Formát textu s oddělovači ve službě Azure Data Factory a Azure Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Pokud chcete analyzovat textové soubory s oddělovači nebo zapisovat data do textového formátu s oddělovači, postupujte podle tohoto článku.
Formát textu s oddělovači je podporovaný pro následující konektory:
- Amazon S3
- Úložiště kompatibilní s Amazon S3
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Systém souborů
- FTP
- Cloudové úložiště Googlu
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku Datové sady . Tato část obsahuje seznam vlastností podporovaných datovou sadou s oddělovači.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na Hodnotu DelimitedText. | Ano |
| location | Nastavení umístění souborů Každý konektor založený na souborech má svůj vlastní typ umístění a podporované vlastnosti v části location. |
Ano |
| columnDelimiter | Znaky použité k oddělení sloupců v souboru. Výchozí hodnota je čárka ,. Pokud je oddělovač sloupců definován jako prázdný řetězec, což znamená, že žádný oddělovač, celý řádek se považuje za jeden sloupec.V současné době je oddělovač sloupců jako prázdný řetězec podporován pouze pro mapování toku dat, ale ne pro aktivita Copy. |
No |
| rowDelimiter | Pro aktivita Copy se jeden znak nebo \r\n používá k oddělení řádků v souboru. Výchozí hodnota je libovolná z následujících hodnot při čtení: ["\r\n", "\r", "\n"]; při zápisu: "\r\n". Příkaz \r\n je podporován pouze v příkazu kopírování. Pro mapování toku dat jsou jednotlivé nebo dva znaky použité k oddělení řádků v souboru. Výchozí hodnota je libovolná z následujících hodnot při čtení: ["\r\n", "\r", "\n"]; při zápisu: "\n". Pokud je oddělovač řádků nastavený na žádný oddělovač (prázdný řetězec), musí být oddělovač sloupců nastaven jako žádný oddělovač (prázdný řetězec), což znamená, že celý obsah bude považovat za jedinou hodnotu. V současné době je oddělovač řádků jako prázdný řetězec podporován pouze pro mapování toku dat, ale ne pro aktivita Copy. |
No |
| quoteChar | Jeden znak pro uvozovky hodnoty sloupce, pokud obsahuje oddělovač sloupců. Výchozí hodnota je dvojité uvozovky ". Pokud quoteChar je definován jako prázdný řetězec, znamená to, že neexistuje žádný znak uvozovky a hodnota sloupce není uvozována a escapeChar slouží k uvozování oddělovače sloupců a samotného. |
No |
| escapeChar | Jeden znak pro řídicí uvozovky uvnitř uvozovky. Výchozí hodnota je zpětné lomítko \. Pokud escapeChar je definovaný jako prázdný řetězec, musí být nastavený také jako prázdný řetězec. V takovém případě se ujistěte, quoteChar že všechny hodnoty sloupců neobsahují oddělovače. |
No |
| firstRowAsHeader | Určuje, jestli má být první řádek považován za řádek záhlaví s názvy sloupců. Povolené hodnoty jsou true a false (výchozí). Pokud je první řádek jako záhlaví nepravdivý, všimněte si náhledu dat uživatelského rozhraní a výstupu vyhledávací aktivity automaticky generují názvy sloupců jako Prop_{n} (počínaje 0), aktivita kopírování vyžaduje explicitní mapování ze zdroje na jímku a vyhledá sloupce podle řad (počínaje 1) a mapování seznamů toků dat a vyhledá sloupce s názvem jako Column_{n} (počínaje 1). |
No |
| nullValue | Určuje řetězcovou reprezentaci hodnoty null. Výchozí hodnota je prázdný řetězec. |
No |
| encodingName | Typ kódování použitý k čtení a zápisu testovacích souborů. Povolené hodnoty jsou následující: "UTF-8","UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1255", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Poznámka: Mapování toku dat nepodporuje kódování UTF-7. Poznámka: Mapování toku dat nepodporuje kódování UTF-8 pomocí značky pořadí bajtů (BOM). |
No |
