Dělení a horizontální škálování ve službě Azure Cosmos DB
PLATÍ PRO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Skřítek
Skřítek ![]() Stůl
Stůl
Azure Cosmos DB používá dělení k škálování jednotlivých kontejnerů v databázi tak, aby splňovala požadavky vaší aplikace na výkon. Položky v kontejneru jsou rozdělené na různé podmnožina označované jako logické oddíly. Logické oddíly se vytvářejí na základě hodnoty klíče oddílu, který je přidružený ke každé položce v kontejneru. Všechny položky v logickém oddílu mají stejnou hodnotu klíče oddílu.
Kontejner například obsahuje položky. Každá položka má jedinečnou hodnotu vlastnosti UserID . Pokud UserID slouží jako klíč oddílu pro položky v kontejneru a existuje 1 000 jedinečných UserID hodnot, vytvoří se pro kontejner 1 000 logických oddílů.
Kromě klíče oddílu, který určuje logický oddíl položky, má každá položka v kontejneru ID položky (jedinečné v rámci logického oddílu). Kombinace klíče oddílu a ID položky vytvoří index položky, který položku jednoznačně identifikuje. Volba klíče oddílu je důležitým rozhodnutím, které ovlivňuje výkon vaší aplikace.
Tento článek vysvětluje vztah mezi logickými a fyzickými oddíly. Popisuje také osvědčené postupy pro dělení a poskytuje podrobný přehled o tom, jak funguje horizontální škálování ve službě Azure Cosmos DB. Není nutné porozumět těmto interním podrobnostem, abyste vybrali klíč oddílu, ale pokrýváme je, abyste měli přehled o tom, jak Azure Cosmos DB funguje.
Logické oddíly
Logický oddíl se skládá ze sady položek, které mají stejný klíč oddílu. Například v kontejneru, který obsahuje data o výživě potravin, všechny položky obsahují foodGroup vlastnost. Jako klíč oddílu pro kontejner můžete použít foodGroup . Skupiny položek, které mají specifické hodnoty pro foodGroup, například Beef Products, Baked Productsa Sausages and Luncheon Meats, tvoří odlišné logické oddíly.
Logický oddíl také definuje obor databázových transakcí. Položky v rámci logického oddílu můžete aktualizovat pomocí transakce s izolací snímků. Když se do kontejneru přidají nové položky, systém transparentně vytvoří nové logické oddíly. Při odstranění podkladových dat se nemusíte starat o odstranění logického oddílu.
Počet logických oddílů v kontejneru není nijak omezený. Každý logický oddíl může ukládat až 20 GB dat. Dobré volby klíče oddílu mají širokou škálu možných hodnot. Například v kontejneru, kde všechny položky obsahují foodGroup vlastnost, mohou data v logickém oddílu Beef Products růst až o 20 GB. Výběrem klíče oddílu s širokou škálou možných hodnot zajistíte, že kontejner dokáže škálovat.
Upozornění služby Azure Monitor můžete použít k monitorování, jestli velikost logického oddílu blíží 20 GB.
Fyzické oddíly
Kontejner se škáluje tak, že distribuuje data a propustnost napříč fyzickými oddíly. Interně se jeden nebo více logických oddílů mapuje na jeden fyzický oddíl. Menší kontejnery mají obvykle mnoho logických oddílů, ale vyžadují pouze jeden fyzický oddíl. Na rozdíl od logických oddílů jsou fyzické oddíly interní implementací systému a Azure Cosmos DB zcela spravuje fyzické oddíly.
Počet fyzických oddílů v kontejneru závisí na následujících vlastnostech:
Zřízená propustnost (každý jednotlivý fyzický oddíl může poskytovat propustnost až 10 000 jednotek žádostí za sekundu). Limit 10 000 RU/s pro fyzické oddíly znamená, že logické oddíly mají také limit 10 000 RU/s, protože každý logický oddíl je mapován pouze na jeden fyzický oddíl.
Celkové úložiště dat (každý fyzický oddíl může uchovávat až 50 GB dat).
