Přechod na sociální síť s Využitím služby Azure Cosmos DB
PLATÍ PRO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Skřítek
Skřítek ![]() Stůl
Stůl
Život v masivně propojené společnosti znamená, že v určitém okamžiku života se stanete součástí sociální sítě. Pomocí sociálních sítí můžete zůstat v kontaktu s přáteli, kolegy, rodinou nebo někdy sdílet svoji vášeň s lidmi se společnými zájmy.
Jako technici nebo vývojáři jste možná přemýšleli, jak tyto sítě ukládají a propojují vaše data. Nebo jste dokonce dostali za úkol vytvořit nebo navrhnout novou sociální síť pro konkrétní nika trhu. To je situace, kdy nastává důležitá otázka: Jak jsou všechna tato data uložená?
Předpokládejme, že vytváříte novou a lesklou sociální síť, kde vaši uživatelé můžou publikovat články se souvisejícími multimédii, jako jsou obrázky, videa nebo dokonce hudba. Uživatelé můžou přidávat komentáře k příspěvkům a udělovat body hodnocení. Na úvodní stránce hlavního webu se zobrazí informační kanál příspěvků, se kterými uživatelé uvidí a budou s nimi pracovat. Tato metoda zpočátku nezní složitě, ale kvůli jednoduchosti se tam zastavíme. (Můžete se ponořit do vlastních uživatelských informačních kanálů ovlivněných relacemi, ale přesahuje cíl tohoto článku.)
Jak tedy tato data ukládáte a kde?
Možná máte zkušenosti s databázemi SQL nebo máte představu o relačním modelování dat. Něco můžete začít kreslit následujícím způsobem:
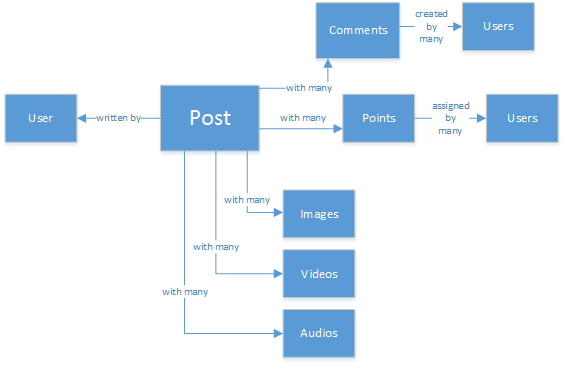
Dokonale normalizovaná a hezká datová struktura... to se neškubuje.
Nechoďte se špatně, celý svůj život jsem pracoval s databázemi SQL. Jsou skvělé, ale stejně jako každý vzor, praxe a softwarová platforma není ideální pro každý scénář.
Proč není v tomto scénáři nejlepší volbou SQL? Pojďme se podívat na strukturu jednoho příspěvku. Kdybych chtěl zobrazit příspěvek na webu nebo aplikaci, budu muset udělat dotaz s... spojením osmi tabulek (!) stačí zobrazit jeden příspěvek. Teď si představte stream příspěvků, které se dynamicky načítají a zobrazují se na obrazovce, a možná uvidíte, kam jdu.
K řešení tisíců dotazů s mnoha spojeními pro obsluhu obsahu můžete použít obrovskou instanci SQL s dostatečným výkonem. Proč byste ale měli, když existuje jednodušší řešení?
Cesta NoSQL
Tento článek vás provede modelováním dat sociální platformy s využitím databáze NoSQL Azure Cosmos DB , která je nákladově efektivní. Dozvíte se také, jak používat další funkce Azure Cosmos DB, jako je rozhraní API pro Gremlin. Pomocí přístupu NoSQL, ukládání dat ve formátu JSON a použití denormalizace, lze dříve komplikovaný příspěvek transformovat do jednoho dokumentu:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
A dá se získat jedním dotazem a bez spojení. Tento dotaz je mnohem jednoduchý a jednoduchý a pro rozpočet vyžaduje k dosažení lepšího výsledku méně prostředků.
