Dělení ve službě Azure Cosmos DB pro Apache Cassandra
PLATÍ PRO: ![]() Cassandra
Cassandra
Tento článek popisuje, jak funguje dělení ve službě Azure Cosmos DB pro Apache Cassandra.
Rozhraní API pro Cassandra používá dělení k škálování jednotlivých tabulek v prostoru klíčů tak, aby splňovalo požadavky vaší aplikace na výkon. Oddíly se vytvářejí na základě hodnoty klíče oddílu, který je přidružený ke každému záznamu v tabulce. Všechny záznamy v oddílu mají stejnou hodnotu klíče oddílu. Azure Cosmos DB transparentně a automaticky spravuje umístění oddílů mezi fyzické prostředky, aby efektivně splňovala požadavky na škálovatelnost a výkon tabulky. S rostoucími požadavky na propustnost a úložiště aplikace azure Cosmos DB přesouvá a vyrovnává data na větším počtu fyzických počítačů.
Z pohledu vývojáře se dělení chová stejně pro Službu Cosmos DB pro Apache Cassandra jako v nativní službě Apache Cassandra. Na pozadí ale existují určité rozdíly.
Rozdíly mezi Apache Cassandra a Azure Cosmos DB
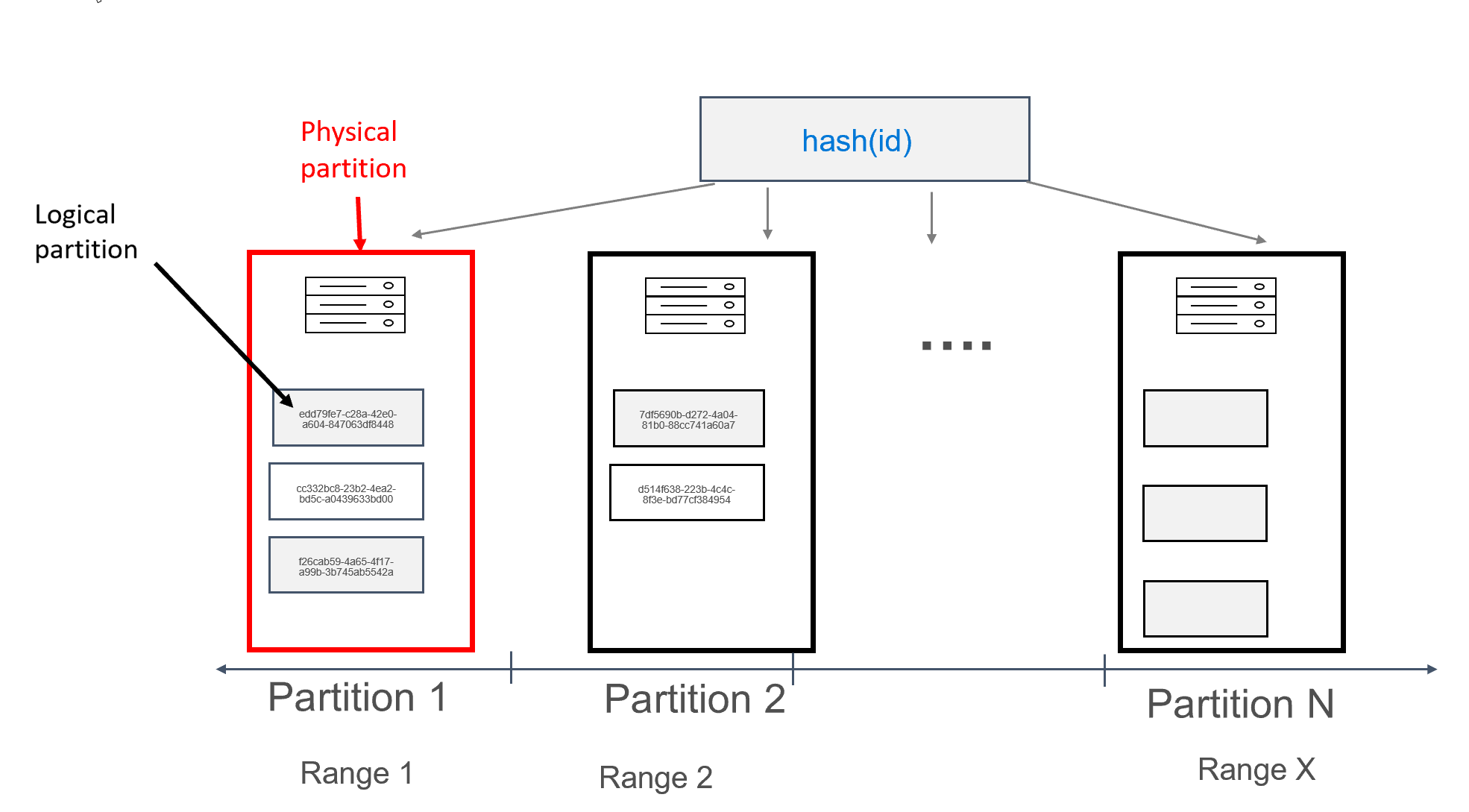
Ve službě Azure Cosmos DB se každý počítač, na kterém jsou uložené oddíly, označuje jako fyzický oddíl. Fyzický oddíl je podobný virtuálnímu počítači; vyhrazenou výpočetní jednotku nebo sadu fyzických prostředků. Každý oddíl uložený v této výpočetní jednotce se v Azure Cosmos DB označuje jako logický oddíl . Pokud už znáte Apache Cassandra, můžete si logické oddíly představit stejným způsobem jako běžné oddíly v Cassandře.