Poznámka:
Fyzické oddíly jsou interní implementací systému a jsou plně spravované službou Azure Cosmos DB. Při vývoji řešení se nezaměřte na fyzické oddíly, protože je nemůžete ovládat. Místo toho se zaměřte na klíče oddílů. Pokud zvolíte klíč oddílu, který rovnoměrně distribuuje spotřebu propustnosti napříč logickými oddíly, zajistíte vyváženou spotřebu propustnosti napříč fyzickými oddíly.
Celkový počet fyzických oddílů v kontejneru není nijak omezený. S rostoucí zřízenou propustností nebo velikostí dat azure Cosmos DB automaticky vytváří nové fyzické oddíly rozdělením existujících oddílů. Rozdělení fyzických oddílů nemá vliv na dostupnost vaší aplikace. Po rozdělení fyzického oddílu budou všechna data v rámci jednoho logického oddílu stále uložena ve stejném fyzickém oddílu. Rozdělení fyzického oddílu jednoduše vytvoří nové mapování logických oddílů na fyzické oddíly.
Propustnost zřízená pro kontejner se rovnoměrně rozdělí mezi fyzické oddíly. Návrh klíče oddílu, který nedistribuuje požadavky rovnoměrně, může vést k příliš velkému počtu požadavků směrovaných na malou podmnožinu oddílů, které se stanou "horkými". Horké oddíly vedou k neefektivnímu využití zřízené propustnosti, což může vést k omezování rychlosti a vyšším nákladům.
Představte si například kontejner s cestou /foodGroup zadanou jako klíč oddílu. Kontejner může mít libovolný počet fyzických oddílů, ale v tomto příkladu předpokládáme, že má tři oddíly. Jeden fyzický oddíl může obsahovat více klíčů oddílu. Například největší fyzický oddíl může obsahovat tři největší logické oddíly s největší velikostí: Beef Products, Vegetable and Vegetable Productsa Soups, Sauces, and Gravies.
Pokud přiřadíte propustnost 18 000 jednotek žádostí za sekundu (RU/s), může každý ze tří fyzických oddílů využívat celkovou zřízenou propustnost 1/3. V rámci vybraného fyzického oddílu můžou klíče logického oddílu Beef ProductsVegetable and Vegetable Productsa Soups, Sauces, and Gravies společně využívat 6 000 zřízených RU/s fyzického oddílu. Vzhledem k tomu, že zřízená propustnost je rovnoměrně rozdělená mezi fyzické oddíly kontejneru, je důležité zvolit klíč oddílu, který rovnoměrně distribuuje spotřebu propustnosti. Další informace najdete v tématu volba správného klíče logického oddílu.
Správa logických oddílů
Azure Cosmos DB transparentně a automaticky spravuje umístění logických oddílů na fyzické oddíly, aby efektivně splňovala požadavky na škálovatelnost a výkon kontejneru. S rostoucími požadavky na propustnost a úložiště aplikace azure Cosmos DB přesouvá logické oddíly, aby se zatížení automaticky rozložilo do většího počtu fyzických oddílů. Další informace ofyzických
Azure Cosmos DB používá dělení založené na hodnotě hash k rozložení logických oddílů mezi fyzické oddíly. Azure Cosmos DB hashuje hodnotu klíče oddílu položky. Výsledek hash určuje logický oddíl. Pak Azure Cosmos DB přiděluje klíčové místo hodnot hash klíčů oddílů rovnoměrně napříč fyzickými oddíly.
Transakce (v uložených procedurách nebo triggerech) jsou povoleny pouze pro položky v jednom logickém oddílu.
Sady replik
Každý fyzický oddíl se skládá ze sady replik, označovaných také jako sada replik. Každá replika hostuje instanci databázového stroje. Sada replik zajišťuje trvalé, vysoce dostupné a konzistentní úložiště dat v rámci fyzického oddílu. Každá replika, která tvoří fyzický oddíl, dědí kvótu úložiště oddílu. Všechny repliky fyzického oddílu společně podporují propustnost přidělenou fyzickému oddílu. Azure Cosmos DB automaticky spravuje sady replik.
Menší kontejnery obvykle vyžadují pouze jeden fyzický oddíl, ale stále mají alespoň čtyři repliky.
Následující obrázek ukazuje, jak jsou logické oddíly mapovány na fyzické oddíly, které jsou distribuovány globálně. Sada oddílů v imagi odkazuje na skupinu fyzických oddílů, které spravují stejné klíče logického oddílu v několika oblastech:
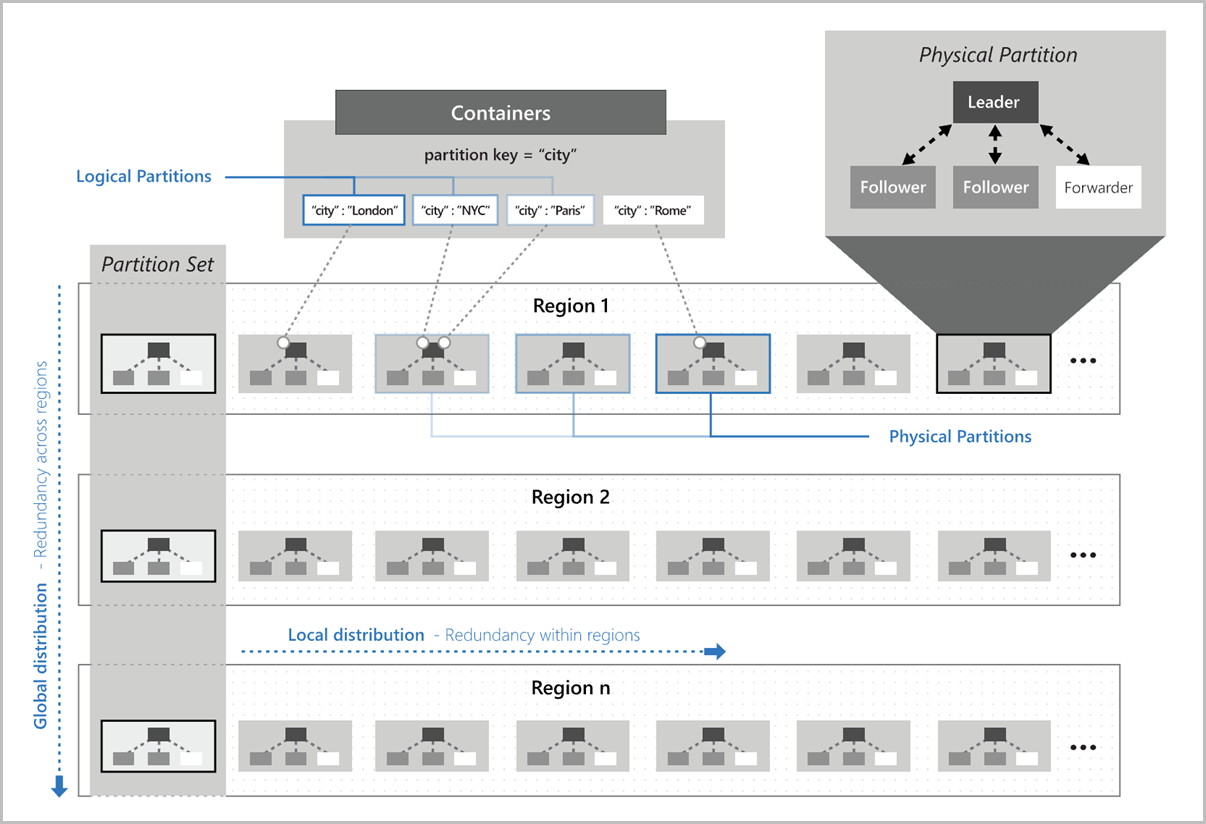
Výběr klíče oddílu
Klíč oddílu má dvě komponenty: cestu klíče oddílu a hodnotu klíče oddílu. Představte si například položku { "userId" : "Andrew", "worksFor": "Microsoft" } , pokud jako klíč oddílu zvolíte "userId", jedná se o dvě komponenty klíče oddílu:
Cesta klíče oddílu (například :/userId). Cesta klíče oddílu přijímá alfanumerické znaky a podtržítka (_). Vnořené objekty můžete použít také pomocí standardní notace cesty(/).
Hodnota klíče oddílu (například: Andrew). Hodnota klíče oddílu může být typu řetězec nebo číselné typy.
Informace o omezeních propustnosti, úložiště a délky klíče oddílu najdete v článku o kvótách služby Azure Cosmos DB.
