Sestavení a trénování vlastního modelu extrakce
Tento obsah se vztahuje na:![]() v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1
v2.1
Vlastní modely Document Intelligence vyžadují pro začátek několik trénovacích dokumentů. Pokud máte alespoň pět dokumentů, můžete začít s trénováním vlastního modelu. Můžete trénovat buď vlastní model šablony (vlastní formulář), nebo vlastní neurální model (vlastní dokument). Tento dokument vás provede procesem trénování vlastních modelů.
Požadavky na vstup vlastního modelu
Nejprve se ujistěte, že vaše trénovací datová sada splňuje vstupní požadavky pro funkci Document Intelligence.
Podporované formáty souborů:
Model PDF Obrázek: JPEG/JPG,PNG,BMP,TIFF,HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
Tipy pro trénování dat
Projděte si tyto tipy k další optimalizaci datové sady pro trénování:
- Místo obrázků používejte textové dokumenty PDF. Naskenované dokumenty PDF se zpracovávají jako obrázky.
- Použijte příklady, které mají všechna pole vyplněná pro formuláře se vstupními poli.
- Používejte formuláře s různými hodnotami v každém poli.
- Pokud mají obrázky formuláře nižší kvalitu, použijte větší datovou sadu (10 až 15 obrázků).
Nahrání trénovacích dat
Jakmile shromáždíte sadu formulářů nebo dokumentů pro trénování, musíte ji nahrát do kontejneru úložiště objektů blob v Azure. Pokud nevíte, jak vytvořit účet úložiště Azure s kontejnerem, použijte rychlý start pro Azure Storage pro Azure Portal. Službu můžete vyzkoušet pomocí cenové úrovně Free (F0) a později upgradovat na placenou úroveň pro produkční prostředí.
Video: Trénování vlastního modelu
