Průvodce mapováním toků dat a průvodce laděním
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Mapování toků dat v kanálech Azure Data Factory a Synapse nabízí rozhraní bez kódu pro návrh a spouštění transformací dat ve velkém. Pokud mapování toků dat ještě neznáte, projděte si téma Přehled mapování toků dat. Tento článek popisuje různé způsoby ladění a optimalizace toků dat tak, aby splňovaly vaše srovnávací testy výkonu.
Podívejte se na následující video a podívejte se na ukázkové časování transformující data s toky dat.
Monitorování výkonu toku dat
Jakmile ověříte logiku transformace pomocí režimu ladění, spusťte koncový tok dat jako aktivitu v kanálu. Toky dat jsou v kanálu zprovozněné pomocí aktivity spuštění toku dat. Aktivita toku dat má jedinečné prostředí pro monitorování v porovnání s jinými aktivitami, které zobrazují podrobný plán provádění a profil výkonu logiky transformace. Pokud chcete zobrazit podrobné informace o monitorování toku dat, vyberte ikonu brýle ve výstupu spuštění aktivity kanálu. Další informace najdete v tématu Monitorování mapování toků dat.

Při monitorování výkonu toku dat existují čtyři možná kritická místa, na která byste se měli podívat:
- Čas spuštění clusteru
- Čtení ze zdroje
- Čas transformace
- Zápis do jímky
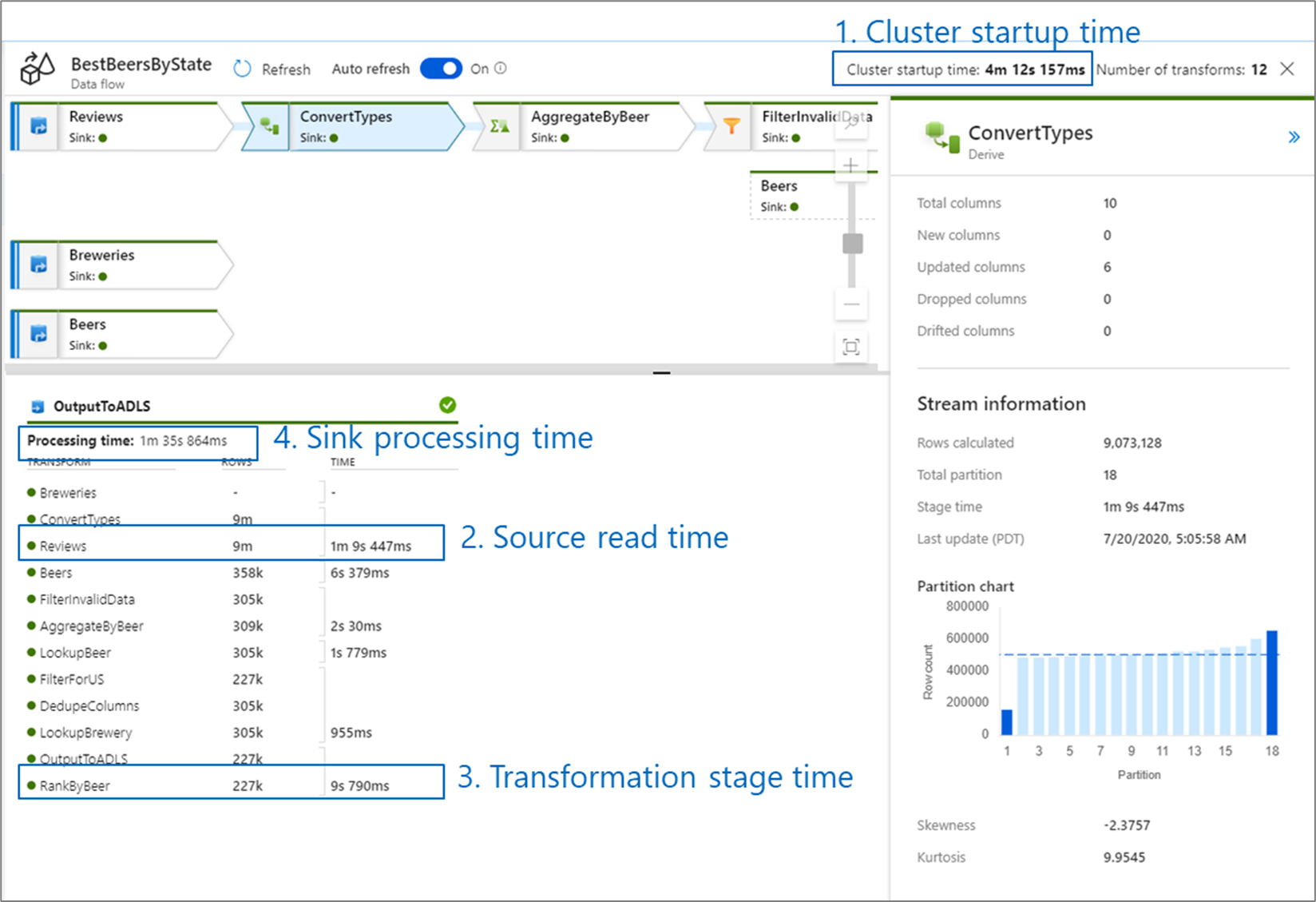
Doba spuštění clusteru je doba potřebnou ke spuštění clusteru Apache Spark. Tato hodnota se nachází v pravém horním rohu obrazovky monitorování. Toky dat běží v modelu za běhu, kde každá úloha používá izolovaný cluster. Tato doba spuštění obvykle trvá 3 až 5 minut. U sekvenčních úloh je možné zkrátit čas spuštění tím, že povolíte hodnotu v reálném čase. Další informace najdete v části Time to Live (Time to Live ) v tématu Výkon prostředí Integration Runtime.
