Kopírování a transformace dat ve službě Azure Database for PostgreSQL pomocí služby Azure Data Factory nebo Synapse Analytics
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory a Synapse Analytics kopírovat data z a do Azure Database for PostgreSQL a pomocí Tok dat transformovat data ve službě Azure Database for PostgreSQL. Další informace najdete v úvodních článcích pro Azure Data Factory a Synapse Analytics.
Tento konektor je specializovaný pro službu Azure Database for PostgreSQL. Ke kopírování dat z obecné databáze PostgreSQL umístěné místně nebo v cloudu použijte konektor PostgreSQL.
Podporované funkce
Tento konektor Azure Database for PostgreSQL je podporovaný pro následující funkce:
| Podporované funkce | IR | Spravovaný privátní koncový bod |
|---|---|---|
| aktivita Copy (zdroj/jímka) | (1) (2) | ✓ |
| Mapování toku dat (zdroj/jímka) | (1) | ✓ |
| Aktivita Lookup | (1) (2) | ✓ |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Tři aktivity fungují na všech možnostech nasazení Azure Database for PostgreSQL:
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby se službou Azure Database for PostgreSQL pomocí uživatelského rozhraní
Pomocí následujícího postupu vytvořte propojenou službu se službou Azure Database for PostgreSQL v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte PostgreSQL a vyberte konektor Azure Database for PostgreSQL.
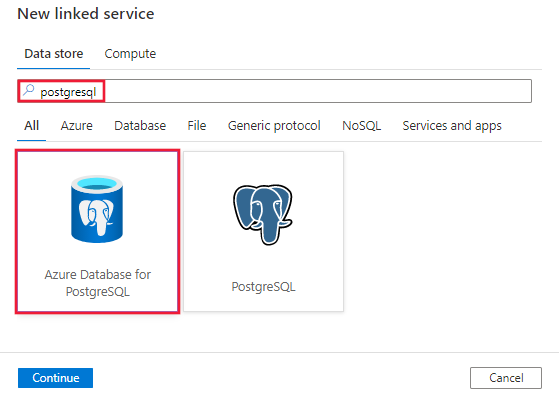
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
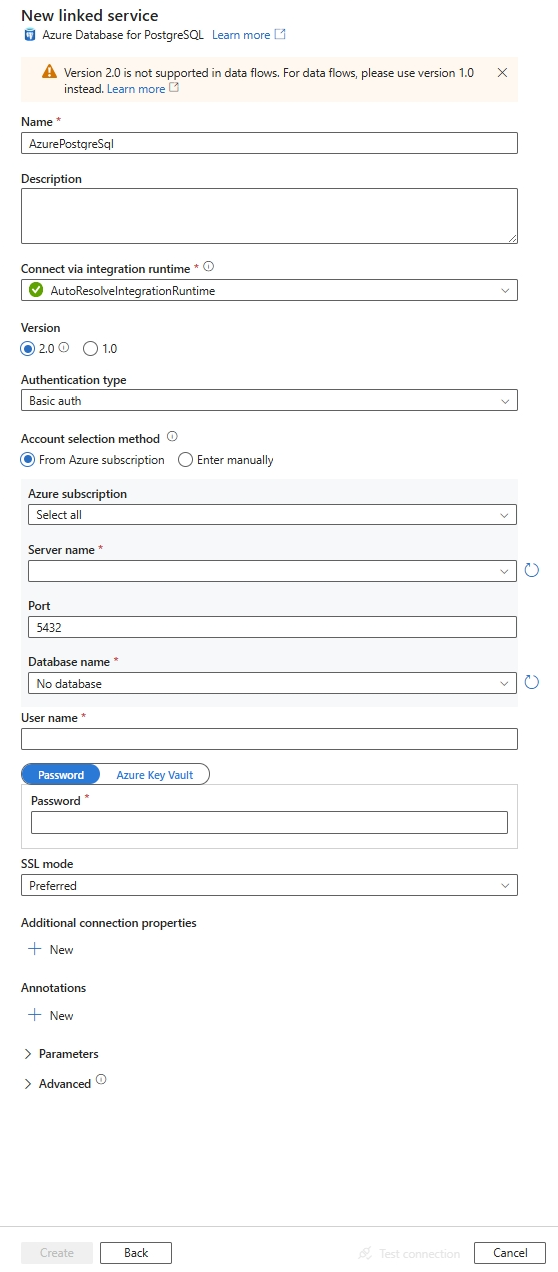
Podrobnosti konfigurace konektoru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit služby Data Factory specifických pro konektor Azure Database for PostgreSQL.
