How to use image and audio in chat completions with Azure AI model inference
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.

Install the Azure AI inference package for Python with the following command:
pip install -U azure-ai-inference
A chat completions model deployment with support for audio and images. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
- This tutorial uses
Phi-4-multimodal-instruct.
- This tutorial uses
Use chat completions
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="Phi-4-multimodal-instruct"
)
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=DefaultAzureCredential(),
model="Phi-4-multimodal-instruct"
)
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of some models for vision in a chat fashion.
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualize the image:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Now, create a chat completion request with the image:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=1,
max_tokens=2048,
)
The response is as follows, where you can see the model's usage statistics:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
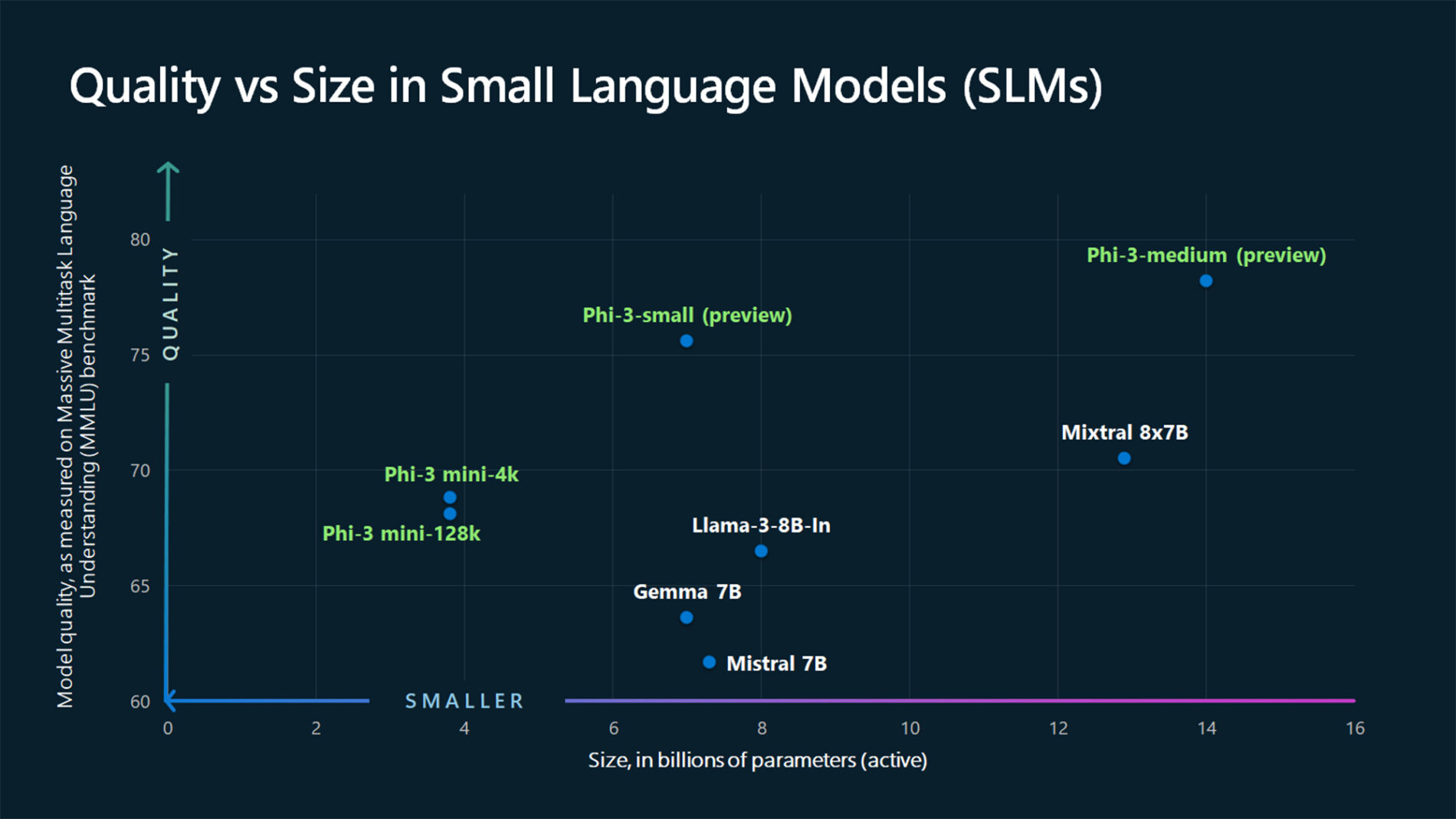
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-4-omni
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Images are broken into tokens and submitted to the model for processing. When referring to images, each of those tokens is typically referred as patches. Each model may break down a given image on a different number of patches. Read the model card to learn the details.
