Modelování a dělení dat ve službě Azure Cosmos DB s využitím příkladu z reálného světa
PLATÍ PRO: ![]() NoSQL
NoSQL
Tento článek vychází z několika konceptů služby Azure Cosmos DB, jako je modelování dat, dělení na oddíly a zřízená propustnost , a ukazuje, jak řešit cvičení návrhu dat z reálného světa.
Pokud obvykle pracujete s relačními databázemi, pravděpodobně jste vytvořili návyky a intuitivně, jak navrhnout datový model. Vzhledem ke konkrétním omezením, ale také jedinečným výhodám služby Azure Cosmos DB se většina těchto osvědčených postupů dobře nepřekládá a může vás přetáhnout do neoptimálních řešení. Cílem tohoto článku je provést celý proces modelování skutečného případu použití ve službě Azure Cosmos DB od modelování položek po kolokaci entit a dělení kontejnerů.
Stáhněte nebo zobrazte zdrojový kód vygenerovaný komunitou, který ilustruje koncepty z tohoto článku.
Důležité
Přispěvatel komunity přispěl touto ukázkou kódu a tým Služby Azure Cosmos DB nepodporuje údržbu.
Scénář
V tomto cvičení budeme uvažovat o doméně platformy pro blogování, kde můžou uživatelé vytvářet příspěvky. Uživatelé můžou k těmto příspěvkům také lajkovat a přidávat komentáře .
Tip
Zvýraznili jsme některá slova kurzívou. Tato slova identifikují druh "věcí", se kterým bude náš model muset manipulovat.
Přidání dalších požadavků do naší specifikace:
- Na úvodní stránce se zobrazí informační kanál nedávno vytvořených příspěvků.
- Můžeme načíst všechny příspěvky pro uživatele, všechny komentáře pro příspěvek a všechny lajky pro příspěvek,
- Příspěvky se vrátí s uživatelským jménem autorů a počtem komentářů a lajků, které mají.
- Komentáře a lajky se vrátí také s uživatelským jménem uživatelů, kteří je vytvořili.
- Když se zobrazí jako seznamy, příspěvky musí prezentovat pouze zkrácený souhrn jejich obsahu.
Identifikace hlavních vzorů přístupu
Abychom mohli začít, dáváme naší počáteční specifikaci určitou strukturu tím, že identifikujeme vzory přístupu našeho řešení. Při návrhu datového modelu pro Azure Cosmos DB je důležité pochopit, které požadavky musí náš model sloužit, aby se zajistilo, že model bude tyto požadavky efektivně obsluhovat.
Abychom si usnadnili sledování celého procesu, kategorizujeme tyto různé požadavky jako příkazy nebo dotazy a výpůjčky některých slovníků z CQRS. V CQRS jsou příkazy požadavky na zápis (tj. záměry aktualizovat systém) a dotazy jsou požadavky jen pro čtení.
Tady je seznam požadavků, které naše platforma zveřejňuje:
- [C1] Vytvoření nebo úprava uživatele
- [Q1] Načtení uživatele
- [C2] Vytvoření nebo úprava příspěvku
- [Q2] Načtení příspěvku
- [Q3] Výpis příspěvků uživatele ve krátkém formátu
- [C3] Vytvoření komentáře
- [Q4] Výpis komentářů k příspěvku
- [C4] Líbí se příspěvku
- [Q5] Zobrazení seznamu lajků příspěvku
- [Q6] Zobrazení seznamu x nejnovějších příspěvků vytvořených v krátkém formátu (informační kanál)
V této fázi jsme nepřemýšleli o podrobnostech o tom, co každá entita (uživatel, příspěvek atd.) obsahuje. Tento krok je obvykle mezi prvními, které je potřeba řešit při návrhu proti relačnímu úložišti. Nejprve začneme tímto krokem, protože musíme zjistit, jak se tyto entity překládají z hlediska tabulek, sloupců, cizích klíčů atd. Je to mnohem méně starostí s dokumentovou databází, která nevynucuje žádné schéma při zápisu.