Vlastnosti propojené služby
Propojená služba Azure Database for PostgreSQL podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na: AzurePostgreSql. | Ano |
| připojovací řetězec | Rozhraní ODBC připojovací řetězec pro připojení ke službě Azure Database for PostgreSQL. Do služby Azure Key Vault můžete také zadat heslo a vytáhnout password konfiguraci z připojovací řetězec. Další podrobnosti najdete v následujících ukázkách a přihlašovacích údajích k úložišti přihlašovacích údajů ve službě Azure Key Vault . |
Ano |
| connectVia | Tato vlastnost představuje prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud je vaše úložiště dat umístěné v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Typický připojovací řetězec je Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Tady jsou další vlastnosti, které můžete nastavit pro každý případ:
| Vlastnost | Popis | Možnosti | Požaduje se |
|---|---|---|---|
| EncryptionMethod (EM) | Metoda, pomocí které ovladač šifruje data odesílaná mezi ovladačem a databázovým serverem. Například EncryptionMethod=<0/1/6>; |
0 (bez šifrování) (výchozí) / 1 (SSL) / 6 (požadavky) | No |
| ValidateServerCertificate (VSC) | Určuje, jestli ovladač ověří certifikát odeslaný databázovým serverem, když je povolené šifrování SSL (Metoda šifrování =1). Například ValidateServerCertificate=<0/1>; |
0 (zakázáno) (výchozí) / 1 (povoleno) | No |
Příklad:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Příklad:
Uložení hesla ve službě Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v tématu Datové sady. Tato část obsahuje seznam vlastností, které Azure Database for PostgreSQL podporuje v datových sadách.
Pokud chcete kopírovat data z Azure Database for PostgreSQL, nastavte vlastnost typu datové sady na AzurePostgreSqlTable. Podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavená na AzurePostgreSqlTable. | Ano |
| tableName | Název tabulky | Ne (pokud je zadán dotaz ve zdroji aktivity) |
Příklad:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v tématu Kanály a aktivity. Tato část obsahuje seznam vlastností podporovaných zdrojem Azure Database for PostgreSQL.
Azure Database for PostgreSql jako zdroj
Pokud chcete kopírovat data ze služby Azure Database for PostgreSQL, nastavte typ zdroje v aktivitě kopírování na AzurePostgreSqlSource. Ve zdrojové části aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavená na AzurePostgreSqlSource. | Ano |
| query | Ke čtení dat použijte vlastní dotaz SQL. Například: SELECT * FROM mytable nebo SELECT * FROM "MyTable". Všimněte si, že v PostgreSQL se název entity považuje za nerozlišující velká a malá písmena, pokud ne. |
Ne (pokud je zadána vlastnost tableName v datové sadě) |
| queryTimeout | Doba čekání před ukončením pokusu o spuštění příkazu a vygenerováním chyby je výchozí 120 minut. Pokud je pro tuto vlastnost nastaven parametr, jsou povolené hodnoty časový rozsah, například 02:00:00 (120 minut). Další informace najdete v tématu CommandTimeout. | No |
| partitionOptions | Určuje možnosti dělení dat, které se používají k načtení dat z Azure SQL Database. Povolené hodnoty jsou: None (výchozí), PhysicalPartitionsOfTable a DynamicRange. Pokud je povolená možnost oddílu (tj. ne None), stupeň paralelismu pro souběžné načítání dat z Azure SQL Database se řídí parallelCopies nastavením aktivity kopírování. |
No |
| partitionSettings | Zadejte skupinu nastavení pro dělení dat. Použít, pokud možnost oddílu není None. |
No |
V části partitionSettings: |
||
| partitionNames | Seznam fyzických oddílů, které je potřeba zkopírovat. Použít, pokud je PhysicalPartitionsOfTablemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfTabularPartitionName do klauzule WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL . |
No |
| partitionColumnName | Zadejte název zdrojového sloupce v celočíselném čísle nebo typu date/datetime (int, smallint, bigint, date, timestamp with time zonetimestamp without time zonenebo time without time zone), který bude použit dělením rozsahu pro paralelní kopírování. Pokud není zadaný, primární klíč tabulky se automaticky rozpozná a použije se jako sloupec oddílu.Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionColumnName do klauzule WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL . |
No |
| partitionUpperBound | Maximální hodnota sloupce oddílu pro zkopírování dat. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionUpbound do klauzule WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL . |
No |
| partitionLowerBound | Minimální hodnota sloupce oddílu pro zkopírování dat. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionLowbound do klauzule WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL . |
No |
Příklad:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for PostgreSQL jako jímka
Pokud chcete kopírovat data do služby Azure Database for PostgreSQL, podporují se v části jímky aktivity kopírování následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu jímky aktivity kopírování musí být nastavena na AzurePostgreSQLSink. | Ano |
| preCopyScript | Zadejte dotaz SQL pro aktivitu kopírování, který se má provést před zápisem dat do služby Azure Database for PostgreSQL v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat. | No |
| writeMethod | Metoda použitá k zápisu dat do služby Azure Database for PostgreSQL. Povolené hodnoty jsou: CopyCommand (výchozí, což je výkonnější), BulkInsert. |
No |
| writeBatchSize | Počet řádků načtených do služby Azure Database for PostgreSQL na dávku Povolená hodnota je celé číslo, které představuje počet řádků. |
Ne (výchozí hodnota je 1 000 000) |
| writeBatchTimeout | Počkejte, než se operace dávkového vložení dokončí, než vyprší časový limit. Povolené hodnoty jsou řetězce časového rozsahu. Příklad je 00:30:00 (30 minut). |
Ne (výchozí hodnota je 00:30:00) |
Příklad:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Paralelní kopírování ze služby Azure Database for PostgreSQL
Konektor Azure Database for PostgreSQL v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.
Když povolíte dělené kopírování, aktivita kopírování spustí paralelní dotazy na zdroj Azure Database for PostgreSQL, aby načetla data podle oddílů. Paralelní stupeň se řídí parallelCopies nastavením aktivity kopírování. Pokud například nastavíte parallelCopies hodnotu čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z vaší služby Azure Database for PostgreSQL.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat ze služby Azure Database for PostgreSQL. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly |
Možnost oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. |
| Úplné načtení z velké tabulky bez fyzických oddílů, zatímco s celočíselnou sloupcem pro dělení dat. |
Možnosti oddílu: Oddíl dynamického rozsahu Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Pokud není zadaný, použije se sloupec primárního klíče. |
| Načtěte velké množství dat pomocí vlastního dotazu s fyzickými oddíly. |
Možnost oddílu: Fyzické oddíly tabulky. Dotaz: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Název oddílu: Zadejte názvy oddílů, ze které chcete kopírovat data. Pokud není zadaný, služba automaticky rozpozná fyzické oddíly v tabulce, kterou jste zadali v datové sadě PostgreSQL. Během provádění služba nahradí ?AdfTabularPartitionName skutečným názvem oddílu a odešle ji do služby Azure Database for PostgreSQL. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, zatímco u celočíselného sloupce pro dělení dat. |
Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Sloupec můžete rozdělit na celé číslo nebo datový typ date/datetime. Horní mez oddílu a dolní mez oddílu: Určete, jestli chcete filtrovat podle sloupce oddílu a načítat data pouze mezi dolním a horním rozsahem. Během provádění služba nahradí ?AdfRangePartitionColumnNamea ?AdfRangePartitionUpboundza skutečný název sloupce a ?AdfRangePartitionLowbound rozsahy hodnot pro každý oddíl a odešle do služby Azure Database for PostgreSQL. Pokud je například sloupec oddílu "ID" nastavený s dolní mezí jako 1 a horní mez jako 80, s paralelní sadou kopírování nastavenou jako 4, služba načte data o 4 oddíly. Jejich ID jsou mezi [1,20], [21, 40], [41, 60] a [61, 80], v uvedeném pořadí. |
Osvědčené postupy pro načtení dat s možností oddílu:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje předdefinovaný oddíl, použijte možnost oddílu Fyzické oddíly tabulky, abyste dosáhli lepšího výkonu.