Výběr klíče oddílu je jednoduchá, ale důležitá volba návrhu ve službě Azure Cosmos DB. Jakmile vyberete klíč oddílu, není možné ho změnit na místě. Pokud potřebujete změnit klíč oddílu, měli byste data přesunout do nového kontejneru s novým požadovaným klíčem oddílu. (Úlohy kopírování kontejnerů pomáhají s tímto procesem.)
Pro všechny kontejnery by váš klíč oddílu měl:
Buďte vlastností, která má hodnotu, která se nemění. Pokud je vlastnost vaším klíčem oddílu, nemůžete hodnotu této vlastnosti aktualizovat.
Měla by obsahovat
Stringpouze hodnoty – nebo čísla by měla být v ideálním případě převedena naStringhodnotu , pokud je možné, že jsou mimo hranice čísel s dvojitou přesností podle IEEE 754 binary64. Specifikace JSON označuje důvody, proč je použití čísel mimo tuto hranici obecně špatným postupem kvůli pravděpodobným problémům s interoperabilitou. Tyto obavy jsou zvláště důležité pro sloupec klíče oddílu, protože je neměnný a vyžaduje, aby se migrace dat později změnila.Má vysokou kardinalitu. Jinými slovy, vlastnost by měla mít širokou škálu možných hodnot.
Rovnoměrně rozprostřete spotřebu jednotek žádostí (RU) a úložiště dat napříč všemi logickými oddíly. Toto rozložení zajišťuje rovnoměrnou spotřebu RU a distribuci úložiště napříč fyzickými oddíly.
Mají hodnoty, které nejsou větší než 2048 bajtů, obvykle nebo 101 bajtů, pokud nejsou povolené velké klíče oddílů. Další informace najdete v části Klíče velkých oddílů.
Pokud potřebujete transakce ACID s více položkami ve službě Azure Cosmos DB, musíte použít uložené procedury nebo triggery. Všechny uložené procedury a triggery založené na JavaScriptu jsou vymezeny na jeden logický oddíl.
Poznámka:
Pokud máte jenom jeden fyzický oddíl, hodnota klíče oddílu nemusí být relevantní, protože všechny dotazy budou cílit na stejný fyzický oddíl.
Typy klíčů oddílů
| Strategie dělení | Vhodné použití | Výhody | Nevýhody |
|---|---|---|---|
| Běžný klíč oddílu (např. CustomerId, OrderId) | – Používá se, když má klíč oddílu vysokou kardinalitu a je v souladu se vzory dotazů (např. filtrování podle CustomerId). – Vhodné pro úlohy, u kterých dotazy většinou cílí na data jednoho zákazníka (např. načítání všech objednávek pro zákazníka). |
- Jednoduchá správa. – Efektivní dotazy, když vzor přístupu odpovídá klíči oddílu (například dotazování všech objednávek podle Id zákazníka). – Zabraňuje dotazům napříč oddíly, pokud jsou vzory přístupu konzistentní. |
– Riziko horkých oddílů, pokud některé hodnoty (např. několik zákazníků s vysokým provozem) generují výrazně více dat než jiné. – Pokud objem dat pro konkrétní klíč rychle roste, může dojít k dosažení limitu 20 GB na logický oddíl. |
| Syntetický klíč oddílu (např. CustomerId + OrderDate) | – Použije se, když žádné jedno pole nemá vysokou kardinalitu a odpovídá vzorům dotazu. - Vhodné pro úlohy náročné na zápis, kde je potřeba rovnoměrně distribuovat data napříč fyzickými oddíly (např. mnoho objednávek zadaných ke stejnému datu). |
– Pomáhá rovnoměrně distribuovat data mezi oddíly, což snižuje horké oddíly (například distribuci objednávek podle ID zákazníka i orderDate). – Rozloží zápisy do více oddílů a zlepší propustnost. |
– Dotazy, které filtrují pouze podle jednoho pole (např. pouze Id zákazníka), můžou vést k dotazům napříč oddíly. – Dotazy napříč oddíly můžou vést k vyšší spotřebě RU (2–3 RU/s další poplatky za každý fyzický oddíl, který existuje) a zvýšení latence. |
| Hierarchický klíč oddílu (HPK) (např. CustomerId/OrderId, StoreId/ProductId) | – Používejte, když potřebujete víceúrovňové dělení pro podporu rozsáhlých datových sad. – Ideální, když dotazy filtrují první a druhou úroveň hierarchie. |