Hlavním důvodem, proč je důležité identifikovat vzory přístupu od začátku, je to proto, že tento seznam požadavků bude naší testovací sadou. Pokaždé, když iterujeme datový model, procházíme jednotlivé požadavky a kontrolujeme jeho výkon a škálovatelnost. Vypočítáme jednotky žádostí spotřebované v každém modelu a optimalizujeme je. Všechny tyto modely používají výchozí zásady indexování a můžete je přepsat indexováním konkrétních vlastností, které můžou dále zlepšit spotřebu a latenci RU.
V1: První verze
Začneme se dvěma kontejnery: users a posts.
Kontejner Uživatelé
Tento kontejner ukládá pouze položky uživatele:
{
"id": "<user-id>",
"username": "<username>"
}
Tento kontejner rozdělíme na oddíly id, což znamená, že každý logický oddíl v rámci tohoto kontejneru obsahuje pouze jednu položku.
Příspěvky kontejneru
Tento kontejner hostuje entity, jako jsou příspěvky, komentáře a lajky:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Tento kontejner rozdělíme podle postId, což znamená, že každý logický oddíl v tomto kontejneru obsahuje jeden příspěvek, všechny komentáře pro tento příspěvek a všechny lajky pro tento příspěvek.
Zavedli type jsme vlastnost v položkách uložených v tomto kontejneru, abychom mohli rozlišovat mezi třemi typy entit, které tento kontejner hostuje.
Rozhodli jsme se také místo vložení odkazovat na související data (podrobnosti o těchto konceptech najdete v této části ):
- neexistuje žádný horní limit počtu příspěvků, které může uživatel vytvořit,
- příspěvky mohou být libovolně dlouhé,
- neexistuje žádný horní limit počtu komentářů a lajků, které by příspěvek mohl mít,
- Chceme být schopni přidat komentář nebo lajk do příspěvku, aniž bychom museli aktualizovat samotný příspěvek.
Jak dobře náš model funguje?
Teď je čas posoudit výkon a škálovatelnost naší první verze. U každého dříve zjištěného požadavku měříme jeho latenci a počet jednotek žádostí, které spotřebuje. Toto měření se provádí proti fiktivní datové sadě obsahující 100 000 uživatelů s 5 až 50 příspěvky na uživatele a až 25 komentářů a 100 lajků na příspěvek.
[C1] Vytvoření nebo úprava uživatele
Tento požadavek je jednoduchý pro implementaci při pouhém vytvoření nebo aktualizaci položky v kontejneru users . Požadavky se pěkně rozprostírají mezi všechny oddíly díky klíči oddílu id .
| Latence | Poplatek za RU | Výkon |
|---|---|---|
7 milisekunda |
5.71 RU |
✅ |
[Q1] Načtení uživatele
Načtení uživatele se provádí čtením odpovídající položky z kontejneru users .
| Latence | Poplatek za RU | Výkon |
|---|---|---|
2 milisekunda |
1 RU |
✅ |
[C2] Vytvoření nebo úprava příspěvku
Podobně jako [C1] stačí do kontejneru posts zapisovat.
| Latence | Poplatek za RU | Výkon |
|---|---|---|
9 milisekunda |
8.76 RU |
✅ |
[Q2] Načtení příspěvku
Začneme načtením odpovídajícího dokumentu z kontejneru posts . To ale nestačí, jak je uvedeno v naší specifikaci, musíme také agregovat uživatelské jméno autora příspěvku, počty komentářů a počty lajků pro příspěvek. Uvedené agregace vyžadují vydání dalších 3 dotazů SQL.