- Pokud ke kopírování dat používáte Prostředí Azure Integration Runtime, můžete nastavit větší počet jednotek Integrace Dat (DIU) (>4) a využít tak více výpočetních prostředků. Zkontrolujte tam příslušné scénáře.
- "Stupeň paralelismu kopírování" řídí čísla oddílů, nastavení příliš velkého čísla někdy snižuje výkon, doporučujeme nastavit toto číslo jako (DIU nebo počet uzlů místního prostředí IR) * (2 až 4).
Příklad: Úplné načtení z velké tabulky s fyzickými oddíly
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Příklad: Dotaz s oddílem dynamického rozsahu
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Mapování vlastností toku dat
Při transformaci dat v mapování toku dat můžete číst a zapisovat do tabulek ze služby Azure Database for PostgreSQL. Další informace najdete v tématu transformace zdroje a transformace jímky v mapování toků dat. Jako typ zdroje a jímky můžete použít datovou sadu Azure Database for PostgreSQL nebo vloženou datovou sadu .
Transformace zdroje
Následující tabulka uvádí vlastnosti podporované zdrojem Azure Database for PostgreSQL. Tyto vlastnosti můžete upravit na kartě Možnosti zdroje.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Table | Pokud jako vstup vyberete tabulku, tok dat načte všechna data z tabulky zadané v datové sadě. | No | - |
(pouze pro vloženou datovou sadu) tableName |
| Dotaz | Pokud jako vstup vyberete Dotaz, zadejte dotaz SQL pro načtení dat ze zdroje, který přepíše jakoukoli tabulku, kterou zadáte v datové sadě. Použití dotazů je skvělý způsob, jak snížit počet řádků pro testování nebo vyhledávání. Klauzule Order By není podporovaná, ale můžete nastavit úplný příkaz SELECT FROM. Můžete také použít uživatelem definované funkce tabulek. select * from udfGetData() je UDF v SQL, která vrací tabulku, kterou můžete použít v toku dat. Příklad dotazu: select * from mytable where customerId > 1000 and customerId < 2000 nebo select * from "MyTable". Všimněte si, že v PostgreSQL se název entity považuje za nerozlišující velká a malá písmena, pokud ne. |
No | String | query |
| Název schématu | Pokud jako vstup vyberete Uložená procedura, zadejte název schématu uložené procedury nebo vyberte Aktualizovat a požádejte službu o zjištění názvů schémat. | No | String | schemaName |
| Uložená procedura | Pokud jako vstup vyberete Uložená procedura, zadejte název uložené procedury pro čtení dat ze zdrojové tabulky nebo vyberte Aktualizovat a požádejte službu o zjištění názvů procedur. | Ano (pokud jako vstup vyberete uloženou proceduru) | String | procedureName |
| Parametry procedury | Pokud jako vstup vyberete Uložená procedura, zadejte všechny vstupní parametry pro uloženou proceduru v pořadí nastaveném v rámci procedury, nebo vyberte importovat všechny parametry procedury pomocí formuláře @paraName. |
No | Pole | vstupy |
| Velikost dávky | Zadejte velikost dávky pro rozdělení velkých dat do dávek. | No | Celé číslo | batchSize |
| Úroveň izolace | Zvolte jednu z následujících úrovní izolace: - Přečteno potvrzeno – Nepotvrzené čtení (výchozí) - Opakovatelné čtení -Serializovatelný – Žádné (ignorovat úroveň izolace) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZOVATELNÝ ŽÁDNÝ |
isolationLevel |
Ukázkový zdrojový skript Azure Database for PostgreSQL
Pokud jako typ zdroje použijete Azure Database for PostgreSQL, přidružený skript toku dat:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Transformace jímky
Následující tabulka uvádí vlastnosti podporované jímkou Azure Database for PostgreSQL. Tyto vlastnosti můžete upravit na kartě Možnosti jímky.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Metoda aktualizace | Určete, jaké operace jsou povolené v cíli databáze. Výchozí hodnota je povolit pouze vkládání. Pokud chcete aktualizovat, upsertovat nebo odstranit řádky, je k označení řádků pro tyto akce potřeba transformace alter řádku. |
Ano |
true nebo false |
s možností odsud vložitelné aktualizovatelné upsertable |
| Klíčové sloupce | U aktualizací, upsertů a odstranění je nutné nastavit klíčové sloupce, aby bylo možné určit, který řádek se má změnit. Název sloupce, který vyberete jako klíč, se použije jako součást následné aktualizace, upsertu a odstranění. Proto je nutné vybrat sloupec, který existuje v mapování jímky. |
No | Pole | keys |
| Přeskočení psaní klíčových sloupců | Pokud chcete hodnotu nezapsat do klíčového sloupce, vyberte Přeskočit psaní klíčových sloupců. | No |
true nebo false |
skipKeyWrites |
| Akce tabulky | Určuje, zda se mají před zápisem znovu vytvořit nebo odebrat všechny řádky z cílové tabulky. - Žádné: V tabulce se neprovede žádná akce. - Znovu vytvořte: Tabulka se přehodí a znovu vytvoří. Vyžaduje se při dynamickém vytváření nové tabulky. - Zkrácení: Odeberou se všechny řádky z cílové tabulky. |
No |
true nebo false |
obnovit truncate |
| Velikost dávky | Určete, kolik řádků se zapisuje v každé dávce. Větší velikosti dávek zlepšují kompresi a optimalizaci paměti, ale při ukládání dat do mezipaměti riskují výjimky z paměti. | No | Celé číslo | batchSize |
| Výběr schématu databáze uživatele | Ve výchozím nastavení se ve schématu jímky vytvoří dočasná tabulka jako pracovní. Alternativně můžete zrušit zaškrtnutí možnosti Použít schéma jímky a místo toho zadat název schématu, pod kterým Služba Data Factory vytvoří pracovní tabulku pro načtení nadřazených dat a automaticky je po dokončení vyčistí. Ujistěte se, že máte v databázi oprávnění k vytvoření tabulky, a upravte oprávnění ke schématu. | No | String | stagingSchemaName |
| Skripty pre a post SQL | Zadejte víceřádkové skripty SQL, které se spustí před (předzpracování) a po (po zpracování) dat zapisují do databáze jímky. | No | String | předsqls postSQLs |
Tip
- Doporučujeme rozdělit jednotlivé dávkové skripty několika příkazy do několika dávek.
- Jako součást dávky je možné spustit pouze příkazy DDL (Data Definition Language) a DML (Data Manipulation Language), které vracejí jednoduchý počet aktualizací. Další informace o provádění dávkových operací
Povolit přírůstkový extrahování: Pomocí této možnosti můžete službě ADF sdělit, aby zpracovávaly pouze řádky, které se od posledního spuštění kanálu změnily.
Přírůstkový sloupec: Při použití funkce přírůstkového extrakce musíte zvolit sloupec data a času nebo číselného sloupce, který chcete použít jako vodoznak ve zdrojové tabulce.
Začněte číst od začátku: Nastavení této možnosti přírůstkovým extrahováním dá ADF pokyn ke čtení všech řádků při prvním spuštění kanálu se zapnutým přírůstkovým extrahováním.
Ukázkový skript jímky Azure Database for PostgreSQL
Pokud jako typ jímky použijete Azure Database for PostgreSQL, přidružený skript toku dat:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Vlastnosti aktivity vyhledávání
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v tématu Podporované úložiště dat.