Rozdílový formát ve službě Azure Data Factory
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak kopírovat data do a z delta lake uloženého v Azure Data Lake Store Gen2 nebo Azure Blob Storage pomocí rozdílového formátu. Tento konektor je k dispozici jako vložená datová sada při mapování toků dat jako zdroj i jímka.
Mapování vlastností toku dat
Tento konektor je k dispozici jako vložená datová sada při mapování toků dat jako zdroj i jímka.
Vlastnosti zdroje
V následující tabulce jsou uvedeny vlastnosti podporované rozdílovým zdrojem. Tyto vlastnosti můžete upravit na kartě Možnosti zdroje.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Formát | Formát musí být delta |
ano | delta |
format |
| Systém souborů | Systém kontejnerů a souborů delta lake | ano | String | fileSystem |
| Folder path | Adresář delta lake | ano | String | folderPath |
| Typ komprese | Typ komprese tabulky Delta | ne | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Compression level | Zvolte, jestli se komprese co nejrychleji dokončí, nebo jestli by výsledný soubor měl být optimálně komprimován. | povinné, pokud compressedType je zadáno. |
Optimal nebo Fastest |
compressionLevel |
| Časová cesta | Zvolte, jestli se má dotazovat na starší snímek tabulky Delta. | ne | Dotaz podle časového razítka: Časové razítko Dotaz podle verze: Celé číslo |
timestampAsOf versionAsOf |
| Povolit žádné nalezené soubory | Pokud je hodnota true, chyba se nevyvolá, pokud se nenašly žádné soubory. | ne | true nebo false |
ignoreNoFilesFound |
Import schématu
Delta je k dispozici pouze jako vložená datová sada a ve výchozím nastavení nemá přidružené schéma. Pokud chcete získat metadata sloupců, klikněte na tlačítko Importovat schéma na kartě Projekce . To vám umožní odkazovat na názvy sloupců a datové typy určené korpusem. Pokud chcete importovat schéma, musí být aktivní ladicí relace toku dat a musíte mít existující definiční soubor entity CDM, na který má odkazovat.
Příklad zdrojového skriptu Delta
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Vlastnosti jímky
Následující tabulka uvádí vlastnosti podporované rozdílovou jímkou. Tyto vlastnosti můžete upravit na kartě Nastavení .
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Formát | Formát musí být delta |
ano | delta |
format |
| Systém souborů | Systém kontejnerů a souborů delta lake | ano | String | fileSystem |
| Folder path | Adresář delta lake | ano | String | folderPath |
| Typ komprese | Typ komprese tabulky Delta | ne | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Compression level | Zvolte, jestli se komprese co nejrychleji dokončí, nebo jestli by výsledný soubor měl být optimálně komprimován. | povinné, pokud compressedType je zadáno. |
Optimal nebo Fastest |
compressionLevel |
| Vacuum | Odstraní soubory starší než zadaná doba trvání, která už není relevantní pro aktuální verzi tabulky. Pokud je zadaná hodnota 0 nebo menší, neprovádí se operace vakua. | ano | Celé číslo | vysát |
| Akce tabulky | Řekne ADF, co dělat s cílovou tabulkou Delta ve vaší jímce. Můžete ji ponechat tak, jak je, a přidat nové řádky, přepsat existující definici tabulky a data novými metadaty a daty, nebo zachovat existující strukturu tabulky, ale nejprve zkrátit všechny řádky a pak vložit nové řádky. | ne | None, Truncate, Overwrite | deltaTruncate, přepsání |
| Metoda aktualizace | Když vyberete možnost Povolit vložení samostatně nebo když zapíšete do nové tabulky delta, cíl přijme všechny příchozí řádky bez ohledu na nastavené zásady řádků. Pokud data obsahují řádky jiných zásad řádků, je potřeba je vyloučit pomocí předchozí transformace filtru. Pokud jsou vybrány všechny metody Aktualizace sloučení, kde jsou řádky vloženy, odstraněny, upserted/aktualizovány podle zásad řádků nastavené pomocí předchozí transformace Alter Row. |
ano | true nebo false |
vložitelné s možností odsud upsertable aktualizovatelné |
| Optimalizovaný zápis | Dosažení vyšší propustnosti operace zápisu prostřednictvím optimalizace interního náhodného prohazování v exekutorech Sparku. V důsledku toho si můžete všimnout menšího počtu oddílů a souborů, které mají větší velikost. | ne | true nebo false |
optimizedWrite: true |
| Automaticky zkomprimovat | Po dokončení jakékoli operace zápisu OPTIMIZE Spark automaticky spustí příkaz k opětovnému uspořádání dat, což v případě potřeby povede k dalším oddílům, aby se v budoucnu zlepšil výkon čtení. |
ne | true nebo false |
autoCompact: true |
Příklad skriptu jímky Delta
Přidružený skript toku dat je:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Rozdílová jímka s vyřezáváním oddílů
S touto možností v části Metoda Update výše (tj. update/upsert/delete) můžete omezit počet zkontrolovaných oddílů. Z cílového úložiště se načítají pouze oddíly, které splňují tuto podmínku. Můžete zadat pevnou sadu hodnot, které může sloupec oddílu trvat.
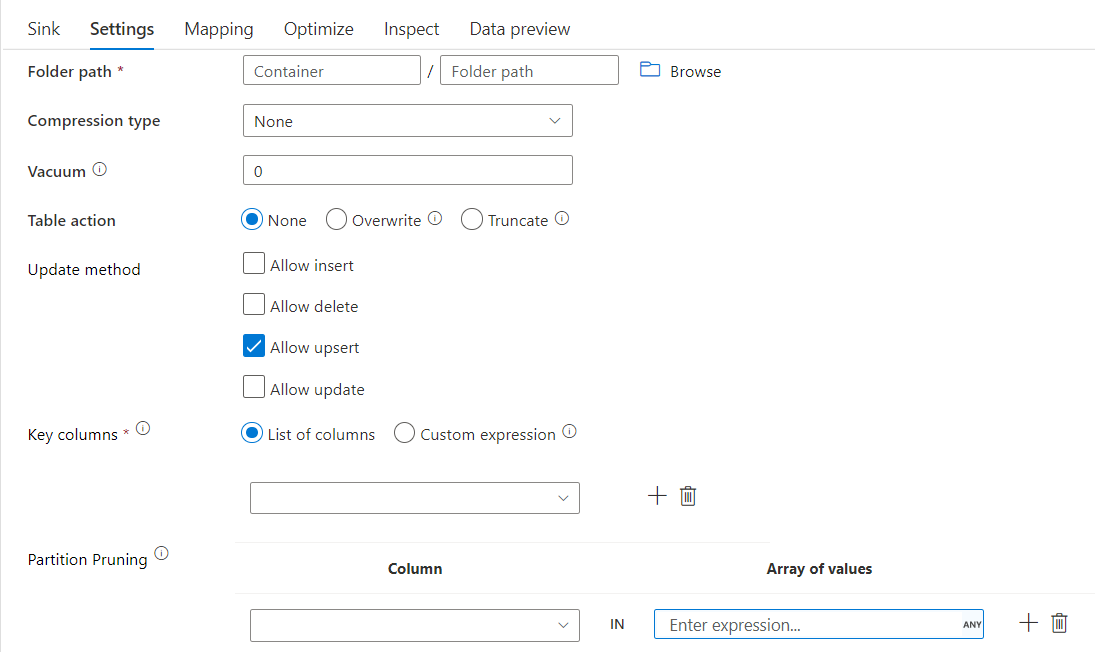
Příklad skriptu jímky Delta s vyřezáváním oddílů
Ukázkový skript je uveden níže.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta bude číst pouze 2 oddíly, kde part_col == 5 a 8 z cílového rozdílového úložiště místo všech oddílů. part_col je sloupec, podle kterého jsou cílová rozdílová data rozdělena. Nemusí se nacházet ve zdrojových datech.
Možnosti optimalizace jímky Delta
Na kartě Nastavení najdete tři další možnosti pro optimalizaci transformace delta jímky.
Pokud je povolená možnost sloučit schéma, umožňuje vývoj schématu , tj. všechny sloupce, které jsou přítomné v aktuálním příchozím datovém proudu, ale ne v cílové tabulce Delta, se do schématu automaticky přidají. Tato možnost je podporována napříč všemi metodami aktualizace.
Pokud je povolená funkce Automatické komprimace , po individuálním zápisu transformace zkontroluje, jestli je možné soubory dále zkomprimovat, a spustí rychlou úlohu OPTIMIZE (s velikostí 128 MB místo 1 GB), aby bylo možné dále komprimovat soubory pro oddíly, které mají největší počet malých souborů. Automatické komprimace pomáhá při zkomprimování velkého počtu malých souborů do menšího počtu velkých souborů. Automatické komprimace se spustí jenom v případech, kdy je nejméně 50 souborů. Po provedení operace komprimace vytvoří novou verzi tabulky a zapíše nový soubor obsahující data několika předchozích souborů v komprimované podobě.
Pokud je povoleno optimalizovat zápis , transformace jímky dynamicky optimalizuje velikosti oddílů na základě skutečných dat tím, že se pokusí zapsat 128 MB souborů pro každý oddíl tabulky. Jedná se o přibližnou velikost a může se lišit v závislosti na vlastnostech datové sady. Optimalizované zápisy zlepšují celkovou efektivitu zápisů a následných čtení. Uspořádá oddíly tak, aby se zlepšil výkon následných čtení.
Tip
Optimalizovaný proces zápisu zpomalí vaši celkovou úlohu ETL, protože po zpracování dat vydá jímka příkaz Spark Delta Lake Optimize. Doporučuje se používat optimalizované zápisy střídmě. Pokud máte například hodinový datový kanál, spusťte tok dat s optimalizovaným zápisem denně.
Známá omezení
Při zápisu do rozdílové jímky existuje známé omezení, kdy se počet zapsaných řádků ve výstupu monitorování nezobrazí.
Související obsah
- Vytvoření transformace zdroje při mapování toku dat
- Vytvořte transformaci jímky při mapování toku dat.
- Vytvořte změnu transformace řádku, která označí řádky jako vložení, aktualizaci, upsert nebo odstranění.