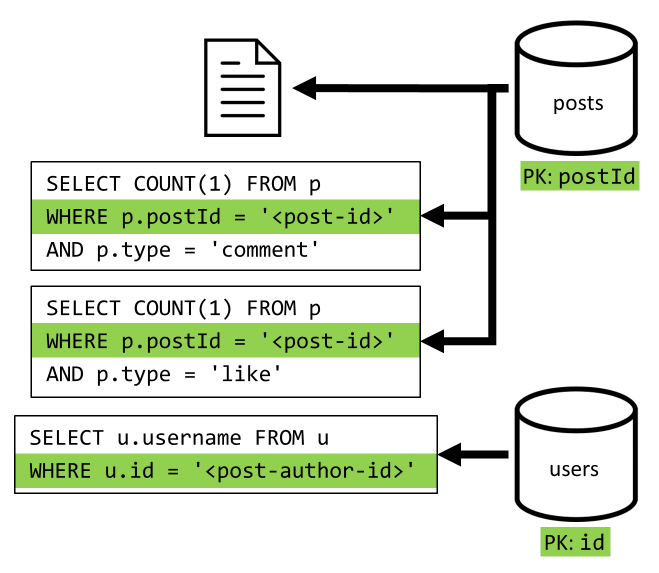
Každý z dalších dotazů filtruje klíč oddílu příslušného kontejneru, což je přesně to, co chceme maximalizovat výkon a škálovatelnost. Ale nakonec musíme provést čtyři operace, abychom vrátili jeden příspěvek, takže to v další iteraci vylepšíme.
| Latence | Poplatek za RU | Výkon |
|---|---|---|
9 milisekunda |
19.54 RU |
⚠ |
[Q3] Výpis příspěvků uživatele ve krátkém formátu
Nejprve musíme načíst požadované příspěvky pomocí dotazu SQL, který načte příspěvky odpovídající danému uživateli. Musíme ale také vydávat další dotazy k agregaci uživatelského jména autora a počtu komentářů a lajků.
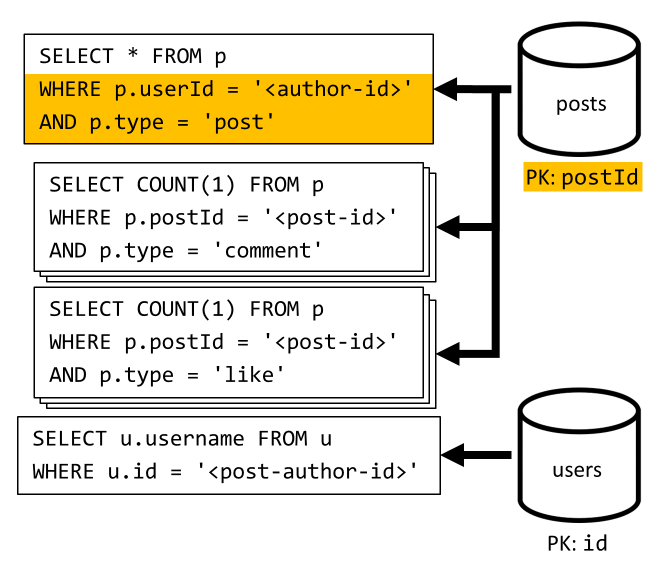
Tato implementace představuje mnoho nevýhod:
- dotazy agregující počty komentářů a lajky musí být vydány pro každý příspěvek vrácený prvním dotazem,
- Hlavní dotaz nefiltruje klíč
postsoddílu kontejneru, což vede ke kontrole ventilátoru a prohledávání oddílů napříč kontejnerem.
| Latence | Poplatek za RU | Výkon |
|---|---|---|
130 milisekunda |
619.41 RU |
⚠ |
[C3] Vytvoření komentáře
Komentář se vytvoří napsáním odpovídající položky v kontejneru posts .
| Latence | Poplatek za RU | Výkon |
|---|---|---|
7 milisekunda |
8.57 RU |
✅ |
[Q4] Výpis komentářů k příspěvku
Začneme dotazem, který načte všechny komentáře pro daný příspěvek a znovu, musíme také agregovat uživatelská jména pro každý komentář samostatně.