Azure Cosmos DB zajišťuje, aby se všechny vlastnosti indexovaly pomocí automatického indexování. Automatické indexování lze dokonce přizpůsobit. Přístup bez schématu nám umožňuje ukládat dokumenty s různými a dynamickými strukturami. Možná zítra chcete, aby příspěvky měly seznam kategorií nebo hashtagů přidružených k nim? Azure Cosmos DB zpracuje nové dokumenty s přidanými atributy bez další práce vyžadované námi.
Komentáře k příspěvku lze považovat za jiné příspěvky s nadřazenou vlastností. (Tento postup zjednodušuje mapování objektů.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Všechny sociální interakce lze uložit na samostatný objekt jako čítače:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Vytváření informačních kanálů je jen otázkou vytváření dokumentů, které můžou obsahovat seznam ID příspěvků s daným pořadím relevance:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Můžete mít "nejnovější" datový proud s příspěvky seřazenými podle data vytvoření. Nebo můžete mít "nejžhavější" datový proud s těmito příspěvky s více lajky za posledních 24 hodin. Můžete dokonce implementovat vlastní stream pro každého uživatele na základě logiky, jako jsou sledující a zájmy. Stále by to byl seznam příspěvků. Záleží na tom, jak tyto seznamy sestavit, ale výkon čtení zůstane beze potíží. Jakmile získáte jeden z těchto seznamů, vydáte jeden dotaz do služby Azure Cosmos DB pomocí klíčového slova IN k získání stránek příspěvků najednou.
Datové proudy informačních kanálů je možné sestavit pomocí procesů na pozadí služby Aplikace Azure Services: Webjobs. Po vytvoření příspěvku je možné zpracování na pozadí aktivovat pomocí front služby Azure Storage a webových úloh aktivovaných pomocí sady Azure Webjobs SDK a implementací šíření post uvnitř datových proudů na základě vlastní logiky.
Body a lajky přes příspěvek se dají zpracovat odloženým způsobem pomocí stejné techniky, aby se vytvořilo nakonec konzistentní prostředí.
Sledující jsou složitější. Azure Cosmos DB má limit velikosti dokumentu a čtení a zápis velkých dokumentů může mít vliv na škálovatelnost vaší aplikace. Takže se můžete zamyslet nad ukládáním sledujících jako dokumentu s touto strukturou:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Tato struktura může fungovat pro uživatele s několika tisíci sledujících uživatelů. Pokud se ale některé celebrity připojí k řadám, tento přístup povede k velké velikosti dokumentu a nakonec dosáhne limitu velikosti dokumentu.
K vyřešení tohoto problému můžete použít smíšený přístup. Jako součást dokumentu Statistika uživatelů můžete uložit počet sledujících uživatelů:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Skutečný graf sledujících uživatelů můžete uložit pomocí rozhraní API služby Azure Cosmos DB pro Gremlin a vytvořit vrcholy pro každého uživatele a hrany , které udržují relace "A-follow-B". S rozhraním API pro Gremlin můžete získat sledující určitého uživatele a vytvořit složitější dotazy, které budou navrhovat lidi běžně. Pokud do grafu přidáte kategorie obsahu, které se lidem líbí nebo které se vám líbí, můžete začít s vytvářením obsahu, které zahrnují inteligentní zjišťování obsahu, navrhovat obsah, který sledujete, nebo najít lidi, se kterými byste mohli mít hodně společného.
Dokument Statistika uživatele je stále možné použít k vytváření karet v uživatelském rozhraní nebo rychlých náhledech profilu.
Vzor "Žebřík" a duplikace dat
Jak jste si možná všimli v dokumentu JSON, který odkazuje na příspěvek, existuje mnoho výskytů uživatele. A měli byste uhodnout, že tyto duplicity znamenají, že informace popisující uživatele, vzhledem k této denormalizaci, mohou být přítomné na více než jednom místě.
