aktivitu poznámkového bloku.
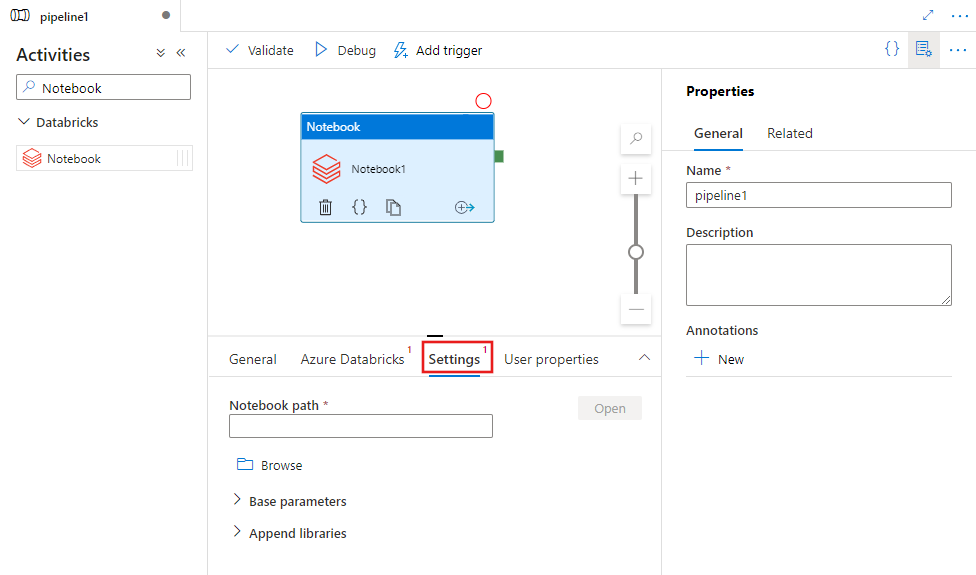
Vyberte kartu Nastavení a zadejte cestu poznámkového bloku, která se má spustit v Azure Databricks, volitelné základní parametry, které se mají předat do poznámkového bloku, a všechny další knihovny, které se mají nainstalovat do clusteru, aby se úloha spustila.
Definice aktivity poznámkového bloku Databricks
Tady je ukázková definice JSON aktivity poznámkového bloku Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Vlastnosti aktivity poznámkového bloku Databricks
Následující tabulka popisuje vlastnosti JSON použité v definici JSON:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| name | Název aktivity v kanálu | Ano |
| description | Text popisující, co aktivita dělá. | No |
| type | U aktivity poznámkového bloku Databricks je typ aktivity DatabricksNotebook. | Ano |
| linkedServiceName | Název propojené služby Databricks, na které běží poznámkový blok Databricks. Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| notebookPath | Absolutní cesta poznámkového bloku, který se má spustit v pracovním prostoru Databricks Tato cesta musí začínat lomítkem. | Ano |
| baseParameters | Pole párů klíč-hodnota. Základní parametry lze použít pro každé spuštění aktivity. Pokud poznámkový blok vezme parametr, který není zadaný, použije se výchozí hodnota z poznámkového bloku. Další informace o parametrech najdete v poznámkových blocích Databricks. | No |
| knihovny | Seznam knihoven, které se mají nainstalovat do clusteru, který spustí úlohu. Může to být pole <řetězce, objektu>. | No |
Podporované knihovny pro aktivity Databricks
V definici aktivity Databricks zadáte tyto typy knihoven: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Další informace najdete v dokumentaci k Databricks pro typy knihoven.
Předávání parametrů mezi poznámkovými bloky a kanály
Parametry můžete předat poznámkovým blokům pomocí vlastnosti baseParameters v aktivitě Databricks.
V některých případech můžete vyžadovat předání určitých hodnot z poznámkového bloku zpět do služby, které se dají použít pro tok řízení (podmíněné kontroly) ve službě nebo spotřebovávat podřízené aktivity (limit velikosti je 2 MB).
V poznámkovém bloku můžete volat dbutils.notebook.exit("returnValue") a odpovídající "returnValue" se vrátí do služby.
Výstup ve službě můžete využívat pomocí výrazu, například
@{activity('databricks notebook activity name').output.runOutput}.Důležité
Pokud předáváte objekt JSON, můžete načíst hodnoty připojením názvů vlastností. Příklad:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Jak nahrát knihovnu v Databricks
Můžete použít uživatelské rozhraní pracovního prostoru:
Použití uživatelského rozhraní pracovního prostoru Databricks
K získání cesty dbfs knihovny přidané pomocí uživatelského rozhraní můžete použít Rozhraní příkazového řádku Databricks.
Knihovny Jar se obvykle ukládají v souboru dbfs:/FileStore/jars při používání uživatelského rozhraní. Seznam všech prostřednictvím rozhraní příkazového řádku: databricks fs ls dbfs:/FileStore/job-jars
Nebo můžete použít rozhraní příkazového řádku Databricks:
Postupujte podle pokynů ke kopírování knihovny pomocí rozhraní příkazového řádku Databricks.
Použití rozhraní příkazového řádku Databricks (kroky instalace)
Například zkopírování souboru JAR do dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar