Řešení potíží s kritickými body výkonu v Azure Databricks
Poznámka:
Tento článek spoléhá na opensourcovou knihovnu hostované na GitHubu na adrese: https://github.com/mspnp/spark-monitoring.
Původní knihovna podporuje Azure Databricks Runtimes 10.x (Spark 3.2.x) a starší.
Databricks přispěl aktualizovanou verzí pro podporu azure Databricks Runtimes 11.0 (Spark 3.3.x) a vyšší ve l4jv2 větvi na adrese: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Upozorňujeme, že verze 11.0 není zpětně kompatibilní kvůli různým systémům protokolování používaným v modulech Databricks Runtime. Nezapomeňte použít správné sestavení pro databricks Runtime. Knihovna a úložiště GitHub jsou v režimu údržby. Pro další verze nejsou žádné plány a podpora problémů bude maximálně náročná. Pokud máte jakékoli další dotazy týkající se knihovny nebo plánu monitorování a protokolování prostředí Azure Databricks, obraťte se na azure-spark-monitoring-help@databricks.com.
Tento článek popisuje, jak pomocí řídicích panelů monitorování najít kritické body výkonu v úlohách Sparku v Azure Databricks.
Azure Databricks je analytická služba založená na Apache Sparku, která usnadňuje rychlý vývoj a nasazování analýz velkých objemů dat. Monitorování a řešení potíží s výkonem je zásadní při provozu produkčních úloh Azure Databricks. K identifikaci běžných problémů s výkonem je užitečné použít vizualizace monitorování na základě telemetrických dat.
Požadavky
Nastavení řídicích panelů Grafana zobrazených v tomto článku:
Nakonfigurujte cluster Databricks tak, aby odesílal telemetrii do pracovního prostoru služby Log Analytics pomocí knihovny monitorování Azure Databricks. Podrobnosti najdete v souboru readme GitHubu.
Nasaďte Grafana ve virtuálním počítači. Další informace najdete v tématu Použití řídicích panelů k vizualizaci metrik Azure Databricks.
Řídicí panel Grafana, který je nasazený, obsahuje sadu vizualizací časových řad. Každý graf je graf časových řad metrik souvisejících s úlohou Apache Sparku, fázemi úlohy a úkoly, které tvoří jednotlivé fáze.
Přehled výkonu Azure Databricks
Azure Databricks je založený na Apache Sparku, což je univerzální distribuovaný výpočetní systém. Kód aplikace, označovaný jako úloha, se spouští v clusteru Apache Spark, který koordinuje správce clusteru. Obecně platí, že úloha je nejvyšší měrnou jednotkou výpočtu. Úloha představuje úplnou operaci prováděnou aplikací Spark. Typická operace zahrnuje čtení dat ze zdroje, použití transformací dat a zápis výsledků do úložiště nebo jiného cíle.
Úlohy jsou rozdělené do fází. Úloha prochází fázemi postupně, což znamená, že pozdější fáze musí čekat na dokončení dřívějších fází. Fáze obsahují skupiny identických úloh , které je možné spouštět paralelně na několika uzlech clusteru Spark. Úkoly jsou nejpodrobnější jednotkou provádění, která se provádí v podmnožině dat.
Další části popisují některé vizualizace řídicích panelů, které jsou užitečné pro řešení potíží s výkonem.
Latence úloh a fází
Latence úlohy je doba trvání spuštění úlohy od spuštění, dokud se neskončí. Zobrazuje se jako percentily spuštění úlohy na cluster a ID aplikace, aby bylo možné vizualizaci odlehlých hodnot. Následující graf ukazuje historii úloh, kde 90. percentil dosáhl 50 sekund, i když 50. percentil byl konzistentně kolem 10 sekund.