Kvůli rychlejšímu dotazování dochází k duplikaci dat. Problém s tímto vedlejším účinkem je, že pokud se nějaká akce změní data uživatele, musíte najít všechny aktivity, které uživatel kdy udělal, a aktualizovat je všechny. Není to praktické, že?
Vyřešíte ho identifikací klíčových atributů uživatele, který se zobrazí ve vaší aplikaci pro každou aktivitu. Pokud ve své aplikaci vizuálně zobrazíte příspěvek a zobrazíte jenom jméno a obrázek autora, proč ukládat všechna data uživatele do atributu "createdBy"? Pokud u každého komentáře, který jenom zobrazujete obrázek uživatele, nepotřebujete ve skutečnosti zbývající informace o uživateli. To je místo, kde se stane něco, co říkám "Žebříkový vzor".
Jako příklad si vezměme informace o uživateli:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Když se podíváte na tyto informace, můžete rychle zjistit, které důležité informace a které nejsou, a vytvořit tak "Žebřík":

Nejmenší krok se nazývá UserChunk, minimální část informací, která identifikuje uživatele a používá se k duplikaci dat. Zmenšením duplicitní velikosti dat pouze na informace, které "zobrazíte", snížíte možnost obrovských aktualizací.
Prostřední krok se nazývá uživatel. Jedná se o úplná data, která se použijí u většiny dotazů závislých na výkonu ve službě Azure Cosmos DB, nejpřístupnějších a kritických. Obsahuje informace reprezentované uživatelem UserChunk.
Největší je rozšířený uživatel. Obsahuje důležité informace o uživateli a další data, která nemusí být rychle čtená nebo mají případné použití, jako je proces přihlášení. Tato data se dají ukládat mimo Službu Azure Cosmos DB ve službě Azure SQL Database nebo v tabulkách Azure Storage.
Proč byste uživatele rozdělili a uložili byste tyto informace na různých místech? Vzhledem k tomu, že z hlediska výkonu jsou větší dokumenty, nákladnější dotazy. Udržujte dokumenty štíhlé, se správnými informacemi, abyste mohli provádět všechny dotazy závislé na výkonu pro vaši sociální síť. Uložte další dodatečné informace pro případné scénáře, jako jsou úplné úpravy profilu, přihlášení a dolování dat pro analýzy využití a iniciativy pro velké objemy dat. Je opravdu jedno, jestli je shromažďování dat pro dolování dat pomalejší, protože běží ve službě Azure SQL Database. Máte obavy, i když uživatelé mají rychlý a tenký zážitek. Uživatel uložený ve službě Azure Cosmos DB by vypadal takto:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
A příspěvek by vypadal takto:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Když dojde k úpravě, kde je ovlivněn atribut bloku dat, můžete snadno najít ovlivněné dokumenty. Stačí použít dotazy, které odkazují na indexované atributy, například SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", a pak aktualizovat bloky dat.
Vyhledávací pole
Uživatelé budou generovat, naštěstí, hodně obsahu. A měli byste být schopni poskytnout možnost hledat a hledat obsah, který nemusí být přímo v jejich streamech obsahu, možná proto, že neposledujete tvůrce, nebo možná jen snažíte najít ten starý příspěvek, který jste udělali před šesti měsíci.
Vzhledem k tomu, že používáte Službu Azure Cosmos DB, můžete snadno implementovat vyhledávací web pomocí služby Azure AI Search během několika minut, aniž byste museli zadávat jakýkoli kód, kromě procesu vyhledávání a uživatelského rozhraní.
Proč je tento proces tak snadný?
Azure AI Search implementuje, co volají indexery, procesy na pozadí, které se připojují do úložišť dat, a automaticky přidávají, aktualizují nebo odeberou vaše objekty v indexech. Podporují indexery služby Azure SQL Database, indexery objektů blob Azure a naštěstí indexery Azure Cosmos DB. Přechod informací ze služby Azure Cosmos DB do služby Azure AI Search je jednoduchý. Obě technologie ukládají informace ve formátu JSON, takže stačí vytvořit index a namapovat atributy z dokumentů, které chcete indexovat. A je to. V závislosti na velikosti vašich dat bude veškerý obsah dostupný k vyhledávání během několika minut pomocí nejlepšího řešení Prohledat jako službu v cloudové infrastruktuře.
Další informace o službě Azure AI Search najdete v Průvodci vyhledáváním v Hitchhikeru.
Základní znalosti
Po uložení veškerého tohoto obsahu, který se každý den rozrůstá a roste, můžete narazit na: Co můžu dělat se všemi tímto proudem informací od uživatelů?
Odpověď je jednoduchá: Dejte ji do práce a poučte se z ní.
Ale co se naučíte? Několik jednoduchých příkladů zahrnuje analýzu mínění, doporučení k obsahu na základě předvoleb uživatele nebo dokonce automatizovaného con režim stanu ratoru, který zajistí, že obsah publikovaný vaší sociální sítí je pro rodinu bezpečný.
Teď, když jsem tě dostala do háku, nejspíš si myslíte, že budete potřebovat phD v matematické vědě k extrakci těchto vzorů a informací z jednoduchých databází a souborů, ale nebudete mít pravdu.
Azure Machine Learning je plně spravovaná cloudová služba, která umožňuje vytvářet pracovní postupy pomocí algoritmů v jednoduchém rozhraní pro přetahování, kódovat vlastní algoritmy v jazyce R nebo používat některá z již vytvořených a připravených rozhraní API, jako jsou: Analýza textu, Content Moderator nebo Doporučení.
Pokud chcete dosáhnout některého z těchto scénářů strojového učení, můžete pomocí služby Azure Data Lake ingestovat informace z různých zdrojů. Pomocí U-SQL můžete také zpracovat informace a vygenerovat výstup, který může služba Azure Machine Learning zpracovat.
Další dostupnou možností je použít služby Azure AI k analýze obsahu uživatelů. Nejen že jim rozumíte lépe (prostřednictvím analýzy toho, co zapisují pomocí rozhraní API Analýza textu), ale mohli byste také detekovat nežádoucí nebo vyspělý obsah a odpovídajícím způsobem pracovat s rozhraním POČÍTAČOVÉ ZPRACOVÁNÍ OBRAZU API. Služby Azure AI zahrnují řadu předefinovaných řešení, která nevyžadují použití žádného druhu znalostí služby Machine Learning.
Sociální prostředí na úrovni planety
Existuje poslední, ale ne nejméně důležitý článek, který musím řešit: škálovatelnost. Při návrhu architektury by se každá komponenta měla škálovat samostatně. Nakonec budete muset zpracovat více dat nebo budete chtít mít větší geografické pokrytí. Naštěstí je dosažení obou úloh prostředím na klíč se službou Azure Cosmos DB.
Azure Cosmos DB podporuje automatické dělení. Automaticky vytvoří oddíly na základě daného klíče oddílu, který je definován jako atribut v dokumentech. Definování správného klíče oddílu musí být provedeno v době návrhu. Další informace najdete v tématu Dělení ve službě Azure Cosmos DB.
V případě sociálních zkušeností musíte strategii dělení sladit se způsobem, jakým se dotazujete a píšete. (Například čtení v rámci stejného oddílu je žádoucí a vyhněte se "horkým místům" rozložením zápisů do více oddílů.) Některé možnosti jsou: oddíly založené na dočasném klíči (den/měsíc/týden), podle kategorie obsahu, podle geografické oblasti nebo podle uživatele. Vše ve skutečnosti závisí na tom, jak se budete dotazovat na data a zobrazit data ve vašem sociálním prostředí.
Azure Cosmos DB bude spouštět dotazy (včetně agregací) napříč všemi oddíly transparentně, takže nemusíte přidávat žádnou logiku, jak se vaše data rozrůstá.