- Jakmile shromáždíte a nahrajete trénovací datovou sadu, budete připraveni natrénovat vlastní model. V následujícím videu vytvoříme projekt a prozkoumáme některé základy úspěšného označování a trénování modelu.
Vytvoření projektu v nástroji Document Intelligence Studio
Sada Document Intelligence Studio poskytuje a orchestruje všechna volání rozhraní API potřebná k dokončení datové sady a trénování modelu.
Začněte tím, že přejdete do sady Document Intelligence Studio. Při prvním použití sady Studio je potřeba inicializovat předplatné, skupinu prostředků a prostředek. Potom podle požadavků pro vlastní projekty nakonfigurujte Studio pro přístup k trénovací datové sadě.
V sadě Studio vyberte dlaždici Vlastní model extrakce a vyberte tlačítko Vytvořit projekt .
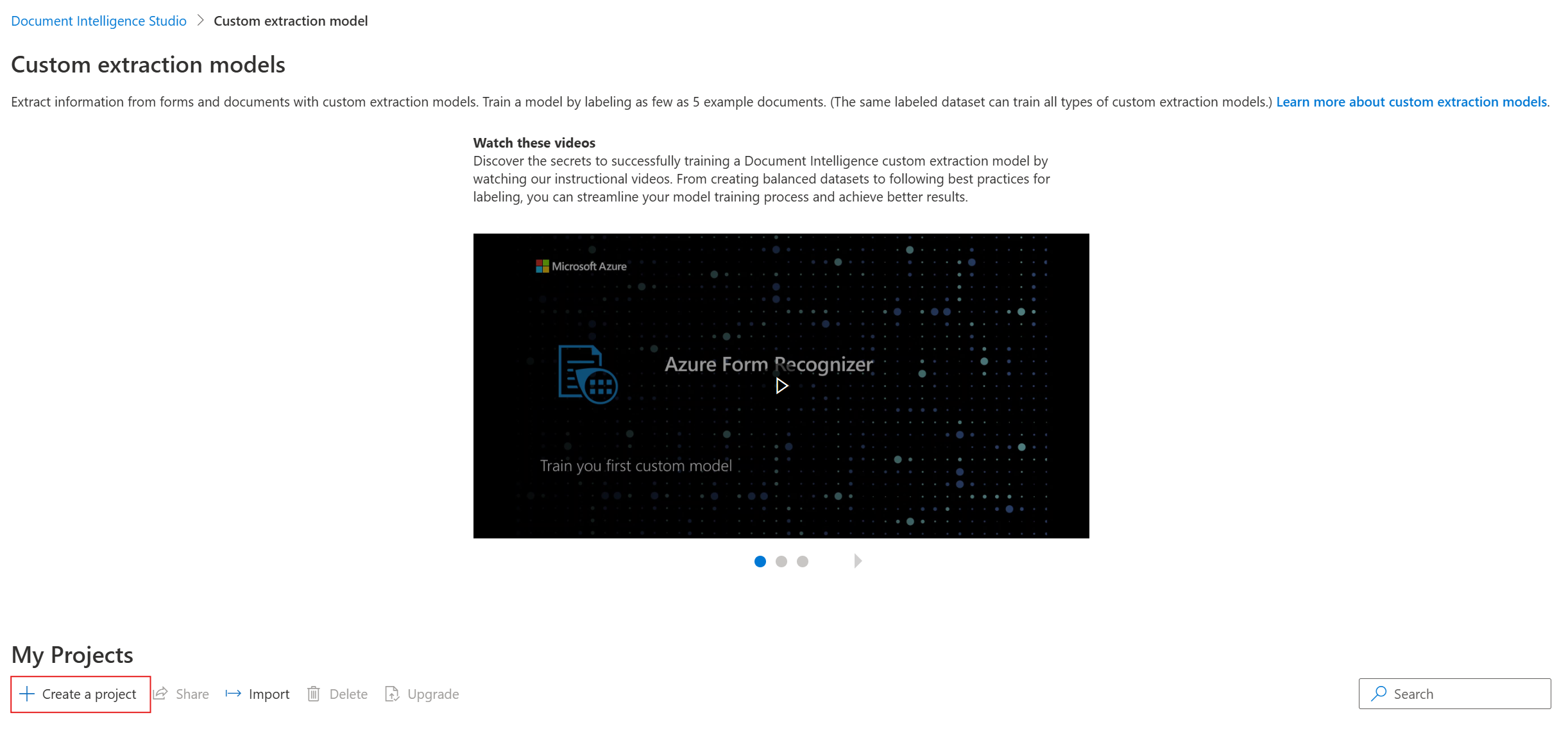
V dialogovém okně
create projectzadejte název projektu, volitelně popis a vyberte pokračovat.V dalším kroku pracovního postupu zvolte nebo vytvořte prostředek document intelligence, než vyberete pokračovat.
Důležité
Vlastní neurální modely jsou k dispozici pouze v několika oblastech. Pokud plánujete trénování neurálního modelu, vyberte nebo vytvořte prostředek v jedné z těchto podporovaných oblastí.
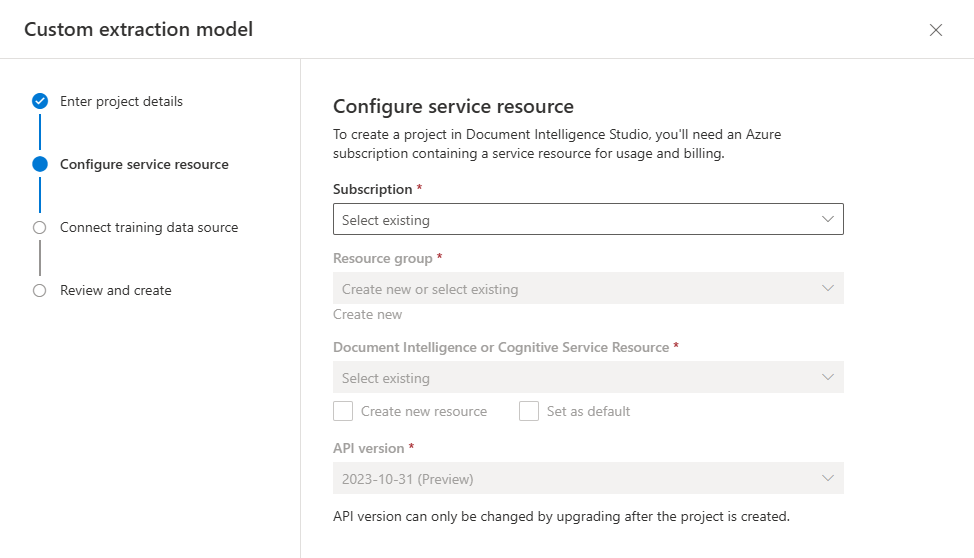
Pak vyberte účet úložiště, který jste použili k nahrání vlastní trénovací datové sady modelu. Cesta ke složce by měla být prázdná, pokud jsou vaše trénovací dokumenty v kořenovém adresáři kontejneru. Pokud jsou vaše dokumenty v podsložce, zadejte relativní cestu z kořenového adresáře kontejneru do pole Cesta ke složce. Po nakonfigurování účtu úložiště vyberte pokračovat.
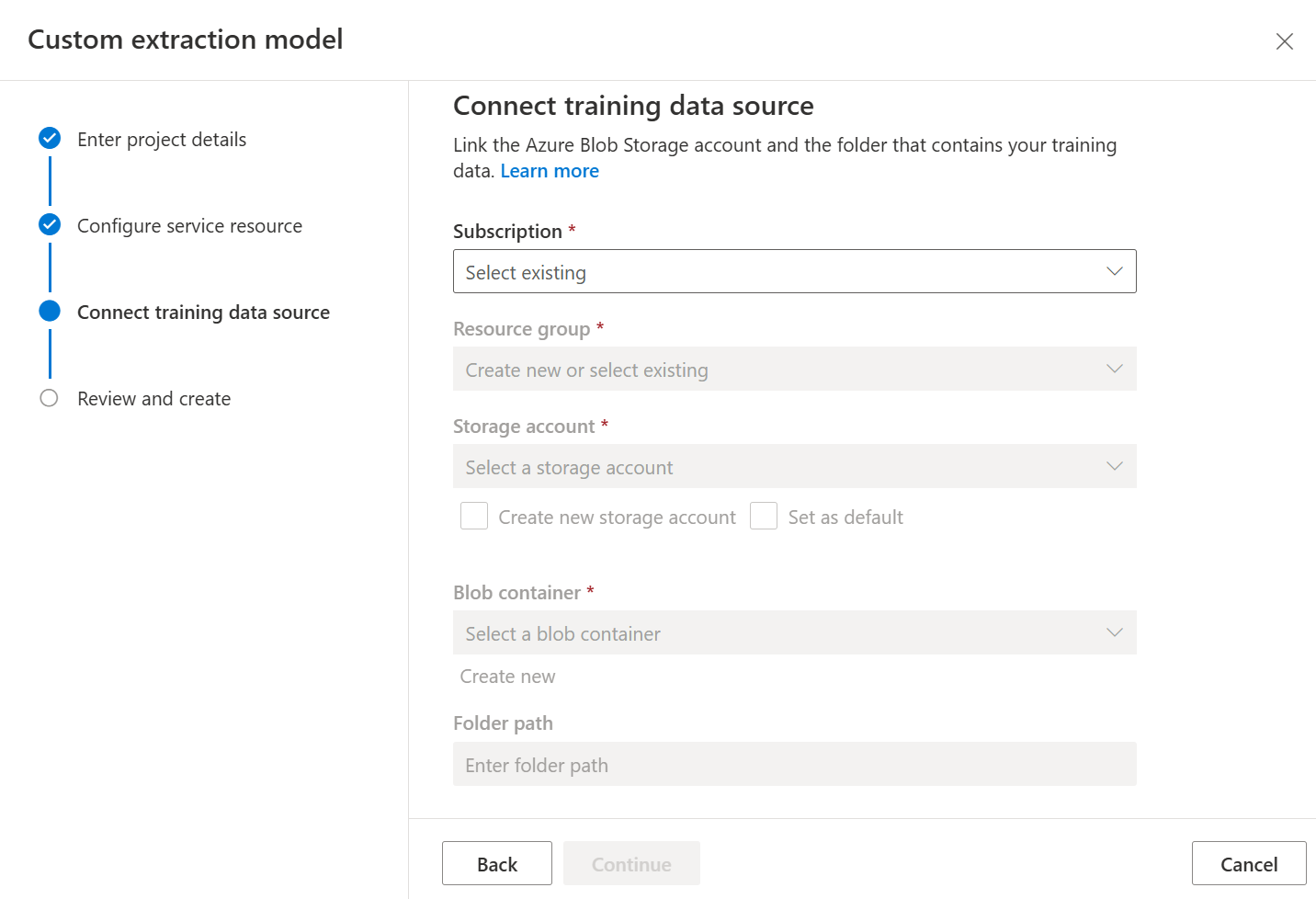
Nakonec zkontrolujte nastavení projektu a vyberte Vytvořit projekt a vytvořte nový projekt. Teď byste měli být v okně popisků a vidět soubory v datové sadě.