- Pomáhá vyhnout se limitu 20 GB vytvořením více úrovní dělení. – Efektivní dotazování na obě hierarchické úrovně (např. filtrování podle ID zákazníka a potom podle ID objednávky). – Minimalizuje dotazy napříč oddíly pro dotazy, které cílí na nejvyšší úroveň (například načítání všech dat z konkrétního ID zákazníka). |
– Vyžaduje pečlivé plánování, aby se zajistilo, že klíč první úrovně má vysokou kardinalitu a je součástí většiny dotazů. – Složitější správa než běžný klíč oddílu. – Pokud dotazy nejsou v souladu s hierarchií (například filtrování pouze podle ID objednávky, pokud je ID zákazníka první úroveň), může dojít k snížení výkonu dotazů. |
Klíče oddílů pro kontejnery náročné na čtení
U většiny kontejnerů je potřeba při výběru klíče oddílu vzít v úvahu všechna výše uvedená kritéria. U velkých kontejnerů náročných na čtení ale můžete chtít zvolit klíč oddílu, který se v dotazech často zobrazuje jako filtr. Dotazy lze efektivně směrovat pouze na relevantní fyzické oddíly zahrnutím klíče oddílu do predikátu filtru.
Tato vlastnost může být dobrou volbou klíče oddílu, pokud je většina požadavků vaší úlohy dotazy a většina dotazů má filtr rovnosti pro stejnou vlastnost. Pokud například často spouštíte dotaz, který filtruje UserID, výběr UserID jako klíč oddílu by snížil počet dotazů napříč oddíly.
Pokud je ale kontejner malý, pravděpodobně nemáte dostatek fyzických oddílů, abyste se museli starat o výkon dotazů napříč oddíly. Většina malých kontejnerů ve službě Azure Cosmos DB vyžaduje pouze jeden nebo dva fyzické oddíly.
Pokud by se kontejner mohl zvětšit na více než několik fyzických oddílů, měli byste se ujistit, že jste vybrali klíč oddílu, který minimalizuje dotazy napříč oddíly. Kontejner vyžaduje více než několik fyzických oddílů, pokud platí některé z následujících skutečností:
Váš kontejner má zřízeno více než 30 000 RU.
Kontejner ukládá více než 100 GB dat.
Použití ID položky jako klíče oddílu
Poznámka:
Tato část se týká především rozhraní API pro NoSQL. Jiná rozhraní API, jako je rozhraní API pro Gremlin, nepodporují jedinečný identifikátor jako klíč oddílu.
Pokud má váš kontejner vlastnost, která má širokou škálu možných hodnot, je pravděpodobně skvělou volbou klíče oddílu. Jedním z možných příkladů takové vlastnosti je ID položky. U malých kontejnerů náročných na čtení nebo kontejnerů s velkými zápisy je ID položky (/id) přirozeně skvělou volbou pro klíč oddílu.
ID položky systémové vlastnosti existuje v každé položce v kontejneru. Můžete mít další vlastnosti, které představují logické ID položky. V mnoha případech jsou tato ID také skvělou volbou klíče oddílu ze stejných důvodů jako ID položky.
ID položky je skvělou volbou klíče oddílu z následujících důvodů:
- Existuje široká škála možných hodnot (jedno jedinečné ID položky na položku).
- Vzhledem k tomu, že pro každou položku existuje jedinečné ID položky, je ID položky skvělou úlohou při rovnoměrné vyrovnávání spotřeby RU a úložiště dat.
- Efektivní čtení bodů můžete snadno provést, protože vždy znáte klíč oddílu položky, pokud znáte JEHO ID položky.
Při výběru ID položky jako klíče oddílu je potřeba vzít v úvahu některé věci:
- Pokud je ID položky klíčem oddílu, stane se jedinečným identifikátorem v celém kontejneru. Nemůžete vytvářet položky, které mají duplicitní ID položek.
- Pokud máte kontejner náročný na čtení s mnoha fyzickými oddíly, dotazy jsou efektivnější, pokud mají filtr rovnosti s ID položky.
- Nemůžete spouštět uložené procedury ani triggery, které cílí na více logických oddílů.