| compressionCodec | Kodek komprese používaný ke čtení a zápisu textových souborů. Povolené hodnoty jsou bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy nebo lz4. Výchozí hodnota není komprimována. Všimněte si, že v současné době aktivita Copy nepodporuje "snappy" & "lz4" a mapování toku dat nepodporuje "ZipDeflate", "TarGzip" a "Tar". Všimněte si, že při dekomprimaci aktivity kopírování dekomprimujte/ soubory TarGzip/Tar a zápis do úložiště dat jímky založené na souborech, ve výchozím nastavení se soubory extrahují do složky: <path specified in dataset>/<folder named as source compressed file>/, pomocí/preserveCompressionFileNameAsFolder preserveZipFileNameAsFolderzdroje aktivity kopírování můžete řídit, zda chcete zachovat název komprimovaných souborů jako strukturu složek. |
No |
| compressionLevel | Poměr komprese. Povolené hodnoty jsou optimální nebo nejrychlejší. - Nejrychlejší: Operace komprese by se měla co nejrychleji dokončit, i když výsledný soubor není optimálně komprimovaný. - Optimální: Operace komprese by měla být optimálně komprimována, i když dokončení operace trvá delší dobu. Další informace naleznete v tématu Úroveň komprese. |
No |
Níže je příklad textové datové sady s oddělovači ve službě Azure Blob Storage:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem textu s oddělovači a jímkou.
Text s oddělovači jako zdroj
Následující vlastnosti jsou podporovány v části aktivity kopírování *source* .
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na DelimitedTextSource. | Ano |
| formatSettings | Skupina vlastností. Níže najdete tabulku nastavení čtení textu s oddělovači. | No |
| storeSettings | Skupina vlastností, jak číst data z úložiště dat. Každý konektor založený na souborech má vlastní podporovaná nastavení čtení v části storeSettings. |
No |
Podporovaná nastavení čtení textu s oddělovači v části formatSettings:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Typ formatSettings musí být nastaven na DelimitedTextReadSettings. | Ano |
| skipLineCount | Určuje počet neprázdných řádků, které se mají přeskočit při čtení dat ze vstupních souborů. Pokud je zadaný parametr skipLineCount i firstRowAsHeader, nejdřív se přeskočí příslušný počet řádků a potom se ze vstupního souboru načtou informace záhlaví. |
No |
| compressionProperties | Skupina vlastností, jak dekomprimovat data pro daný kodek komprese. | No |
| preserveZipFileNameAsFolder (pod compressionProperties->type as ZipDeflateReadSettings) |
Platí, když je vstupní datová sada nakonfigurovaná pomocí komprese ZipDeflate . Určuje, zda chcete zachovat název zdrojového souboru ZIP jako strukturu složek během kopírování. - Pokud je nastavena hodnota true (výchozí), služba zapíše rozbalené soubory do <path specified in dataset>/<folder named as source zip file>/.- Pokud je nastavena na hodnotu false, služba zapíše rozbalené soubory přímo do <path specified in dataset>. Ujistěte se, že v různých zdrojových souborech ZIP nemáte duplicitní názvy souborů, abyste se vyhnuli závodnímu nebo neočekávanému chování. |
No |
| preserveCompressionFileNameAsFolder (pod compressionProperties->type jako TarGZipReadSettings nebo TarReadSettings) |
Platí, když je vstupní datová sada nakonfigurovaná pomocí komprese Tar Tar./ Určuje, zda se má během kopírování zachovat zdrojový komprimovaný název souboru jako struktura složek. - Při nastavení na hodnotu true (výchozí) služba zapíše dekompresované soubory do <path specified in dataset>/<folder named as source compressed file>/. - Pokud je nastavena na hodnotu false, služba zapíše dekomprimované soubory přímo do <path specified in dataset>. Ujistěte se, že v různých zdrojových souborech nemáte duplicitní názvy souborů, abyste se vyhnuli závodnímu nebo neočekávanému chování. |
No |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Text s oddělovači jako jímka
Následující vlastnosti jsou podporovány v části aktivity kopírování *jímka*.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na DelimitedTextSink. | Ano |
| formatSettings | Skupina vlastností. Níže najdete tabulku nastavení zápisu textu s oddělovači. | No |
| storeSettings | Skupina vlastností pro zápis dat do úložiště dat. Každý konektor založený na souborech má vlastní podporovaná nastavení zápisu v části storeSettings. |
No |