Označení dat
Prvním úkolem v projektu je označit datovou sadu poli, která chcete extrahovat.
Soubory, které jste nahráli do úložiště, jsou uvedené na levé straně obrazovky s prvním souborem připraveným k označení.
Začněte popisovat datovou sadu a vytvořit první pole tak, že v pravém horním rohu obrazovky vyberete tlačítko plus (➕).
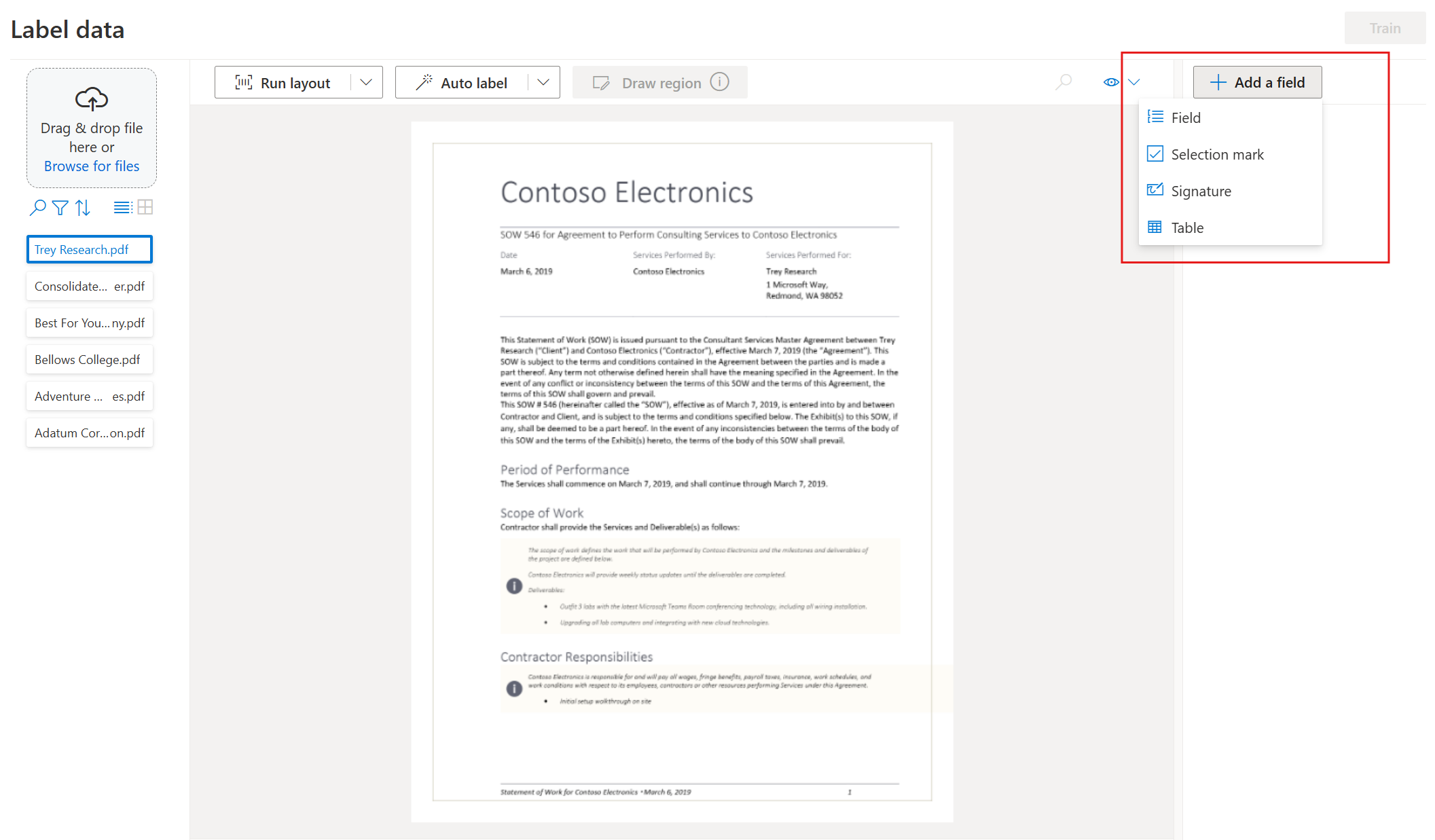
Zadejte název pole.
