Jak vygenerovat vkládání s využitím odvození modelu Azure AI
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro vkládání s modely nasazenými do odvozování modelu Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat vložené modely, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
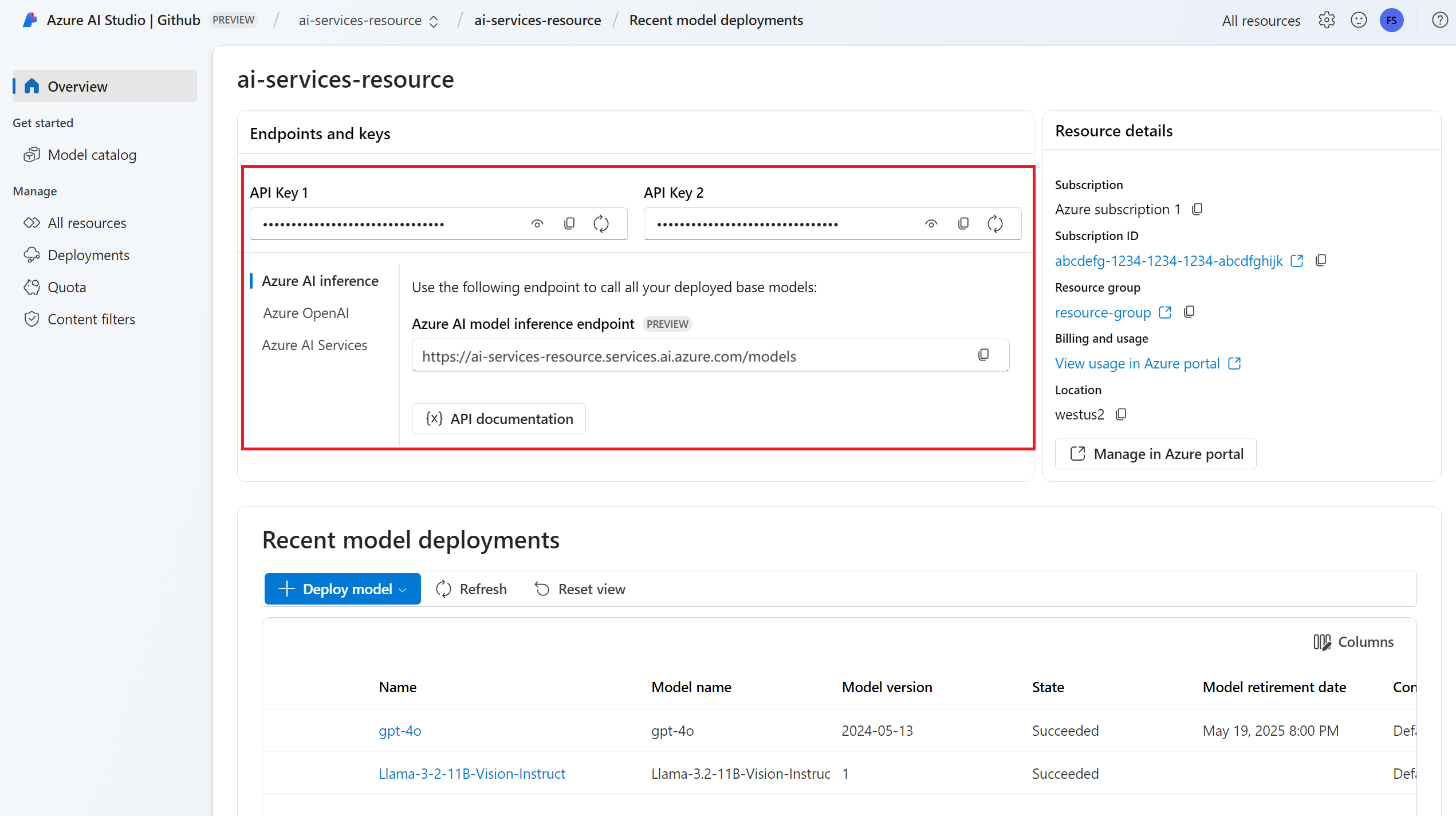

Nasazení modelu vkládání. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI, abyste do prostředku přidali model vkládání.