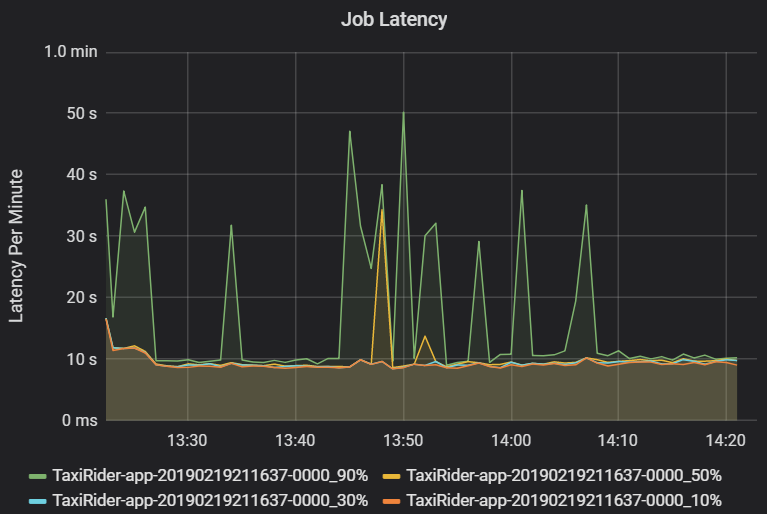
Prozkoumejte spouštění úloh podle clusteru a aplikace a vyhledejte špičky v latenci. Jakmile jsou clustery a aplikace s vysokou latencí identifikovány, přejděte k prozkoumání latence fáze.
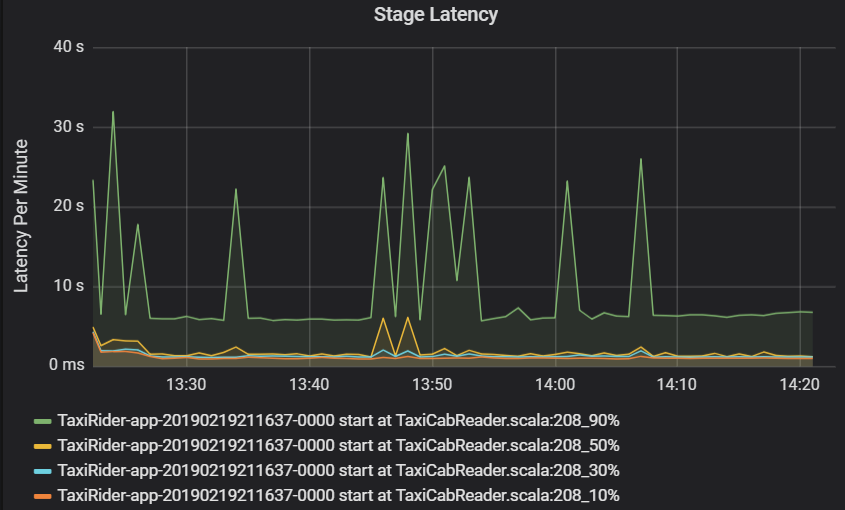
Latence fáze se také zobrazuje jako percentily, které umožňují vizualizaci odlehlých hodnot. Latence fáze je rozdělená podle názvu clusteru, aplikace a fáze. Identifikujte špičky v latenci úloh v grafu, abyste zjistili, které úkoly se drží po dokončení fáze.