Přiřaďte k poli hodnotu tak, že vyberete slovo nebo slova v dokumentu. Vyberte pole v rozevíracím seznamu nebo v seznamu polí na pravém navigačním panelu. Označená hodnota je pod názvem pole v seznamu polí.
Opakujte proces pro všechna pole, která chcete označit jako datovou sadu.
Označte zbývající dokumenty v datové sadě tak, že vyberete každý dokument a vyberete text, který se má označit.
Teď máte všechny dokumenty v datové sadě označené popiskem. Soubory .labels.json a .ocr.json odpovídají jednotlivým dokumentům v trénovací datové sadě a novému souboru fields.json. Tato trénovací datová sada se odešle pro trénování modelu.
Trénování vašeho modelu
S označenou datovou sadou teď můžete model vytrénovat. V pravém horním rohu vyberte tlačítko vlaku.
V dialogovém okně trénování modelu zadejte jedinečné ID modelu a volitelně i popis. ID modelu přijímá datový typ řetězce.
V režimu sestavení vyberte typ modelu, který chcete trénovat. Přečtěte si další informace o typech a možnostech modelu.
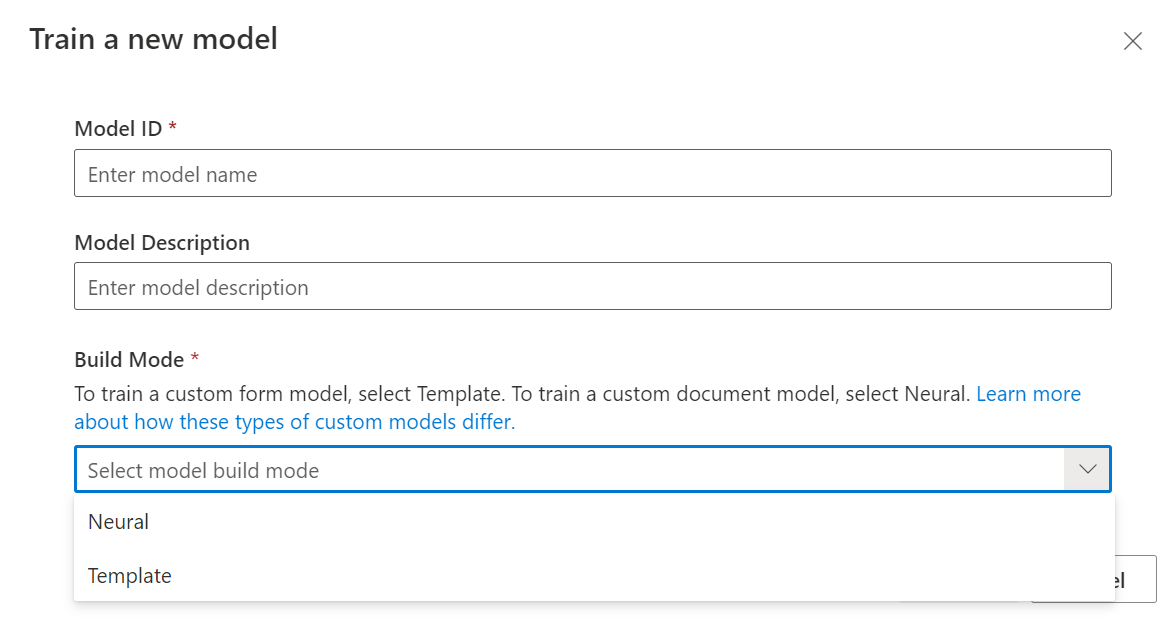
Výběrem možnosti Trénování zahájíte proces trénování.