Use chat completions with audio
Some models can reason across text and audio inputs. The following example shows how you can send audio context to chat completions models that also supports audio. Use InputAudio to load the content of the audio file into the payload. The content is encoded in base64 data and sent over the payload.
from azure.ai.inference.models import (
TextContentItem,
AudioContentItem,
InputAudio,
AudioContentFormat,
)
response = client.complete(
messages=[
SystemMessage("You are an AI assistant for translating and transcribing audio clips."),
UserMessage(
[
TextContentItem(text="Please translate this audio snippet to spanish."),
AudioContentItem(
input_audio=InputAudio.load(
audio_file="hello_how_are_you.mp3", audio_format=AudioContentFormat.MP3
)
),
],
),
],
)
The response is as follows, where you can see the model's usage statistics:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
The model can read the content from an accessible cloud location by passing the URL as an input. The Python SDK doesn't provide a direct way to do it, but you can indicate the payload as follows:
response = client.complete(
{
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3"
}
}
]
},
],
}
)
Note
Using audio inputs is only supported using Python, C#, or REST requests.
Note
Using audio inputs is only supported using Python, C#, or REST requests.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
Install the Azure AI inference package with the following command:
dotnet add package Azure.AI.Inference --prereleaseIf you are using Entra ID, you also need the following package:
dotnet add package Azure.Identity
- A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
Use chat completions
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
credential,
clientOptions,
);
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualize the image:
Now, create a chat completion request with the image:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "Phi-4-multimodal-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
The response is as follows, where you can see the model's usage statistics:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Images are broken into tokens and submitted to the model for processing. When referring to images, each of those tokens is typically referred as patches. Each model may break down a given image on a different number of patches. Read the model card to learn the details.
Use chat completions with audio
Some models can reason across text and audio inputs. The following example shows how you can send audio context to chat completions models that also supports audio. Use InputAudio to load the content of the audio file into the payload. The content is encoded in base64 data and sent over the payload.
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem("hello_how_are_you.mp3", AudioContentFormat.Mp3),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
The response is as follows, where you can see the model's usage statistics:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
The model can read the content from an accessible cloud location by passing the URL as an input. The Python SDK doesn't provide a direct way to do it, but you can indicate the payload as follows:
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem(new Uri("https://.../hello_how_are_you.mp3"))),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
The response is as follows, where you can see the model's usage statistics:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use chat completions API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use chat completion models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
A chat completions model deployment. If you don't have one read Add and configure models to Azure AI services to add a chat completions model to your resource.
- This tutorial uses
Phi-4-multimodal-instruct.
- This tutorial uses
Use chat completions
To use chat completions API, use the route /chat/completions appended to the base URL along with your credential indicated in api-key. Authorization header is also supported with the format Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
If you have configured the resource with Microsoft Entra ID support, pass you token in the Authorization header:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Use chat completions with images
Some models can reason across text and images and generate text completions based on both kinds of input. In this section, you explore the capabilities of Some models for vision in a chat fashion:
Important
Some models support only one image for each turn in the chat conversation and only the last image is retained in context. If you add multiple images, it results in an error.
To see this capability, download an image and encode the information as base64 string. The resulting data should be inside of a data URL:
Tip
You will need to construct the data URL using a scripting or programming language. This tutorial uses this sample image in JPEG format. A data URL has a format as follows: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
{kind=link}
Visualize the image:
Now, create a chat completion request with the image:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
The response is as follows, where you can see the model's usage statistics:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}
Images are broken into tokens and submitted to the model for processing. When referring to images, each of those tokens is typically referred as patches. Each model may break down a given image on a different number of patches. Read the model card to learn the details.
Use chat completions with audio
Some models can reason across text and audio inputs. The following example shows how you can send audio context to chat completions models that also supports audio.
The following example sends audio content encoded in base64 data in the chat history:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "input_audio",
"input_audio": {
"data": "0xABCDFGHIJKLMNOPQRSTUVWXYZ...",
"format": "mp3"
}
}
]
}
],
}
The response is as follows, where you can see the model's usage statistics:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
The model can read the content from an accessible cloud location by passing the URL as an input. You can indicate the payload as follows:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3",
}
}
]
}
],
}
The response is as follows, where you can see the model's usage statistics:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}