Apache Cassandra doporučuje limit 100 MB velikosti dat, která je možné uložit do oddílu. Rozhraní API pro Cassandra pro Azure Cosmos DB umožňuje až 20 GB na logický oddíl a až 30 GB dat na fyzický oddíl. Na rozdíl od Apache Cassandra se výpočetní kapacita dostupná ve fyzickém oddílu v Azure Cosmos DB vyjadřuje pomocí jedné metriky označované jako jednotky žádostí, které vám umožní uvažovat o úlohách z hlediska požadavků (čtení nebo zápisů) za sekundu místo jader, paměti nebo IOPS. To může usnadnit plánování kapacity, jakmile porozumíte nákladům na jednotlivé žádosti. Každý fyzický oddíl může mít k dispozici až 1 0000 RU výpočetních prostředků. Další informace o možnostech škálovatelnosti najdete v našem článku o elastickém škálování v rozhraní API pro Cassandra.
Ve službě Azure Cosmos DB se každý fyzický oddíl skládá ze sady replik, označovaných také jako sady replik s alespoň 4 replikami na oddíl. To je na rozdíl od Apache Cassandra, kde je možné nastavit faktor replikace 1. To ale vede k nízké dostupnosti, pokud se jediný uzel s daty vypne. V rozhraní API cassandra je vždy faktor replikace 4 (kvorum 3). Azure Cosmos DB automaticky spravuje sady replik, zatímco je potřeba je udržovat pomocí různých nástrojů v Apache Cassandře.
Apache Cassandra má koncept tokenů, což jsou hodnoty hash klíčů oddílů. Tokeny jsou založeny na hodnotě hash nártu 64 bajtů s hodnotami v rozsahu -2^63 až -2^63 -1. Tento rozsah se v Apache Cassandře běžně označuje jako okruh tokenů. Okruh tokenů se distribuuje do rozsahů tokenů a tyto rozsahy jsou rozdělené mezi uzly, které jsou přítomné v nativním clusteru Apache Cassandra. Dělení pro službu Azure Cosmos DB se implementuje podobným způsobem, ale používá jiný algoritmus hash a má větší interní okruh tokenů. Externě však zveřejňujeme stejný rozsah tokenů jako Apache Cassandra, tj. -2^63 až -2^63 -1.
Primární klíč
Všechny tabulky v rozhraní API pro Cassandru musí mít primary key definované. Syntaxe primárního klíče je znázorněna níže:
column_name cql_type_definition PRIMARY KEY
Předpokládejme, že chceme vytvořit uživatelskou tabulku, která ukládá zprávy pro různé uživatele:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
V tomto návrhu id jsme definovali pole jako primární klíč. Primární klíč funguje jako identifikátor záznamu v tabulce a slouží také jako klíč oddílu ve službě Azure Cosmos DB. Pokud je primární klíč definovaný dříve popsaným způsobem, bude v každém oddílu jenom jeden záznam. Výsledkem bude dokonale vodorovná a škálovatelná distribuce při zápisu dat do databáze a je ideální pro případy použití vyhledávání klíč-hodnota. Aplikace by měla poskytnout primární klíč při každém čtení dat z tabulky, aby se maximalizoval výkon čtení.
Složený primární klíč
Apache Cassandra má také koncept compound keys. Složená primary key složka se skládá z více než jednoho sloupce; první sloupec je partition keysloupec a všechny další sloupce jsou clustering keys. Syntaxe obrázku compound primary key je znázorněná níže:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Předpokládejme, že chceme změnit výše uvedený návrh a efektivně načíst zprávy pro daného uživatele:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
V tomto návrhu teď definujeme user jako klíč oddílu a id jako klíč clusteringu. Můžete definovat libovolný počet klíčů clusteringu, ale každá hodnota (nebo kombinace hodnot) pro klíč clusteringu musí být jedinečná, aby se do stejného oddílu přidalo více záznamů, například:
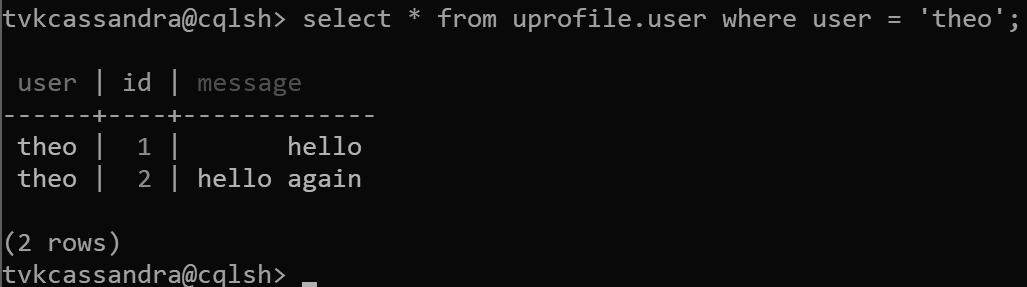
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Když se data vrátí, seřadí se podle klíče clusteringu podle očekávání v Apache Cassandře:
Upozorňující
Při dotazování dat v tabulce, která má složený primární klíč, pokud chcete filtrovat klíč oddílu a další neindexovaná pole kromě klíče clusteringu, ujistěte se, že do klíče oddílu explicitně přidáte sekundární index:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB pro Apache Cassandra ve výchozím nastavení nepoužívá indexy na klíče oddílů a index v tomto scénáři může výrazně zlepšit výkon dotazů. Další informace najdete v našem článku o sekundárním indexování .
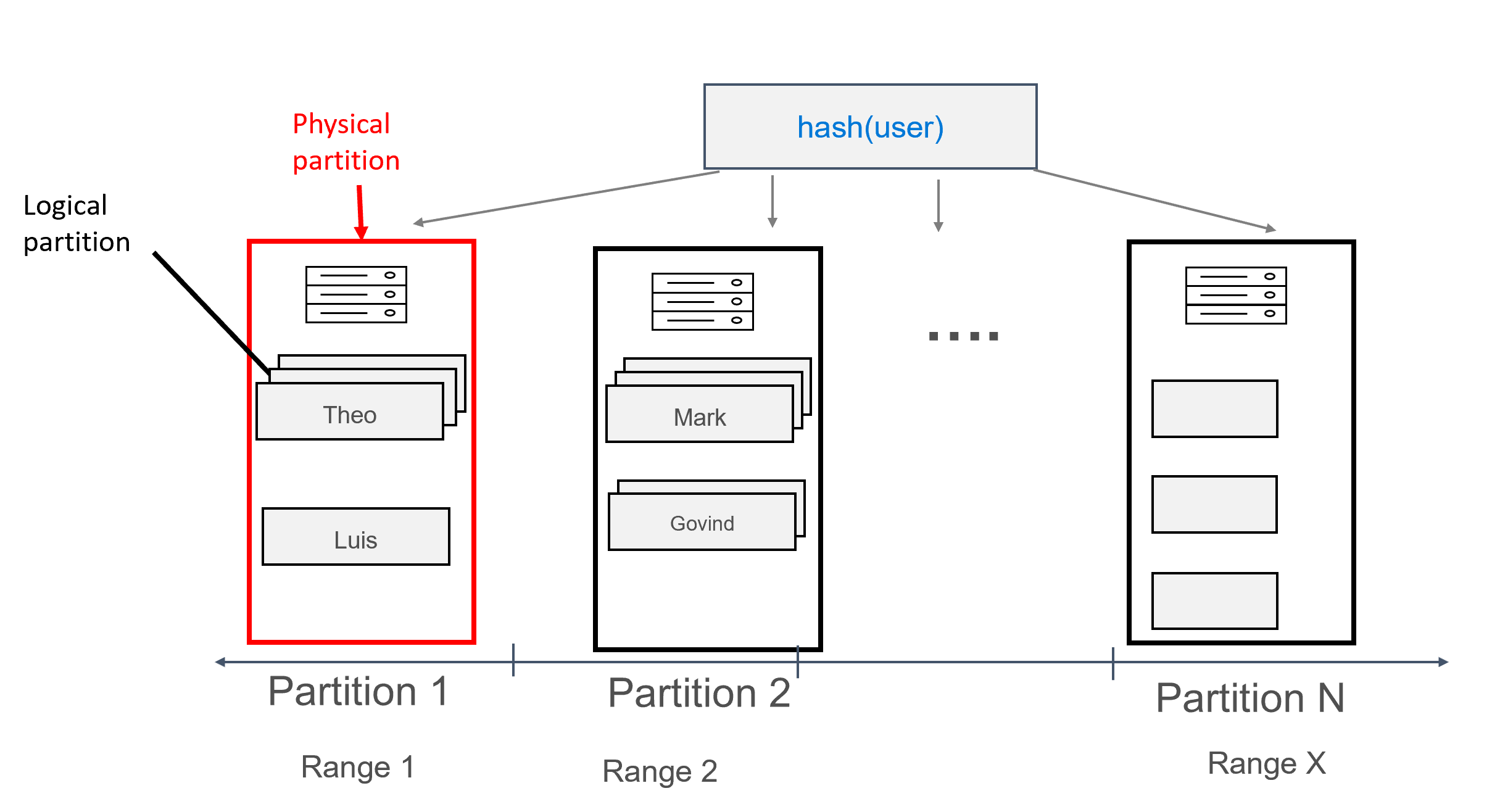
S tímto způsobem je možné přiřadit více záznamů ke každému oddílu seskupeným uživatelem. Proto můžeme vydat dotaz, který je efektivně směrován partition key (v tomto případě user) a získat všechny zprávy pro daného uživatele.
Složený klíč oddílu
Složené klíče oddílů fungují v podstatě stejně jako složené klíče, s tím rozdílem, že jako složený klíč oddílu můžete zadat více sloupců. Syntaxe složených klíčů oddílů je znázorněná níže:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Můžete mít například následující, kde jedinečná kombinace firstname a lastname tvoří klíč oddílu a id je klíč clusteringu:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Další kroky
- Seznamte se s dělením a horizontálním škálováním ve službě Azure Cosmos DB.
- Přečtěte si o zřízené propustnosti ve službě Azure Cosmos DB.
- Seznamte se s globální distribucí ve službě Azure Cosmos DB.