Modely šablon se vytrénuje během několika minut. Trénování neurálních modelů může trvat až 30 minut.
Přejděte do nabídky Modely a zobrazte stav operace trénování.
Test modelu
Po dokončení trénování modelu můžete model otestovat výběrem modelu na stránce seznamu modelů.
Vyberte model a vyberte na tlačítku Test .
+ AddVýběrem tlačítka vyberte soubor k otestování modelu.Pokud je vybraný soubor, zvolte tlačítko Analyzovat a otestujte model.
Výsledky modelu se zobrazí v hlavním okně a pole extrahovaná jsou uvedena na pravém navigačním panelu.
Ověřte model vyhodnocením výsledků pro každé pole.
Na pravém navigačním panelu je také vzorový kód pro vyvolání modelu a výsledků JSON z rozhraní API.
Blahopřejeme, že jste se naučili trénovat vlastní model v nástroji Document Intelligence Studio! Váš model je připravený k použití s rozhraním REST API nebo sadou SDK k analýze dokumentů.
Platí pro: ![]() v2.1. Další verze: v3.0
v2.1. Další verze: v3.0
Když použijete vlastní model Document Intelligence, poskytnete vlastní trénovací data pro operaci Trénování vlastního modelu , aby model mohl trénovat na vaše oborové formuláře. Podle tohoto průvodce se dozvíte, jak efektivně shromažďovat a připravovat data pro efektivní trénování modelu.
Potřebujete alespoň pět dokončených formulářů stejného typu.
Pokud chcete použít ručně označená trénovací data, musíte začít alespoň s pěti dokončenými formuláři stejného typu. Kromě požadované datové sady můžete i nadále používat neoznačené formuláře.
Požadavky na vstup vlastního modelu
Nejprve se ujistěte, že vaše trénovací datová sada splňuje vstupní požadavky pro funkci Document Intelligence.
Podporované formáty souborů:
Model PDF Obrázek: JPEG/JPG,PNG,BMP,TIFF,HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
Tipy pro trénování dat
Pomocí těchto tipů můžete dále optimalizovat sadu dat pro účely trénování.
- Místo obrázků používejte textové dokumenty PDF. Naskenované dokumenty PDF se zpracovávají jako obrázky.
- Použijte příklady, které mají všechna pole vyplněná pro dokončené formuláře.
- Používejte formuláře s různými hodnotami v každém poli.
- Pro dokončené formuláře použijte větší datovou sadu (10 až 15 obrázků).
Nahrání trénovacích dat
Jakmile shromáždíte sadu dokumentů pro trénování, musíte ji nahrát do kontejneru úložiště objektů blob v Azure. Pokud nevíte, jak vytvořit účet úložiště Azure s kontejnerem, postupujte podle rychlého startu azure Storage pro Azure Portal. Použijte úroveň výkonu Standard.
Pokud chcete použít ručně označená data, nahrajte .labels.json a .ocr.json soubory, které odpovídají vašim trénovacím dokumentům. K vygenerování těchto souborů můžete použít nástroj Sample Labeling (nebo vlastní uživatelské rozhraní).
Uspořádání dat v podsložkách (volitelné)
Ve výchozím nastavení rozhraní API pro trénování vlastního modelu používá jenom dokumenty umístěné v kořenovém adresáři kontejneru úložiště. Pokud je ale zadáte ve volání rozhraní API, můžete je trénovat s daty v podsložkách. Za normálních okolností má tělo volání vlastního modelu trénování následující formát, kde <SAS URL> je adresa URL sdíleného přístupového podpisu kontejneru:
{
"source":"<SAS URL>"
}
Pokud do textu požadavku přidáte následující obsah, rozhraní API se trénuje s dokumenty umístěnými v podsložkách. Pole "prefix" je volitelné a omezuje trénovací sadu dat na soubory, jejichž cesty začínají daným řetězcem. Hodnota "Test"například způsobí, že se rozhraní API podívá jenom na soubory nebo složky, které začínají slovem Test.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Další kroky
Teď, když jste se dozvěděli, jak vytvořit trénovací sadu dat, postupujte podle rychlého startu a vytrénujte vlastní model document intelligence a začněte ho používat ve formulářích.