Podporovaná nastavení zápisu textu s oddělovači v části formatSettings:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Typ formatSettings musí být nastaven na DelimitedTextWriteSettings. | Ano |
| fileExtension | Přípona souboru sloužící k pojmenování výstupních souborů, .csvnapříklad , . .txt Musí být zadána, pokud fileName není zadána ve výstupní datové sadě DelimitedText. Pokud je název souboru nakonfigurovaný ve výstupní datové sadě, použije se jako název souboru jímky a nastavení přípony souboru bude ignorováno. |
Ano, pokud název souboru není zadaný ve výstupní datové sadě |
| maxRowsPerFile | Při zápisu dat do složky se můžete rozhodnout zapisovat do více souborů a zadat maximální počet řádků na soubor. | No |
| fileNamePrefix | Platí, pokud maxRowsPerFile je nakonfigurováno.Při zápisu dat do více souborů zadejte předponu názvu souboru, výsledkem je tento vzor: <fileNamePrefix>_00000.<fileExtension>. Pokud není zadána, automaticky se vygeneruje předpona názvu souboru. Tato vlastnost se nevztahuje, pokud zdroj je úložiště dat založené na souborech nebo úložiště dat s povolenou možností oddílu. |
No |
Mapování vlastností toku dat
Při mapování toků dat můžete číst a zapisovat do textového formátu s oddělovači v následujících úložištích dat: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 a SFTP a můžete číst textový formát s oddělovači v AmazonU S3.
Vložená datová sada
Mapování toků dat podporuje vložené datové sady jako možnost pro definování zdroje a jímky. Vložená datová sada s oddělovači je definována přímo uvnitř transformace zdroje a jímky a není sdílena mimo definovaný tok dat. Je užitečné pro parametrizaci vlastností datové sady přímo uvnitř toku dat a může těžit z lepšího výkonu ze sdílených datových sad ADF.
Při čtení velkého počtu zdrojových složek a souborů můžete zlepšit výkon zjišťování souborů toku dat nastavením možnosti "Projektované schéma uživatele" uvnitř projekce | Dialogové okno Možnosti schématu Tato možnost vypne výchozí automatické zjišťování schématu ADF a výrazně zlepší výkon zjišťování souborů. Před nastavením této možnosti nezapomeňte naimportovat projekci, aby služba ADF má existující schéma pro projekci. Tato možnost nefunguje s posunem schématu.
Vlastnosti zdroje
V následující tabulce jsou uvedeny vlastnosti podporované zdrojem textu s oddělovači. Tyto vlastnosti můžete upravit na kartě Možnosti zdroje.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Cesty se zástupnými kartami | Zpracují se všechny soubory odpovídající cestě se zástupným znakem. Přepíše složku a cestu k souboru nastavenou v datové sadě. | ne | Řetězec[] | Zástupné cardPaths |
| Kořenová cesta oddílu | Pro data souborů rozdělená do oddílů můžete zadat kořenovou cestu oddílu, abyste mohli číst dělené složky jako sloupce. | ne | String | partitionRootPath |
| Seznam souborů | Určuje, jestli váš zdroj ukazuje na textový soubor se seznamem souborů, které se mají zpracovat. | ne | true nebo false |
fileList |
| Víceřádkové řádky | Obsahuje zdrojový soubor řádky, které pokrývají více řádků. Víceřádkové hodnoty musí být v uvozovkách. | ne true nebo false |
multiLineRow | |
| Sloupec pro uložení názvu souboru | Vytvoření nového sloupce s názvem zdrojového souboru a cestou | ne | String | rowUrlColumn |
| Po dokončení | Soubory po zpracování odstraňte nebo přesuňte. Cesta k souboru začíná z kořenového adresáře kontejneru. | ne | Odstranit: true nebo false Pohnout: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrovat podle poslední změny | Zvolte filtrování souborů na základě toho, kdy byly naposledy změněny. | ne | Časové razítko | modifiedAfter modifiedBefore |
| Povolit žádné nalezené soubory | Pokud je pravda, chyba se nevyvolá, pokud se nenašly žádné soubory. | ne | true nebo false |
ignoreNoFilesFound |
| Maximální počet sloupců | Výchozí hodnota je 20480. Přizpůsobte tuto hodnotu, pokud je číslo sloupce více než 20480. | ne | Celé číslo | maxColumns |
Poznámka:
Podpora zdrojů toků dat pro seznam souborů je omezená na 1024 položek v souboru. Pokud chcete do seznamu souborů zahrnout více souborů, použijte zástupné cardy.