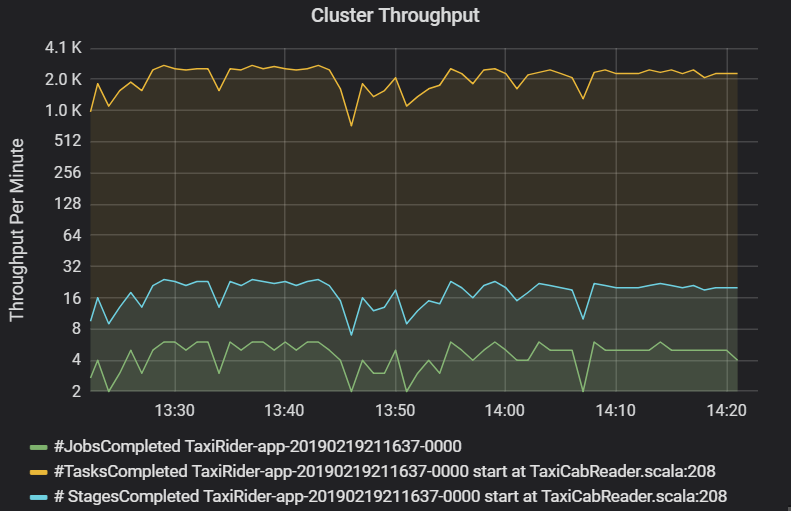
Graf propustnosti clusteru zobrazuje počet úloh, fází a úkolů dokončených za minutu. To vám pomůže pochopit úlohy z hlediska relativního počtu fází a úkolů na úlohu. Tady vidíte, že počet úloh za minutu se pohybuje mezi 2 a 6, zatímco počet fází je přibližně 12 – 24 za minutu.
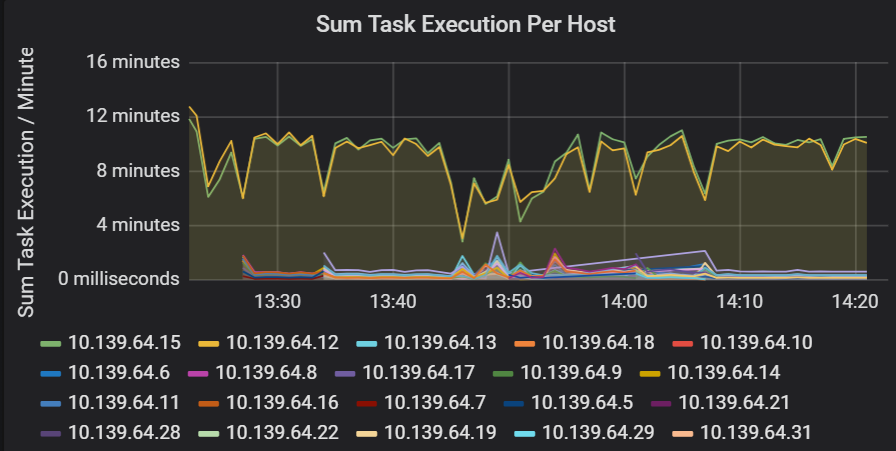
Součet latence provádění úkolů
Tato vizualizace ukazuje součet latence spouštění úloh na hostitele spuštěného v clusteru. Tento graf slouží ke zjišťování úloh, které běží pomalu kvůli zpomalení hostitele v clusteru nebo nesprávnému umístění úloh na exekutor. V následujícím grafu má většina hostitelů součet přibližně 30 sekund. Dva hostitelé ale mají součty, které najet kolem 10 minut. Hostitelé buď běží pomalu, nebo je počet úloh na exekutor nesprávně přidělený.