Nainstalujte balíček odvození Azure AI pomocí následujícího příkazu:
pip install -U azure-ai-inference
Použití vkládání
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
Vytváření vložených objektů
Vytvořte požadavek pro vložení, abyste viděli výstup modelu.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
Tip
Při vytváření požadavku vezměte v úvahu vstupní limit tokenu pro model. Pokud potřebujete vložit větší části textu, budete potřebovat strategii vytváření bloků dat.
Odpověď je následující, kde vidíte statistiku využití modelu:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Může být užitečné vypočítat vkládání do vstupních dávek.
inputs Parametr může být seznam řetězců, kde každý řetězec je jiný vstup. Odpověď je seznam vkládání, kde každé vložení odpovídá vstupu ve stejné pozici.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
Odpověď je následující, kde vidíte statistiku využití modelu:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Tip
Při vytváření dávek požadavků vezměte v úvahu limit dávky pro každý z modelů. Většina modelů má limit dávky 1024.
Určení dimenzí vkládání
Můžete zadat počet dimenzí pro vkládání. Následující příklad kódu ukazuje, jak vytvořit vkládání s rozměry 1024. Všimněte si, že ne všechny vložené modely podporují indikující počet dimenzí v požadavku a v těchto případech se vrátí chyba 422.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
Vytváření různých typů vkládání
Některé modely můžou generovat více vkládání pro stejný vstup v závislosti na tom, jak je plánujete použít. Tato funkce umožňuje načíst přesnější vkládání pro vzory RAG.
Následující příklad ukazuje, jak vytvořit vkládání, které se používají k vytvoření vkládání pro dokument, který bude uložen ve vektorové databázi:
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
Když pracujete na dotazu na načtení takového dokumentu, můžete pomocí následujícího fragmentu kódu vytvořit vkládání pro dotaz a maximalizovat výkon načítání.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
Všimněte si, že ne všechny modely vkládání podporují indikující typ vstupu v požadavku a v těchto případech se vrátí chyba 422. Ve výchozím nastavení se vrátí vkládání typu Text .
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro vkládání s modely nasazenými do odvozování modelu Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat vložené modely, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
Nasazení modelu vkládání. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI, abyste do prostředku přidali model vkládání.
Pomocí následujícího příkazu nainstalujte knihovnu Azure Inference pro JavaScript:
npm install @azure-rest/ai-inference
Použití vkládání
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Vytváření vložených objektů
Vytvořte požadavek pro vložení, abyste viděli výstup modelu.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
Tip
Při vytváření požadavku vezměte v úvahu vstupní limit tokenu pro model. Pokud potřebujete vložit větší části textu, budete potřebovat strategii vytváření bloků dat.
Odpověď je následující, kde vidíte statistiku využití modelu:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Může být užitečné vypočítat vkládání do vstupních dávek.
inputs Parametr může být seznam řetězců, kde každý řetězec je jiný vstup. Odpověď je seznam vkládání, kde každé vložení odpovídá vstupu ve stejné pozici.
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
Odpověď je následující, kde vidíte statistiku využití modelu:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Tip
Při vytváření dávek požadavků vezměte v úvahu limit dávky pro každý z modelů. Většina modelů má limit dávky 1024.
Určení dimenzí vkládání
Můžete zadat počet dimenzí pro vkládání. Následující příklad kódu ukazuje, jak vytvořit vkládání s rozměry 1024. Všimněte si, že ne všechny vložené modely podporují indikující počet dimenzí v požadavku a v těchto případech se vrátí chyba 422.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
Vytváření různých typů vkládání
Některé modely můžou generovat více vkládání pro stejný vstup v závislosti na tom, jak je plánujete použít. Tato funkce umožňuje načíst přesnější vkládání pro vzory RAG.