Časem se časem zvýší provoz a zvýší se spotřeba prostředků (měřená v RU nebo jednotkách žádostí). Při růstu uživatelské základny budete číst a zapisovat častěji. Uživatelská základna začne vytvářet a číst další obsah. Takže schopnost škálování propustnosti je důležitá. Zvýšení počtu RU je snadné. Můžete to udělat několika kliknutími na webu Azure Portal nebo vydáním příkazů prostřednictvím rozhraní API.
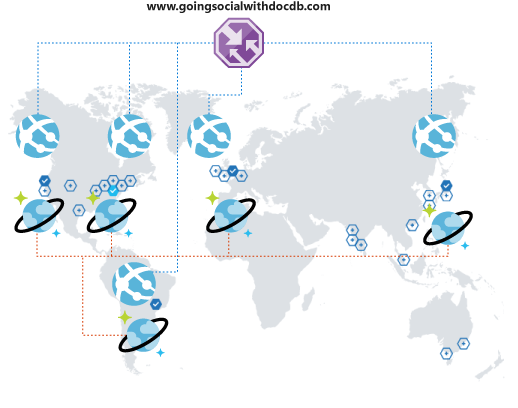
Co se stane, když se věci budou lépe zlepšovat? Předpokládejme, že si uživatelé z jiné země nebo oblasti nebo kontinentu všimnou vaší platformy a začnou ji používat. To je skvělé překvapení!
Ale počkej! Brzy zjistíte, že jejich zkušenosti s vaší platformou nejsou optimální. Jsou tak daleko od vaší provozní oblasti, že latence je hrozná. Očividně nechcete, aby skončili. Pokud existuje jen snadný způsob, jak rozšířit váš globální dosah? Existuje!
Azure Cosmos DB umožňuje globálně a transparentně replikovat data několika kliknutími a automaticky vybírat z dostupných oblastí z klientského kódu. Tento proces také znamená, že můžete mít více oblastí převzetí služeb při selhání.
Při globální replikaci dat je potřeba zajistit, aby je vaši klienti mohli využívat. Pokud používáte webový front-end nebo přistupujete k rozhraním API z mobilních klientů, můžete nasadit Azure Traffic Manager a naklonovat službu Aplikace Azure ve všech požadovaných oblastech pomocí konfigurace výkonu pro podporu rozšířeného globálního pokrytí. Když klienti přistupují k front-endu nebo rozhraním API, budou přesměrováni do nejbližší služby App Service, která se zase připojí k místní replice služby Azure Cosmos DB.
Závěr
Tento článek vysvětluje některé světlo na alternativy vytváření sociálních sítí zcela v Azure s nízkonákladovými službami. přináší výsledky tím, že podporuje použití vícevrstvého úložného řešení a distribuce dat s názvem "Žebřík".
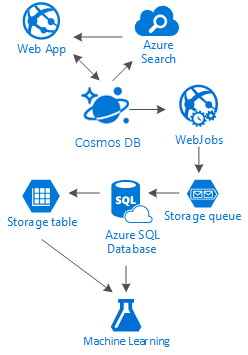
Pravdou je, že pro tento druh scénářů neexistuje žádná stříbrná kulka. Je to součinnost vytvořená kombinací skvělých služeb, které nám umožňují vytvářet skvělé prostředí: rychlost a svoboda služby Azure Cosmos DB poskytovat skvělou sociální aplikaci, inteligenci za prvotřídním vyhledávacím řešením, jako je Azure AI Search, flexibilita služby Aplikace Azure Services k hostování ani jazykově nezávislých aplikací, ale výkonných procesů na pozadí a rozšíření Azure Storage a Azure SQL Database pro ukládání velkých objemů dat. objemy dat a analytická síla služby Azure Machine Learning k vytváření znalostí a inteligentních funkcí, které můžou poskytovat zpětnou vazbu k vašim procesům a pomáhají nám poskytovat správný obsah správným uživatelům.
Další kroky
Další informace o případech použití služby Azure Cosmos DB najdete v tématu Běžné případy použití služby Azure Cosmos DB.