Početúkolůch
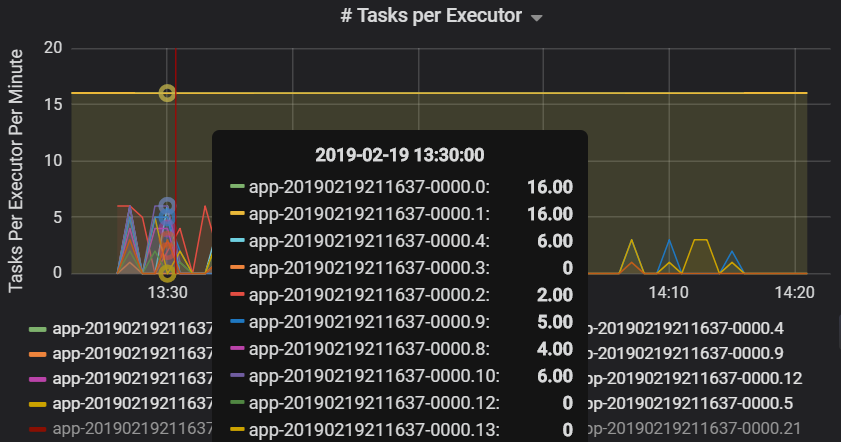
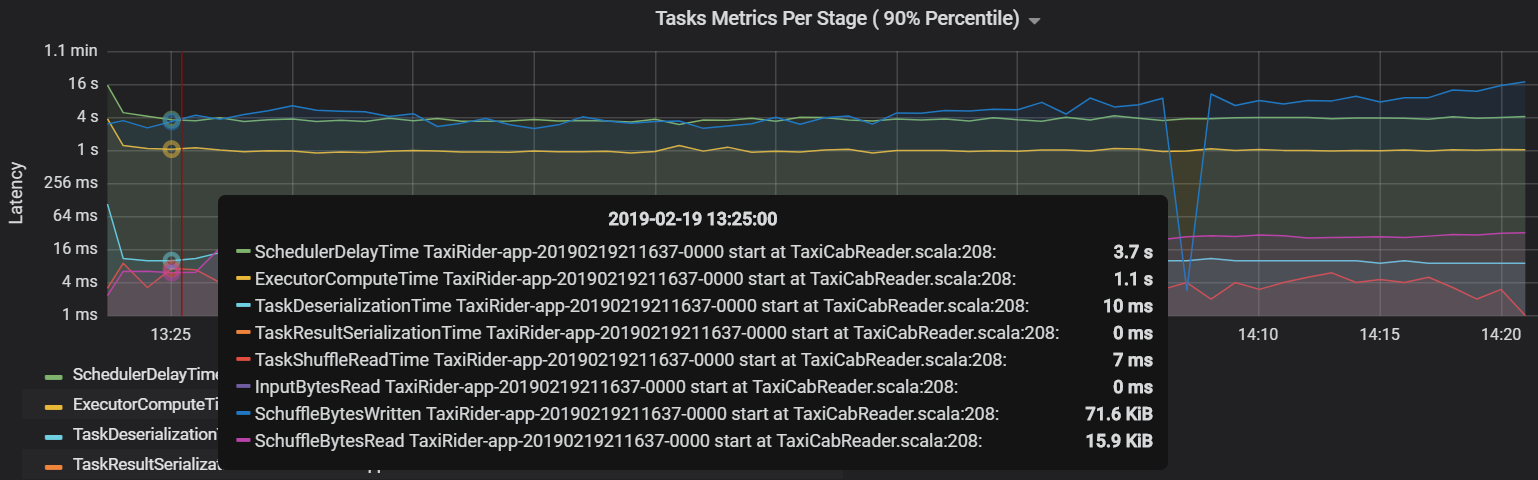
Metriky úkolů v jednotlivých fázích
Vizualizace metrik úloh poskytuje rozpis nákladů pro provádění úkolu. Můžete ho použít k zobrazení relativního času stráveného na úkolech, jako je serializace a deserializace. Tato data můžou zobrazovat příležitosti k optimalizaci – například pomocí proměnných vysílání, aby se zabránilo expedičním datům. Metriky úkolů také zobrazují velikost dat náhodného náhodného prohazování úkolu a časy čtení a zápisu náhodného čtení a zápisu. Pokud jsou tyto hodnoty vysoké, znamená to, že se v síti přesouvá velké množství dat.
Další metrika úkolu je zpoždění plánovače, které měří, jak dlouho trvá naplánování úkolu. V ideálním případě by tato hodnota měla být nízká ve srovnání s výpočetním časem exekutoru, což je čas strávený skutečně prováděním úlohy.
Následující graf ukazuje čas zpoždění plánovače (3,7 s), který překračuje výpočetní čas exekutoru (1,1 s). To znamená, že více času strávíte čekáním na naplánování úkolů, než když provedete skutečnou práci.
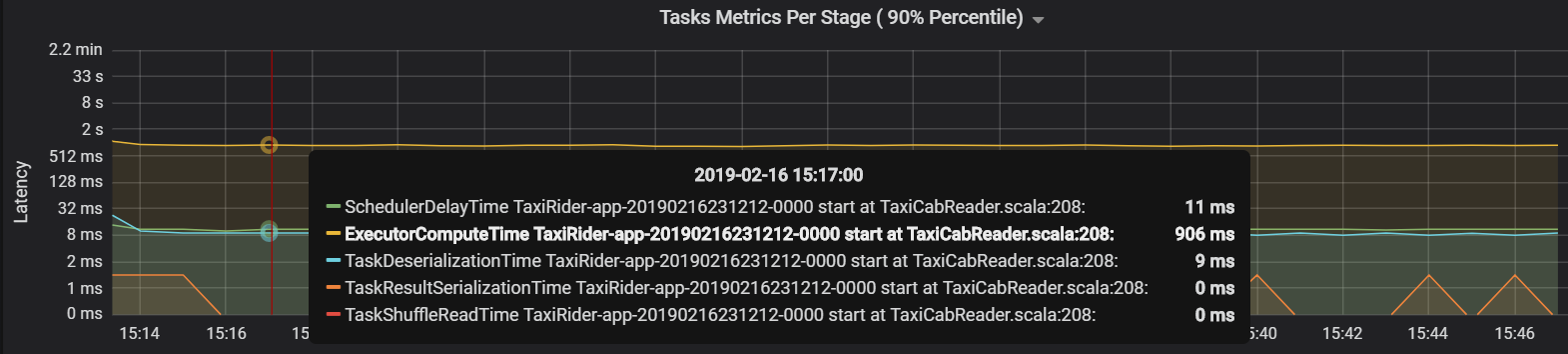
V tomto případě byl problém způsoben příliš mnoha oddíly, což způsobilo velké množství režijních nákladů. Snížení počtu oddílů zkrátilo dobu zpoždění plánovače. Další graf ukazuje, že většinu času strávíte prováděním úkolu.
Propustnost a latence streamování
Propustnost streamování přímo souvisí se strukturovaným streamováním. Propustnost streamování souvisí se dvěma důležitými metrikami: Vstupní řádky za sekundu a zpracovávané řádky za sekundu. Pokud vstupní řádky za sekundu odsadí zpracovávané řádky za sekundu, znamená to, že systém zpracování datových proudů se zastavuje. Pokud vstupní data pocházejí ze služby Event Hubs nebo Kafka, měly by vstupní řádky za sekundu držet krok s rychlostí příjmu dat na front-endu.
Dvě úlohy můžou mít podobnou propustnost clusteru, ale velmi odlišné metriky streamování. Následující snímek obrazovky ukazuje dvě různé úlohy. Jsou podobné z hlediska propustnosti clusteru (úlohy, fáze a úlohy za minutu). Druhé spuštění ale zpracuje 12 000 řádků za sekundu a 4 000 řádků za sekundu.
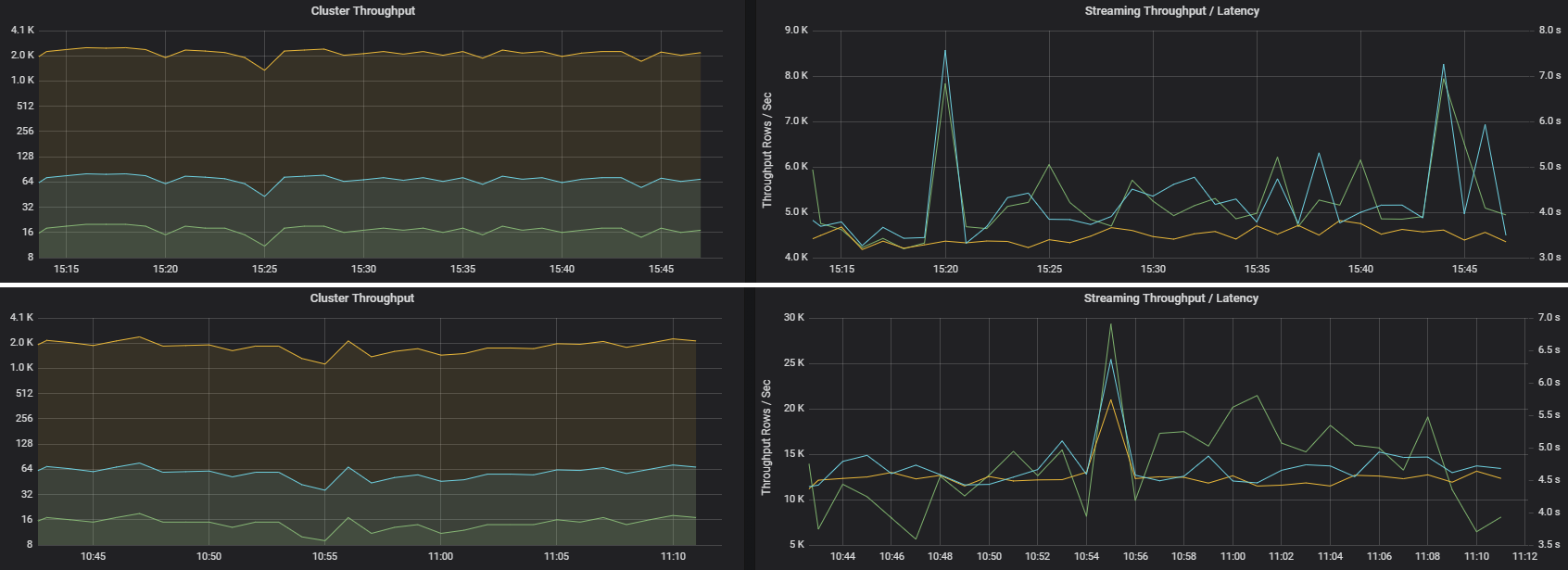
Propustnost streamování je často lepší obchodní metrikou než propustnost clusteru, protože měří počet zpracovaných datových záznamů.
Spotřeba prostředků na exekutor
Tyto metriky pomáhají pochopit práci, kterou každý exekutor provádí.
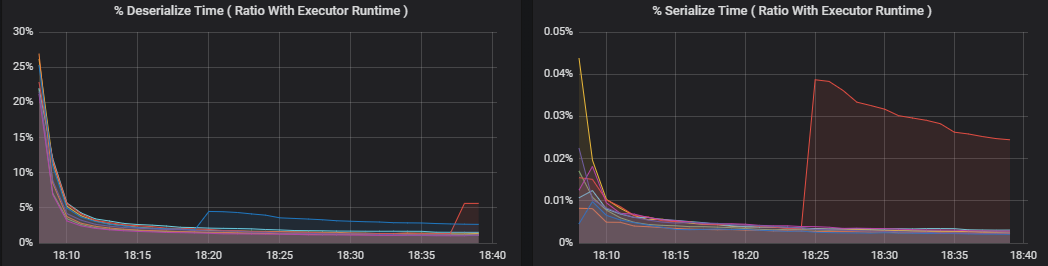
Procento metrik měří, kolik času exekutor stráví různými věcmi, vyjádřený poměrem času stráveného oproti celkovému výpočetnímu času exekutoru. Jsou to:
- % serializace času
- % deserializace času
- % času exekutoru procesoru
- % času JVM
Tyto vizualizace ukazují, jak velká část těchto metrik přispívá k celkovému zpracování exekutoru.
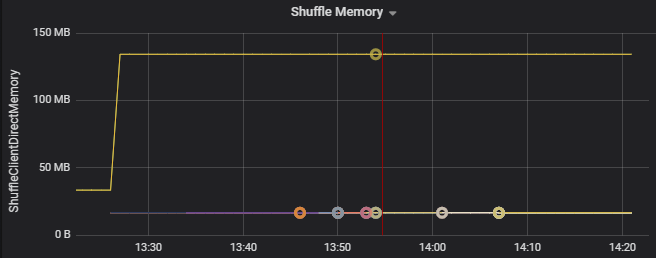
Metriky shuffle jsou metriky související s náhodném prohazování dat napříč exekutory.
- Prohazovat vstupně-výstupní operace
- Shuffle memory
- Využití systému souborů
- Využití disku
Běžné kritické body výkonu
Mezi dva běžné kritické body výkonu ve Sparku patří odpadlíci úloh a neoptimální počet oddílů náhodného náhodného prohazování.
Odpadlíci úkolů
Jednotlivé fáze úloh se spouští postupně, přičemž dřívější fáze blokují pozdější fáze. Pokud jedna úloha prohazuje oddíly pomaleji než jiné úlohy, všechny úlohy v clusteru musí počkat, dokud je pomalá úloha nedohoní, a teprve pak může daná fáze skončit. K tomu může dojít z následujících důvodů:
Hostitel nebo skupina hostitelů jsou pomalé. Příznaky: Vysoká latence úlohy, fáze nebo úloha a nízká propustnost clusteru. Součet latencí úkolů na hostitele nebude rovnoměrně distribuován. Spotřeba prostředků se ale rovnoměrně distribuuje mezi exekutory.
Úlohy mají nákladnou agregaci ke spuštění (zpracování dat). Příznaky: Vysoká latence úloh, vysoká latence fáze, vysoká latence úlohy nebo nízká propustnost clusteru, ale součet latencí na hostitele je rovnoměrně distribuovaný. Spotřeba prostředků se rovnoměrně distribuuje mezi exekutory.
Pokud jsou oddíly nerovné velikosti, může větší oddíl způsobit nerovné provádění úloh (dělení skewing). Příznaky: Spotřeba prostředků exekutoru je ve srovnání s jinými exekutory spuštěnými v clusteru vysoká. Všechny úlohy spuštěné na exekutoru budou pomalé a budou obsahovat spuštění fáze v kanálu. O těchto fázích se říká, že jde o bariéry.
Neoptimální počet oddílů náhodného náhodného prohazu
Během strukturovaného streamovacího dotazu je přiřazení úlohy exekutoru operací náročnou na prostředky pro cluster. Pokud data náhodného prohazování nejsou optimální velikostí, bude mít zpoždění úkolu negativní vliv na propustnost a latenci. Pokud existuje příliš málo oddílů, jádra v clusteru budou nedostatečně využitá, což může vést k neefektivitě zpracování. Naopak pokud existuje příliš mnoho oddílů, je pro malý počet úloh velká část režie správy.
Metriky spotřeby prostředků slouží k řešení potíží se spouštěním oddílů a chybným umístěním exekutorů v clusteru. Pokud dojde ke nerovnoměrné distribuci oddílu, prostředky exekutoru se zvýší oproti ostatním exekutorům spuštěným v clusteru.
Následující graf například ukazuje, že paměť používaná při náhodném prohazování prvních dvou exekutorů je větší než ostatní exekutory 90X:
Další kroky
- Monitorování Azure Databricks v pracovním prostoru Služby Azure Log Analytics
- Studijní program: Sestavování a provoz řešení strojového učení pomocí Azure Databricks
- Dokumentace ke službě Azure Databricks
- Přehled služby Azure Monitor
Související prostředky
- Monitorování Azure Databricks
- Odesílání protokolů aplikací Azure Databricks do Azure Monitoru
- Použití řídicích panelů k vizualizaci metrik Azure Databricks
- Moderní analytická architektura s využitím Azure Databricks
- Příjem dat, ETL (extrakce, transformace, načítání) a kanály zpracování datových proudů pomocí Azure Databricks