Toky dat využívají optimalizátor Sparku, který změní pořadí a spouští obchodní logiku ve fázích, aby bylo možné co nejrychleji provádět. Pro každou jímku, do které tok dat zapisuje, uvádí výstup monitorování dobu trvání každé fáze transformace spolu s časem potřebným k zápisu dat do jímky. Čas, který je největší, je pravděpodobně kritickým bodem vašeho toku dat. Pokud fáze transformace, která trvá největší, obsahuje zdroj, můžete se podívat na další optimalizaci času čtení. Pokud transformace trvá dlouhou dobu, možná budete muset změnit rozdělení nebo zvětšit velikost prostředí Integration Runtime. Pokud je doba zpracování jímky velká, možná budete muset vertikálně navýšit kapacitu databáze nebo ověřit, že nevypíšete výstup do jednoho souboru.
Jakmile zjistíte kritický bod toku dat, využijte následující strategie optimalizace ke zlepšení výkonu.
Testování logiky toku dat
Při navrhování a testování toků dat z uživatelského rozhraní vám režim ladění umožňuje interaktivně testovat na živém clusteru Spark, který umožňuje zobrazit náhled dat a spouštět toky dat bez čekání na zahřátí clusteru. Další informace naleznete v tématu Režim ladění.
Karta Optimalizace
Karta Optimalizovat obsahuje nastavení pro konfiguraci schématu dělení clusteru Spark. Tato karta existuje v každé transformaci toku dat a určuje, jestli chcete data po dokončení transformace znovu rozdílit. Úprava dělení poskytuje kontrolu nad distribucí dat mezi výpočetní uzly a optimalizacemi umístění dat, které můžou mít pozitivní i negativní vliv na celkový výkon toku dat.
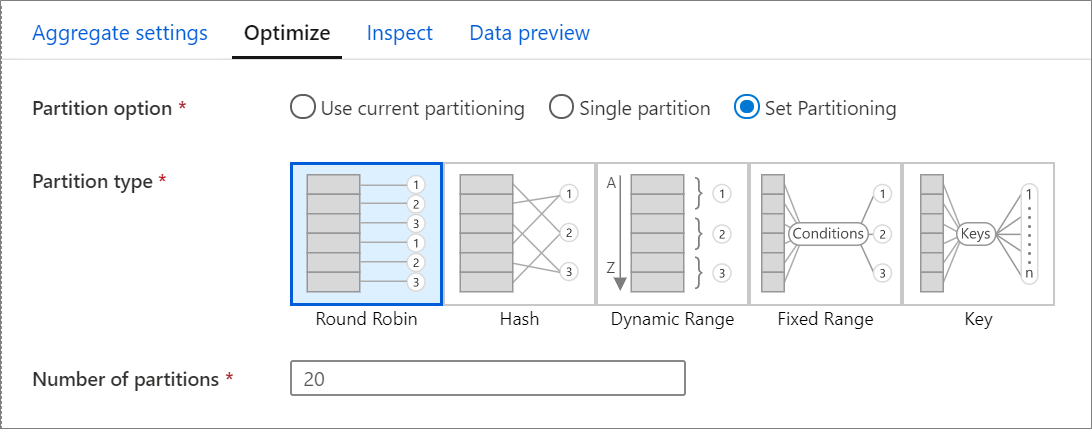
Ve výchozím nastavení je vybráno použití aktuálního dělení, které dává službě pokyn, aby aktuální výstupní dělení transformace. Vzhledem k tomu, že opětovné dělení dat nějakou dobu trvá, ve většině scénářů se doporučuje použít aktuální dělení . Scénáře, ve kterých můžete chtít data rozdělit do oddílů, patří po agregaci a spojeních, které výrazně zkosí vaše data nebo při použití dělení zdroje v databázi SQL.
Pokud chcete změnit dělení u jakékoli transformace, vyberte kartu Optimalizovat a vyberte přepínač Nastavit dělení . Zobrazí se řada možností dělení. Nejlepší způsob dělení se liší v závislosti na vašich datových svazcích, kandidátských klíčích, hodnotách null a kardinalitě.
Důležité
Jeden oddíl kombinuje všechna distribuovaná data do jednoho oddílu. Jedná se o velmi pomalou operaci, která také výrazně ovlivňuje všechny podřízené transformace a zápisy. Tato možnost se důrazně nedoporučuje, pokud neexistuje explicitní obchodní důvod k jeho použití.
V každé transformaci jsou k dispozici následující možnosti dělení:
Kruhové dotazování
Kruhové dotazování distribuuje data rovnoměrně mezi oddíly. Kruhové dotazování použijte, pokud nemáte vhodné klíčové kandidáty k implementaci solidní strategie inteligentního dělení. Můžete nastavit počet fyzických oddílů.
Hodnoty hash
Služba vytvoří hodnotu hash sloupců, aby se vytvořily jednotné oddíly tak, aby řádky s podobnými hodnotami spadají do stejného oddílu. Pokud použijete možnost Hash, otestujte možnou nerovnoměrnou distribuci oddílů. Můžete nastavit počet fyzických oddílů.
Dynamický rozsah
Dynamická oblast používá dynamické rozsahy Sparku na základě sloupců nebo výrazů, které zadáte. Můžete nastavit počet fyzických oddílů.
Pevný rozsah
Vytvořte výraz, který poskytuje pevný rozsah hodnot ve sloupcích dělených dat. Abyste se vyhnuli nerovnoměrné distribuci oddílů, měli byste mít před použitím této možnosti dobrý přehled o datech. Hodnoty, které zadáte pro výraz, se použijí jako součást funkce oddílu. Můžete nastavit počet fyzických oddílů.
Klíč
Pokud dobře rozumíte kardinalitě dat, může být klíčem dělení dobrá strategie. Dělení klíčů vytváří oddíly pro každou jedinečnou hodnotu ve sloupci. Počet oddílů nemůžete nastavit, protože číslo je založené na jedinečných hodnotách v datech.
Tip
Ruční nastavení schématu dělení znovu prohodí data a může odsazení výhod optimalizátoru Sparku. Osvědčeným postupem je nenastavovat dělení ručně, pokud ho nepotřebujete.
Úroveň protokolování
Pokud k úplnému protokolování všech podrobných protokolů telemetrie nevyžadujete každé spuštění kanálu aktivit toku dat, můžete volitelně nastavit úroveň protokolování na Úroveň Základní nebo Žádná. Při provádění toků dat v režimu Podrobné (výchozí) požadujete, aby služba během transformace dat plně protokoluje aktivitu na jednotlivých úrovních oddílů. Může to být náročná operace, takže pouze povolení podrobného řešení potíží může zlepšit celkový tok dat a výkon kanálu. Režim "Základní" protokoluje pouze doby trvání transformace, zatímco hodnota None bude poskytovat pouze souhrn doby trvání.

Související obsah
Podívejte se na další Tok dat články týkající se výkonu: