Optimalizace jímek
Když toky dat zapisují do jímek, dojde k jakémukoli vlastnímu dělení bezprostředně před zápisem. Podobně jako u zdroje se ve většině případů doporučuje, abyste jako vybranou možnost oddílu ponecháli aktuální dělení . Dělená data zapisují mnohem rychleji než nerozdělovaná data, i když cíl není rozdělený na oddíly. Následují jednotlivé aspekty různých typů jímky.
Jímky azure SQL Database
Ve většině případů by ve službě Azure SQL Database mělo fungovat výchozí dělení. Je možné, že vaše jímka může mít příliš mnoho oddílů, aby vaše databáze SQL zpracovávala. Pokud na to narazíte, snižte počet oddílů vysílaných jímkou služby SQL Database.
Osvědčený postup odstranění řádků v jímce na základě chybějících řádků ve zdroji
Tady je video s návodem, jak používat toky dat s existujícími transformacemi, měnit řádky a jímky, abyste dosáhli tohoto běžného vzoru:
Dopad zpracování řádků chyb na výkon
Když v transformaci jímky povolíte zpracování řádků chyb (pokračovat při chybě), služba před zápisem kompatibilních řádků do cílové tabulky provede další krok. Tento dodatečný krok má malé snížení výkonu, které může být v rozsahu 5 % přidáno pro tento krok s dodatečným malým výkonem, pokud jste také nastavili možnost zapisovat nekompatibilní řádky do souboru protokolu.
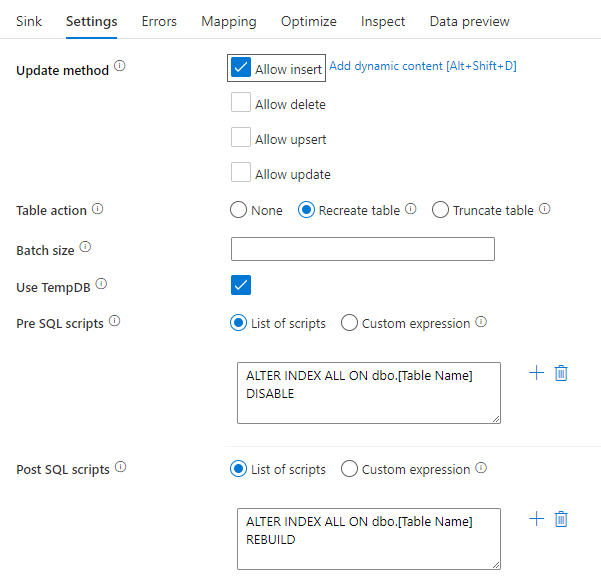
Zakázání indexů pomocí skriptu SQL
Zakázání indexů před načtením v databázi SQL může výrazně zlepšit výkon zápisu do tabulky. Před zápisem do jímky SQL spusťte následující příkaz.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Po dokončení zápisu znovu sestavte indexy pomocí následujícího příkazu:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Můžete je provést nativně pomocí skriptů Pre a Post-SQL v rámci jímky Azure SQL Database nebo Synapse při mapování toků dat.
Upozorňující
Při zakazování indexů tok dat v současnosti přebírá kontrolu nad databází a dotazy pravděpodobně úspěšně. V důsledku toho se uprostřed noci aktivuje mnoho úloh ETL, aby se zabránilo tomuto konfliktu. Další informace o omezeních zakázání indexů SQL
Vertikální navýšení kapacity databáze
Před spuštěním kanálu naplánujte změnu velikosti zdrojové databáze a datového skladu azure SQL a jímky, abyste zvýšili propustnost a minimalizovali omezování Azure, jakmile dosáhnete limitů DTU. Po dokončení provádění kanálu změňte velikost databází zpět na jejich normální rychlost spuštění.
Jímky Azure Synapse Analytics
Při zápisu do Azure Synapse Analytics se ujistěte, že je možnost Povolit přípravu nastavená na true. To službě umožňuje zapisovat pomocí příkazu SQL COPY, který efektivně načte data hromadně. Při použití přípravy budete muset odkazovat na účet Azure Data Lake Storage Gen2 nebo Azure Blob Storage.
Kromě přípravy platí stejné osvědčené postupy pro Azure Synapse Analytics jako Azure SQL Database.
Jímky založené na souborech
I když toky dat podporují různé typy souborů, pro optimální dobu čtení a zápisu se doporučuje nativní formát Parquet pro Spark.
Pokud jsou data rovnoměrně distribuovaná, použijte aktuální dělení , je nejrychlejší možností dělení na oddíly pro zápis souborů.
Možnosti názvu souboru
Při psaní souborů máte možnost pojmenování, které mají každý vliv na výkon.
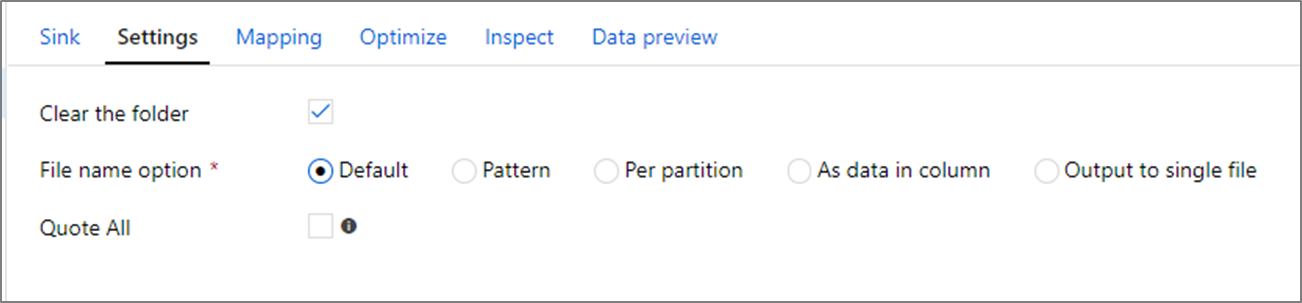
Výběr výchozí možnosti zapíše nejrychlejší zápis. Každý oddíl odpovídá souboru s výchozím názvem Sparku. To je užitečné, pokud právě čtete ze složky dat.
Nastavení vzoru pojmenování přejmenuje každý soubor oddílu na uživatelsky přívětivější název. K této operaci dochází po zápisu a je o něco pomalejší než volba výchozího nastavení.
Každý oddíl umožňuje ručně pojmenovat jednotlivé oddíly.
Pokud sloupec odpovídá způsobu výstupu dat, můžete jako data sloupce vybrat název souboru. Tato změna prohodí data a může ovlivnit výkon, pokud sloupce nejsou rovnoměrně distribuované.
Pokud sloupec odpovídá způsobu, jakým chcete generovat názvy složek, vyberte složku Název jako data sloupce.
Výstup do jednoho souboru kombinuje všechna data do jednoho oddílu. To vede k dlouhým časem zápisu, zejména u velkých datových sad. Tato možnost se nedoporučuje, pokud neexistuje explicitní obchodní důvod k jeho použití.
Jímky azure Cosmos DB
Když píšete do služby Azure Cosmos DB, může změna propustnosti a velikosti dávky během provádění toku dat zvýšit výkon. Tyto změny se projeví jenom během spuštění aktivity toku dat a po uzavření se vrátí do původního nastavení kolekce.
Velikost dávky: Obvykle stačí výchozí velikost dávky. Pokud chcete tuto hodnotu dále ladit, vypočítejte hrubou velikost objektu dat a ujistěte se, že velikost objektu * velikost dávky je menší než 2 MB. Pokud ano, můžete zvětšit velikost dávky, abyste získali lepší propustnost.
Propustnost: Tady nastavte vyšší propustnost, abyste umožnili rychlejší zápis dokumentů do služby Azure Cosmos DB. Mějte na paměti vyšší náklady na RU na základě nastavení vysoké propustnosti.
Rozpočet propustnosti zápisu: Použijte hodnotu, která je menší než celková ru za minutu. Pokud máte tok dat s vysokým počtem oddílů Sparku, nastavení propustnosti rozpočtu umožňuje větší rovnováhu mezi těmito oddíly.
Související obsah
Podívejte se na další Tok dat články týkající se výkonu: