Výkon a škálování v Durable Functions (Azure Functions)
Pro optimalizaci výkonu a škálovatelnosti je důležité porozumět jedinečným charakteristikám škálování Durable Functions. V tomto článku vysvětlujeme, jak se pracovní procesy škálují na základě zatížení a jak lze ladit různé parametry.
Škálování pracovního procesu
Základní výhodou konceptu centra úkolů je, že počet pracovních procesů, které zpracovávají pracovní položky centra úkolů, je možné průběžně upravovat. Konkrétně můžou aplikace přidávat další pracovní procesy (horizontální navýšení kapacity), pokud je potřeba práci zpracovat rychleji, a můžou pracovní procesy odebrat (škálovat se), pokud není dostatek práce, aby pracovní procesy zůstaly zaneprázdněné. Pokud je centrum úloh zcela nečinné, je dokonce možné škálovat na nulu . Při škálování na nulu neexistují žádní pracovníci; pouze řadič škálování a úložiště musí zůstat aktivní.
Následující diagram znázorňuje tento koncept:
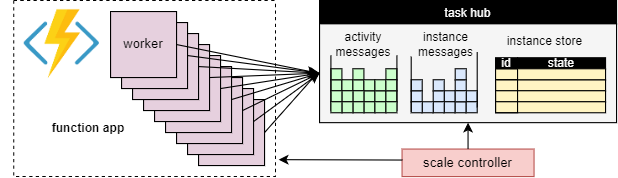
Automatické škálování
Stejně jako všechny funkce Azure Functions běžící v plánech Consumption a Elastic Premium podporuje Durable Functions automatické škálování prostřednictvím kontroleru škálování Azure Functions. Kontroler škálování monitoruje, jak dlouho musí zprávy a úlohy čekat, než se zpracovávají. Na základě těchto latencí se může rozhodnout, jestli se mají přidávat nebo odebírat pracovní procesy.
Poznámka:
Počínaje Durable Functions 2.0 je možné aplikace funkcí nakonfigurovat tak, aby běžely v rámci koncových bodů služby chráněné virtuální sítí v plánu Elastic Premium. V této konfiguraci triggery Durable Functions místo kontroleru škálování inicializuje žádosti o škálování. Další informace naleznete v tématu Monitorování škálování modulu runtime.
V plánu Premium může automatické škálování pomoct udržet počet pracovních procesů (a proto provozní náklady) zhruba úměrné zatížení, ke kterému aplikace dochází.
Využití procesoru
Funkce orchestratoru spouští logiku několikrát kvůli jejich chování při přehrání. Proto je důležité, aby vlákna funkce orchestrátoru neprovádějly úlohy náročné na procesor, vstupně-výstupní operace nebo blokovaly z jakéhokoli důvodu. Všechny práce, které můžou vyžadovat vstupně-výstupní operace, blokování nebo více vláken, by se měly přesunout do funkcí aktivit.
Funkce aktivit mají stejné chování jako běžné funkce aktivované frontou. Můžou bezpečně provádět vstupně-výstupní operace, spouštět operace náročné na procesor a používat více vláken. Vzhledem k tomu, že triggery aktivit jsou bezstavové, můžou volně škálovat na nevázaný počet virtuálních počítačů.
Funkce entit se také provádějí na jednom vlákně a operace se zpracovávají jednorázově. Funkce entit však nemají žádná omezení pro typ kódu, který lze spustit.
Časové limity funkcí
Funkce aktivit, orchestrátoru a entit podléhají stejným časovým limitům funkcí jako všechny funkce Azure Functions. Obecně platí, že Durable Functions zpracovává časové limity funkcí stejně jako neošetřené výjimky vyvolané kódem aplikace.
Pokud dojde například k vypršení časového limitu aktivity, zaznamená se spuštění funkce jako selhání a orchestrátor se upozorní a zpracuje časový limit stejně jako jakákoli jiná výjimka: opakování probíhá, pokud je zadáno voláním, nebo může být spuštěna obslužná rutina výjimky.
Dávkování operací entit
Aby se zlepšil výkon a snížily náklady, může jedna pracovní položka provádět celou dávku operací entit. V plánech consumption se pak každá dávka fakturuje jako jedna spuštění funkce.
Ve výchozím nastavení je maximální velikost dávky 50 pro plány spotřeby a 5000 pro všechny ostatní plány. Maximální velikost dávky lze také nakonfigurovat v souboru host.json . Pokud je maximální velikost dávky 1, je dávkování účinně zakázáno.
Poznámka:
Pokud provádění jednotlivých operací entit trvá dlouho, může být užitečné omezit maximální velikost dávky, aby se snížilo riziko vypršení časových limitů funkcí, zejména u plánů spotřeby.
Ukládání do mezipaměti instance
Obecně platí, že pokud chcete zpracovat pracovní položku orchestrace, musí pracovní proces obojí
- Načtěte historii orchestrace.
- Přehrajte kód orchestrátoru pomocí historie.
Pokud stejný pracovní proces zpracovává více pracovních položek pro stejnou orchestraci, může poskytovatel úložiště tento proces optimalizovat uložením do mezipaměti historie v paměti pracovního procesu, což eliminuje první krok. Kromě toho může orchestrátor mid-execution ukládat do mezipaměti, což eliminuje druhý krok, přehrání historie a také.
Typickým účinkem ukládání do mezipaměti je snížení vstupně-výstupních operací vůči základní službě úložiště a celková vyšší propustnost a latence. Na druhou stranu ukládání do mezipaměti zvyšuje spotřebu paměti pracovního procesu.
Ukládání do mezipaměti instance v současné době podporuje poskytovatel služby Azure Storage a poskytovatel úložiště Netherite. Následující tabulka obsahuje porovnání.
| Poskytovatel služby Azure Storage | Zprostředkovatel úložiště Netherite | Poskytovatel úložiště MSSQL | |
|---|---|---|---|
| Ukládání do mezipaměti instance | Podporováno (Pouze pracovní proces v .NET) |
Podporováno | Nepodporováno |
| Výchozí nastavení | Disabled | Povolený | Není k dispozici |
| Mechanismus | Rozšířené relace | Mezipaměť instancí | Není k dispozici |
| Dokumentace | Zobrazit rozšířené relace | Zobrazit mezipaměť instancí | Není k dispozici |
Tip
Ukládání do mezipaměti může snížit četnost přehrání historie, ale nemůže úplně eliminovat opakované přehrání. Při vývoji orchestrátorů důrazně doporučujeme je otestovat na konfiguraci, která zakazuje ukládání do mezipaměti. Toto chování vynuceného přehrání může být užitečné pro detekci porušení omezení kódu funkce orchestrátoru v době vývoje.
Porovnání mechanismů ukládání do mezipaměti
Poskytovatelé k implementaci ukládání do mezipaměti používají různé mechanismy a nabízejí různé parametry pro konfiguraci chování ukládání do mezipaměti.
-
Rozšířené relace používané poskytovatelem služby Azure Storage udržují orchestrátory uprostřed spouštění v paměti, dokud nebudou nějakou dobu nečinné. Parametry pro řízení tohoto mechanismu jsou
extendedSessionsEnabledaextendedSessionIdleTimeoutInSeconds. Další podrobnosti najdete v části Rozšířené relace v dokumentaci poskytovatele služby Azure Storage.
Poznámka:
Rozšířené relace jsou podporovány pouze v pracovním procesu .NET.
- Mezipaměť instance, jak ji používá zprostředkovatel úložiště Netherite, uchovává stav všech instancí, včetně jejich historie, v paměti pracovního procesu a přitom sleduje celkovou využitou paměť. Pokud velikost mezipaměti překročí limit nakonfigurovaný službou
InstanceCacheSizeMB, data nejméně naposledy použitých instancí se vyřadí. PokudCacheOrchestrationCursorsje nastavena hodnota true, mezipaměť také ukládá orchestrátory mid-execution spolu se stavem instance. Další podrobnosti najdete v části Mezipaměť instance dokumentace poskytovatele úložiště Netherite.
Poznámka:
Instance ukládají do mezipaměti všechny sady SDK jazyka, ale CacheOrchestrationCursors tato možnost je k dispozici pouze pro pracovní proces .NET v procesu.
Omezení souběžnosti
Jedna instance pracovního procesu může souběžně spouštět více pracovních položek . To pomáhá zvýšit paralelismus a efektivněji využívat pracovní procesy. Pokud se ale pracovní proces pokusí zpracovat příliš mnoho pracovních položek najednou, může vyčerpat dostupné prostředky, jako je zatížení procesoru, počet síťových připojení nebo dostupná paměť.
Aby se zajistilo, že jednotlivý pracovní proces nepřekončí, může být nutné omezovat souběžnost jednotlivých instancí. Omezením počtu funkcí, které jsou současně spuštěny u každého pracovního procesu, můžeme se vyhnout vyčerpání limitů prostředků pro daný pracovní proces.
Poznámka:
Omezení souběžnosti platí jenom místně, aby se omezilo aktuálně zpracovávané na pracovní proces. Tato omezení tedy neomešují celkovou propustnost systému.
Tip
V některýchpřípadechch K tomu může dojít, když každý pracovní proces zabere méně práce, což způsobí, že kontroler škálování přidá další pracovní procesy, aby udržel krok s frontami, což pak zvýší celkovou propustnost.
Konfigurace omezení
Omezení souběžnosti aktivit, orchestrátoru a funkce entity je možné nakonfigurovat v souboru host.json . Relevantní nastavení jsou durableTask/maxConcurrentActivityFunctions pro funkce aktivit a durableTask/maxConcurrentOrchestratorFunctions pro funkce orchestrátoru i entity. Tato nastavení řídí maximální počet funkcí orchestrátoru, entity nebo aktivity, které jsou načteny do paměti v jednom pracovním procesu.
Poznámka:
Orchestrace a entity se načtou do paměti pouze v případě, že aktivně zpracovávají události nebo operace nebo pokud je povolené ukládání do mezipaměti instance. Po spuštění logiky a čekání (tj. stisknutí await příkazu (C#) nebo yield (JavaScript, Python) v kódu funkce orchestrátoru) se můžou uvolnit z paměti. Orchestrace a entity, které jsou uvolněné z paměti, se nezapočítávají do maxConcurrentOrchestratorFunctions omezení. I když jsou miliony orchestrací nebo entit ve stavu Spuštěno, počítají se pouze do limitu omezení při jejich načtení do aktivní paměti. Orchestrace, která plánuje funkci aktivity podobně, se nezapočítává do omezení, pokud orchestrace čeká na dokončení provádění aktivity.
Funkce 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Důležité informace o modulu runtime jazyka
Jazykový modul runtime, který vyberete, může uplatňovat striktní omezení souběžnosti nebo vaše funkce. Aplikace Durable Function App napsané v Pythonu nebo PowerShellu můžou například podporovat pouze spuštění jedné funkce najednou na jednom virtuálním počítači. To může vést k významným problémům s výkonem, pokud nejsou pečlivě zohledněné. Pokud například orchestrátor fandí na 10 aktivit, ale modul runtime jazyka omezuje souběžnost pouze na jednu funkci, pak se 9 z 10 funkcí aktivity zablokuje a čeká na spuštění. Tyto 9 zablokované aktivity navíc nebudou moct být vyrovnávat zatížení žádným jiným pracovníkům, protože modul runtime Durable Functions je už načetl do paměti. To se stává obzvláště problematické, pokud jsou funkce aktivit dlouhotrvající.
Pokud modul runtime jazyka, který používáte, omezuje souběžnost, měli byste aktualizovat nastavení souběžnosti Durable Functions tak, aby odpovídalo nastavení souběžnosti modulu runtime vašeho jazyka. Tím se zajistí, že se modul runtime Durable Functions nebude pokoušet spouštět více funkcí souběžně, než je povoleno modulem runtime jazyka, což umožňuje vyrovnávání zatížení všech čekajících aktivit na jiných virtuálních počítačích. Pokud máte například aplikaci v Pythonu, která omezuje souběžnost na 4 funkce (možná je nakonfigurovaná pouze se 4 vlákny v jednom pracovním procesu jazyka nebo 1 vláknem ve 4 jazykových pracovních procesech), měli byste nakonfigurovat obě maxConcurrentOrchestratorFunctions a maxConcurrentActivityFunctions až 4.
Další informace a doporučení k výkonu pro Python najdete v tématu Zvýšení výkonu propustnosti aplikací v Pythonu ve službě Azure Functions. Techniky uvedené v této referenční dokumentaci pro vývojáře Pythonu můžou mít významný dopad na výkon a škálovatelnost Durable Functions.
Počet oddílů
Někteří poskytovatelé úložiště používají mechanismus dělení a umožňují zadat partitionCount parametr.