Následující příklad ukazuje, jak vytvořit vkládání, které se používají k vytvoření vkládání pro dokument, který bude uložen ve vektorové databázi:
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
Když pracujete na dotazu na načtení takového dokumentu, můžete pomocí následujícího fragmentu kódu vytvořit vkládání pro dotaz a maximalizovat výkon načítání.
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
Všimněte si, že ne všechny modely vkládání podporují indikující typ vstupu v požadavku a v těchto případech se vrátí chyba 422. Ve výchozím nastavení se vrátí vkládání typu Text .
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro vkládání s modely nasazenými do odvozování modelu Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat vložené modely, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
Nasazení modelu vkládání. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI, abyste do prostředku přidali model vkládání.
Přidejte do projektu balíček pro odvození Azure AI:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Pokud používáte ID Entra, potřebujete také následující balíček:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Naimportujte následující obor názvů:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Použití vkládání
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Vytváření vložených objektů
Vytvořte požadavek pro vložení, abyste viděli výstup modelu.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
Tip
Při vytváření požadavku vezměte v úvahu vstupní limit tokenu pro model. Pokud potřebujete vložit větší části textu, budete potřebovat strategii vytváření bloků dat.
Odpověď je následující, kde vidíte statistiku využití modelu:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
Může být užitečné vypočítat vkládání do vstupních dávek.
inputs Parametr může být seznam řetězců, kde každý řetězec je jiný vstup. Odpověď je seznam vkládání, kde každé vložení odpovídá vstupu ve stejné pozici.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
Odpověď je následující, kde vidíte statistiku využití modelu:
Tip
Při vytváření dávek požadavků vezměte v úvahu limit dávky pro každý z modelů. Většina modelů má limit dávky 1024.
Určení dimenzí vkládání
Můžete zadat počet dimenzí pro vkládání. Následující příklad kódu ukazuje, jak vytvořit vkládání s rozměry 1024. Všimněte si, že ne všechny vložené modely podporují indikující počet dimenzí v požadavku a v těchto případech se vrátí chyba 422.
Vytváření různých typů vkládání
Některé modely můžou generovat více vkládání pro stejný vstup v závislosti na tom, jak je plánujete použít. Tato funkce umožňuje načíst přesnější vkládání pro vzory RAG.
Následující příklad ukazuje, jak vytvořit vkládání, které se používají k vytvoření vkládání pro dokument, který bude uložen ve vektorové databázi:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
Když pracujete na dotazu na načtení takového dokumentu, můžete pomocí následujícího fragmentu kódu vytvořit vkládání pro dotaz a maximalizovat výkon načítání.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
Všimněte si, že ne všechny modely vkládání podporují indikující typ vstupu v požadavku a v těchto případech se vrátí chyba 422. Ve výchozím nastavení se vrátí vkládání typu Text .
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro vkládání s modely nasazenými do odvozování modelu Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat vložené modely, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
Nasazení modelu vkládání. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI, abyste do prostředku přidali model vkládání.
Nainstalujte balíček odvození Azure AI pomocí následujícího příkazu:
dotnet add package Azure.AI.Inference --prereleasePokud používáte ID Entra, potřebujete také následující balíček:
dotnet add package Azure.Identity
Použití vkládání
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"text-embedding-3-small"
);
Vytváření vložených objektů
Vytvořte požadavek pro vložení, abyste viděli výstup modelu.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Tip
Při vytváření požadavku vezměte v úvahu vstupní limit tokenu pro model. Pokud potřebujete vložit větší části textu, budete potřebovat strategii vytváření bloků dat.