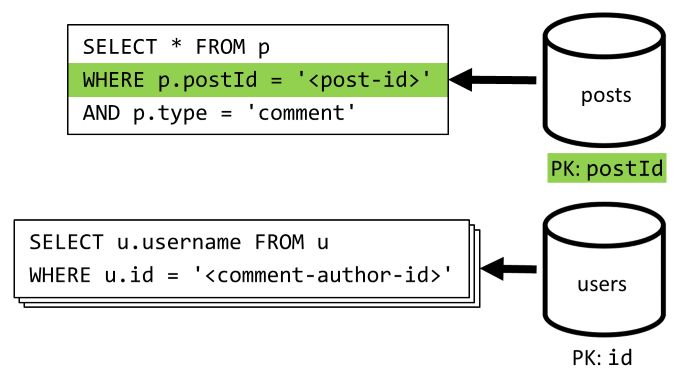
I když hlavní dotaz filtruje klíč oddílu kontejneru, agregace uživatelských jmen samostatně penalizuje celkový výkon. Později to vylepšíme.
| Latence | Poplatek za RU | Výkon |
|---|---|---|
23 milisekunda |
27.72 RU |
⚠ |
[C4] Líbí se příspěvku
Stejně jako [C3] vytvoříme odpovídající položku v kontejneru posts .
| Latence | Poplatek za RU | Výkon |
|---|---|---|
6 milisekunda |
7.05 RU |
✅ |
[Q5] Zobrazení seznamu lajků příspěvku
Stejně jako [Q4] se dotazujeme na lajky pro tento příspěvek a pak agregujeme jejich uživatelská jména.
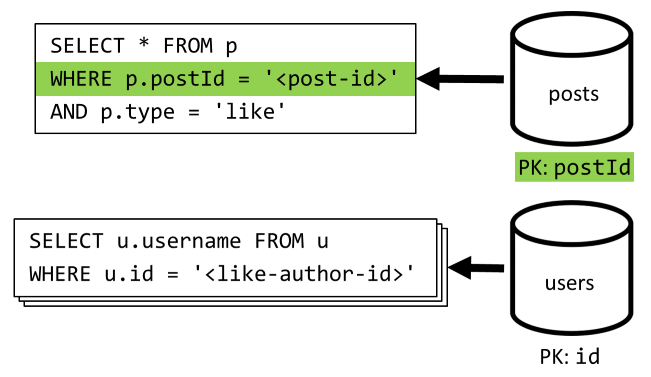
| Latence | Poplatek za RU | Výkon |
|---|---|---|
59 milisekunda |
58.92 RU |
⚠ |
[Q6] Zobrazení seznamu x nejnovějších příspěvků vytvořených v krátkém formátu (informační kanál)
Nejnovější příspěvky načteme dotazováním kontejneru posts seřazeného sestupným datem vytvoření, agregací uživatelských jmen a počty komentářů a lajků pro každý příspěvek.
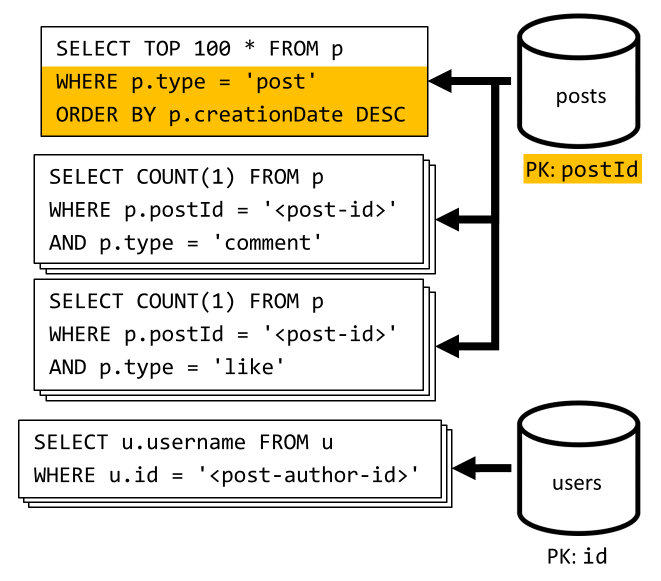
Náš počáteční dotaz znovu nefiltruje klíč posts oddílu kontejneru, který aktivuje nákladný ventilátor. Tato sada výsledků je ještě horší, protože cílíme na větší sadu výsledků a výsledky seřadíme pomocí ORDER BY klauzule, což z hlediska jednotek žádostí zdražuje.