Příklad zdroje
Následující obrázek je příkladem konfigurace zdroje textu s oddělovači při mapování toků dat.
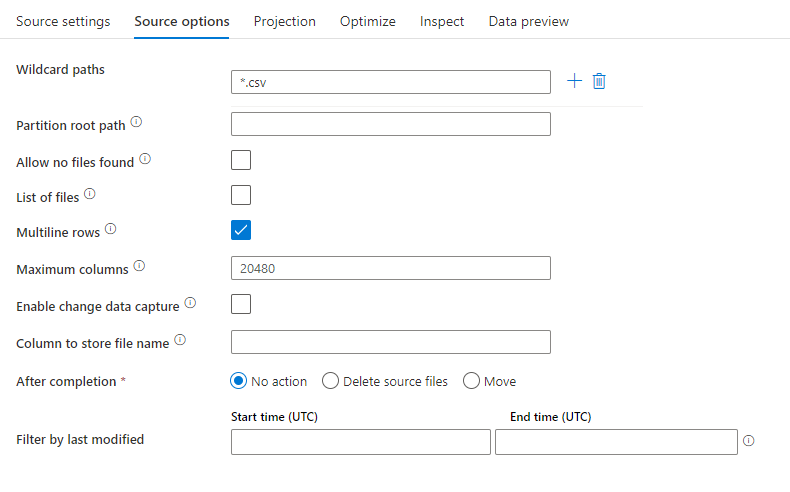
Přidružený skript toku dat je:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Poznámka:
Zdroje toků dat podporují omezenou sadu linuxových globbingů podporovaných systémy souborů Hadoop.
Vlastnosti jímky
V následující tabulce jsou uvedeny vlastnosti podporované jímkou textu s oddělovači. Tyto vlastnosti můžete upravit na kartě Nastavení .
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Vymazání složky | Pokud je cílová složka před zápisem vymazána. | ne | true nebo false |
truncate |
| Možnost názvu souboru | Formát pojmenování zapsaných dat. Ve výchozím nastavení je ve formátu jeden soubor na oddíl. part-#####-tid-<guid> |
ne | Vzor: Řetězec Na oddíl: String[] Název souboru jako dat sloupců: Řetězec Výstup do jednoho souboru: ['<fileName>'] Name folder as column data: String |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Citace vše | Uzavření všech hodnot do uvozovek | ne | true nebo false |
QuoteAll |
| Hlavička | Přidání hlaviček zákazníka do výstupních souborů | ne | [<string array>] |
záhlaví |
Příklad jímky
Následující obrázek je příkladem konfigurace jímky textu s oddělovači při mapování toků dat.
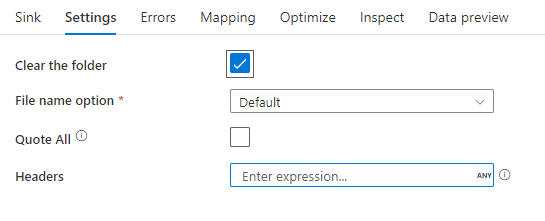
Přidružený skript toku dat je:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Související konektory a formáty
Tady jsou některé běžné spojnice a formáty související s formátem textu s oddělovači:
- Azure Blob Storage
- Binární formát
- Dataverse
- Formát Delta
- Formát aplikace Excel
- Systém souborů
- FTP
- HTTP
- Formát JSON
- Formát Parquet