Odpověď je následující, kde vidíte statistiku využití modelu:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Může být užitečné vypočítat vkládání do vstupních dávek.
inputs Parametr může být seznam řetězců, kde každý řetězec je jiný vstup. Odpověď je seznam vkládání, kde každé vložení odpovídá vstupu ve stejné pozici.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Odpověď je následující, kde vidíte statistiku využití modelu:
Tip
Při vytváření dávek požadavků vezměte v úvahu limit dávky pro každý z modelů. Většina modelů má limit dávky 1024.
Určení dimenzí vkládání
Můžete zadat počet dimenzí pro vkládání. Následující příklad kódu ukazuje, jak vytvořit vkládání s rozměry 1024. Všimněte si, že ne všechny vložené modely podporují indikující počet dimenzí v požadavku a v těchto případech se vrátí chyba 422.
Vytváření různých typů vkládání
Některé modely můžou generovat více vkládání pro stejný vstup v závislosti na tom, jak je plánujete použít. Tato funkce umožňuje načíst přesnější vkládání pro vzory RAG.
Následující příklad ukazuje, jak vytvořit vkládání, které se používají k vytvoření vkládání pro dokument, který bude uložen ve vektorové databázi:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Když pracujete na dotazu na načtení takového dokumentu, můžete pomocí následujícího fragmentu kódu vytvořit vkládání pro dotaz a maximalizovat výkon načítání.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Všimněte si, že ne všechny modely vkládání podporují indikující typ vstupu v požadavku a v těchto případech se vrátí chyba 422. Ve výchozím nastavení se vrátí vkládání typu Text .
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro vkládání s modely nasazenými do odvozování modelu Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat vložené modely, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
- Nasazení modelu vkládání. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI, abyste do prostředku přidali model vkládání.
Použití vkládání
Pokud chcete použít vkládání textu, použijte trasu /embeddings připojenou k základní adrese URL spolu s přihlašovacími údaji uvedenými v api-key.
Authorization záhlaví je podporováno také ve formátu Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Pokud jste nakonfigurovali prostředek s podporou Microsoft Entra ID , předejte token v Authorization hlavičce:
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Vytváření vložených objektů
Vytvořte požadavek pro vložení, abyste viděli výstup modelu.
{
"input": [
"The ultimate answer to the question of life"
]
}
Tip
Při vytváření požadavku vezměte v úvahu vstupní limit tokenu pro model. Pokud potřebujete vložit větší části textu, budete potřebovat strategii vytváření bloků dat.
Odpověď je následující, kde vidíte statistiku využití modelu:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
Může být užitečné vypočítat vkládání do vstupních dávek.
inputs Parametr může být seznam řetězců, kde každý řetězec je jiný vstup. Odpověď je seznam vkládání, kde každé vložení odpovídá vstupu ve stejné pozici.
{
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
Odpověď je následující, kde vidíte statistiku využití modelu:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
Tip
Při vytváření dávek požadavků vezměte v úvahu limit dávky pro každý z modelů. Většina modelů má limit dávky 1024.
Určení dimenzí vkládání
Můžete zadat počet dimenzí pro vkládání. Následující příklad kódu ukazuje, jak vytvořit vkládání s rozměry 1024. Všimněte si, že ne všechny vložené modely podporují indikující počet dimenzí v požadavku a v těchto případech se vrátí chyba 422.
{
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
Vytváření různých typů vkládání
Některé modely můžou generovat více vkládání pro stejný vstup v závislosti na tom, jak je plánujete použít. Tato funkce umožňuje načíst přesnější vkládání pro vzory RAG.
Následující příklad ukazuje, jak vytvořit vkládání, které se používají k vytvoření vkládání pro dokument, který bude uložen ve vektorové databázi:
{
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
Když pracujete na dotazu na načtení takového dokumentu, můžete pomocí následujícího fragmentu kódu vytvořit vkládání pro dotaz a maximalizovat výkon načítání.
{
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
Všimněte si, že ne všechny modely vkládání podporují indikující typ vstupu v požadavku a v těchto případech se vrátí chyba 422. Ve výchozím nastavení se vrátí vkládání typu Text .