| Latence | Poplatek za RU | Výkon |
|---|---|---|
306 milisekunda |
2063.54 RU |
⚠ |
Reflektování výkonu V1
Při pohledu na problémy s výkonem, kterým jsme čelí v předchozí části, můžeme identifikovat dvě hlavní třídy problémů:
- některé požadavky vyžadují vydání více dotazů, aby bylo možné shromáždit všechna data, která potřebujeme vrátit,
- některé dotazy nefiltrují klíč oddílu kontejnerů, na které cílí, což vede k rozšíření, které brání škálovatelnosti.
Pojďme všechny tyto problémy vyřešit tak, že začneme prvním.
V2: Představujeme denormalizaci pro optimalizaci dotazů pro čtení
Důvodem, proč musíme v některých případech vydávat další žádosti, je to, že výsledky počátečního požadavku neobsahují všechna data, která potřebujeme vrátit. Denormalizace dat řeší tento druh problému v naší sadě dat při práci s nerelačním úložištěm dat, jako je Azure Cosmos DB.
V našem příkladu upravíme položky příspěvku tak, aby se přidalo uživatelské jméno autora příspěvku, počet komentářů a počet lajků:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Také upravíme komentář a lajkujeme položky a přidáme uživatelské jméno uživatele, který ho vytvořil:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Denormalizace komentáře a lajkování počtů
Chceme toho dosáhnout tak, že pokaždé, když přidáme komentář nebo něco podobného, také zvýšíme commentCount nebo v odpovídajícím příspěvku likeCount . Když postId kontejner rozdělíte posts , nová položka (komentář nebo lajk) a odpovídající příspěvek se nachází ve stejném logickém oddílu. V důsledku toho můžeme k provedení této operace použít uloženou proceduru.
Při vytváření komentáře ([C3]) místo pouhého přidání nové položky v posts kontejneru voláme následující uloženou proceduru v tomto kontejneru:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Tato uložená procedura převezme ID příspěvku a textu nového komentáře jako parametry a pak:
- načte příspěvek.
- zvýší hodnotu
commentCount - nahradí příspěvek.
- přidá nový komentář.
Při provádění uložených procedur jako atomických transakcí zůstává hodnota commentCount a skutečný počet komentářů vždy synchronizovaný.
Samozřejmě voláme podobnou uloženou proceduru při přidávání nových lajků k přírůstku likeCount.
Denormalizace uživatelských jmen
Uživatelská jména vyžadují jiný přístup, protože uživatelé se nacházejí nejen v různých oddílech, ale v jiném kontejneru. Když musíme denormalizovat data napříč oddíly a kontejnery, můžeme použít kanál změn zdrojového kontejneru.
V našem příkladu použijeme kanál změn kontejneru users k reakci vždy, když uživatelé aktualizují svoje uživatelská jména. Když k tomu dojde, rozšíříme změnu voláním jiné uložené procedury v kontejneru posts :
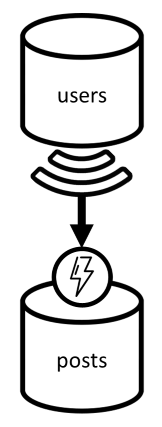
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Tato uložená procedura přebírá ID uživatele a nové uživatelské jméno uživatele jako parametry a pak:
- načte všechny položky odpovídající
userId(které můžou být příspěvky, komentáře nebo lajky). - pro každou z těchto položek
- nahrazuje
userUsername - nahradí položku.
- nahrazuje
Důležité
Tato operace je nákladná, protože vyžaduje, aby se tato uložená procedura spustila v každém oddílu kontejneru posts . Předpokládáme, že většina uživatelů zvolí během registrace vhodné uživatelské jméno a nikdy ho nezmění, takže tato aktualizace se spustí velmi zřídka.
Jaké jsou zvýšení výkonu V2?
Pojďme si promluvit o některých nárůstech výkonu V2.
[Q2] Načtení příspěvku
Teď, když je naše denormalizace na místě, musíme načíst pouze jednu položku pro zpracování této žádosti.
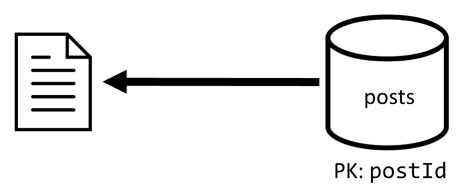
| Latence | Poplatek za RU | Výkon |
|---|---|---|
2 milisekunda |
1 RU |
✅ |
[Q4] Výpis komentářů k příspěvku
Opět můžeme ušetřit další požadavky, které načítá uživatelská jména, a nakonec jediným dotazem, který filtruje klíč oddílu.
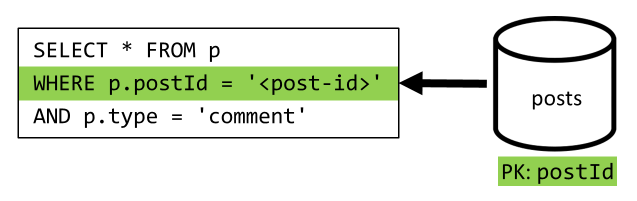
| Latence | Poplatek za RU | Výkon |
|---|---|---|
4 milisekunda |
7.72 RU |
✅ |
[Q5] Zobrazení seznamu lajků příspěvku
Stejná situace při výpisu lajků.
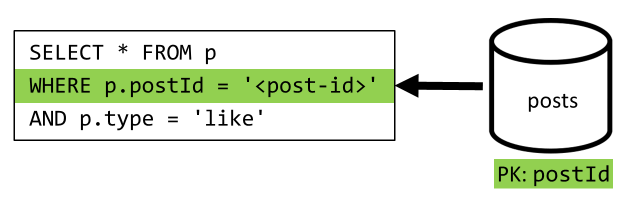
| Latence | Poplatek za RU | Výkon |
|---|---|---|
4 milisekunda |
8.92 RU |
✅ |
V3: Zajištění škálovatelnosti všech požadavků
Stále existují dva požadavky, které jsme plně neoptimalizovali při pohledu na naše celková vylepšení výkonu. Tyto požadavky jsou [Q3] a [Q6]. Jedná se o požadavky týkající se dotazů, které nefiltrují klíč oddílu kontejnerů, na které cílí.
[Q3] Výpis příspěvků uživatele ve krátkém formátu
Tato žádost již přináší výhody vylepšení představených ve verzi 2, která šetří více dotazů.

Zbývající dotaz ale stále nefiltruje klíč oddílu kontejneru posts .
Způsob, jak se zamyslet nad touto situací, je jednoduchá:
- Tento požadavek musí filtrovat podle
userIdtoho, že chceme načíst všechny příspěvky pro konkrétního uživatele. - Nefunguje dobře, protože se provádí proti kontejneru
posts, který nemáuserIddělení. - Když uvedeme zřejmé, vyřešili bychom problém s výkonem provedením tohoto požadavku na kontejner rozdělený na oddíly
userId. - Ukázalo se, že už takový kontejner máme:
userskontejner!
Proto zavádíme druhou úroveň denormalizace duplikováním celých příspěvků do kontejneru users . Díky tomu efektivně získáme kopii našich příspěvků, pouze rozdělené podle jiné dimenze, což jim umožní zefektivnit načítání podle jejich userId.