Při použití dělení nekonkurují pracovní procesy přímo pro jednotlivé pracovní položky. Místo toho jsou pracovní položky nejprve seskupené do partitionCount oddílů. Tyto oddíly se pak přiřadí pracovníkům. Tento dělený přístup k distribuci zatížení může pomoct snížit celkový počet požadovaných přístupů k úložišti. Může také povolit ukládání instancí do mezipaměti a zlepšit umístění, protože vytváří spřažení: všechny pracovní položky pro stejnou instanci se zpracovávají stejným pracovním procesem.
Poznámka:
Dělení omezuje horizontální navýšení kapacity, protože většina partitionCount pracovních procesů může zpracovávat pracovní položky z dělené fronty.
Následující tabulka ukazuje, pro každého zprostředkovatele úložiště, které fronty jsou rozdělené do oddílů, a povolený rozsah a výchozí hodnoty parametru partitionCount .
| Poskytovatel služby Azure Storage | Zprostředkovatel úložiště Netherite | Poskytovatel úložiště MSSQL | |
|---|---|---|---|
| Zprávy instance | Partitioned | Partitioned | Není dělené |
| Zprávy o aktivitách | Není dělené | Partitioned | Není dělené |
Výchozí partitionCount |
4 | 12 | Není k dispozici |
Maximum partitionCount |
16 | 32 | Není k dispozici |
| Dokumentace | Viz škálování orchestratoru na více instancí. | Viz důležité informace o počtu oddílů. | Není k dispozici |
Upozorňující
Po vytvoření centra úloh už nelze počet oddílů změnit. Proto je vhodné ji nastavit na dostatečně velkou hodnotu, aby vyhovovala budoucím požadavkům na horizontální navýšení kapacity pro instanci centra úloh.
Konfigurace počtu oddílů
Parametr partitionCount lze zadat v souboru host.json . Následující příklad host.json fragment kódu durableTask/storageProvider/partitionCount nastaví vlastnost (nebo durableTask/partitionCount v Durable Functions 1.x) na 3.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Důležité informace o minimalizaci latencí vyvolání
Za normálních okolností by se žádosti o vyvolání (na aktivity, orchestrátory, entity atd.) měly zpracovávat poměrně rychle. Neexistuje ale žádná záruka maximální latence jakéhokoli požadavku na vyvolání, protože závisí na faktorech, jako jsou: typ chování služby App Service, nastavení souběžnosti a velikost backlogu vaší aplikace. Proto doporučujeme investovat do zátěžového testování , abyste mohli měřit a optimalizovat latence vaší aplikace.
Cíle výkonu
Při plánování použití Durable Functions pro produkční aplikaci je důležité zvážit požadavky na výkon v rané fázi procesu plánování. Mezi základní scénáře použití patří:
- Provádění sekvenčních aktivit: Tento scénář popisuje funkci orchestrátoru, která spouští řadu funkcí aktivit po druhé. Nejvíce se podobá ukázce řetězení funkcí.
- Paralelní provádění aktivit: Tento scénář popisuje funkci orchestrátoru, která paralelně spouští mnoho funkcí aktivit pomocí modelu Fan-out a Fan-in .
- Paralelní zpracování odpovědí: Tento scénář je druhou polovinou modelu Fan-out, Fan-in . Zaměřuje se na výkon ventilátoru. Je důležité si uvědomit, že na rozdíl od ventilátoru se ventilátor provádí jednou instancí funkce orchestrátoru, a proto se dá spustit jenom na jednom virtuálním počítači.
- Zpracování externích událostí: Tento scénář představuje jednu instanci funkce orchestrátoru, která čeká na externí události po jednom.
- Zpracování operací entit: Tento scénář testuje, jak rychle může jednaentita čítače zpracovat konstantní datový proud operací.
V příslušné dokumentaci pro poskytovatele úložiště poskytujeme čísla propustnosti pro tyto scénáře. Zejména jde o toto:
- informace o poskytovateli služby Azure Storage najdete v tématu Cíle výkonu.
- pro poskytovatele úložiště Netherite, viz Základní scénáře.
- informace o poskytovateli úložiště MSSQL naleznete v tématu Srovnávací testy propustnosti orchestrace.
Tip
Na rozdíl od ventilátoru jsou operace s ventilátory omezené na jeden virtuální počítač. Pokud vaše aplikace používá model ventilátorů, ventilátorů a máte obavy o výkon ventilátorů, zvažte dílčí rozdělení ventilátoru funkce aktivity mezi několik dílčích orchestrací.