Kontejner users teď obsahuje dva druhy položek:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
V tomto příkladu:
- Zavedli
typejsme v položce uživatele pole pro rozlišení uživatelů od příspěvků. - Do položky uživatele jsme také přidali
userIdpole, které je redundantní s polemid, ale vyžaduje se, protožeuserskontejner je teď rozdělený nauserIdoddíly (a neidjako dříve).
Abychom toho denormalizace dosáhli, znovu použijeme informační kanál změn. Tentokrát reagujeme na kanál změn kontejneru posts a odešleme do kontejneru users jakýkoli nový nebo aktualizovaný příspěvek. A protože výpis příspěvků nevyžaduje vrácení celého obsahu, můžeme je v procesu zkrátit.
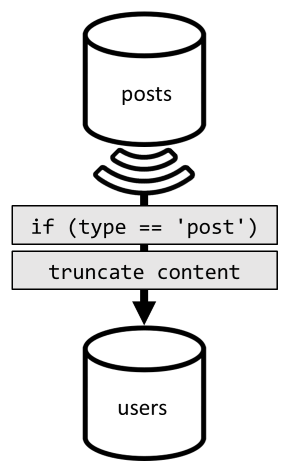
Teď můžeme směrovat dotaz do kontejneru users a filtrovat klíč oddílu kontejneru.

| Latence | Poplatek za RU | Výkon |
|---|---|---|
4 milisekunda |
6.46 RU |
✅ |
[Q6] Zobrazení seznamu x nejnovějších příspěvků vytvořených v krátkém formátu (informační kanál)
Musíme se zde vypořádat s podobnou situací: i po uvolnění dalších dotazů nepotřebných denormalizací zavedeným ve V2 se zbývající dotaz nefiltruje na klíč oddílu kontejneru:
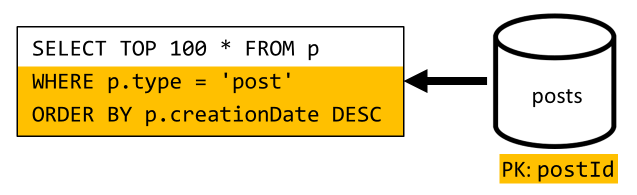
Při dosažení stejného přístupu vyžaduje maximalizace výkonu a škálovatelnosti tohoto požadavku, aby dosáhl pouze jednoho oddílu. Dosažení pouze jednoho oddílu je možné, protože musíme vrátit pouze omezený počet položek. Abychom mohli naplnit domovskou stránku naší blogovací platformy, stačí získat 100 nejnovějších příspěvků, aniž by bylo nutné stránkovat celou datovou sadu.
Abychom mohli tento poslední požadavek optimalizovat, zavádíme do našeho návrhu třetí kontejner, který je zcela vyhrazený pro obsluhu tohoto požadavku. Naše příspěvky do nového feed kontejneru denormalizujeme:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Pole type rozdělí tento kontejner, který je vždy post v našich položkách. Tím zajistíte, že všechny položky v tomto kontejneru budou sedět ve stejném oddílu.
Abychom dosáhli denormalizace, stačí připojit kanál kanálu změn, který jsme dříve zavedli k odeslání příspěvků do tohoto nového kontejneru. Je důležité mít na paměti, že musíme zajistit, že ukládáme pouze 100 nejnovějších příspěvků; jinak se obsah kontejneru může zvětšit nad maximální velikost oddílu. Toto omezení je možné implementovat voláním triggeru po každém přidání dokumentu do kontejneru:
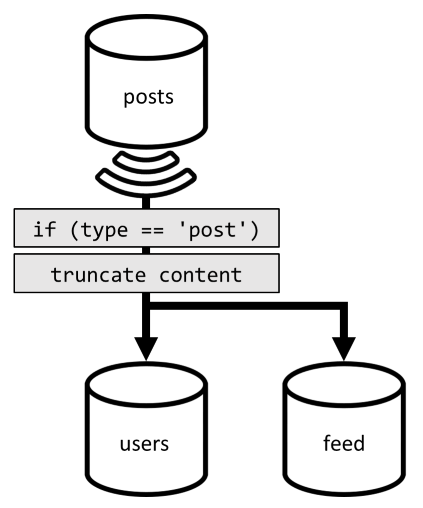
Tady je text post-triggeru, který zkrátí kolekci:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Posledním krokem je přesměrování dotazu na nový feed kontejner:
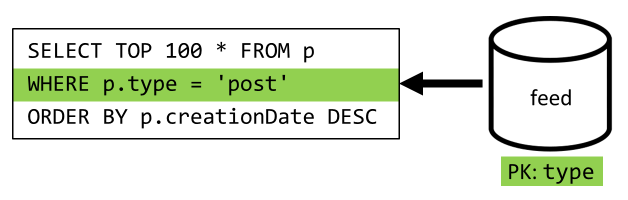
| Latence | Poplatek za RU | Výkon |
|---|---|---|
9 milisekunda |
16.97 RU |
✅ |
Závěr
Pojďme se podívat na celkové vylepšení výkonu a škálovatelnosti, která jsme zavedli v různých verzích našeho návrhu.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Optimalizovali jsme scénář náročný na čtení.
Možná jste si všimli, že jsme se zaměřili na zlepšení výkonu žádostí o čtení (dotazů) na úkor požadavků na zápis (příkazy). V mnoha případech teď operace zápisu aktivují následnou denormalizaci prostřednictvím kanálů změn, což z nich dělá výpočetně nákladnější a delší materializaci.
Odůvodňujeme toto zaměření na výkon čtení tím, že platforma pro blogování (podobně jako většina sociálních aplikací) je pro čtení silná. Úloha náročné na čtení značí, že množství požadavků na čtení, které musí obsloužit, je obvykle řádově vyšší než počet žádostí o zápis. Proto je vhodné, aby žádosti o zápis byly dražší, aby bylo možné žádosti o čtení levnější a lépe fungovat.
Pokud se podíváme na nejvýkonnější optimalizaci, kterou jsme provedli, [Q6] přešla z 2000 ru na pouhých 17 RU. Dosáhli jsme toho denormalizací příspěvků za cenu přibližně 10 RU na položku. Protože bychom sloužili mnohem více žádostí o kanál než vytváření nebo aktualizace příspěvků, náklady na tuto denormalizaci jsou zanedbatelné vzhledem k celkové úsporě.
Denormalizace se dá použít přírůstkově.
Vylepšení škálovatelnosti, která jsme prozkoumali v tomto článku, zahrnují denormalizaci a duplikování dat v datové sadě. Je třeba poznamenat, že tyto optimalizace nemusí být zavedeny v den 1. Dotazy, které filtrují klíče oddílů, fungují ve velkém lépe, ale dotazy napříč oddíly můžou být přijatelné, pokud se volají zřídka nebo v omezené sadě dat. Pokud vytváříte prototyp nebo spouštíte produkt s malou a řízenou uživatelskou základnou, můžete tato vylepšení pravděpodobně ušetřit pro pozdější použití. Co je pak důležité, je monitorovat výkon modelu, abyste se mohli rozhodnout, jestli a kdy je čas je přenést.
Kanál změn, který používáme k distribuci aktualizací do jiných kontejnerů, uchovává všechny tyto aktualizace trvale. Tato trvalost umožňuje požadovat všechny aktualizace od vytvoření kontejneru a denormalizovaných zobrazení bootstrap jako jednorázově dohoněnou operaci i v případě, že váš systém již obsahuje mnoho dat.
Další kroky
Po tomto úvodu do praktického modelování a dělení dat můžete zkontrolovat následující články a projít si koncepty, které jsme probrali: